
이번 포스팅에서는 구조화된 데이터의 처리를 지원하는 라이브러리인 pandas에 대한 내용을 이어서 정리해 보았습니다.
pandas 사용법 및 특징
groupby
data = {
"col1": [
"one",
"one",
"one",
"two",
"two",
"two",
"two",
"three",
"three",
"three",
"four",
"four",
],
"col2": [1, 2, 2, 3, 3, 4, 2, 1, 1, 4, 3, 3],
"col3": [100,300,300,200,400,100,200,300,400,100,200,300],
"col4": [1000,2000,3000,4000,1000,2000,3000,4000,1000,2000,3000,4000],
}
df = pd.DataFrame(data)
#series로 데이터를 가져와 집계함수 사용이 가능
df.groupby('col1')["col4"].std()
df.groupby('col1')["col4"].sum()
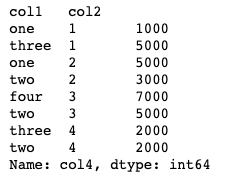
df.groupby(['col1','col2'])["col4"].sum()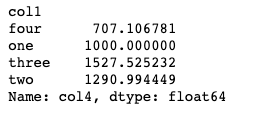

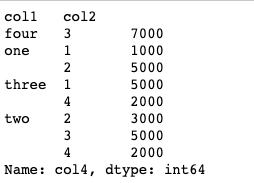
- 다양한 형태로써의 전환
hierarchical_index = df.groupby(['col1','col2'])["col4"].sum()
hierarchical_index.index # 인덱스를 보여줌
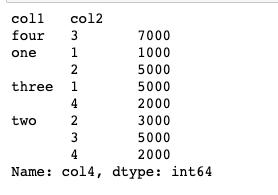
hierarchical_index.unstack() #matrix형태로 풀어서 보여줌
hierarchical_index.unstack().stack()
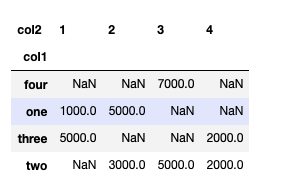
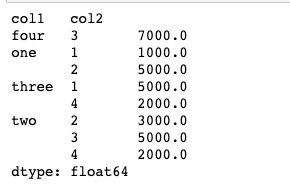
- 그룹의 level다루기
hierarchical_index.reset_index() #인덱스 붙혀서 보여줌(반환값으로 리턴)
hierarchical_index.swaplevel() #그룹 지어지는 순서가 바뀜(col2 -> col1)
hierarchical_index.sort_index(level=1) #level1를 기준으로 sorting해줌
hierarchical_index.sort_index(level=0) #level0를 기준으로 sorting해줌
hierarchical_index.sort_values() #결과물을 기준으로 정렬
#Series결과 => 집계함수 사용 가능
print(type(hierarchical_index))
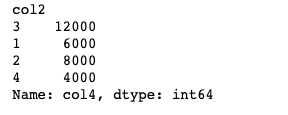
hierarchical_index.sum(level = 1)
hierarchical_index.sum(level = 0)




groupby2
- groupby객체 데이터 접근
data = {
"col1": [
"one",
"one",
"one",
"two",
"two",
"two",
"two",
"three",
"three",
"three",
"four",
"four",
],
"col2": [1, 2, 2, 3, 3, 4, 2, 1, 1, 4, 3, 3],
"col3": [100,300,300,200,400,100,200,300,400,100,200,300],
"col4": [1000,2000,3000,4000,1000,2000,3000,4000,1000,2000,3000,4000],
}
df = pd.DataFrame(data)
grouped = df.groupby("col1")
for k,v in grouped:
print(k)
print("==========")
print(v)# 타입은 데이터프레임
print("==========")
- groupby객체를 사용하는 다양한 방법
grouped.get_group('one') #특정 그룹을 받아옴
# aggregation : 요약된 통계정보를 추출해 줌
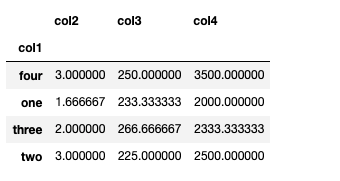
grouped.agg(sum)
grouped.agg(np.mean)
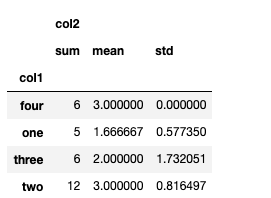
grouped[['col1','col2']].agg([np.sum, np.mean, np.std])
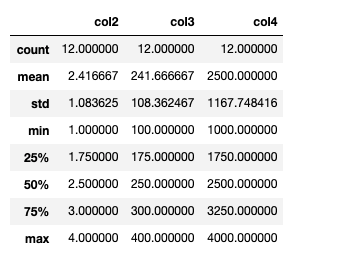
df.describe()
#transpose로 정보를 보기 편하게
#grouped.describe().T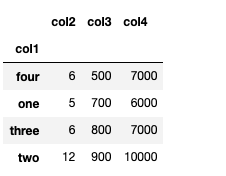
# transformation : 해당 정보를 변환해줌
for k,v in grouped:
print(k)
print("==========")
print(v)# 타입은 데이터프레임
print("==========")
score = lambda x : (x.max())
grouped.transform(score) #해당되는 그룹의 각각의 원소마다 동일한 값을 부여하는 형태
#데이터정규화
#score = lambda x : (x - x.mean()) / x.std()
#grouped.transform(score)

# filtration : 특정 정보를 제거하여 보여주는 필터링 기능
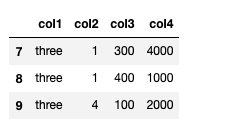
df.groupby('col1').filter(lambda x: len(x) >= 3) #집단의 데이터가 3개 이상인 것들
df.groupby("col1").filter(lambda x: x["col3"].mean() > 250)
case study
- dateutil을 사용한 DataFrame 데이터의 변형 및 활용
!wget https://www.shanelynn.ie/wp-content/uploads/2015/06/phone_data.csv출처
https://www.shanelynn.ie/wp-content/uploads/2015/06/phone_data.csv
df_phone = pd.read_csv("./phone_data.csv")
df_phone.head()
#dateutil.parser.parse: 문자열 형태를 날짜형으로 바꿔줌
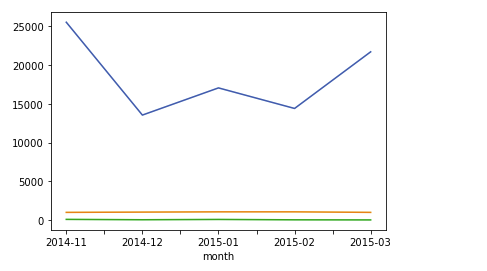
df_phone["date"] = df_phone["date"].apply(dateutil.parser.parse, dayfirst=True)_phone[df_phone["item"] == "call"].groupby("month")["duration"].sum().plot()
df_phone[df_phone["item"] == "data"].groupby("month")["duration"].sum().plot()
df_phone[df_phone["item"] == "sms"].groupby("month")["duration"].sum().plot()
# 데이터의 갯수를 가져옴
df_phone.groupby(["month","item"])["duration"].count()
df_phone.groupby(["month","item"])["duration"].count().unstack()
df_phone.groupby(["month","item"])["duration"].count().unstack().plot()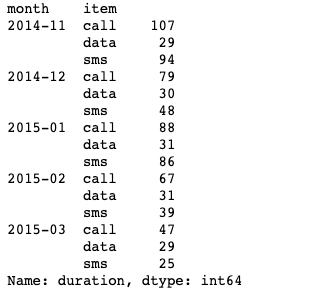


# as_index : 인덱스를 새롭게 생성
df_phone.groupby("month",as_index = False).agg({"duration" : "sum"})
- 집계함수의 다양한 적용방법
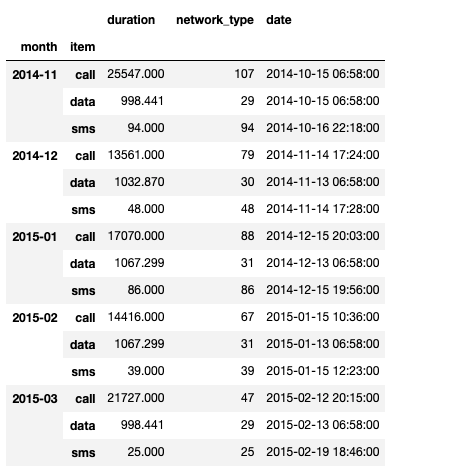
df_phone.groupby(["month", "item"]).agg(
{
"duration": sum,
"network_type": "count",
"date": "first",
}
) 
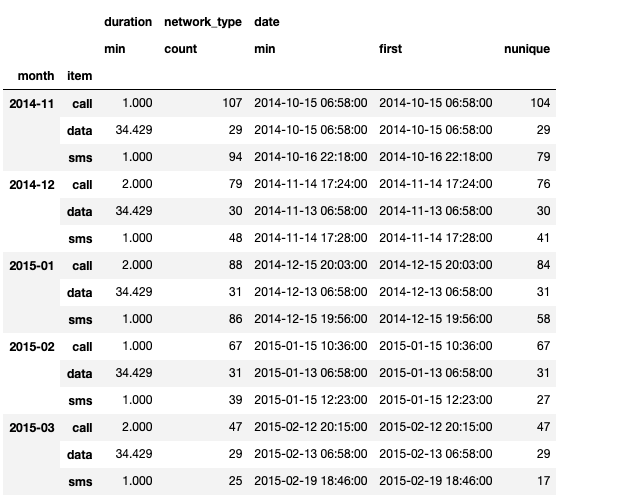
df_phone.groupby(["month", "item"]).agg(
{
"duration": [min],
"network_type": "count",
"date": [min, "first", "nunique"],
}
) 
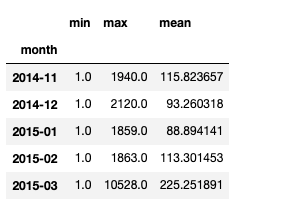
grouped = df_phone.groupby("month").agg({"duration": [min, max, np.mean]})
grouped.columns = grouped.columns.droplevel(level=0) # 열의 이름 중 level1을 없앰
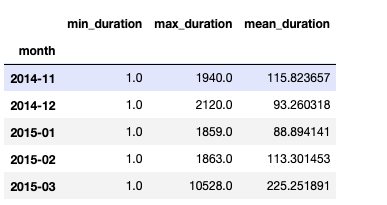
# 컬럼 이름 재지정
grouped.rename(
columns={"min": "min_duration", "max": "max_duration", "mean": "mean_duration"}
)
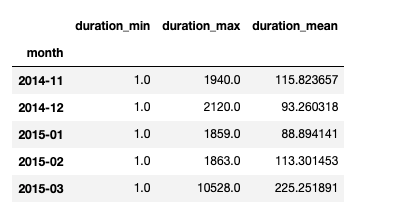
# 컬럼 이름 접두어 생성
grouped.add_prefix("duration_")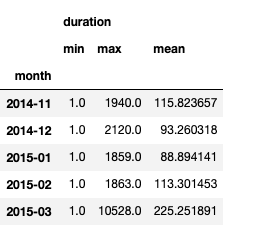
pivot table, crosstab
- pivot table
엑셀의 형태와 동일
dataframe을 이용하여 생성
집계함수에 대한 결과를 효과적으로 표현
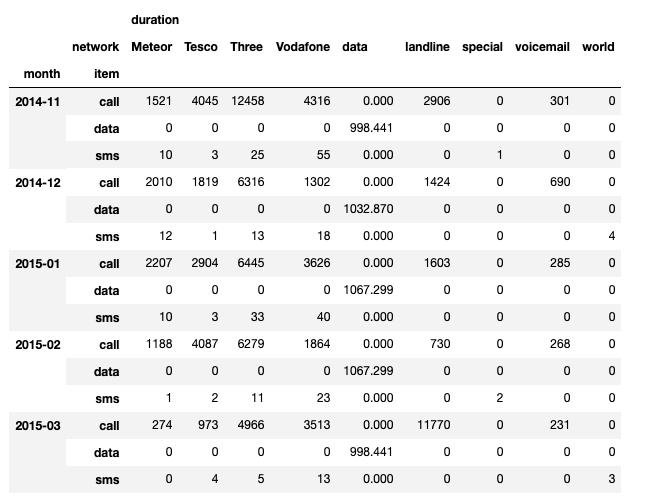
df_phone.pivot_table(
values=["duration"],
index=[df_phone.month, df_phone.item],
columns=df_phone.network,
aggfunc="sum",
fill_value=0,
)
#groupby를 이요해서도 pivot table같이 표현 가능
df_phone.groupby(["month","item","network"])["duration"].sum().unstack()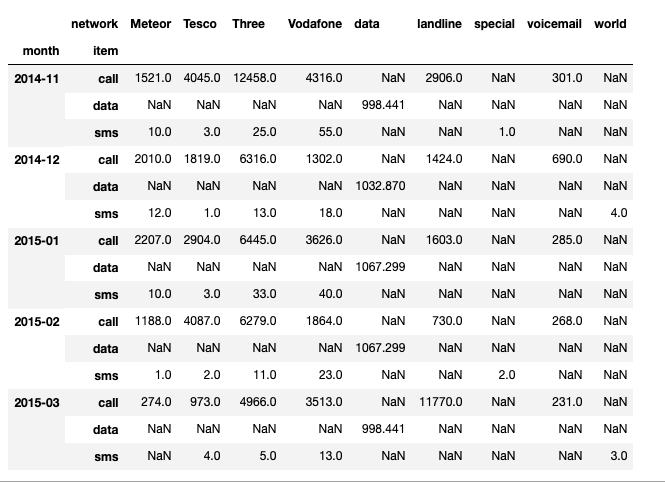
- crosstab
두 컬럼에 교차 빈호, 비율, 덧셈 등을 구할 때 사용
pivot table의 특수한 형태
pd.crosstab(
index = [df_phone.month, df_phone.item],
columns = df_phone.network,
values = df_phone.duration,
aggfunc = "sum"
).fillna(0)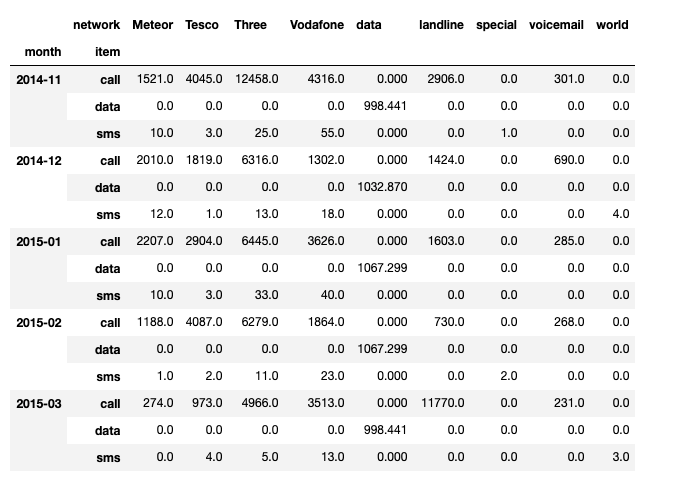
df_phone.month # 시리즈로 빼오기
merge & concat
- merge : 특정한 컬럼을 기준으로 데이터를 합침
- concat : 데이터를 이어 붙힘
raw_data = {
"subject_id": ["1", "2", "3", "4", "5", "7", "8", "9", "10", "11"],
"test_score": ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'],
}
df_a = pd.DataFrame(raw_data, columns=["subject_id", "test_score"])
raw_data = {
"subject_id": ["4", "5", "6", "7", "8"],
"first": ["f1", "f2", "f3", "f4", "f5"],
"last": ["l1", "l2", "l3", "l4", "l5"],
}
df_b = pd.DataFrame(raw_data, columns=["subject_id", "first", "last"])
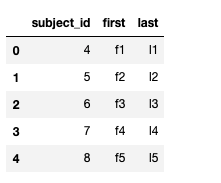
pd.merge(df_a,df_b,left_on = 'subject_id',right_on = 'subject_id') # inner join
pd.merge(df_a, df_b, on="subject_id") # inner join
pd.merge(df_a, df_b, right_index=True, left_index=True) # inner join(양쪽 공통 컬럼 삭제하지 않기)
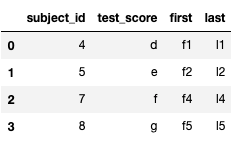
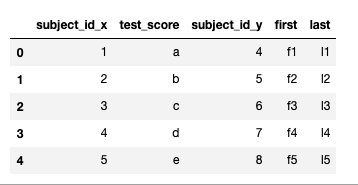
#left outer join
pd.merge(df_a, df_b, on="subject_id", how="left")
#right outer join
pd.merge(df_a, df_b, on="subject_id", how="right")
#outer join
pd.merge(df_a, df_b, on="subject_id", how="outer")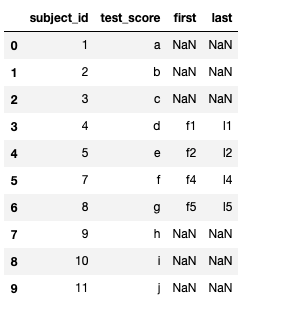

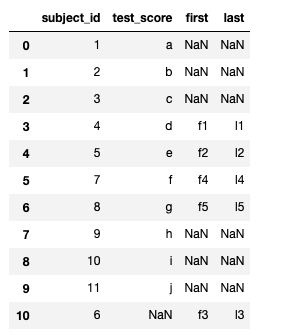
raw_data = {
"subject_id": ["4", "5", "6", "7", "8"],
"first": ["f1", "f2", "f3", "f4", "f5"],
"last": ["l1", "l2", "l3", "l4", "l5"],
}
df_a = pd.DataFrame(raw_data, columns=["subject_id", "first", "last"])
raw_data = {
"subject_id": ["1", "2", "3", "4", "5"],
"first": ["f1", "f2", "f3", "f4", "f5"],
"last": ["l1", "l2", "l3", "l4", "l5"],
}
df_b = pd.DataFrame(raw_data, columns=["subject_id", "first", "last"])

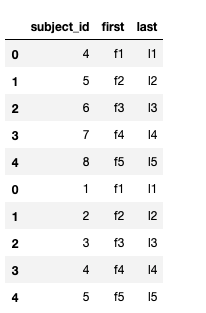
df_new = pd.concat([df_a, df_b]) #행이 추가됨
df_new.reset_index(drop = True)
df_a.append(df_b) #인덱스가 그대로 붙어짐(결과 참고)
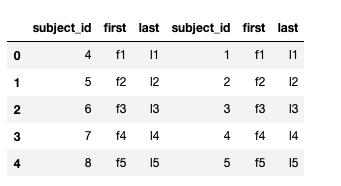
df_new = pd.concat([df_a, df_b], axis=1) # 옆으로 붙음
df_new.reset_index(drop = True)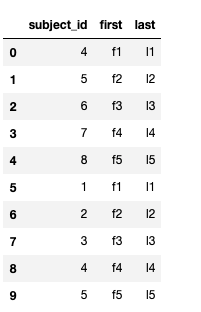
persistence
- DB를 이용한 dbconnection 기능
- excel 혹은 pickle을 이용한 객체의 저장
import sqlite3
conn = sqlite3.connect("./flights.db")
cur = conn.cursor()
cur.execute("select * from airlines limit 5;")
results = cur.fetchall() #데이터를 가져옴
#Data Frame으로 불러오기
df_airplines = pd.read_sql_query("select * from airlines;", conn)
df_airplines
# 엑셀 파일의 사용
# DataFrame의 엑셀 추출 코드
# Xls 엔진으로 openpyxls 또는 XlsxWrite사용
# openpyxl, XlsxWriter설치해야 함
import openpyxl
df = pd.DataFrame([[11, 21, 31], [12, 22, 32], [31, 32, 33]],
index=['one', 'two', 'three'], columns=['a', 'b', 'c'])
#방법1
with pd.ExcelWriter('./test.xlsx',engine="xlsxwriter") as writer:
df.to_excel(writer, sheet_name="Sheet1")
#방법2
writer = pd.ExcelWriter('./test.xlsx', engine='xlsxwriter')
df.to_excel(writer, sheet_name='Sheet1')
writer.close()
#pickle파일로 저장
df_routes.to_pickle("./test.pickle")이 외의 방법들은 docs를 참고하자
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.ExcelWriter.html
Reference
Naver BoostCamp AI Tech - edwith 강의
https://m.blog.naver.com/PostView.nhn?blogId=acornedu&logNo=220934409189&proxyReferer=https:%2F%2Fwww.google.com%2F

한걸음씩 꾸준히