빅데이터 관련 포스팅을 보면 대부분 하둡 에코시스템(Hadoop eco-system)을 사용하는것을 볼 수 있습니다. Hadoop에 대해 알아보도록 하겠습니다.
Hadoop 이란?
빅데이터를 저장 및 처리하기 위해서는 하나의 컴퓨터로는 부족합니다. 그래서 여러 대의 컴퓨터를 이용해서 데이터를 분석하고 저장하는 플랫폼이 나오게 되었고, 하둡은 사실상 표준으로 사용되고 있습니다. 하둡을 사용함으로써 데이터를 분석하는 비용과 시간을 단축시킬 수 있게 되었습니다.
하둡의 두 가지 대표적인 기능은 HDFS, MapReduce 기능입니다. 이 포스팅에서는 HDFS에 대해 알아보도록 하겠습니다.
HDFS(Hadoop Distributed File System)
하둡 분산형 파일 시스템(이하 HDFS)는 대용량 파일을 여러 대의 컴퓨터에 나눠 저장하는 시스템입니다. 저사양 서버들을 이용하여 대용량의 분산파일시스템을 구축할 수 있어 대규모 데이터 저장 또는 배치 처리시 유용한 파일 시스템입니다. 하지만 고사양이나 트랜잭션에는 적합한 시스템이 아닙니다. 확장을 위해 고성능 고용량의 장비를 추가하기 보다는 컴퓨터 수를 추가하는 방식을 사용합니다.
HDFS의 특징
- 여러 개의 복사본을 저장하여 데이터 유실을 방지합니다.
기본적으로 블록당 3개의 복사본을 저장하며, 데이터를 128MB로 나눠 저장합니다.(복사본의 수, 쪼개는 용량은 변경 가능합니다.) - 스트리밍 방식으로 데이터에 접근합니다.
HDFS는 랜덤엑세스 방식이 아니라 순차적으로 쭉 읽는 방식입니다. 따라서 빠르게 특정 데이터에 접근하기보다는 대용량의 데이터를 순차적으로 처리하는데 적합합니다. - 데이터 무결성을 유지합니다.
HDFS는 데이터 수정은 할 수 없으며, READ와 APPEND만 할 수 있습니다. - 데이터 수정은 불가하지만 파일 이동, 삭제, 복사할 수 있는 인터페이스를 제공합니다.
- 예시

위 그림처럼 만약 612MB의 용량을 가지고 있는 파일이 있다면 HDFS에서는 이를 128MB 단위로 쪼개 총 5개의 블록을 만듭니다. 블록 E를 보면 알 수 있듯이 모든 블록이 128MB를 차지하는건 아닙니다. 복사본을 3개씩 생성하므로 총 저장하는 블록의 수는 5x3 = 15개 입니다. 총 15개의 블록들이 여러개의 서버에 분산되어 저장됩니다. 이 때 어떤 블록이 어떤 서버에 저장되었는지에 대한 메타 데이터를 저장해주어야 합니다.
HDFS의 구조
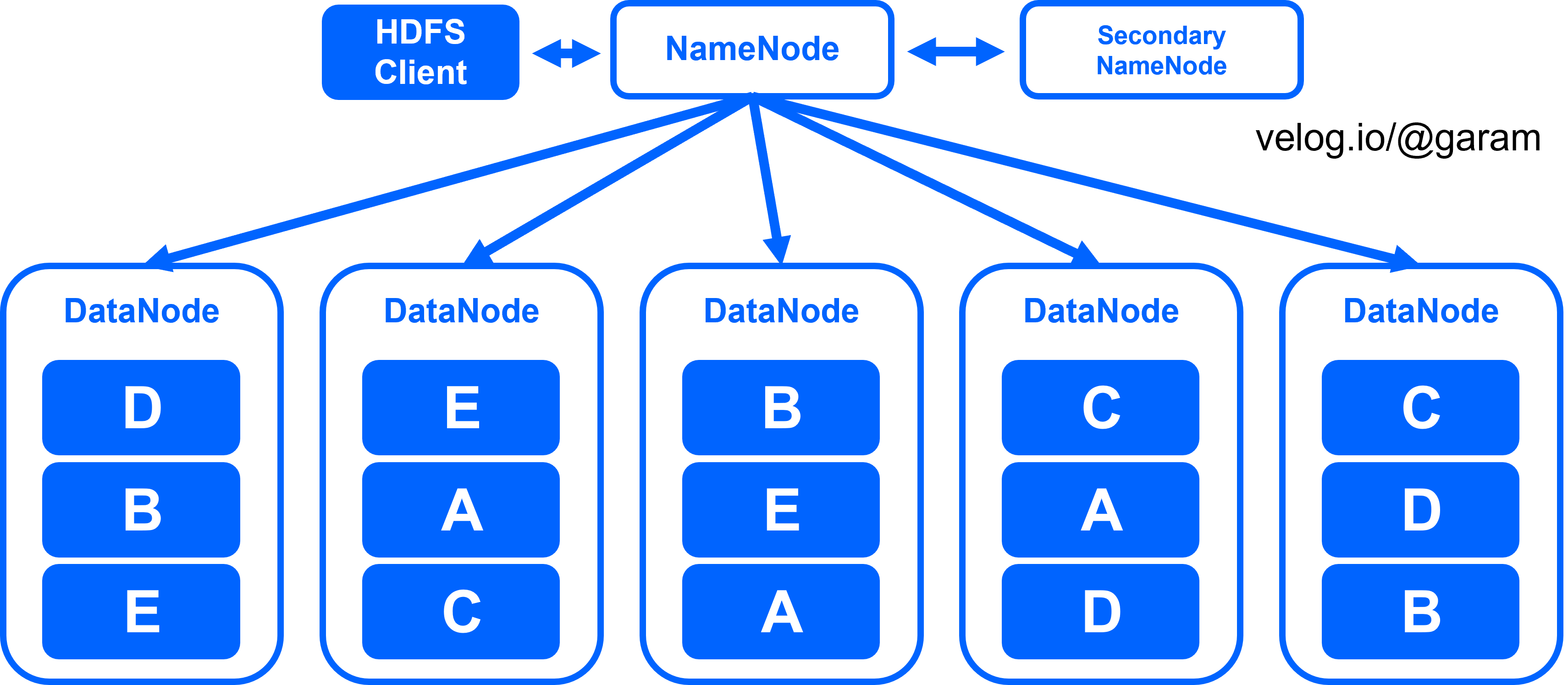
HDFS는 위 그림과 같이 Namenode, Datanode, Secondary Namenode로 구성되어 있습니다.
- Namenode
HDFS의 메타데이터를 관리합니다. 메타데이터에는 파일의 생성일, 수정일, 네임스페이스, 파일이름 등등 파일의 정보가 포함됩니다. Namenode는 파일을 구성하는 블록들의 목록과 위치가 저장되어 있으므로 HDFS에 파일을 읽거나 쓰는 작업의 시작점 역할을 수행합니다. 디스크가 아닌 메모리에서 직접 관리하여 빠른 응답이 가능합니다.
메타데이터에는 다음과 같은 정보들이 담겨있습니다.
1. 파일명
2. 디렉토리(파일경로)
3. 데이터 블록 크기
4. 소유자/소속그룹
5. 파일속성
6. DataNode와 블록 대응 정보
(블록ID와 해당 블록을 보유한 DataNode 정보, DataNode가 hear beat를 3초 간격으로 전송할 때 자신이 관리하는 블록 정보를 report하는데 이를 바탕으로 전체 블록정보를 구축 및 복제 수가 충분한지 판단합니다.)
메타데이터는 다음 두 파일에 저장됩니다.
1. fsimage
메타데이터에 저장된 정보중 (위 목록에서) 1~5번을 포함한 정보입니다. 메모리상에 관리되어 있는 메타데이터 내의 파일 시스템 이미지입니다. 체크 포인트라고 불리는 타이밍에 NameNode의 로컬 파일 시스템에 생성됩니다.
2. edits
HDFS에서 파일 처리 시 로컬 파일 시스템에 생성되는 편집로그입니다. 메모리 상에서 관리되고 있는 fsimage에 적용됩니다.
- Datanode
Datanode는 데이터블록들을 저장합니다. Namenode와 3가지 종류의 통신을 하면서 커넥션을 유지합니다.
- handshake
맨 처음 Datanode를 Namenode에 등록할 때 수행하는 통신입니다. Datanode가 통신이 가능하며 적절한 소프트웨어 버전인지 확인합니다. 적합한 Datanode임이 확인되면 고유한 id를 부여합니다. - block report
Namenode가 블록의 실제 위치를 알 수 있게 하는 통신입니다. 각 Datanode들은 매 시간마다 Namenode에 블록이 실제로 저장되어있는 위치와 현황을 알려줍니다. - heart beat
하나의 HDFS는 수천개 이상의 컴퓨터로 구성되어 있으며, 이 중 일부 노드가 고장나는 상황은 빈번하게 일어납니다. 각 Datanode는 3초에 한번씩 heartbeat를 Namenode에게 보내 자신이 잘 동작하고 있음을 확인시켜줍니다. Namenode는 10분 이상 응답이 없는 노드는 고장이 난 것으로 간주하며, 해당 노드에 저장되어 있었던 블록들은 다른 노드에 복사본을 하나씩 추가합니다.
- Secondary Namenode
하둡의 Namenode이 고장날 경우를 대비해 구성한 노드입니다. 보조 Namenode인 Secondary Namenode는 HDFS에서 작성한 로그(editslog)와 파일시스템(fsimage)저장파일을 동기화하는 역할을 수행합니다.
-
주기적으로 Namenode에서 fsimage와 edits를 받아서 이들을 합치고, 갱신내용을 반영한 새로운 fsimage를 생성합니다.
-
생성한 fsimage를 Namenode로 전송합니다.
-
체크포인트를 실시하여 fsimage에 적용 완료 된 edits를 삭제함으로써 디스크 공간을 절약합니다.
즉, fsimage를 매 쓰기동작마다 갱신하는것이 아니라 주기적으로 업데이트 하는 것입니다. 위 과정을 통해, Namenode 재시작 시 fsimage에 대한 edits적용 크기를 줄일 수 있어 재시작 시간이 단축됩니다(edits파일은 크기제한이 없음). 또한, Namenode 장애가 발생한 경우, 메타 데이터를 보존함으로써 완전 데이터 손실을 방지합니다.
참고 사이트
https://velog.io/@ha0kim/2021-03-02
https://tourspace.tistory.com/223
https://yeomko.tistory.com/38
https://opentutorials.org/course/2908/17055
https://sjh836.tistory.com/43
https://velog.io/@kimdukbae/Hadoop
https://m.blog.naver.com/acornedu/222069158703
https://sungwookkang.com/1454
https://nathanh.tistory.com/91
