



IP 프로토콜은 네트워크 계층의 프로토콜로
먼저 네트워크 계층의 기본 기능을 먼저 살펴보자.
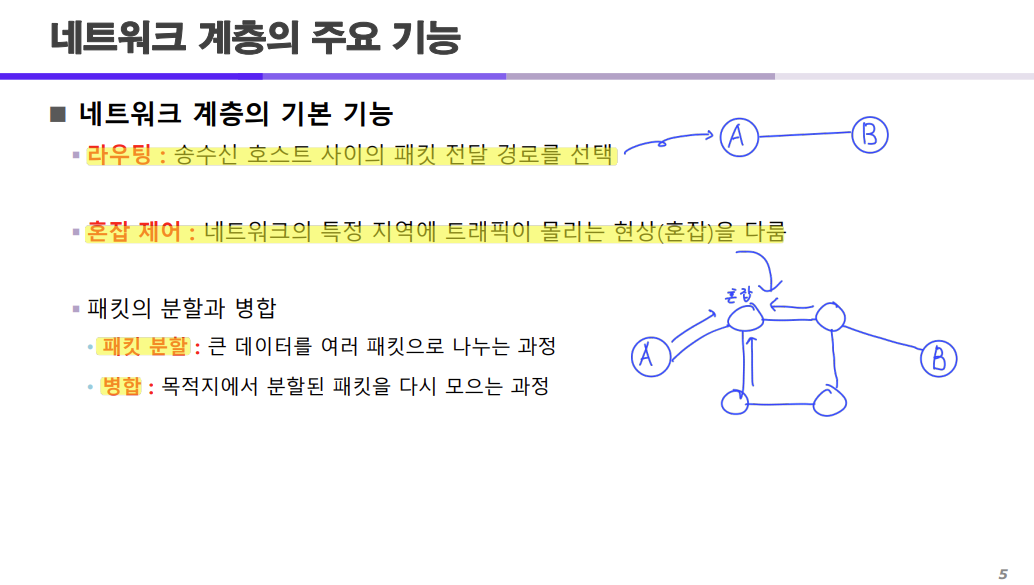
라우팅 = 송수신 호스트 사이의 패킷 전달 경로를 선택한다.
혼잡 제어 = 네트워크의 특정 지역에 트래픽이 몰리는 현상(혼잡)을 다룸
혼잡 제어의 경우 간단히 위 그림과 같이 한 지역에 대해 트래픽이 몰리는 현상을 제어하는 것을 말한다.
흐름 제어와는 다르게 흐름 제어는 A와 B간의 전송을 제어하는 것이면
혼잡 제어는 A와 B가 아니라 A, B, C, D에서 특정 지역에 트래픽이 몰리는 현상을 제어하는 것이다.
그래서 네트워크 계층의 기본 기능은
라우팅, 혼잡 제어, 패킷의 분할과 병합이 있다.
패킷 분할 = 데이터를 여러 패킷으로 나누는 과정
병합 = 목적지에서 분할된 패킷을 다시 모으는 과정
네트워크 계층의 패킷이 데이터 링크 계층에 있는 프레임으로 전달될 때 네트워크 계층의 패킷 크기가 데이터 링크 계층의 프레임 크기보다 크면 우리는 패킷 분할을 통해 데이터를 여러 패킷으로 나눠서 아래 계층인 데이터 링크 계층으로 전달해줘야 하며
수신 호스트로 전송된 데이터는 다시 데이터 링크 계층에서 네트워크 계층으로 갈 때 분할된 데이터를 병합하여 네트워크 계층으로 전달해준다.
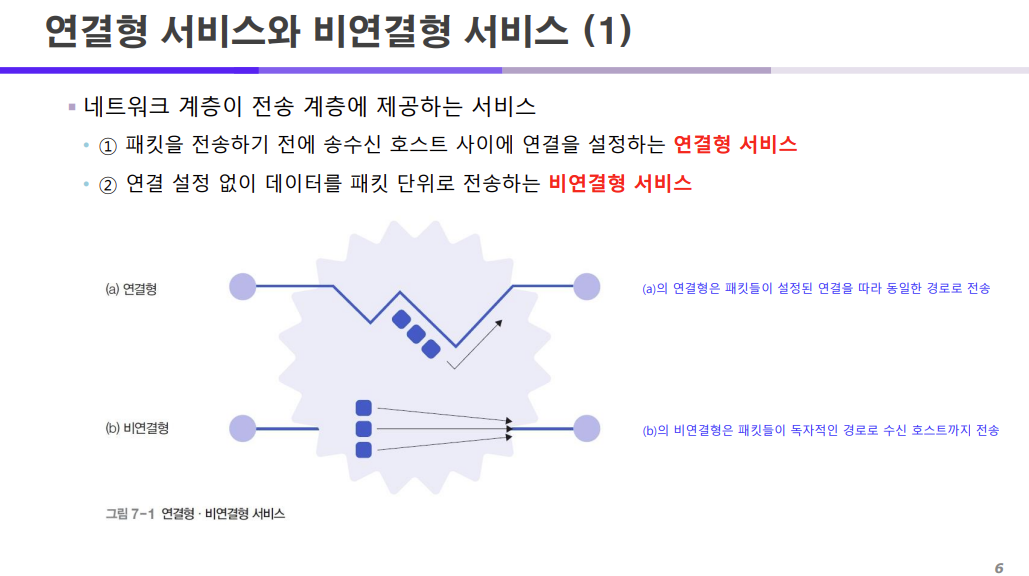
우리가 라우팅을 할 때 연결형과 비연결형 서비스에 대해서 이야기한 적이 있다.
연결형 = 송수신 사이에 연결을 설정하는 방식 = 송수신 사이에 연결된 경로를 따라 전송
비연결형 = 연결 설정 없이 패킷 단위로 전송 = 패킷이 각자 독자적인 경로로 수신 호스트로 전송

비연결형은 연결 없이 패킷이 각자 독자적인 경로로 수신 호스트로 전송되기 때문에
송신 호스트에서 1번 2번 3번 데이터를 순차적으로 전송했어도 수신 호스트에서는 3번 2번 1번 데이터 순서로 받을 수 있고(패킷의 전달 순서)
송신 호스트에서 1번 2번 3번 데이터를 보냈는데 2번이 분실되어 수신 호스트에는 1번과 3번만 도착할 수 있다.(패킷 분실 여부)
이러한 이유로 비연결형 서비스는 연결형 서비스보다 신뢰성이 떨어지는 전송 방식이다.
대표적인 비연결형 서비스는 IP 프로토콜이다.
연결형 서비스는 패킷을 전송하기 전에 연결을 미리 설정하여 송신하는 방식으로
도착하는 패킷의 순서가 송신된 순서와 동일하며 상대적으로 신뢰성이 높다는 특성이 있다.
연결형 방식을 사용하는 프로토콜은 전송 계층의 UDP 프로토콜이 대표적이다.
라우팅은 간단히 패킷의 전송 경로를 지정하는 것이라고 생각하면 된다.
라우팅의 주요 기능 = 입력된 패킷을 어느 출력 경로를 통해 다음 라우터까지 전달해야 가장 효과적인지 결정하는 것

라우팅을 크게 분류하면
- 정적 라우팅
- 동적 라우팅
이렇게 2가지로 분류할 수 있다.
정적 라우팅 = 경우 송수신 호스트 사이에 패킷 전송이 이루어지기 전에 경로 정보를 라우터에 미리 저장하여 중개하는 방식
=> 우리가 데이터를 전달할 경로가 사전에 정해진 방식
동적 라우팅 = 라우터에서 사용하는 경로 정보를 네트워크 상황에 따라 적절하게 변경하는 방식으로, 경로 정보의 변경 주기에 따라 계속 보완할 수 있음
=> 사전에 어떤 경로로 갈지 정해져 있지만 중간중간 네트워크 상황에 따라 경로가 수정되는 방식
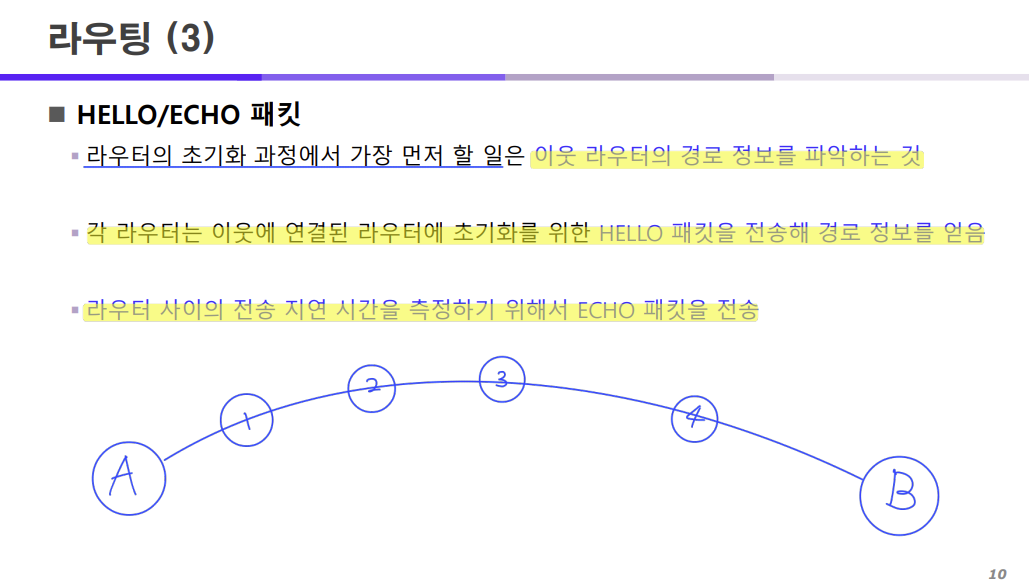
라우터의 초기화 과정에서 가장 먼저 해야할 일은 이웃 라우터의 경로 정보를 미리 파악하는 것이다.
각 라우터는 이웃에 연결된 라우터에 초기화를 위한 HELLO 패킷을 전송해 경로 정보를 얻고
각 라우터 사이의 전송 지연 시간을 측정하기 위해서 ECHO 패킷을 전송한다.
간단히
HELLO 패킷은 이웃된 라우터까지의 경로 정보를 위해서 전송하는 것이고
(주변에 어떤 경로로 어떤 라우터가 있고 몇 개의 라우터가 있는지 알기 위해서 사용)
ECHO 패킷은 이웃된 라우터까지의 전송 지연 시간을 측정하기 위해서 전송하는 것이다.
이렇게 HELLO 패킷과 ECHO 패킷을 통해 사전 조사를 진행하고
진행된 사전 조사를 토대로 라우팅을 진행하게 되는 것이다.
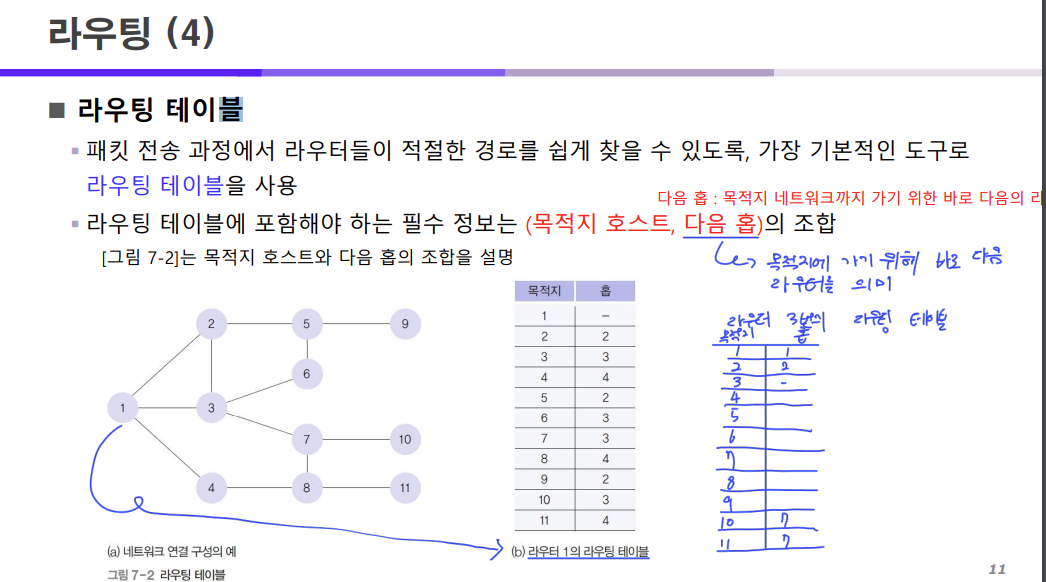
위 HELLO 패킷과 ECHO 패킷을 통해 진행된 사전 조사를 통해 라우팅 테이블이 작성되고
이 라우팅 테이블은 모든 라우터들이 각각의 라우팅 테이블을 가지고 있게 된다.
각각의 라우팅 테이블에는 목적지 호스트와 다음 홉이 적혀있다.
다음 홉 = 목적지에 가기 위한 바로 다음 라우터를 의미

누가 라우팅 경로를 결정하는지에 따라서 아래와 같이 4가지 방식으로 나뉘어진다.
- 소스 라우팅
- 분산 라우팅
- 중앙 라우팅
- 계층 라우팅
이렇게 4가지이다.
먼저 소스 라우팅 방식에 대해서 살펴보자.
소스 라우팅 = 패킷을 전송하는 송신 호스트가 목적지 호스트까지 전달 경로를 스스로 결정하는 방식
이미 송신 호스트가 경로를 정했기 때문에 헤더에 이 정보를 저장하고 보내서 각각의 라우터가 이 정보를 확인하여 데이터를 전달하도록 함.

분산 라우팅 = 송신 호스트와 각각의 거치는 라우터들이 목적지까지의 경로를 결정하는 방식
거치는 라우터에 따라서 각각의 라우터가 현재 네트워크 상황에 따라서 어떤 경로가 최적의 경로인지 선택하는 방법.
중앙 라우팅 = RCC라는 특별한 호스트를 사용해 전송 경로에 대한 모든 정보를 관리하는 방식
관제탑과 같은 특별한 호스트가 어느 경로로 가야 하는지 정하는 방식
예를 들어 A라는 호스트가 B 호스트에게 데이터를 보내고자 할 때 RCC에게 어느 경로로 데이터를 전달해야 하는지 물어보고 RCC가 말해준 경로를 따라서 B에게 데이터를 보내는 방식이다.
계층 라우팅 = 분산 라우팅 기능과 중앙 라우팅 기능을 적절히 조합하는 방식
분산 라우팅과 중앙 라우팅 기능을 조합하여 만든 방식으로 전체 네트워크의 구성을 계층 구조 형태로 관리한다.

혼잡 = 네트워크의 성능 감소 현상이 급격하게 악화되는 현상을 의미 = 데이터가 급격하게 몰렸을 때
이러한 혼잡 문제를 해결하기 위한 방안이 바로 혼잡 제어이다.
흐름 제어의 경우 송신 호스트와 수신 호스트 사이의 논리적인 점대점 전송 속도를 다루지만
혼잡 제어의 경우 더 넓은 관점에서 호스트와 라우터를 포함한 서브넷 네트워크의 전송 능력 문제를 다룬다.

혼잡의 원인 = 네트워크 용량에 비해 전송 패킷이 많기 때문
혼잡이 심화되는 주요인은 다음과 같다.
-
A 라우터에서 B 라우터로 데이터를 전송하는데 7초가 걸림, 그러나 타임 아웃 기능이 5초 이내로 실행되기 때문에 무한정으로 타임 아웃이 진행되어 지속적으로 패킷이 재전송되고 이 데이터들이 네트워크에 계속 쌓이게 됨.
-
A 라우터가 지금 버퍼에 5개의 데이터를 저장할 수 있는데 현재 3개가 이미 저장되어 있음,
이때 C라는 라우터가 A 라우터에게 5개의 데이터를 보냈는데 A는 버퍼에 빈 공간이 2개 밖에 없기에
5개 중 3개의 데이터는 버리고 전달 받은 2개의 데이터에 대해서만 응답을 보냄.
라우터 C는 이를 해결하기 위해서 다시 3개의 데이터를 재전송 하지만 A는 빈 버퍼가 없어 계속해서 데이터를 버려서 계속해서 네트워크에 돌아다니는 데이터의 수가 증가하게 됨.
이러한 원인에 의해서 혼잡이 발생하게 된다.

그럼 발생하는 혼잡을 제어하기 위해서 트래픽 성형을 진행해야 하는데
트래픽 성형은 다음과 같다.
트래픽 성형(Traffic Shaping)
혼잡의 원인: 트래픽이 특정 시간에 집중되는 버스트 현상으로 인해 발생.
필요성: 송신 호스트가 전송하는 패킷의 발생 빈도를 예측 가능한 전송률로 조정하여 네트워크 혼잡을 완화.
작동 방식:
협상을 통해 네트워크로 유입되는 패킷의 분포 특성을 사전에 정의.
이를 기반으로 네트워크는 혼잡도를 예측하고 효율적으로 혼잡 제어를 수행.

방법 1 리키 버킷 알고리즘
트래픽 성형에서 사용하는 알고리즘이 바로 리키 버킷 알고리즘이다.
리키 버킷 알고리즘의 진행 방식은 다음과 같다.
리키 버킷 알고리즘이란?
송신 호스트로부터 입력된 패킷이 시간대별로 일정하지 않고 어느 순간 많거나 어느 순간 적어도
깔대기라는 버퍼를 사용해 패킷이 이를 지나게 되면은
가변율을 고정율로 즉 일정한 전송률을 가지게 만들어 트래픽을 줄이도록 하는 알고리즘이다.
간단히 말하면
리키 버킷 알고리즘은
송신 호스트로부터 입력되는 패킷이 어느 순간 많고 어느 순간에 적어도
중간에 버퍼를 지나게 되면 일정한 전송률을 가지게 만들어 트래픽을 줄이는 알고리즘이다.

만약 버퍼의 용량을 넘어서게 되면 패킷이 분실된다.

방법 2 ECN 패킷 사용
ECN 패킷을 사용하게 되면은
미리 특정 지역에 혼잡이 발생할 것 같으면 라우터들이 송신 호스트에게 이러한 사실을 알려서 혼잡이 발생하지 않도록 한다.
정리하면 라우터가 미리 혼잡이 발생할 것을 인지해 송신 호스트에게 ECN 패킷을 보낸다.
이는 송신 호스트에게 미리 이 구간에 혼잡이 발생할 가능성이 있다는 것을 라우터가 알리는 것으로 혼잡이 다른 지역으로 확대되지 않도록 한다.
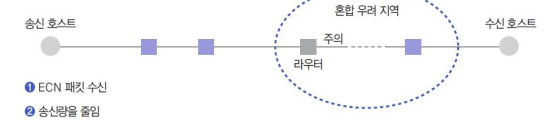
사실 조금 더 자세하게 보면
위와 같이 라우터가 혼잡 우려 지역에서 혼잡이 발생할 것을 인지하게 되면 먼저 혼잡 우려 지역을 지나 수신 호스트에게 ECN 패킷을 보내고 수신 호스트가 송신 호스트에게 ECN 패킷을 보내게 된다.
그러면 송신 호스트는 데이터를 보낼 때 경로를 다시 설정해서 수신 호스트에게 보내게 된다.

방법 3 전용 대역 할당
그 외로 혼잡을 제거하는 방법으로 아예 대역을 미리 할당 받아서 혼잡이 발생하지 않게하는 방식이 있다.
이렇게 대역을 미리 할당하게 되면 네트워크에서 수용 불가능할 정도로 트래픽이 발생하는 일이 없어지지만
전송 대역을 해당 호스트가 이용하지 않을 때 다른 호스트들이 이 대역을 이용하지 못하는 단점이 존재한다.
따라서 이러한 자원 예약 방식은 통신 자원을 낭비한다는 단점이 있다.
따라서 전용 대역 할당은 사용하지 않고 ECN 패킷 방법을 주로 활용한다.
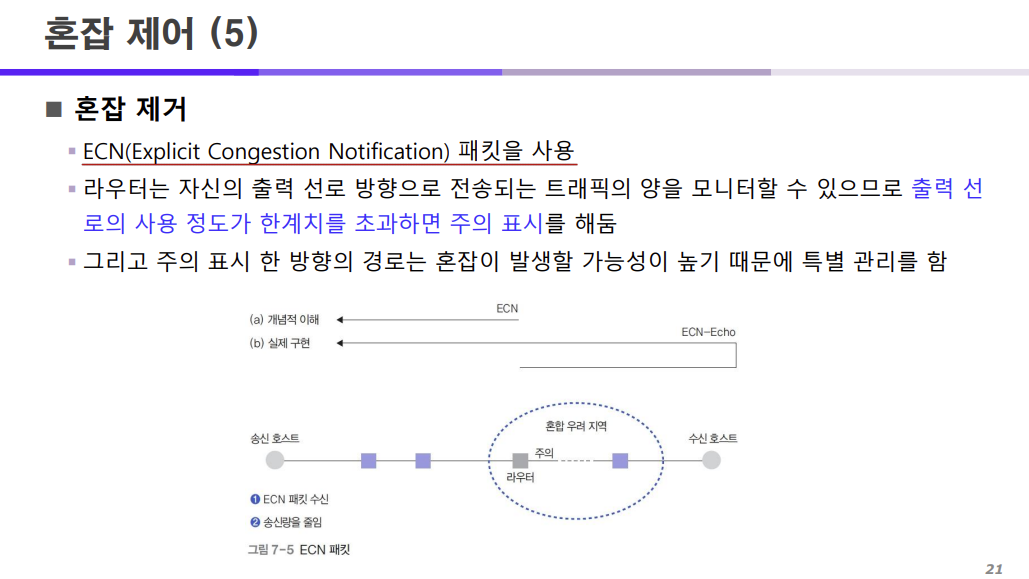
ECN 패킷에 대해서 더 자세히 보자.
라우터는 자신의 출력 선로 방향으로 전송되는 트래픽의 양을 모니터할 수 있기 때문에
출력 선로의 사용 정도가 한계치를 넘계되면 주의 표시를 진행한다.
이렇게 주의 표시가 된 방향의 경로는 혼잡이 발생할 가능성이 높기 때문에 특별 관리를 진행한다.
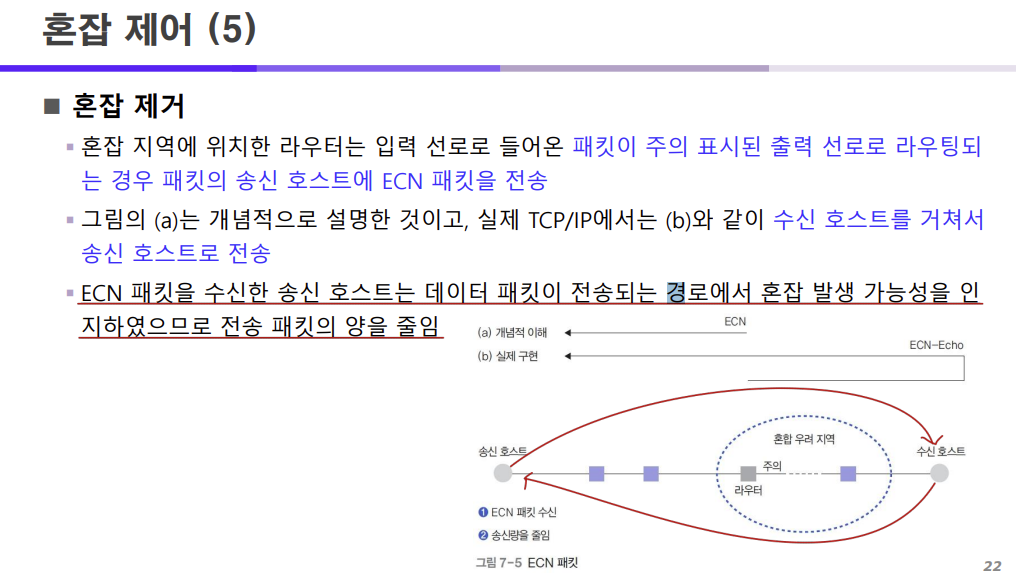
혼잡 지역에 위치한 라우터는 입력 선로로 들어온 패킷이 주의 표시된 출력 선로로 라우팅 되는 경우에
패킷의 송신 호스트에 ECN 패킷을 전송한다.
실제로는 위 그림 중 (b)와 같이 TCP/IP에서는 수신 호스트를 거쳐서 송신 호스트에게 ECN 패킷을 전송한다.
그럼 ECN 패킷을 수신한 송신 호스트는 데이터 패킷이 전송되는 경로에서 혼잡 발생 가능성을 인지했기 때문에
전송 패킷의 양을 줄인다.

라우터가 수신 호스트에게 ECN 패킷을 먼저 보내는 이유를 알아보자.
-
특정 라우터에서 주의 표시를 시작하면 이후 경로에 위치한 라우터들도 주의 표시를 할 가능성이 높고 그렇기에 ECN 패킷이 여러 라우터에서 동시에 발생할 가능성이 높음.
-
따라서 최초로 ECN 패킷을 생성한 라우터에서는 전송되는 패킷의 헤더 내부에 ECN-Echo와 같은 임의의 표시를 하여 목적지인 수신 호스트까지 도착하는 동안에 거치는 라우터가 ECN 패킷을 더 이상 생성하지 않도록 함.
이게 우리가 라우터에서 바로 송신 호스트에게 ECN을 보내지 않고 수신에게 전달했다가 다시 송신에게 ECN 패킷을 보내는 이유이다.
이렇게 ECN 패킷을 라우터 -> 수신 -> 송신 순서로 보내게 되면
라우터가 ECN 패킷의 헤더에 ECN-Echo를 표시한 다음 이후 경로의 라우터에 ECN 패킷을 만들지 않도록 할 수 있다.
따라서 라우터에서 ECN 패킷을 먼저 수신 호스트에 보내고 이후에 다시 송신 호스트에게 보내도록 하는 것이다.
ECN 패킷을 받은 송신 호스트는 정해진 비율에 따라서 송신 패킷의 양을 줄여서 전송하고
임의의 시간이 지나도 ECN 패킷이 계속 들어오면
송신 패킷의 양을 더 줄여서 이 과정은 ECN 패킷이 발생하지 않을 때까지 계속된다.
