추상화 없는 메모리 관리
1.개념
추상화가 없다는 뜻은 생각한 그대로 동작하는 것이라 생각한다. 그렇다면 추상화 없는 메모리 관리는 무엇일까?
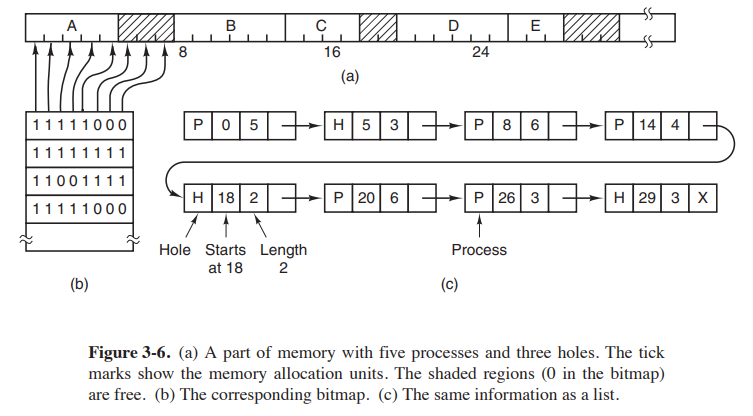
아래의 그림을 살펴보자
(a)는 과거에 메인프레임, 미니컴퓨터에 사용
(b)는 palmtop, 혹은 임베디드 시스템에서 사용되었음
(c)는 초기 세대의 PC(MS-DOS 구동하는 PC)등에서 사용됨
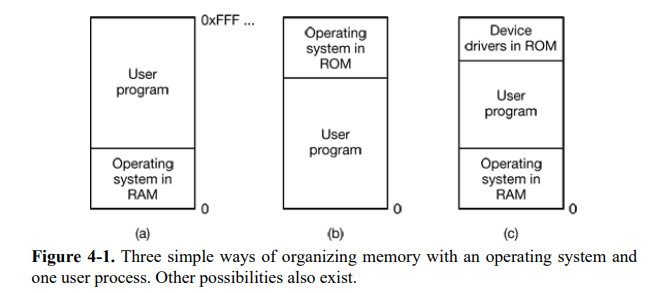
이런 방식으로 메모리를 관리하면 한 번에 하나의 프로그램만 실행할 수 있다는 문제점이 있다.
IBM 360에서 위의 문제를 해결한 방법을 알아보자.
- 메모리는 2KB의 블록들로 분할한다.
- 각 블록은 4bit 보호키가 있음
- 각 보호키는 CPU의 전용 레지스터에 저장
- PSW(Program Status Word)에 실행중인 프로그램의 보호키를 저장
- 현재 PSW와 블록의 보호키가 맞으면 접근
- 아니면 trap
- PSW는 OS만이 변경가능
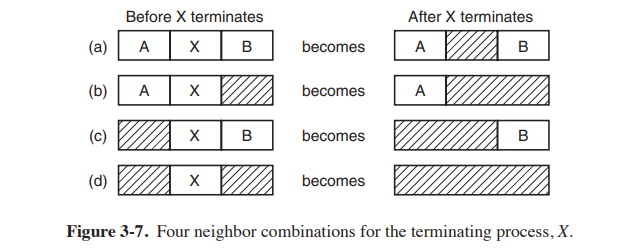
이렇게 동시에 여러 프로그램을 메모리에 올릴 수 있게 되었지만 모든 문제가 해결되지는 않았다. 여러 프로그램을 메모리에 올릴 때 어떻게 배치를 할지 애매한 부분이 있다. 그림을 통해 살펴보자
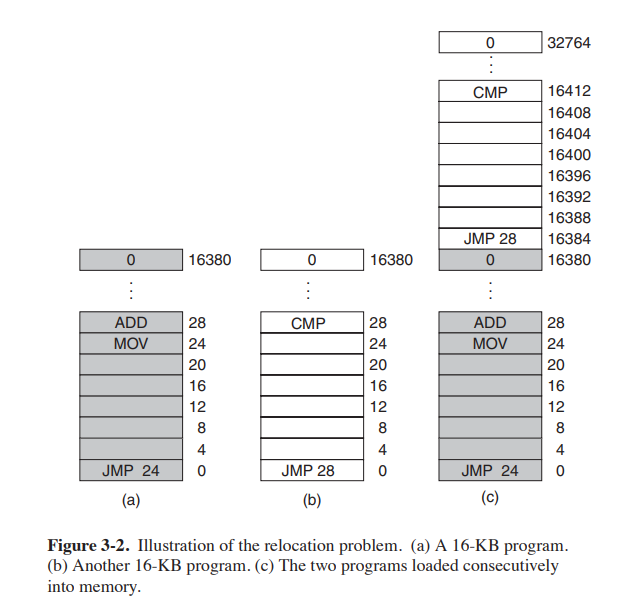
(a) 프로그램과 (b)프로그램을 동시에 메모리에 올려서 (C)의 형태가 되었다. 16KB 프로그램2개를 하나로 합친 모양이고 간단하다. 하지만 내부의 명령어 중에서 JUMP 28이 문제가 된다. (b)에서 JUMP 28는 문제가 되지 않지만 (c)에서 JUMP 28는 다른 프로그램의 영역으로 점프한다.
이 역시 IBM 360에서 static relocation이라는 방법으로 해결했다.
- 프로그램이 16384에 적재되면, 모든 주소에 16384를 더하는 것으로 해결
2.단점
- 물리적인 한계
- 프로그램이 메모리의 크기보다 크면 실행 불가
- swap이 어려움
- 페이징에 따라서 단편화 심해짐
메모리 추상화와 메모리 관리
1.주소공간 (Address space)
주소공간은 프로세스가 사용할 수 있는 모든 주소들의 집합을 말한다. 여기서 주소들은 실제 물리적 주소가 아니라 물리적 주소에 대응되는 임의의 주소이다.
각 프로세스는 각자의 주소공간을 가지기 때문에 위의 그림에서 나타난 문제가 발생하지 않는다. 그렇다면 JUMP 28을 어떻게 해결한 것일까
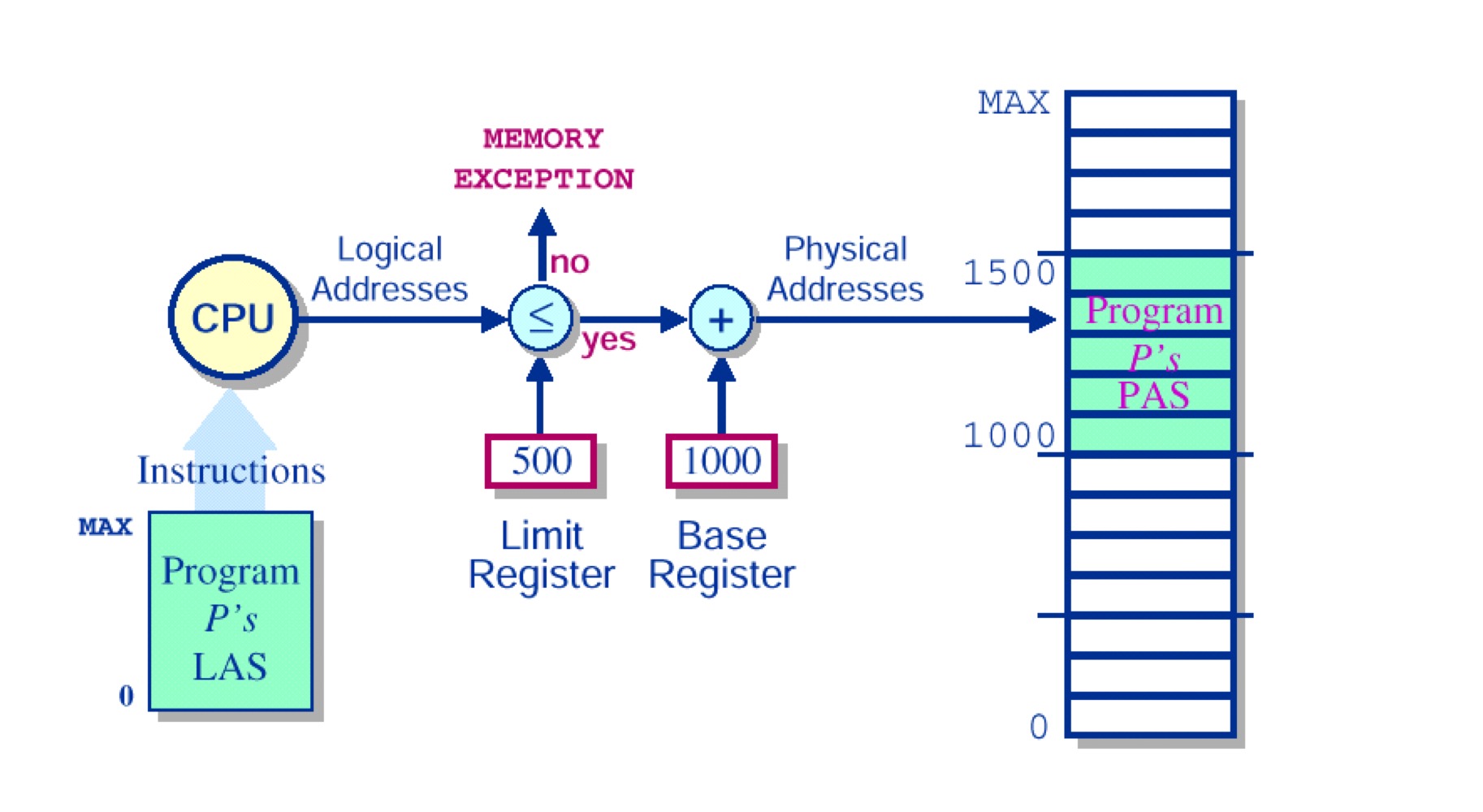
2.Base and Limit
Dynamic Relocation의 간단한 구현이다. 프로그램의 주소공간을 실제 물리 메모리에 매핑시키는 역할을 한다.
base: 프로세스의 시작 물리주소
limit: 주소공간의 크기
위 그림에서 프로세스의 논리주소 0에 접근하고 싶으면 CPU에서 Base를 더해서 실제 주소로 연결된다. 또한 limit을 통해서 메모리 보호의 기능도 한다.
(프로세스들의 base/limit값은 PCB에 저장되어 있다가 문맥 전환 시 CPU 레지스터에 저장)
장점
- 메모리 어디에나 프로그램을 올릴 수 있음
- 프로세스가 다른 프로세스의 영역에 침범 하는 것을 막아줌
- 문맥교환 시 base/limit 값만 바꿔주면 됨
단점 - 프로그램이 연속된 물리 메모리를 차지해야 함
- 프로그램이 물리 메모리보다 크면 실행 불가
3.Swap
Dynamic Relocation을 통해서 프로그램이 어떤 물리 주소에 올라가도 실행될 수 있게 됨. 이를 기반으로 OS는 현재 CPU를 차지하지 않는 프로세스를 메모리 -> Disk 반대의 경우 Disk -> 메모리로 swap
여러 프로세스가 메모리에 들어오고 나가는 모습
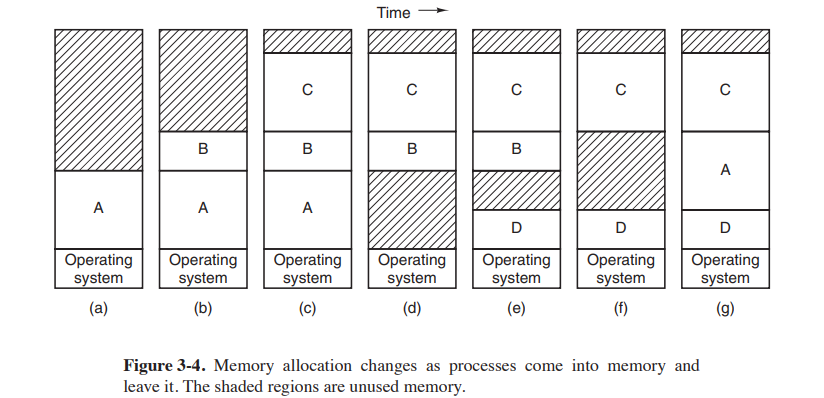
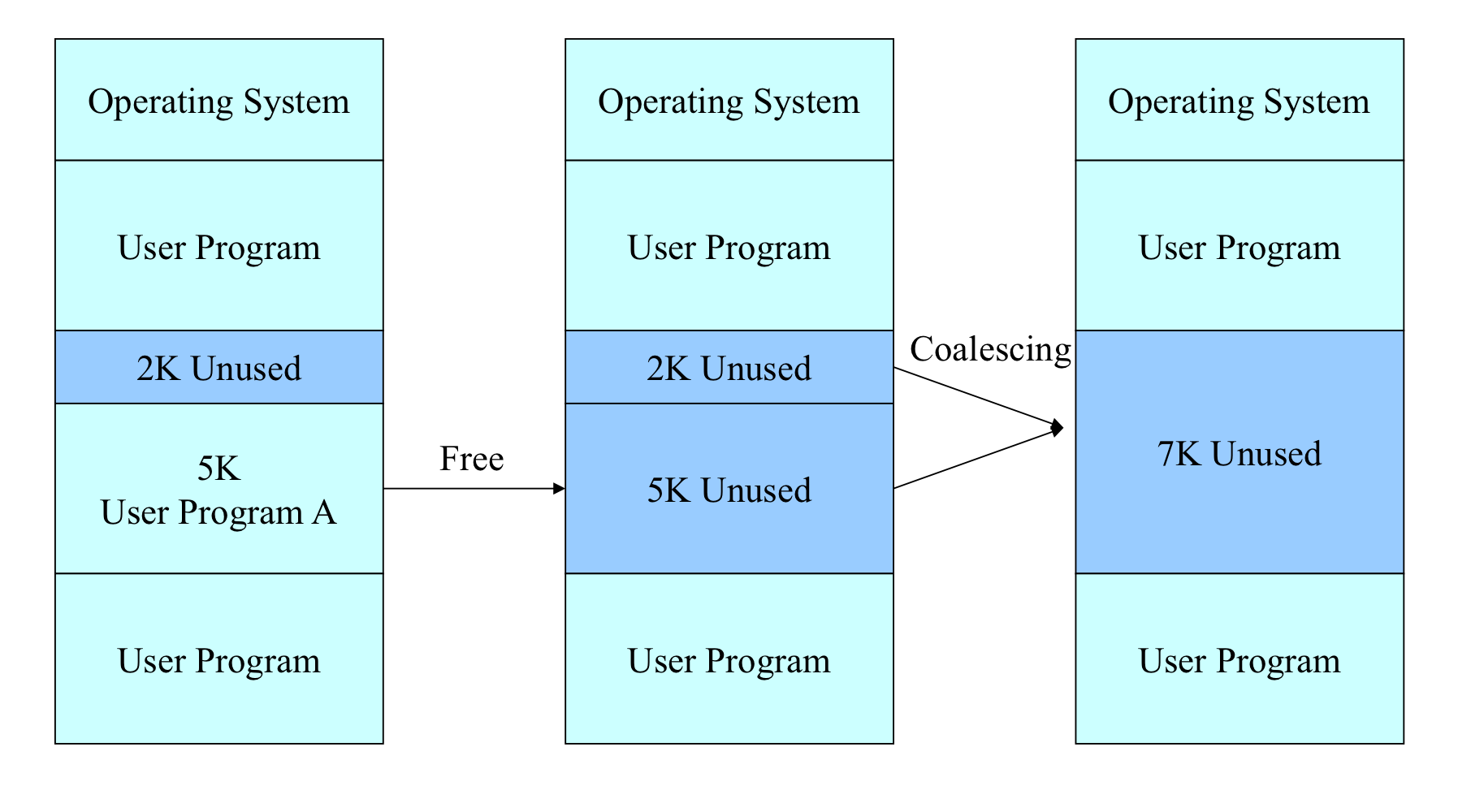
그림에서 보이듯 사용되지 않은 메모리 공간이 있다. 여러 프로세스들이 들어오고 나가다 보면 빈 공간이 여기저기 흩어져 있을 수 있는데 이를 외부 단편화라 한다. 1KB의 빈 공간이 4군데로 퍼져 있는데 실행할 프로그램이 4KB라면 흩어져 있는 메모리를 한곳에 모으면 실행할 수 있다.
4.Free Memory Management
메모리의 빈 공간(미사용 영역)을 잘 모으고 통합해서 효율적인 메모리 사용을 해보자
-
비트맵 사용
-
연결 리스트 사용
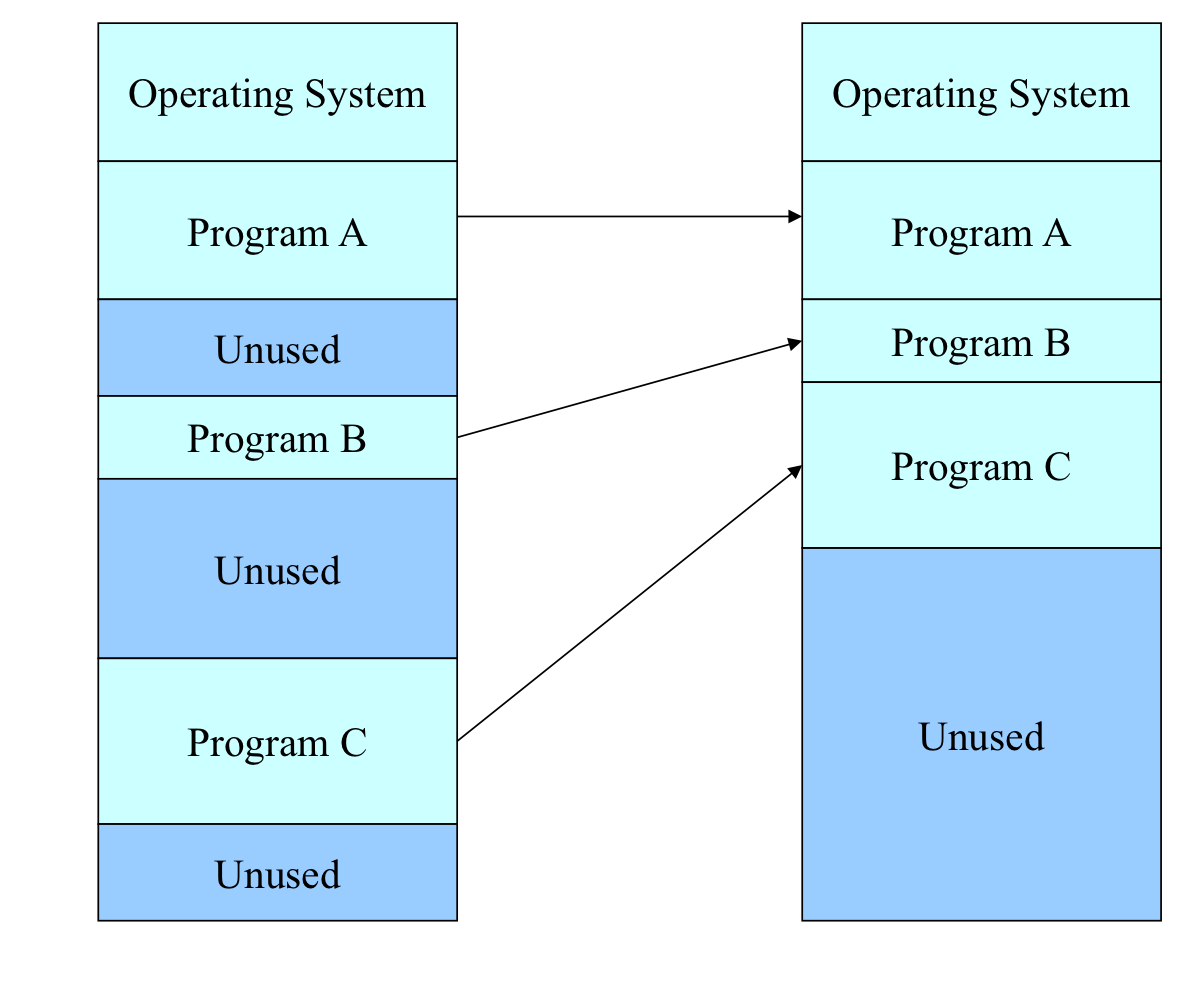
메모리 통합/ 압축
-
통합
-
압축
메모리 할당 알고리즘
- First fit
- Next fit
- Best fit
- Worst fit
가상 메모리
1.개념
앞서 살펴본 추상화의 개념이 발전하면서 나타난 기법. 사용자에게 메모리의 모든 물리적 측면을 숨기는 것이다.
- 메모리는 bytes의 논리적으로 무한한 가상 주소 공간이다.
- 프로세스는 각자의 주소 공간을 가지며, 연속적이고 논리적으로 무한하다고 여김
- 물리 메모리보다 큰 프로그램을 실행할 수 있음
- 한 시점에 물리 메모리에 올라와 있는것은 가상 주소 공간의 일부
2.페이징
개념
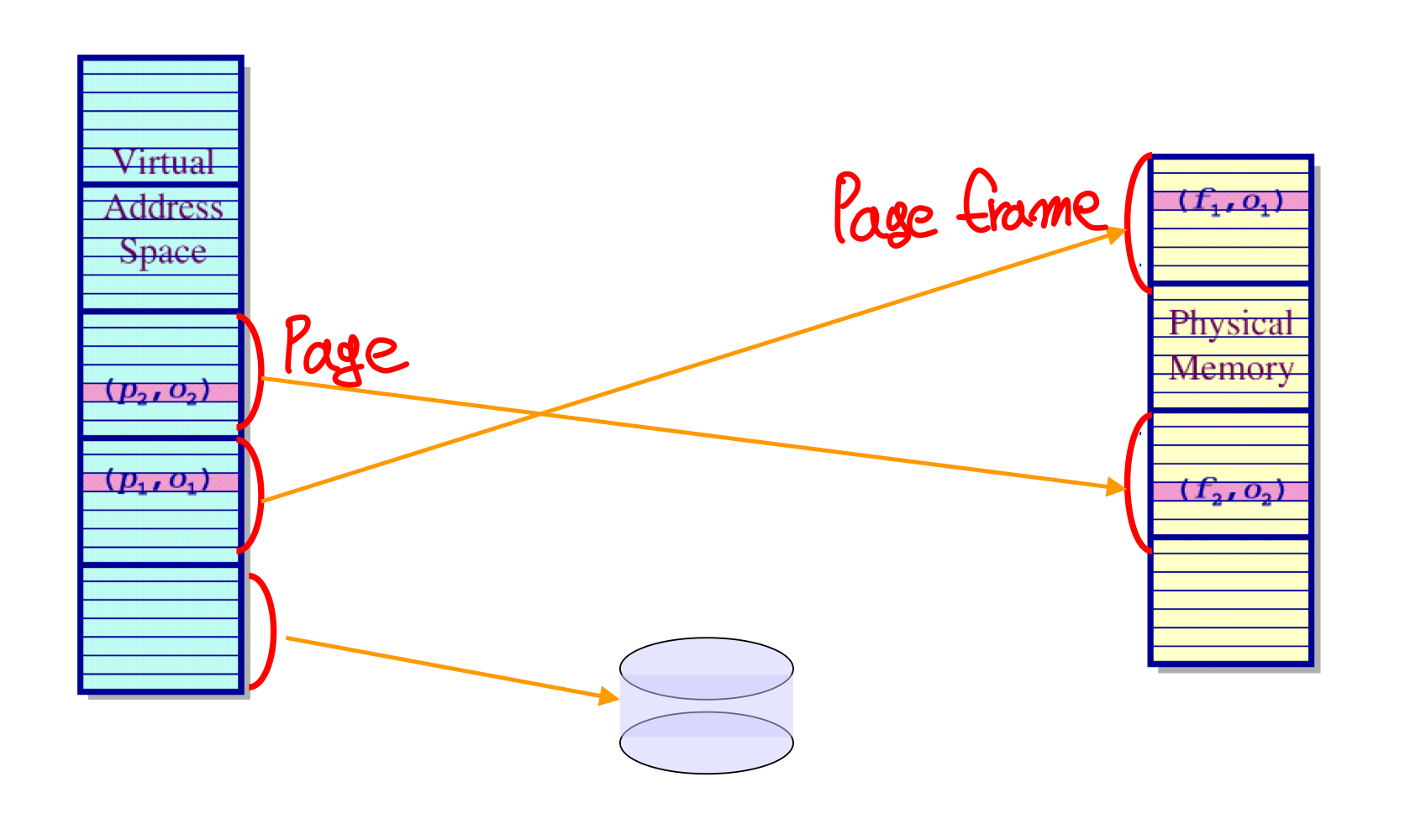
가상 주소 공간을 동일한 사이즈의 페이지로 나누는 것.
물리 메모리도 이에 상응하는 과정이 있고 페이지 프레임으로 나뉨.
MMU(Memory Management Unit)이 페이지를 페이지 프레임으로 매핑 시켜줌.
사용자가 가상 메모리를 사용하면 CPU가 알아서 실제 메모리에 매핑에서 사용
- 가상 메모리에서는 연속적인 공간 이지만 물리적 메모리에서는 아닐 가능성이 높음
- 모든 페이지가 프레임에 매핑되지 않음. swap을 통해서 효율적인 관리
- 가상 주소는 페이지 넘버, 오프셋으로 나뉨
- 몇번에 페이지에 있는지, 그 페이지 안에서 어디에 있는지
- 페이지 크기에 따라서 오프셋의 크기가 정해지고 이를 가상 주소의 하위비트로 사용, 나머지는 페이지 넘버로 사용
- 32bit 시스템에서 페이지가 4KB = 라면 오프셋은 12비트 따라서 페이지 넘버는 까지 사용 가능.
- 프레임도 프레임 넘버, 오프셋으로 나뉨
- 페이지 크기
- 내부 단편화, 테이블 크기, IO 효율등을 고려
- 프로세스 크기 , 페이지 크기 , 테이블 엔트리 크기 , 내부 단편화 크기 일 때
- 를 p에 대해 미분하면
페이지 테이블
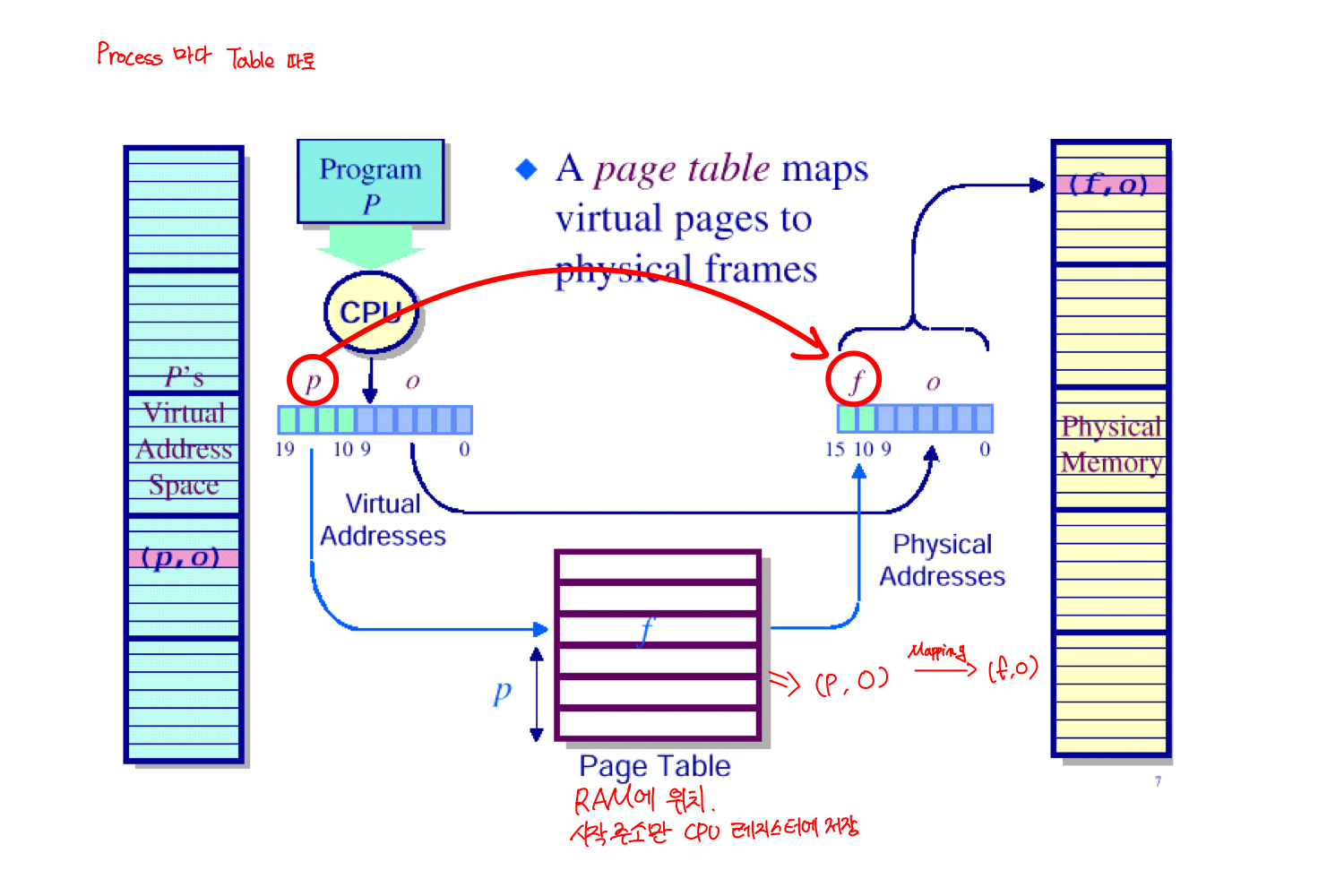
페이즈를 프레임에 매핑 시키는 방법
가상 주소에서 페이지 넘버를 프레임 넘버로 변환시킨다.(오프셋은 그대로 유지)
- 각 프로세스는 별도의 테이블을 가진다
- 하지만 각 프로세스의 가상 주소가 같은 곳으로 매핑될 수 있다.
- ex) 같은 프로그램을 2개 킨 경우 코드 메모리의 code영역
- 공유 라이브러리 (동적 링킹)
- 하지만 각 프로세스의 가상 주소가 같은 곳으로 매핑될 수 있다.
- 테이블 엔트리
- 플래그 (간단한 버젼)
- Valid : 해당 페이지가 RAM에 있거나, 접근 가능한지 확인
- 0이면 Page fault 후 할당 또는 swap
- dirty : 이후에 수정이 되었는지
- swap영역으로 나갈 때 1이면 다시 써야함
- refrence : 최근 접근 여부
- 페이지 교체 알고리즘에서 사용
- Valid : 해당 페이지가 RAM에 있거나, 접근 가능한지 확인
- 페이지 넘버
- 플래그 (간단한 버젼)
TLB(Translation Lookaside Buffer)
가상 주소를 매핑할 때 매번 RAM의 페이지 테이블을 살펴보는 것은 비효울적이다. -> 그럼 캐시처럼 CPU내부에 저장하자.
- 교체 정책을 적절히 사용해야함.
- hit rate가 중요
- 문맥 전환 시 TLB flush
- 현제는 일부/선택적 flush 가능한모양
너무 큰 페이지 테이블
지금까지 살펴본 것은 싱글 레벨 페이징. 이 경우 사용하지 않는 page도 유지 해야함. 왜? 할당되지 않은 목록을 알아야 나중에 할당을 해주니까. 그러다보니 페이지 테이블이 너무 커져서 다음과 같은 해결 방법이 등장함
Multilevel Paging
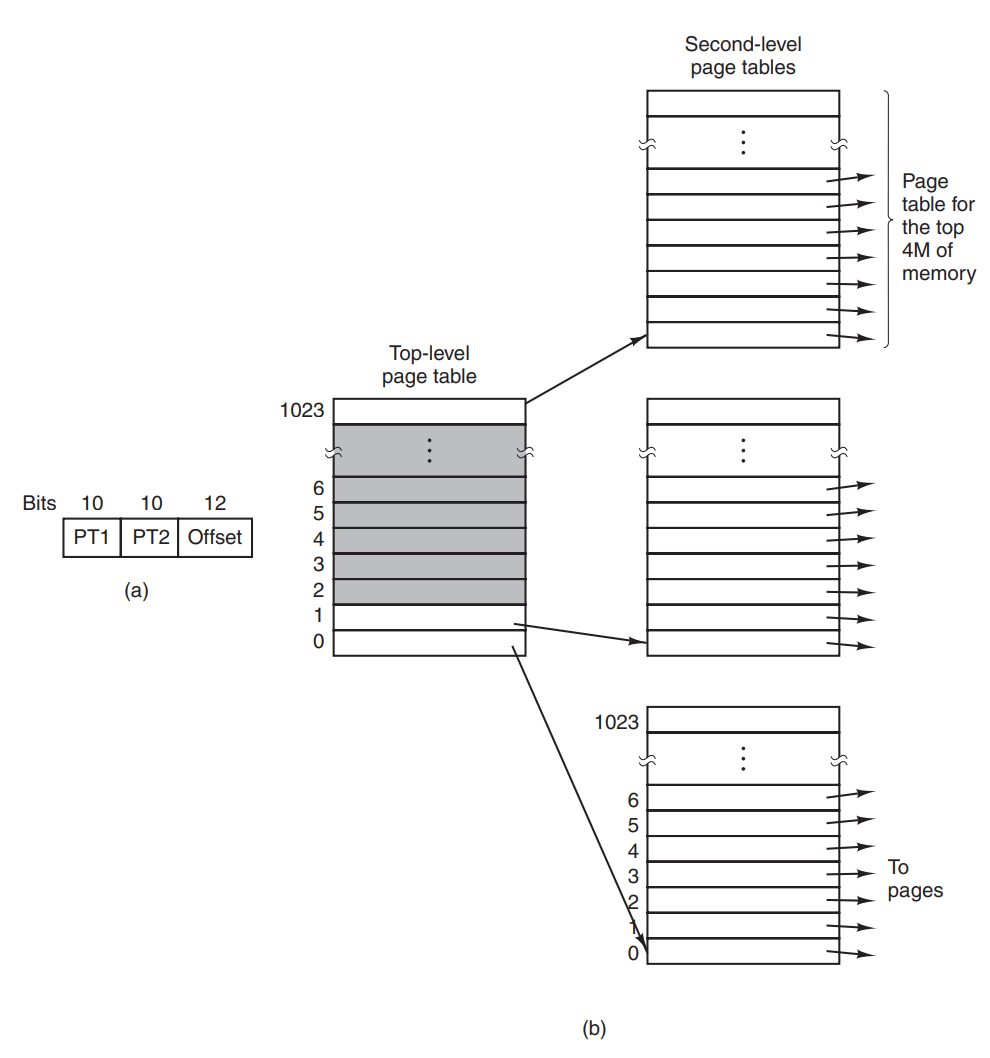
말 그대로 페이징을 여러번 하는 것. 32bit 시스템을 예로 들면 싱글레벨의 경우 개의 페이지를 모두 기록해야 함. 하지만 싱글레벨의 경우 Top-level 의 항목만 필수로 유지하고 나중에 하위 페이지가 필요하면 그 때 할당하는 방식 하위 테이블을 모두 유지하지 않아 테이블을 효율적으로 사용가능. TLB 역시 멀티레벨로 하는데 miss시 성능이 좀 떨어지는 듯.
64bit는 4레벨 멀티 페이징 하는 모양
Inverted page table
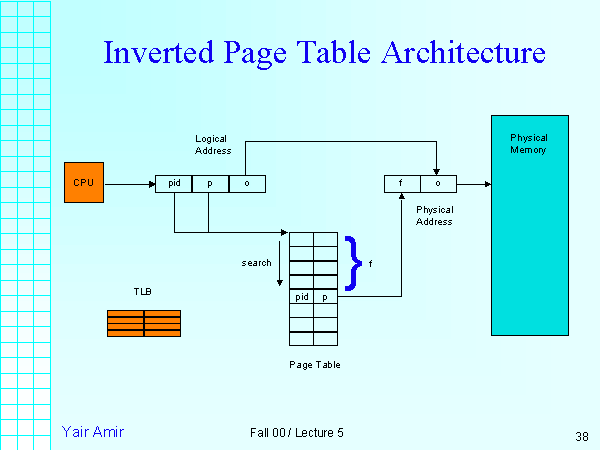
기존 페이지 테이블은 가상 주소 공간의 크기에 따라서 테이블의 크기가 정해짐. 여기서 설명하는 역 페이지 테이블은 실제 프레임의 크기만큼으로 테이블 크기를 줄임
- 테이블에 몇번 프로세스가 몇번 페이지를 가지고 있는지 기록
- CPU가 pid p o를 사용해서 IPT 접근 -> IPT에서 해당 pid p 가 몇번째 프레임(i)인지 확인 -> i o 로 매핑
- TLB miss, 탐색 성능문제
- 과거에는 miss시 인터럽트 걸어서 OS가 순차적으로 TLB 세팅후 변환
- pid 혹은 p를 키로 해시 테이블을 만들자
Page Faults
페이지 테이블의 valid bit가 0(페이지가 프레임에 매핑되지 x)인 경우. 다음의 과정을 거침
- OS가 인터럽트를 걸어서 서비스 루틴 실행
- 오류인지 swap에만 있는지 확인
- swap에만 있으면 빈 프레임에 적재 후 table 수정하고 리턴
- 리눅스의 경우 미리미리 빈 공간을 확보한다고 함.
- fault 발생한 시점부터 다시 시작
페이지 교체
-
현재 사용되지 않는 페이지들은 디스크에 저장됨.
- Backing store
-
Optimal page replacement
- 상한선 알고리즘
- 미래를 안다는 가정하에 교체 시뮬
-
NRU
- 페이지의 참조, 수정 여부를 가지고 4가지 상태로 분류
- 최근에 참조되지 않은 페이지를 먼저 교체
- 수정은 그 다음 우선 순위
-
FIFO
- Fetch 순서를 유지
- 이를 기반으로 FIFO
- 자주 사용되는 페이지 삭제 가능성 있음
-
Second chance page replacement
- FIFO의 발전형
- 바로 교체하지 않고 큐에 마지막에 넣음
-
Clock page replacement
- LRU를 구현하다 보면 이 형태로 구현됨
- Second chance의 발전형
- 원형 큐를 사용
- Hand와 Rbit를 통해 교체
-
LRU
- 가장 흔하게 사용됨
- 연결리스트, 하드웨어
-
Working set page replacement
- 최근 dt동안 사용된 페이지 집합을 들고 있다가
- swap시 페이지에 없는걸 내보내기
-
WSClock page replacement
- Working set + clock
- 멀티 프로그래밍에서 중요
- 현실성 있슴
추가적으로 살펴볼만한 것들
-
Local vs Global
- Local
- 자신의 프레임에서만 교체
- 안정성 높지만 메모리 낭비 등의 문제
- global
- 전체 프레임에서 교체
- 안전성 낮지만 메모리 활용도가 높음
- Local
-
Thrashing
- 페이지 폴트가 연속적으로 발생해서 다른 작업을 진행하지 못하는 상태
- PC 다운됨
- 적절한 swap out을 통해서 working set을 유지
-
Cleaning Policy
- 미리 프레임의 빈 공간을 확보하는 정책
- UNIX에서는 Two Handed Clock 사용
-
lock bit를 사용해 swap에서 제외가능
- I/O 작업을 하고 있을 때
-
정책과 매커니즘의 분리
- 저레벨 MMU
- 페이지 폴트 핸들러
- 유저 영역에서 실행되는 외부 pager (정책 결정)
Memory Mapped File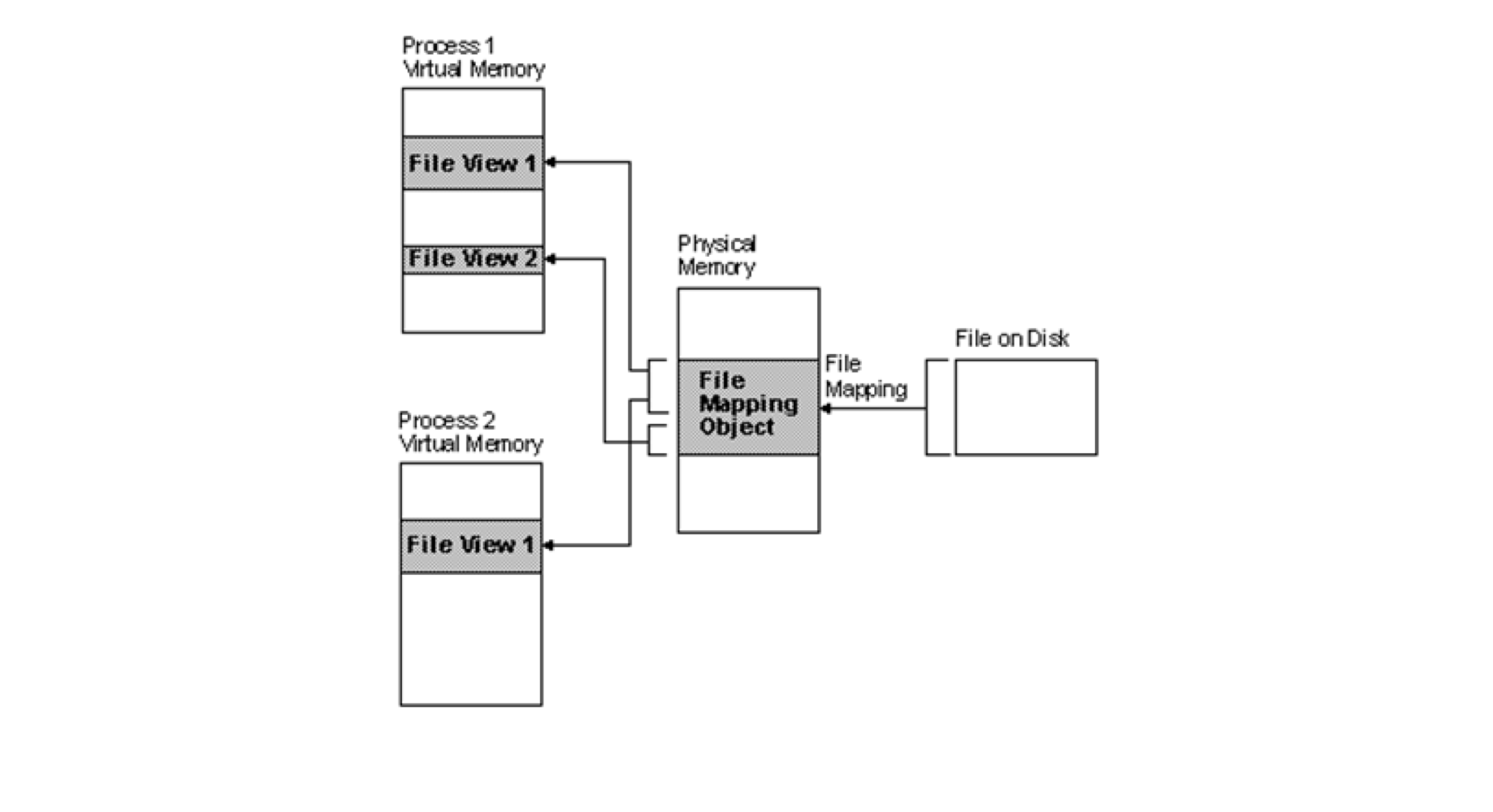
파일을 가상 메모리에 매핑해서 메모리를 사용하는 것 처럼 사용하는 방식. 마치 파일이 프로세스의 일부인 것 처럼 사용
IO 성능이 대폭 향상된다.
분산 시스템의 VMI
- 메시지 패싱
- 분산 공유 메모리
3.Segmentation
페이징이 물리적으로 크기를 나누었다면, Segmentaiton은 논리적으로 나눠서 배치하는 것이다. 페이징과 다르게 가변길이!
우리가 자주보는 segmentation fault의 segmentation임
먼저 컴파일러가 컴파일을 하면서 만드는 테이블들, 결과물의 예시를 알아보자
- 심볼 테이블
- 코드가 출력된 목록(어셈블리)으로 저장됨
- 상수
- parse tree
- call stack
이러한 항목들이 Segment가 될 수 있고, 이를 통해서 메모리를 매핑하는 것.
각 프로세스마다 seg table이 있고, 각 seg의 길이를 기록함.
외부 단편화가 발생하는데, 페이징과 결합한 Segment-paging으로 해결
- 세그먼트 번호 + 오프셋
- 오프셋을 페이지 번호 + 오프셋 으로 분리
- 어찌보면 2단계 페이징과 유사
- 펜티엄에서는 다음과 같은 방식으로 해결
- 당시에는 독특하면서 중요한 방식이었다고...
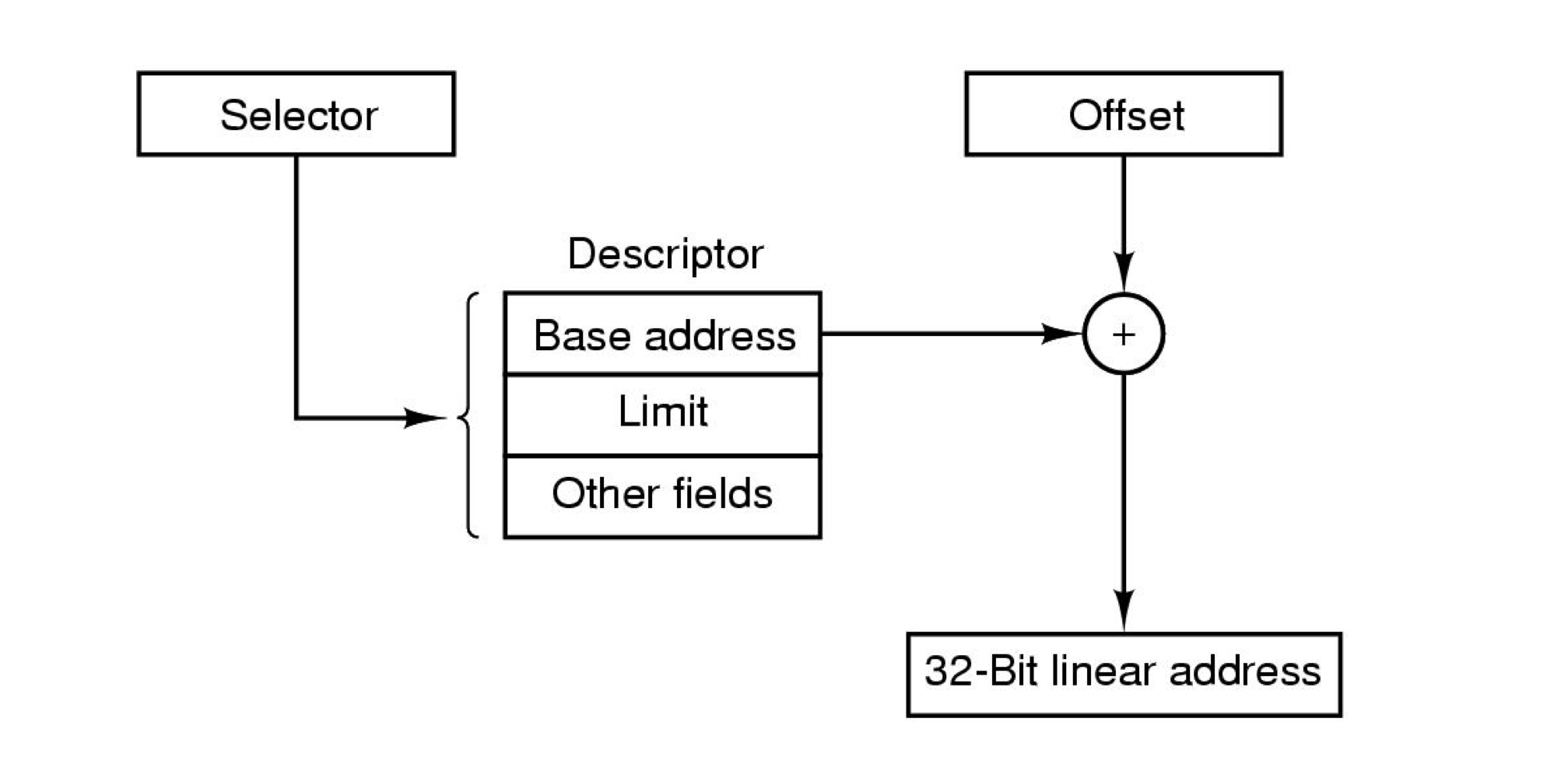
- 당시에는 독특하면서 중요한 방식이었다고...
Ref
