MapReduce
대용량의 데이터 처리를 위한 분산 처리 프레임워크입니다. MapReduce 프레임워크를 이용하면 대량의 데이터를 병렬로 분석 가능합니다. Map과 Reduce라는 2개의 메소드로 구성되어 있습니다.
- Map : 흩어져 있는 데이터를 연관성 있는 데이터들로 분류하는 작업 (key-value의 형태)
- Reduce : Map에서 출력된 데이터의 중복을 제거하고 원하는 데이터를 추출하는 작업
HDFS가 파일 저장소를 담당한다면 MapReduce는 연산을 담당합니다. 분산처리의 개념을 간단하게 생각해보면, 1명이 데이터 100개를 처리 vs 100명이 데이터 1개씩 처리를 비교해보면 상식적으로 후자가 더 빠를 것입니다. 하지만 작업을 나누는 시간과 100명이 처리한 결과를 취합하고 정리하는 시간이 필요합니다.
Map 작업에서는 분산되어있는 데이터를 key - value 형태로 묶는 작업을 수행합니다.
Reduce 작업에서는 반환된 key - value 형태의 리스트를 받아 데이터를 합치고 원하는 데이터를 추출하는 작업을 수행합니다.
MapReduce 처리 과정
텍스트 파일에서 단어의 개수를 count하는 문제를 예시로 들어보겠습니다.
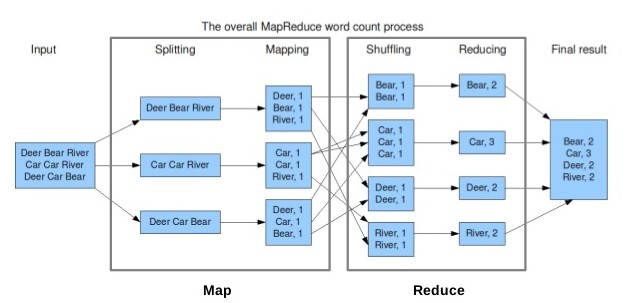
- 텍스트 파일(들)을 HDFS에 업로드하고, 각 파일은 블록으로 나뉘어 Datanode에 저장됩니다.
- (Splitting) 라인별로 문자열이 처리되며, Map연산을 통해 key - value 형태의 리스트를 만듭니다.
- (Shuffling) 과정을 통해 같은 key를 가지는 데이터들끼리 모아 정렬합니다.
- (Reducing) 과정을 통해 각 key 별 빈도수를 계산합니다.
- 결과를 합산하여 HDFS에 파일로 결과를 저장합니다.
즉 MapReduce 작업을 시작할 때와 끝날 때 HDFS로부터 파일을 가져오고( Read ), HDFS에 파일을 쓰는( Write ) 작업을 수행합니다.
MapReduce의 Job
MapReduce에서 Job은 사용자가 수행하려는 작업단위로 'Full Program' 즉, 전체 프로그램을 의미합니다. 하둡은 Job을 Map Task와 Reduce Task로 작업을 나눠서 실행합니다.
MapReduce Architecture
MapReduce는 JobTracker와 TaskTracker로 구성되며 HDFS와 마찬가지로 master-slaves 구조입니다. Client는 JabTracker에게 Job 실행을 요청하고, 진행상황 및 완료 결과를 공유받게 됩니다.
- Client
사용자가 실행한 MapReduce 프로그램과 하둡에서 제공하는 MapReduce API를 의미합니다. 분석하고자 하는 데이터를 Job의 형태로 JobTracker에게 전달합니다. - JobTracker
사용자가 요청한 Job을 어떻게 실행하게 될 지 계산하고(스케줄링), 모니터링 합니다. 주로 NameNode가 구동되는 서버에서 동작합니다. 몇 개의 Map과 Reduce를 실행하게 될 지 계산하며, task들을 어떤 TaskTracker에서 실행할지 결정합니다. TaskTracker와 Heartbeats message를 사용하여 상태와 작업 실행 정보를 공유합니다. - TaskTracker
사용자가 설정한 MapReduce 프로그램을 실행하는 데몬입니다. 주로 DataNode에서 실행됩니다. JobTracker부터 작업을 요청받고 요청 받은만큼 Map Task와 Reduce Task를 생성합니다. Task가 생성되면 새로운 JVM을 생성해 Task를 실행합니다.
MapReduce Work Flow
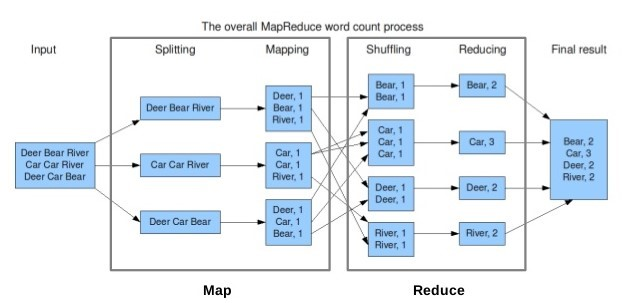
위 그림을 다시 보겠습니다. 입력 데이터가 들어오면 Input Split 단위로 쪼개게 됩니다. Input Split의 크기는 일반적으로 HDFS의 블록크기와 동일합니다. 이 과정을 Splitting이라고 합니다.
그 다음 Mapping 과정을 거칩니다. 이 때 Input Split의 데이터를 레코드 단위로 한 줄씩 읽어서 사용자가 정의한 Map Function을 적용합니다. 즉, Input Split의 레코드 수 만큼 Map Function이 적용되게 하고 하나의 Input Split에 하나의 Mapper Class가 적용됩니다.
여기까지의 Map Task의 결과로 Intermediate Key-Value Pair가 생성됩니다. 위 그림에서 보면 "Deer, 1"과 같은 Pair가 생성됩니다.
Reduce Task는 이 Pair를 내려받아 Shuffling을 합니다. Shuffle과정은 Map Task의 데이터가 Reduce Task로 전달되는 과정입니다. 이 과정에서 네트워크 통신이 가장 많이 일어나게 되며 MapReduce 성능의 저하가 가장 많이 발생하는 과정입니다.
( 작성 예정 : " MapReduce 실행과정 "/ " 후속포스팅(MapReduce 실습) " )
참고 사이트
https://mangkyu.tistory.com/129
https://velog.io/@spdlqjfire/%ED%95%98%EB%91%A1-%ED%94%84%EB%A1%9C%EA%B7%B8%EB%9E%98%EB%B0%8D-MapReduce
https://velog.io/@kimdukbae/MapReduce
https://12bme.tistory.com/154
