
Object detection
✔️ Sementc segmentation
이미지를 클래스 마다 분류
✔️ Instance segmentation, Panoptic segmentation
이미지를 instance마다 분류
Instance segmentation Panoptic segmentation
✔️ object detection이란?
개체들을 구분하기 위한 기술로써(더욱 근본적인 기술) Classification + Box localization의 결합으로써 볼 수 있다.
✔️ Optical Character Recognition(OCR) : 글자 인식 기술로써 이 기술에도 Object detection이 사용이 된다.
Two-stage detecrtor(R-CNN family)
✔️ Gradient-based detector

출처 : Naver BoostCamp AI Tech - edwith 강의
➡️ (a) - 사람이 만든 알고리즘을 통해 경계선을 뽑아옴
➡️ (b), (c) - 관심문제인지 아닌지 SVM(선형분류기)를 통해 관심 문제인지 아닌지 판별
➡️ (f), (g) - feature와 크기가 같은 벡터 W를(학습을 하여) 곱해 주고 SVM(선형분류기)를 통해 사람의 형태를 가져옴
f - 사람의 경우 가져오는 형태
g - 사람이 아닌 경우 가져오는 형태
✔️ Selective search
👉 사람이나 특정 물체 뿐만 아니라 다양한 물체에 대하여 detection을 한다.
👉 비슷한 영역에 반복적으로 합쳐주는 과정을 수행
👉 합쳐진 segment들을 뽑아 box처리를 해 줌

출처 : Naver BoostCamp AI Tech - edwith 강의
비슷한 색, Gradient특징, 비슷한 분포 등으로 반복해서 합쳐주는 과정을 수행
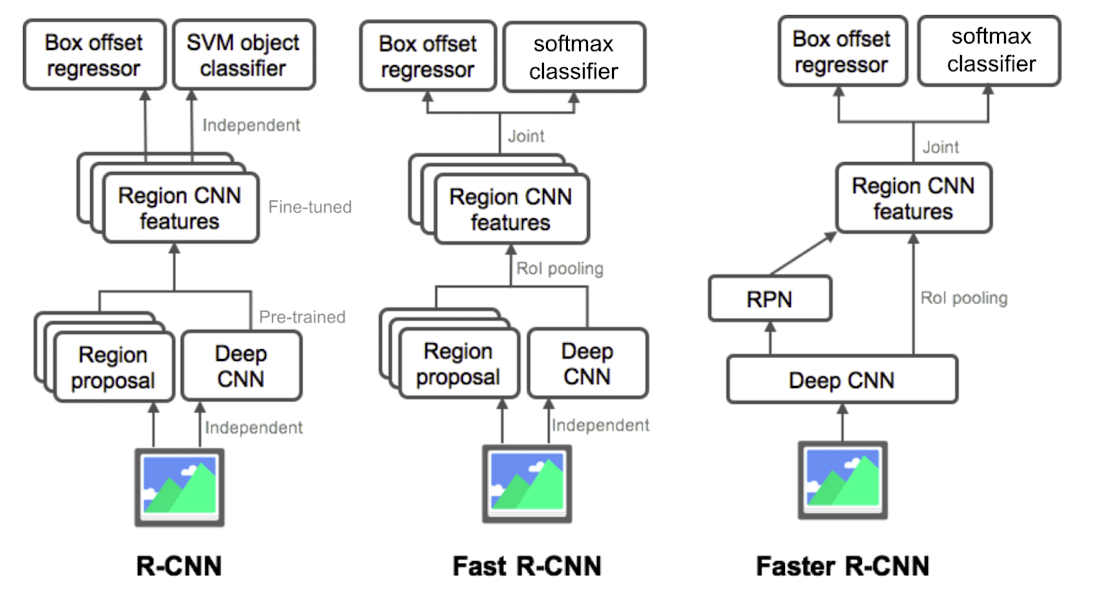
✔️ R-CNN
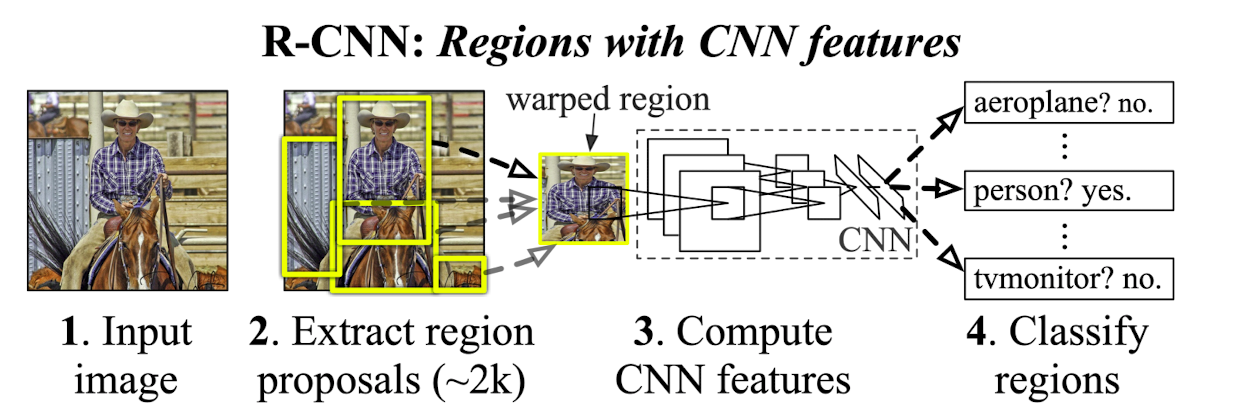
출처 : Naver BoostCamp AI Tech - edwith 강의
➡️ (2) - region proposals를 뽑아온다.
➡️ 그 이후 input으로 적절한 크기로 wraping(픽셀 위치를 옮기는 작접)을 해 준다.
➡️ (3) - pre-trained된 CNN 모델을 사용한다.
➡️ (4) - FC layer에서 추출된 feature를 기반으로 SUM<-> Linear 기반의 선형 Classifier만을 사용한다.
❗️단점
1️⃣ 각각의 region proposal마다 수행해야 함으로 속도가 느리다.
2️⃣ region proposal뽑는데(selected search) 별도 알고리즘 사용 => 학습을 통한 성능향상 한계
✔️ Fast R-CNN
👉 영상전체 feature 한번에 추출 후 재활용하여 여러 인스터스를 detection한다.
👉 한번 뽑아낸 feature를 여러번 재활용하기 위해 제한된 layer
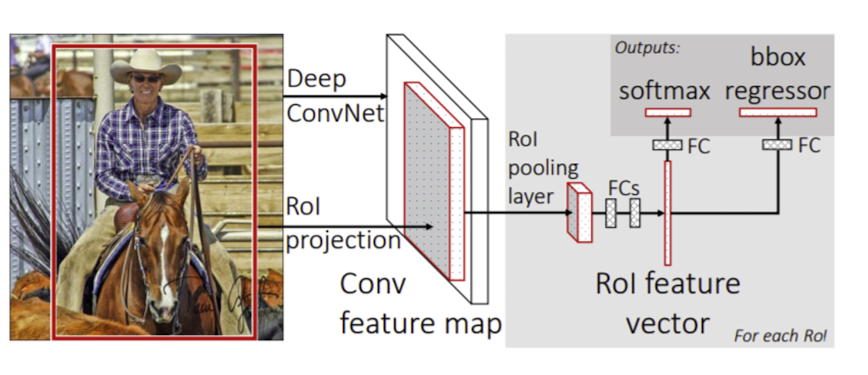
출처 : Naver BoostCamp AI Tech - edwith 강의
➡️ original image로 부터 Conv. feature map을 뽑아온다.
➡️ RoI pooling을 통하여 feature map으로부터 RoI feature map을 뽑아온다.
RoI(Region of interest) : Region proposal이 제시한 물체의 후보 위치들을 의미한다.
bounding box가 주워지게 되면 RoI에 해당하는 feature만을 추출 그리고 일정 size로 resampling
즉, fixed sized로 되게 resize해주게 한다.
➡️ 클래스와 더 정교한 bounding box를 추출하기 위해서 bound box regression과 classification을 수행한다.(3개의 layer들을 사용하여 해당 task들을 각각 수행)
✔️ Faster R-CNN
💡 IoU(intersection of union)
- neural region proposal에 의한 end-to-end object detection이다.
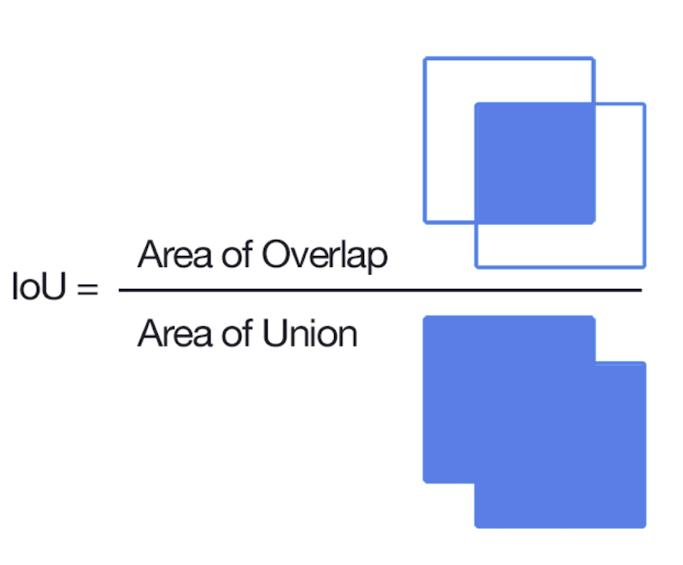
출처 : Naver BoostCamp AI Tech - edwith 강의
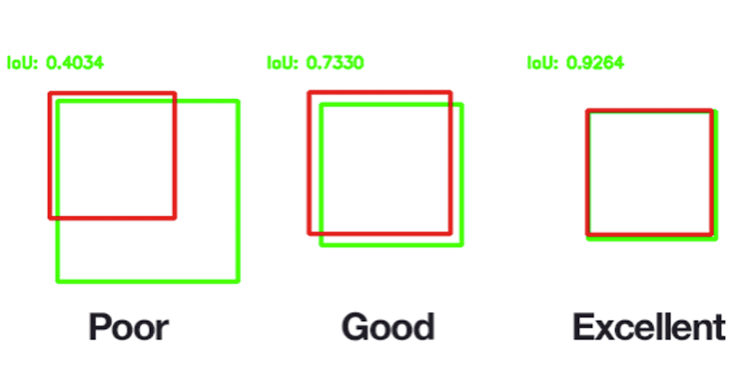
출처 : Naver BoostCamp AI Tech - edwith 강의
➡️
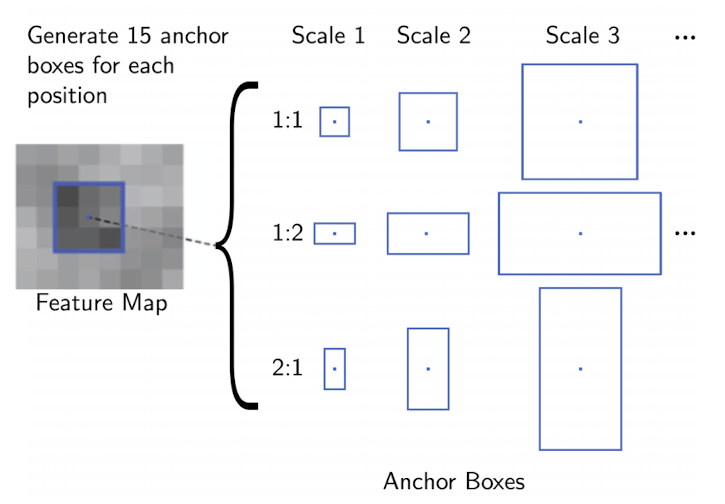
💡 Anchor boxes
-
미리 정의된 pre-define bounding boxes로써 크기와 비율에 따라 나뉘게 된다.
-
positive sample VS negative sample
IoU with ground truth > 0.7 => positive sample
IoU with ground truth < 0.3 => negative sample
➡️ negative에 따라 loss 설정하여 학습이 되도록 설정!
➡️ 학습 데이터의 bounding box와 어떻게 loss적용할지 결정하는 기준
출처 : Naver BoostCamp AI Tech - edwith 강의
출처 : Naver BoostCamp AI Tech - edwith 강의
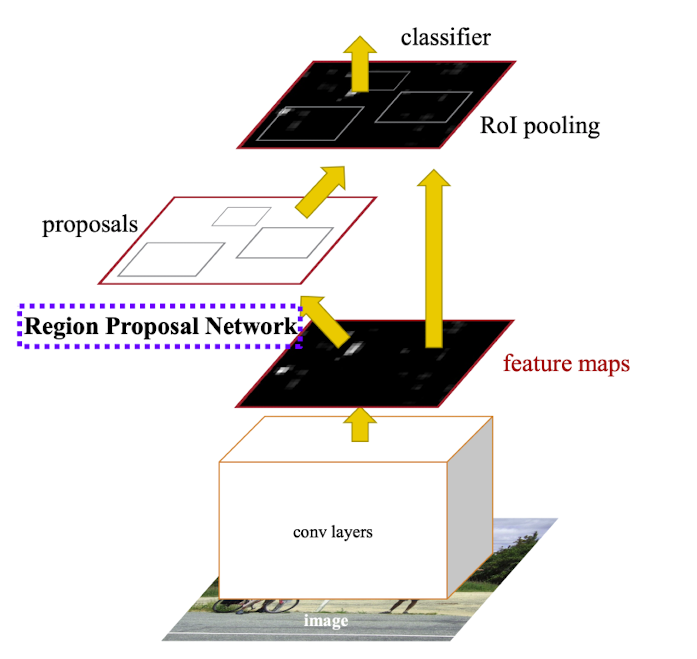
➡️ 가장 큰 특징은 Time-consuming selective search(third part의 별도 알고리즘)대신에 Resion Proposal Network(RPN)을 사용한다는 점이 차이점이다.
➡️ RPN(Region Proposal Network)모듈을 통과 후 RoI pooling을 수행 한 후 classification과 bounding box regression을 수행한다.
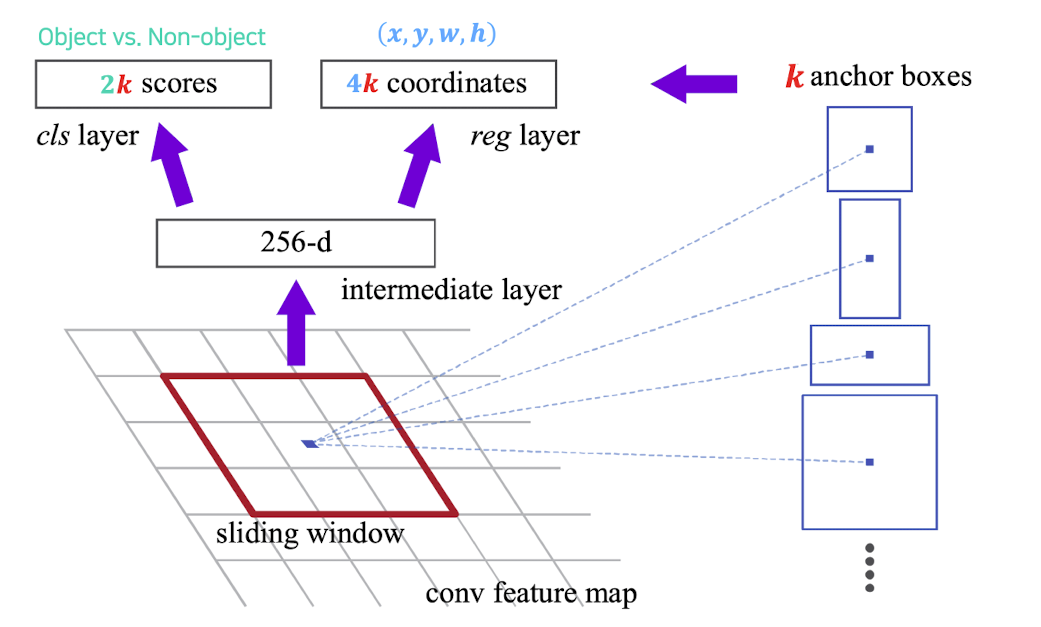
➡️ 각 위치마다(sliding window형식으로 돌면서) 256 dememsion feature vector를 추출한다.
➡️ cls layer를 거치는 부분에서는 k개 object인지 아닌지(2k scores) classification score이 나오게 되고 classification Loss(cross Entropy)를 사용한다.
➡️ reg layer부분을 보게 되면 이 부분은 k개의 bounding box의 정교한 위치를 regression하는 regression branch이다.
매 위치마다 k개의 anchor box를 고려하는데 4k인 이유는 x,y,w,h를 결정해 주기 때문이고 이미 anchor boxes있는데 크기를 다시 결정해주는 이유는 다 고려하면 시간이 오래 걸리니 대강적으로 만들고 regression을 통해 더 정교하게 만들어주기 위해서이기 때문이다.
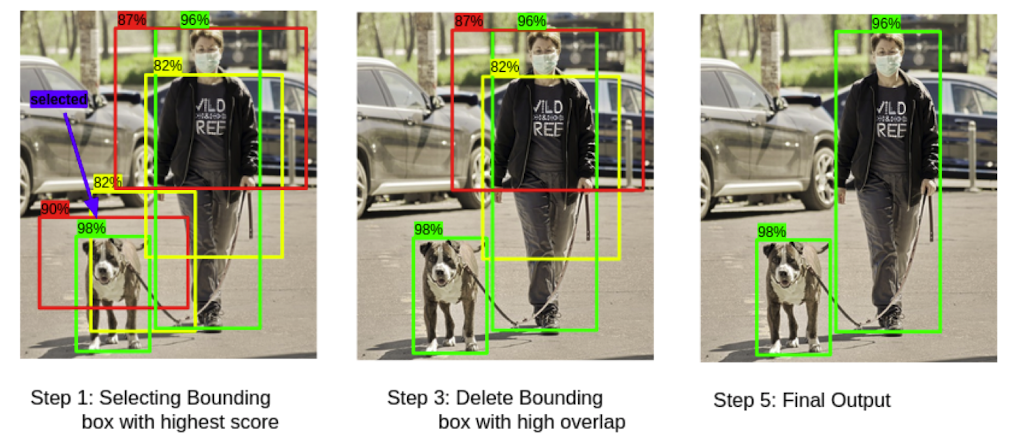
👉 Non-Maximum Suppression(NMS)
1️⃣ 가장 높은 objectiveness score를 가진 박스를 추출한다.
2️⃣ 다른 박스들과의 IoU를 비교한다.
3️⃣ 50%이하의 값을 가지는 bounding box들은 제거한다.
4️⃣ 다음 objectiveness score를 가진 박스를 추출한다.
5️⃣ 2-4정도를 반복한다.
➡️ 하수로 생성된 anchore box를 지움
출처 : Naver BoostCamp AI Tech - edwith 강의
Summary
출처 : Naver BoostCamp AI Tech - edwith 강의
⭐️ R-CNN : 딥러닝을 활용하지 않고 Region proposal에 별도 알고리즘을 사용한다. 또한 pre-trained된 Deep CNN사용
⭐️ Fast R-CNN : Resion proposal은 여전히 학습을 통해 수행되는 모델이 아니고 RoI pooling을 통해 하나의 feature로 부터 여러 물체를 탐지하도록 CNN부분을 학습한다.
⭐️ 네크워크 구조로 전체 프로세스가 end-to-end로 학습되도록 아키텍처 구성
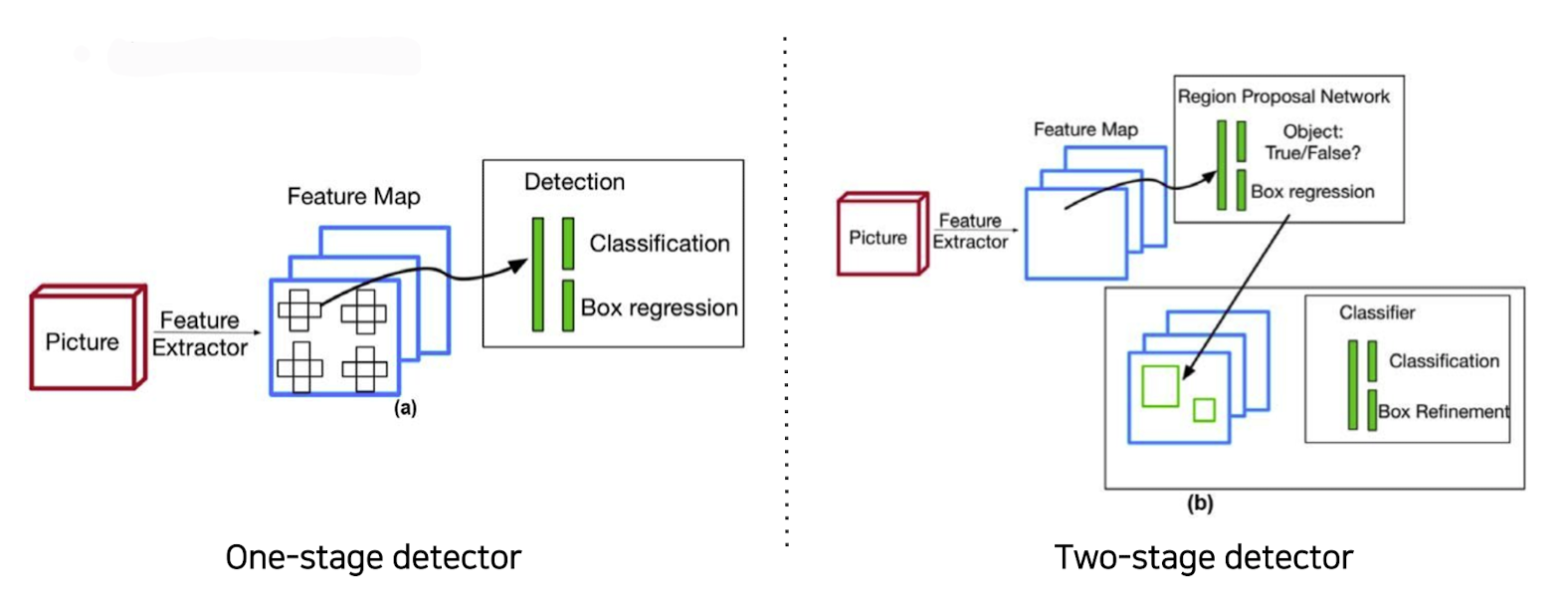
Single-stage detector
👉 One - stage는 위와 같은 two - stage에 비해 구조가 간단하고 빠른 수행속도를 가지고 있다.(단지, 정확도는 조금 떨어짐)
출처 : Naver BoostCamp AI Tech - edwith 강의
✔️ YOLO(You only look once)
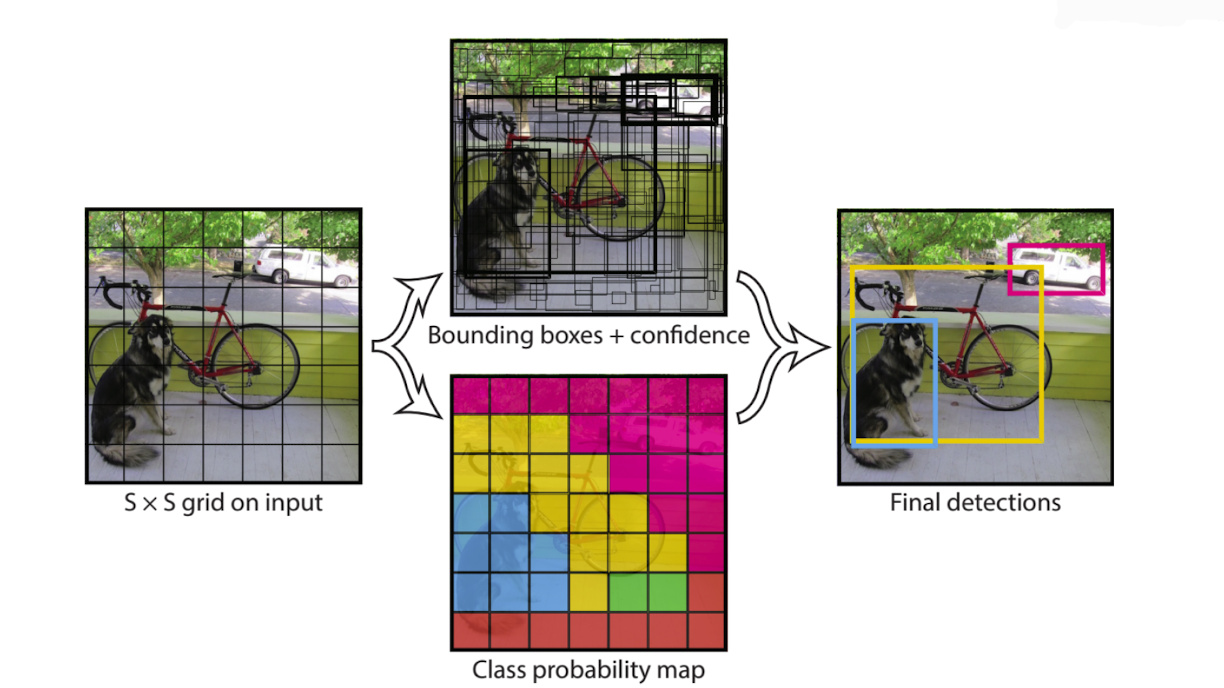
👉 각 위치마다 class score따로 예측한다.(anchor box의 4개 좌표 + confidence score<신뢰점수>) -> 미리 각 위치에 bounding box형태로 개 정해놓고 더 정교한 box로 Regression하는 부분도 포함한다.
👉 최종결과는 이전과 마찬가지로 non-maximal surficient algorithm을 사용하여 정의된 bounding box를 출력한다.
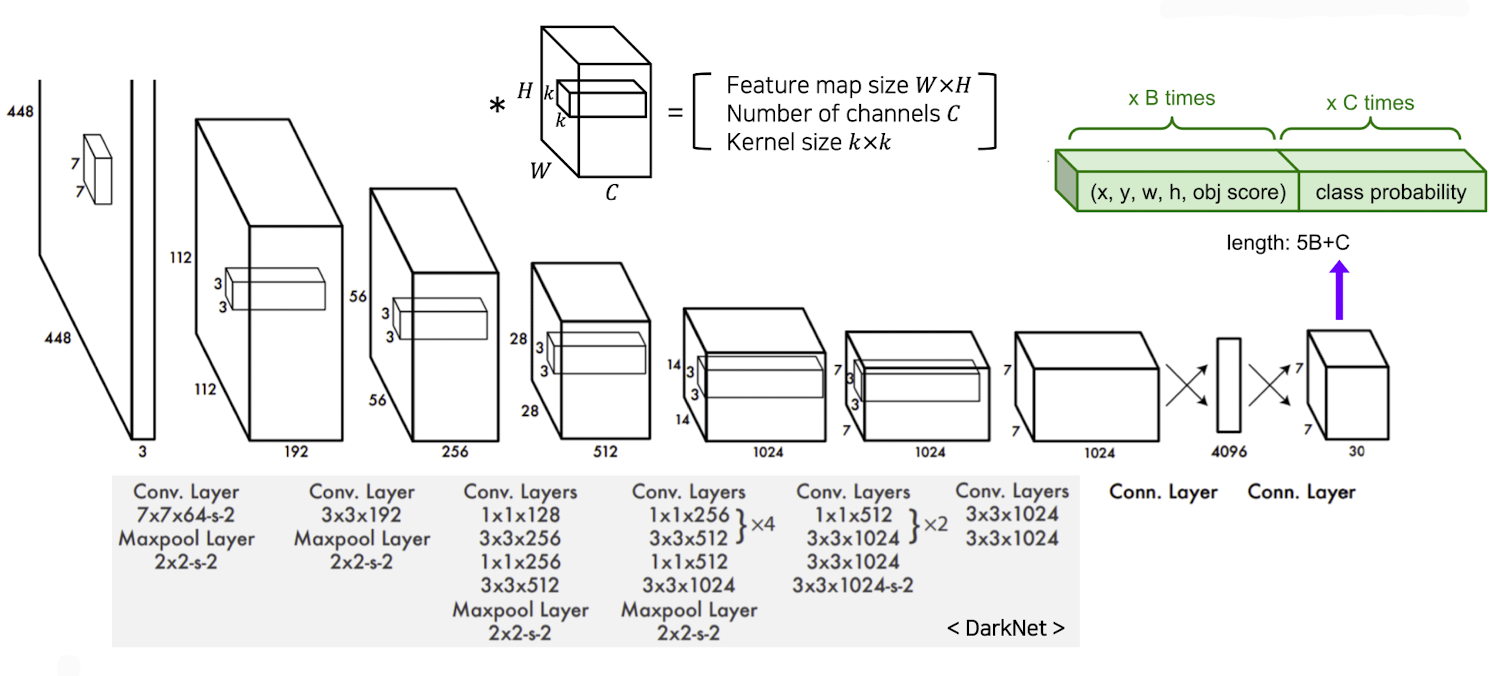
출처 : Naver BoostCamp AI Tech - edwith 강의
➡️ FC를 거치기 전 부분을 보게 되면 grid를 S X S로 나눈다고 하였는데 이 경우는 7이고 이는 마지막 부분의 해상도라고 생각하면 된다.
➡️ 채널을 30개로 해 주는 이유는 여기에는 bounding box를 사용한 case는 2개이고 클래스는 20개의 object class를 고려해 주웠기 때문에 이를 합치면 이다.(위의 그림 초록색 부분 참조)
⭐️ real time 알고리즘에서 앞도적인 성능을 보여주고 있고 two - stage보다 조금 성능이 낮지만 훨씬 빠른 결과를 낸다.
✔️ SSD(Single shot multibox detector)
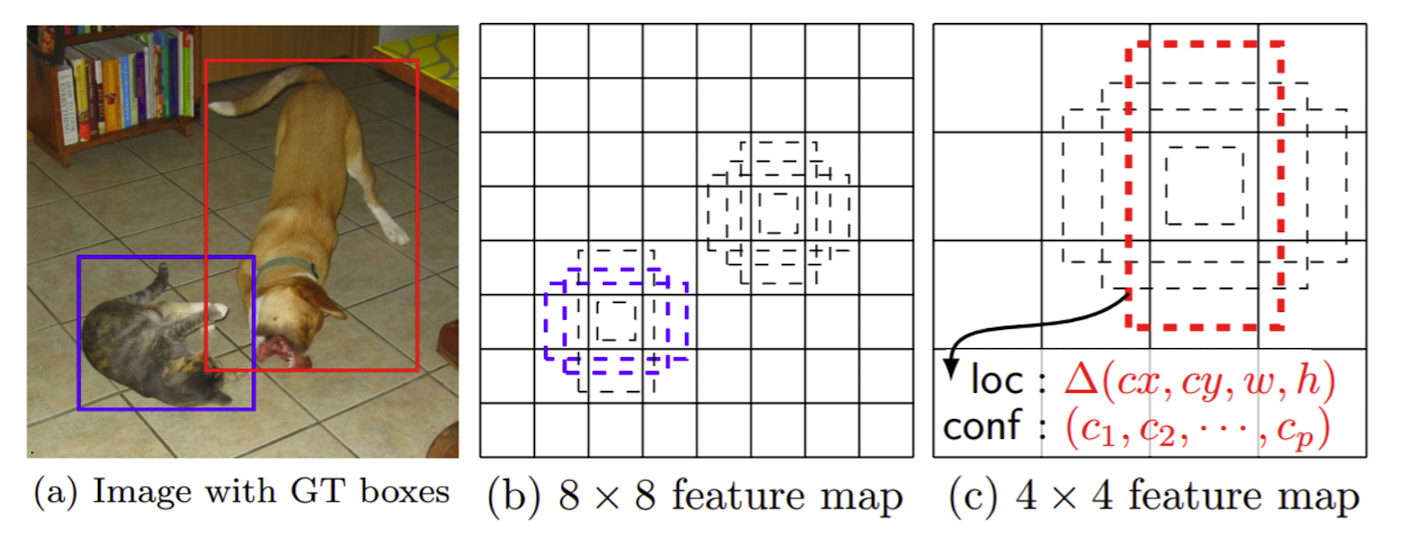
출처 : Naver BoostCamp AI Tech - edwith 강의
➡️ YOLO는 맨 마직막 layer에서 한번만 prediction하기 때문에 localization정확도가 조금 떨어지는 결과를 보여주웠는데 이를 개선하고자 나온 방법이 SSD이다.
➡️ multi scale object를 더 잘 처리하기 위해 나타난 기법이다.
➡️ feature map에 크기에 따라 bounding box의 크기가 변동되면서 고려되도록 설계 => 해상도에 맞게 조절이 가능
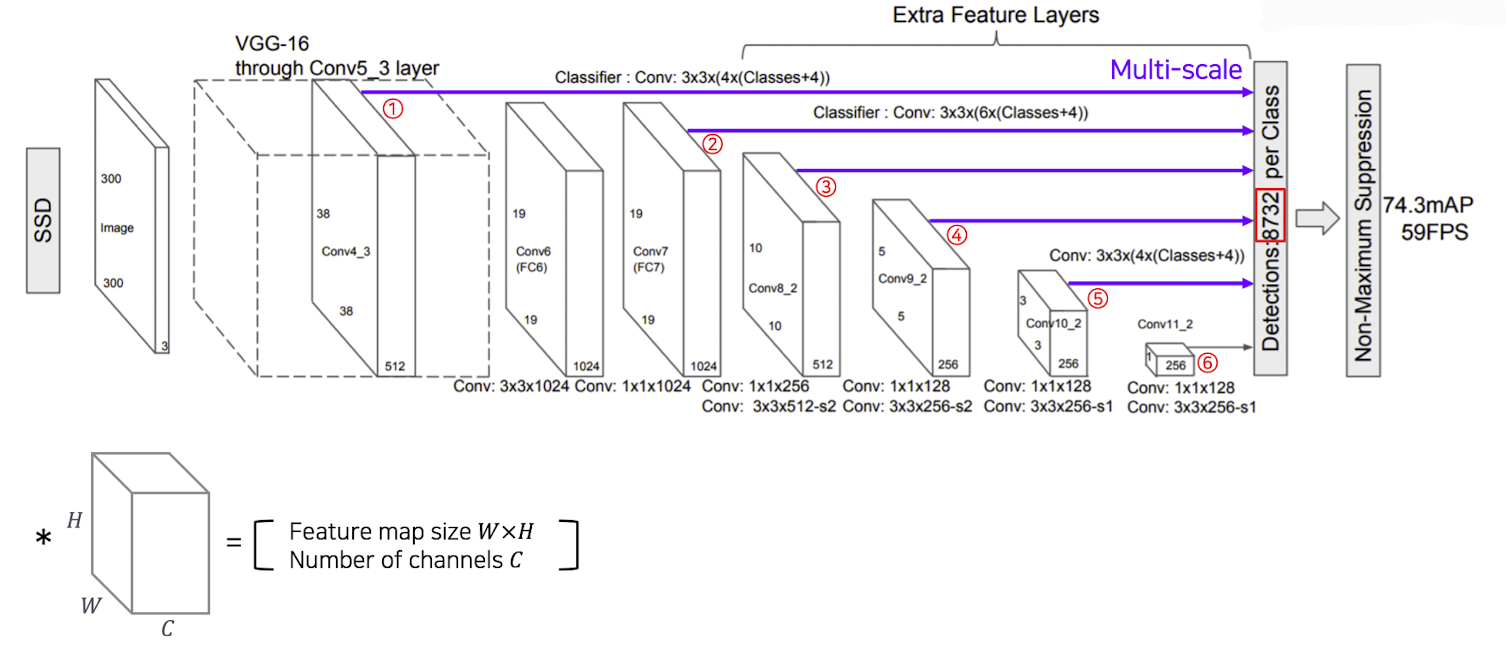
출처 : Naver BoostCamp AI Tech - edwith 강의
➡️ 1 ~ 6을 보게 되면 각 scale마다 object detection결과를 출력하도록 설정을 하여 다양한 scale의 object들에 대하여 더 잘 대응할 수 있도록 설계를 하였다.
➡️ 각 Scale마다 object detection을 수행하도록 해 주고 화살표 끝 부분의 의미는 classifier를 수행했다고 보면 된다.
Classifier부분을 보게 되면 Conv 3 x 3 x(anchor box의 수 x (클래스 수 + 좌표 표현의 수<4>))의 수로 구성이 되어 있다.
❗️ 이때, 끝 부분에 8732라는 숫자는 anchor box의 총 갯수를 의미하고 다음과 같이 계산이 가능하다.

출처 : Naver BoostCamp AI Tech - edwith 강의
이때, 많은 수의 anchor box들이 존재해도 모델이 간단하여 높은 성능을 보여주게 된다.
⭐️ YOLO보다 높은 속도와 높은 성능을 보여주게 된다.<논문에서는 크기가 다른 input을 넣어 이 점은 고려를 해 주워야 한다.>
Single-stage detector vs two-stage detector
👉 Single-stage detector 은 많은 negative example들(negative한 anchor box들)을 사용하는 문제점을 가지고 있다.
👉 이를 해결하기 위해 Focal loss, RetinaNet등이 사용이 된다.
💡 Focal loss
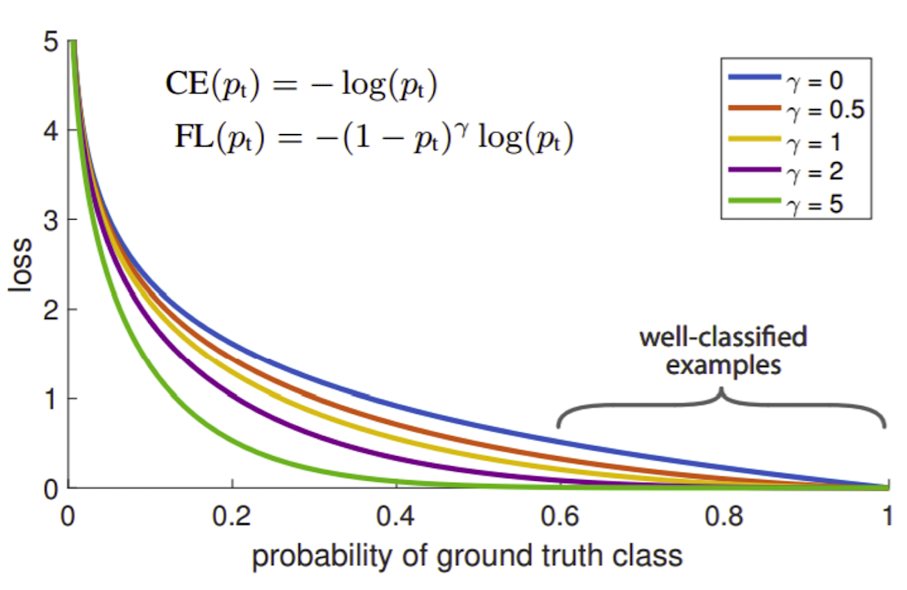
출처 : Naver BoostCamp AI Tech - edwith 강의
➡️ Cross Entropy를 사용하고 에 따라 function의 shape을 정해준다.
➡️ 잘 맞추는 경우는 더 smooth한 loss를 주고 반대로 맞추지 못하면 더 sharp한 loss를 준다. => 가 클수록 좀 더 sharp하게 변한다.
➡️ 정답에 가까운 gradient는 거의 무시가 되고(gradient거의 발생하지 않음) sharp한 gradient가 발생하는 부분들이 큰 영향을 발휘한다.
➡️ 어렵고 잘못 판별된 예제들에 대해서는 더 강한 rate를 주고 쉬운 얘들에 대해서는 작은 rate를 주워 학습하게끔 해 준다.
💡 RetinaNet
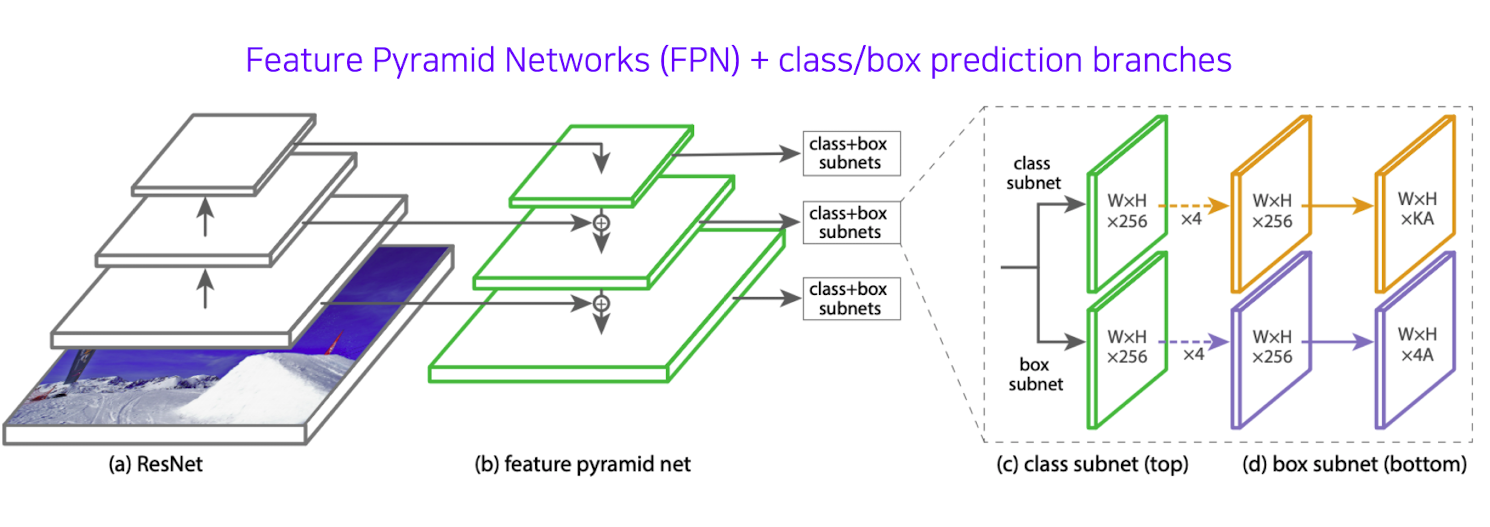
출처 : Naver BoostCamp AI Tech - edwith 강의
➡️ U NET의 특징과 비슷한 특징을 가짐
➡️ low level feature와 high level feature들을 (b)에서 덧셈으로써 합쳐준다.
➡️ class subnet과 box subnet을 보게 되면 class head와 box head가 따로 구성되어 있음을 볼 수 있고 Classification과 box Regression<박스 위치를 교정>이 각 위치마다 dense하게 각 위치마다 수행이 되는 것을 확인 할 수 있다.
⭐️ RetinaNet의 성능을 보게 되면 YOLO, SSD보다 속도가 비슷하며 높은 성능을 내는 것을 확인 할 수 있다.
Detectiion with Transformer
👉 Transformer는 NLP에서 좋은 성능을 보여 주웠는데 이를 vision에서 보여 줄 수는 없을까 해서 많은 변형된 모델들이 나오게 되었다.
👉 종류
- ViT(Vision Transformer) bt Google
- Deit(Data-efficient image tansformer) by Facebook
- DERT(DEtection TRansformer) by Facebook
✔️DERT(DEtection TRansformer)
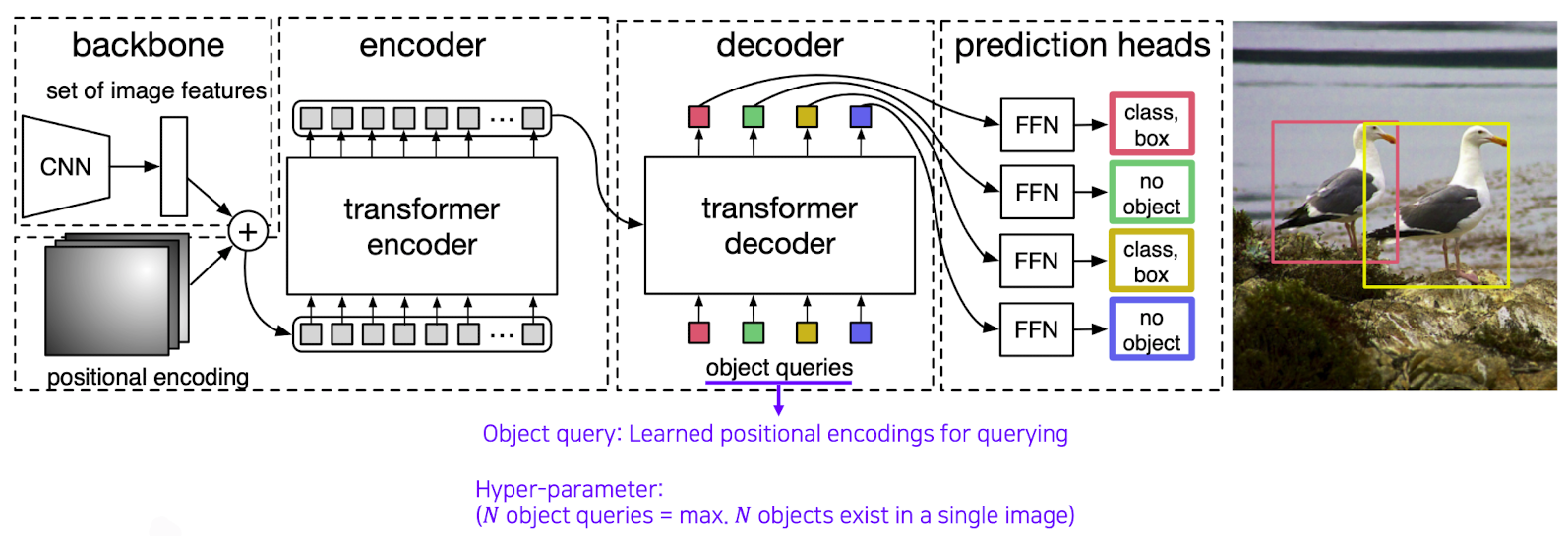
출처 : Naver BoostCamp AI Tech - edwith 강의
➡️ backbone을 통하여 입력 토큰을 생성 후 object queries에 이 위치에 해당하는 object가 무었인지 질의를 넣은 후(이때, 질의를 무작정 넣어주는 것이 아닌 하나의 이미지에서 최대N개의 위치에서 object detection 가능하다고 미리 정해주고 시작을 한다.)어떤 Object가 있느냐 정보가 파싱되어 나오게 된다.
💡 이 외에 추가적으로 물제의 중심점을 기준으로 bounding box를 생성하는 기법들도 나오고 있다. => CornerNet/CenterNet
Reference
Naver BoostCamp AI Tech - edwith 강의
