
가벼운 모델
기본 컨셉 코드
✔️ 메모리의 관점
a = 256
print(a == 256)
print(a is 256)
b = 257
print(b == 257)
print(b is 257)True
True
True
Falseimport sys
print(sys.getsizeof(0))
print(sys.getsizeof(1))
print(sys.getsizeof(2 ** 30 -1))
print(sys.getsizeof(2 ** 30))
print(sys.getsizeof(2 ** 60 - 1))
print(sys.getsizeof(2 ** 60))
print(sys.getsizeof(2 ** 90 - 1))
print(sys.getsizeof(2 ** 90))
print(sys.int_info)24
28
28
32
32
36
36
40
sys.int_info(bits_per_digit=30, sizeof_digit=4)reference : https://runebook.dev/ko/docs/python/library/sys
⭐️ 이러한 파이썬의 메모리를 잘 사용하면 적은 메모리를 통해서도 AI모델을 경량화 하여 동작시킬 수 있지 않을까?
✔️ Bytecode 역어셈블러
import dis
def add(a,b):
c = a + b
return c
r = add(10,20)
print(r,add.__code__.co_varnames)
print("==========")
dis.dis(add)30 ('a', 'b', 'c')
==========
3 0 LOAD_FAST 0 (a)
2 LOAD_FAST 1 (b)
4 BINARY_ADD
6 STORE_FAST 2 (c)
4 8 LOAD_FAST 2 (c)
10 RETURN_VALUEimport dis
def add(a,b):
return a + b
r = add(10,20)
print(r,add.__code__.co_varnames)
print("==========")
dis.dis(add)30 ('a', 'b')
==========
3 0 LOAD_FAST 0 (a)
2 LOAD_FAST 1 (b)
4 BINARY_ADD
6 RETURN_VALUE⭐️ 같은 동작을 하는 코드임에도 실제 동작하는 어셈블리어의 명령어 수가 차이가 난다. 이를 이용하면 AI모델을 경량화가 가능하지 않을까?
print(4 != 0 not in [1,2,3]) # T
print((4 != 0) not in [1,2,3]) # F
print(4 != 0 not in [0,1,2,3]) # F
print((4 != 0) not in [0,1,2,3]) # Fimport dis
dis.dis('4 != 0 not in [0,1,2,3]') 1 0 LOAD_CONST 0 (4)
2 LOAD_CONST 1 (0)
4 DUP_TOP
6 ROT_THREE
8 COMPARE_OP 3 (!=)
10 JUMP_IF_FALSE_OR_POP 18
12 LOAD_CONST 2 ((0, 1, 2, 3))
14 COMPARE_OP 7 (not in)
16 RETURN_VALUE
>> 18 ROT_TWO
20 POP_TOP
22 RETURN_VALUEimport dis
dis.dis('(4 != 0) not in [1,2,3]') 1 0 LOAD_CONST 0 (4)
2 LOAD_CONST 1 (0)
4 COMPARE_OP 3 (!=)
6 LOAD_CONST 2 ((1, 2, 3))
8 COMPARE_OP 7 (not in)
10 RETURN_VALUE결정
✔️ 연역적 결정 : 전제가 참이면 결론이 참

출처 : Naver BoostCamp AI Tech - edwith 강의
✔️ 귀납적 결정 : 관찰에 의한 결정(낮은 확률로 거짓일 수도 있는 것만을 감안)
- 많은 양의 데이터로부터 단순히 규칙성 등으로 보아 추론
- 데이터와 AI모델을 이용한 추론
- 데이터와 경량화된 AI모델을 이용한 추론
결정기
✔️ 세상에는 다양한 (~기)들이 존재한다. (ex - 발전기, 계산기, 결정기 등)
✔️ AI모델은 이 중에서도 결정을 내려주는 결정기 역활을 한다.
✔️ AI모델은 다양한 모델(수식구조)을 이용하여 보다 합리적인 결정을 내리도록 결정을 내도록 하게 해준다.
✔️ AI모델은 분류기 역활 또한 수행해 준다.(현재 이미지는 사람인지 동물인지 분류 등)
✔️ 도덕적 가치같은 사람또한 어떤 것이 정답인지 내리지 못하는 의사결정 문제들도 세상에는 존재한다.(결정 가능한 문제들부터 통계를 이용한 결정, 금전적인 문제, automatic한 문제, 결정할 수 없는 문제)
가벼운 결정기
✔️ 경량화 vs 소형화
- 경량화 : 물건이나 규모가 이전의 것보다 줄거나 가벼워짐
- 소형화 : 사물의 형체나 규모가 작아짐, 혹은 그렇게 함
출처 : https://dict.naver.com/search.nhn?dicQuery=%EA%B2%BD%EB%9F%89%ED%99%94&query=%EA%B2%BD%EB%9F%89%ED%99%94&target=dic&ie=utf8&query_utf=&isOnlyViewEE=
https://dict.naver.com/search.nhn?dicQuery=%EC%86%8C%ED%98%95%ED%99%94&query=%EC%86%8C%ED%98%95%ED%99%94&target=dic&ie=utf8&query_utf=&isOnlyViewEE=
✔️ 소형 모델에 들어가는 예시 기술
- TinyML
참고 자료
https://github.com/mit-han-lab/tinyml/tree/master/tinytl
https://arxiv.org/pdf/2007.10319.pdf - A scenario
참고 자료
https://www.researchgate.net/profile/George-Plastiras/publication/327265258_Edge_Intelligence_Challenges_and_Opportunities_of_Near-Sensor_Machine_Learning_Applications/links/5c084eed92851c39ebd6160e/Edge-Intelligence-Challenges-and-Opportunities-of-Near-Sensor-Machine-Learning-Applications.pdf
Backbone & dataset for model compression
⭐️ 데이터의 특징과 모델의 backbone을 잘 사용하면 모델 경량화에 대한 insight들을 얻을 수 있다.
✔️ 자주 사용되는 backbone model -> https://pytorch.org/vision/stable/models.html
왠만해서는 이러한 모델들을 많이 사용하게 되는데 이미 많이 사용되어 있을 수록 성능 비교가 비교적 더욱 쉽기 때문이다.
참고 자료
https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=8506339
✔️ Cifar10, Cifar100, ImageNet같은 다양한 데이터 셋이 존재하고 각각의 데이터 셋에 다라 모델의 수행 능력이 달라 질 수 있는 특성이 있다.
Edge device
✔️ Cloude service같은 경우에는 랜선을 타고 데이터가 이동하기 때문에 보안 이슈같은 문제가 생길 수 있고 사내 서버 같은 경우에는 보안상으로는 괜찮으나 높은 유지 비용이 들지만 Edge device같은 경우 기계 끝단에서 task가 수행되기에 일단 보안상의 문제, 가격적 측면에서의 이점, 독립적으로 수행이 되는 장점, 입력을 받고 바로 task를 수행(빠름)하는 등의 장점들이 존재한다.
Edge Inelligence
✔️ 예전에는 모든 장치들이 중앙 서버에 의해 통제를 받았다면 최근에는 Edge device들 끼리 통신 밑 여러 task들을 수행하고 중앙서버는 간혹적으로 task가 생기면 처리하는 형태로 바뀌어 가고 있다.
✔️ Edge intelligence는 크게 4가지 관점에서 바라볼 수 있다.
- Edge Training (아직 연구단계)
- Edge Offloading (엣지 단에서 처리하여 어느정도 처리하면 중앙 서버로 보냄)
- Edge Inference
- Edge Caching
참고 자료
https://arxiv.org/pdf/2003.12172.pdf
✔️ 컴퓨터 메모리 계층구조
참고 자료
https://en.wikipedia.org/wiki/Memory_hierarchy
가장 적당하게
기본 컨셉 코드
from scipy.spatial import distance
print(distance.euclidean([1,0,0], [0,1,0]))
print(distance.euclidean([1,1,0], [0,1,0]))
print(distance.hamming([1,0,0], [0,1,0]))
print(distance.hamming([1,0,0], [1,1,0]))
print(distance.hamming([1,0,0], [2,0,0]))
print(distance.hamming([1,0,0], [3,0,0]))
print(distance.cosine([1,0,0], [0,1,0]))
print(distance.cosine([100,0,0], [0,1,0]))
print(distance.cosine([1,1,0], [0,1,0]))eculidean distance - https://ko.wikipedia.org/wiki/%EC%9C%A0%ED%81%B4%EB%A6%AC%EB%93%9C_%EA%B1%B0%EB%A6%AC
hamming distance - https://www.tutorialspoint.com/what-is-hamming-distance
cosine(둘 사이 각도를 중점적으로 볼 때 사용) - https://cmry.github.io/notes/euclidean-v-cosine
⭐️ 다양한 정도를 측정하는 기술들을 이용하여 풀고자 하는 Problem에 대한 최적의 Solution들을 찾을 수 있지 않을까?
Problem, computation, decision, and optimization
✔️ 문제란?
문제란 바라는 것과 인식하는 것 간의 차이이다.
✔️ 문제 풀이의 구조
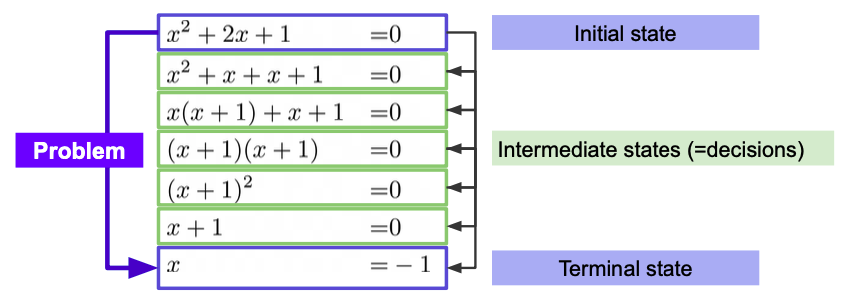
출처 : Naver BoostCamp AI Tech - edwith 강의
✔️ 문제 풀이를 위해 프로그램 내에서는 다양한 알고리즘들이 사용된다.
✔️ Computation?
참고 자료
https://en.wikipedia.org/wiki/Computation
✔️ Computation as deduction
이미 증명된 정리 혹은 프로그램으로써 이미 구현된 라이브러리를 이용하여 계산을 보다 간소화 하여 처리 할 수 있다.
✔️ ML model optimize, computers optimize
- ML model optimization
Deductive process(연역적 방법)를 사용하면서 가능한 모든 combination조합을 사용함으로써 최적의 Solution을 찾는다. - computer optimization
Inductive process(귀납적 방법)를 사용하면서 과거의 데이터를 이용함으로써 모든 combination조합을 사용하지 않으면서 가장 유망한 Solution을 찾아가는 과정이다.
참고 자료
https://en.wikipedia.org/wiki/Travelling_salesman_problem
http://www.denizyuret.com/2015/03/alec-radfords-animations-for.html
✔️ Decision problem, optimization problem
- Decision problem이란 bound가 존재를 하고 해당 조건에 맞는지에 대한 판별 여부를 따진다.
- optimization problem이란 해당 문제 조건에서 가장 최적의bound를 찾는 과정이고 이를 찾기 위해 Decision과정을 반복하여 수행을 한다.


출처 : Naver BoostCamp AI Tech - edwith 강의
Constraints
⭐️ 제약조건은 항상 정해져 있고 비용을 얼마만큼 사용할 수 있냐 판단하는 일은 모두 중요하다.(Trade off)
✔️ Decision problem, optimization problem
- Decision problem
현재 이 비용을 들이면 제약조건에 만족할 수 있는가? - optimization problem
제약조건을 만족하면서 얼마만큼의 비용을 사용할 수 있는가?
💡 Model을 얼마만큼 비용을 들여 제약조건에 만족하며 Task를 원활하게 수행 할 수 있도록 줄일 수 있는가? -> 문제를 해결하면 그만큼의 값어치 창출(<input, output>, <Initialized, Trained>에서도 동일한 개념이 적용됨)
💡Optimization
Constraints을 만족하며 얼마만큼 최소화 할 수 있는가?
참고 자료
https://en.wikipedia.org/wiki/Optimization_problem
Constraints in model compression
✔️ 최적화와 경량화
사용 기술
- (structed)Pruning
- Quantization
- Knowledge Distillation
- Filter decomposition
➡️ 해당 기술들을 사용하여 Neural network를 Decision을 통해 계속해서 Compress하면서 Optimization을 수행한다.
✔️ 생각외로 모델을 학습시키는데에는 다양한 요소의 cost들이 들어가게 된다.(이때, Goal은 Prefoemance)
다양한 요소의 cost
- Budget
- Security
- Connectivity
- Model size(ex - 앱스토어에 일정수준 크기가 커지면 제약이 많아지는 경우가 생김)
- Stability
- Adaptability
- Inference time
- Traning time
- Power consumption
- CO2 emission
참고 자료
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8506339
Reference
Naver BoostCamp AI Tech - edwith 강의
