
이번 시간에는 라우팅에 대해서 공부를 진행해보자.

- 최단 경로 라우팅
먼저 최단 경로 라우팅 프로토콜에 대해서 살펴보자.
최단 경로 라우팅은 말 그대로 최단 경로로 라우팅하겠다는 의미인데 여기서 말하는 최단 경로의 기준은 어떤 것일까?
여기서 말하는 최단 경로의 기준은 목적지까지 거치는 라우터 수(홉의 수)가 최소가 되는 경로를 의미한다.
홉 = 네트워크에서 데이터가 한 라우터 또는 네트워크 장비를 거치는 단계
홉의 수 = 거치는 라우터의 갯수
최단 경로 라우팅
=> 목적지까지 거치는 라우터의 수가 최소가 되는 경로
간단히 위 예를 보면 a에서 g까지 도달하는 경로는 여러개가 존재하지만
이중에서 최단 경로 라우팅에 맞는 경로는 a -> c -> g가 된다.

- 플러딩
라우터에서 초기에 테이블을 작성할 때 플러딩 방식을 통해 데이터를 흘려보내고 응답을 받을 때 역순으로 테이블을 채워나가는 방식
이 플러딩 방식으로 데이터의 경로를 중계하는 라우팅 방식이 있다.
플러딩 방식으로 데이터의 경로를 중계하게 되면 라우터는 입력된 패킷을 출력 가능한 모든 경로로 중개한다.
플러딩 방식은 중요한 데이터를 모든 호스트에게 동시에 전달하는 환경에서 사용한다.

- 거리 벡터 라우팅 프로토콜
간단히 벡터를 정보라고 해석해서 거리 정보를 가지고 라우팅 하겠다는 의미로 해석하면 된다.
거리 벡터 라우팅 프로토콜은 라우터가 가지고 있는 거리 정보를 나와 직접적으로 연결된 이웃 라우터와 라우팅 정보를 교환한다.
이 프로토콜을 구현하기 위해서 사용되는 정보들이 크게 3가지가 존재하는데
- 링크 벡터
- 거리 벡터
- 다음 홉 벡터
이렇게 3가지가 필요하다.
링크 벡터는 무엇인가?
링크 벡터에는 연결 정보 즉 라우터 A와 직접 연결된 이웃 네트워크에 대한 연결 정보를 보관한다.
라우터와 네트워크는 연결되어 있기 때문에 이웃 네트워크에 대한 연결 정보는 곧 이웃 라우터에 대한 정보를 보관한다고 생각하면 된다.
그래서 위 사진과 같이 링크 벡터의 경우 라우터 A와 직접 연결된 네트워크가 M개일 때 링크 벡터 정보를 아래와 같이 나타낸다.


따라서 링크 벡터에 보관된 정보는
라우터 A가 해당 네트워크와 연결하기 위해 할당한 라우터 포트 번호이다.
이 링크 벡터의 경우
자신과 직접 연결된 이웃 라우터가 누구인지 알기 위한 자료로 사용되고 이들에게 거리 벡터 정보를 제공하는 데 사용된다.
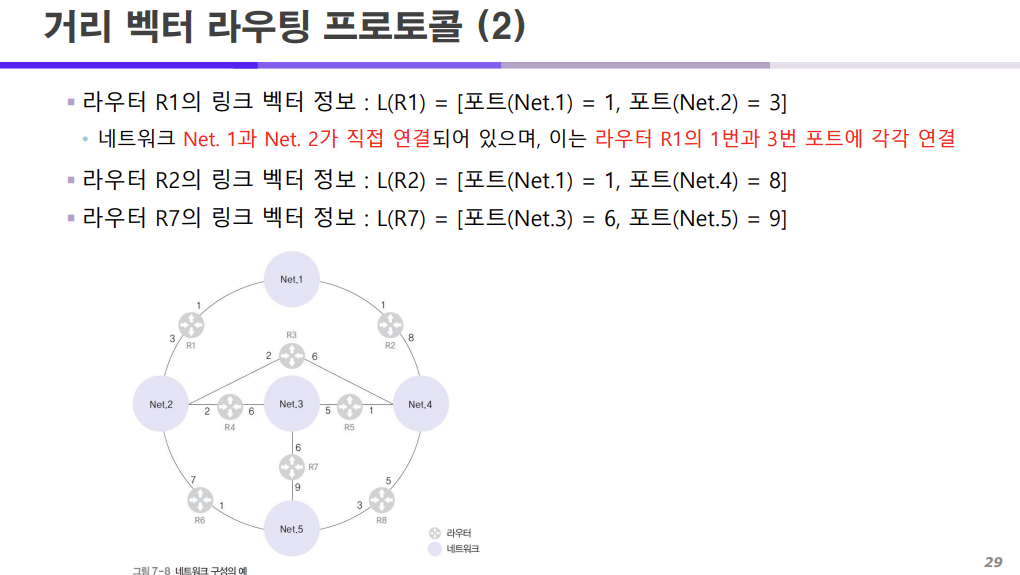
위에서 라우터의 포트 번호가 보관된다고 했는데
이는 위 사진을 통해 이해할 수 있다.
라우터 R1의 링크 벡터 정보는 1번 포트는 네트워크 1과 3번 포트는 네트워크 2와 연결되어 있기 때문에
위와 같이 나타낼 수 있는 것이다.

다음은 2번째로 필요한 정보인 거리 벡터이다.
거리 벡터를 측정하는 기준이 다양하다.
- A에서 B까지 가는데 거쳐가는 홉의 수
- A에서 B로 데이터를 보내는데 걸리는 시간
- A에서 B로 데이터를 보내는데 드는 통신 비용
등등 거리 정보로 사용할 수 있는 정보가 다양하다.
하지만 이 거리 벡터 라우팅 프로토콜에서 사용하는 거리 벡터의 기준은 바로 시간이다.
즉 내가 A에서 B까지 데이터를 보내는 데 있어서 걸리는 시간 즉 전송 지연 시간을 가지고 거리 정보로 사용한다.
근데 이 책에서는 전송 지연 시간을 가지고 예제를 만들면 이해하기 어렵기 때문에 거치는 라우터의 수를 가지고 예제를 만들어 두었다.
예제는 아래와 같다.

거리 벡터에서 관리하는 정보는 일반적으로 개별 네트워크까지 패킷을 전송하는 데 걸리는
최소 전송 지연 시간이다.
위 예제에서는 임의로 표시된 거리 값을 홉 수로 가정한 것이다.
위 그림에서 전체 네트워크에 포함된 네트워크는 총 5개로 각각의 라우터들은 모두 거리 벡터 정보를 5개씩 보관한다.
라우터 R1을 위한 거리 벡터 값을 보면 네트워크 1, 2, 3, 4, 5에 대해서 각각의 거리 벡터 정보를 임의로 홉 수로 표시해 놓은 것을 확인할 수 있다.
라우터 R1에서 네트워크 1, 2까지는 본인을 포함해 1개
라우터 R1에서 네트워크 3, 4, 5까지는 본인을 포함한 2개의 라우터를 거치게 된다.

- 다음 홉 벡터
다음 홉 벡터 = 현재 위치에서 목적지까지 가는데 거치는 바로 다음 라우터를 말한다.
다음 홉 벡터의 경우 개별 네트워크까지 패킷을 전송하는 경로에 있는 다음 홉 정보를 관리하기 때문에
보관하는 정보의 수는 거리 벡터와 마찬가지로 전체 네트워크에 속한 네트워크의 개수이다.
따라서 위 그림을 보면
라우터 R1을 위한 다음 홉 벡터 값은 총 5개를 표기하며
라우터 R1에서 네트워크 1과 2까지는 거치는 라우터가 없기 때문에 '-'로 표시한다.

다음으로는 RIP에 대해서 살펴보자.
RIP는 거리 벡터 라우팅 방식을 사용하는 대표적인 내부 라우팅 프로토콜이다.
RIP는 다음과 같은 제한을 두어 개별 거리 정보가 라우팅 테이블에 순차적으로 적용되도록 한다.
우리가 위에서 거리 벡터 라우팅 프로토콜의 경우 인접한 네트워크에게 내가 가진 정보를 공유한다고 했는데 새로 입력된 거리 벡터 정보가 기존 정보와 비교했을 때 목적지까지 도착 지연 시간이 더 적으면 새로운 경로로 라우팅 테이블을 수정하게 된다.
-
입력되는 거리 벡터 정보가 새로운 네트워크의 목적지 주소이면 라우팅 테이블에 적용
-
입력되는 거리 벡터 정보가 기존 정보와 비교했을 때 목적지까지 도착하는 지연이 더 적으면 대체함
-
임의의 라우터로부터 거리 벡터 정보가 들어왔을 때, 라우팅 테이블에 해당 라우터를 다음 홉으로 하는 등록 정보가 있으면 새로운 정보로 수정함.
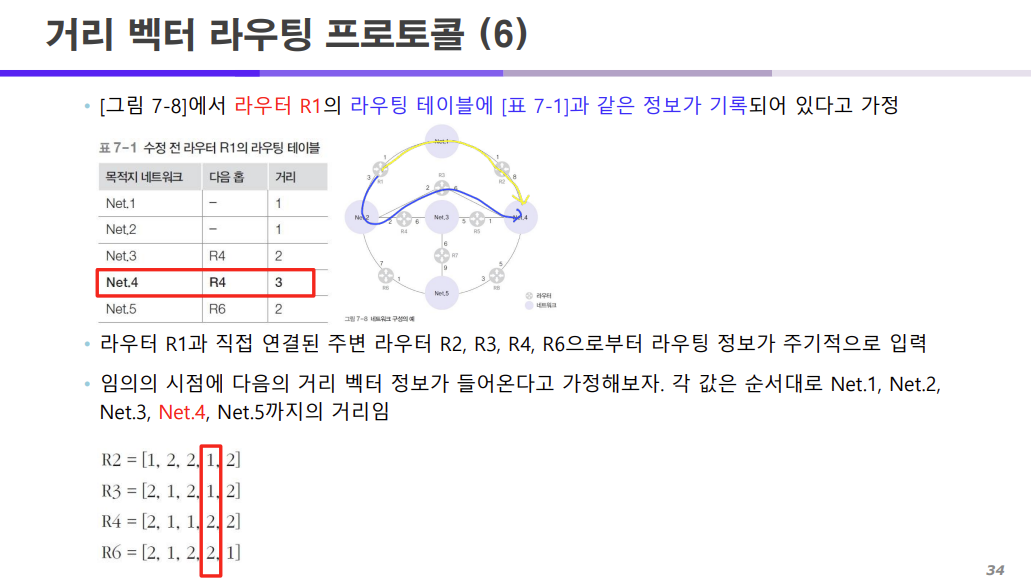
위 그림에서 기존 라우팅 R1의 라우팅 테이블에 표와 같은 정보가 기록되어 있을 때
NET4까지의 다음 홉은 현재 R4로 기록되어 있고 NET4까지 총 3홉(거리)을 지나야 한다고 나와있다.
R1과 직접 연결된 주변 라우터 R2, R3, R4, R6로부터 라우팅 정보가 주기적으로 입력되면서
위 R2, R3, R4, R6 표는 각각의 라우터에서 네트워크까지의 거리를 보여주고
이때 R2, R3는 네트워크 4까지 거리가 1이고 R4, R6는 네트워크 4까지 거리가 2임을 볼 수 있다.
그럼 여기서 R1의 입장에서는 거리를 줄이기 위해서는 R2, R3, R4, R6 중에서 무엇을 선택해야 할까?
여기서 만약 R2나 R3를 선택한다고 가정하면 거리의 수가 줄어들 것이고
R4나 R6를 선택하게 되면 거리가 지금과 같이 늘어날 것이다.
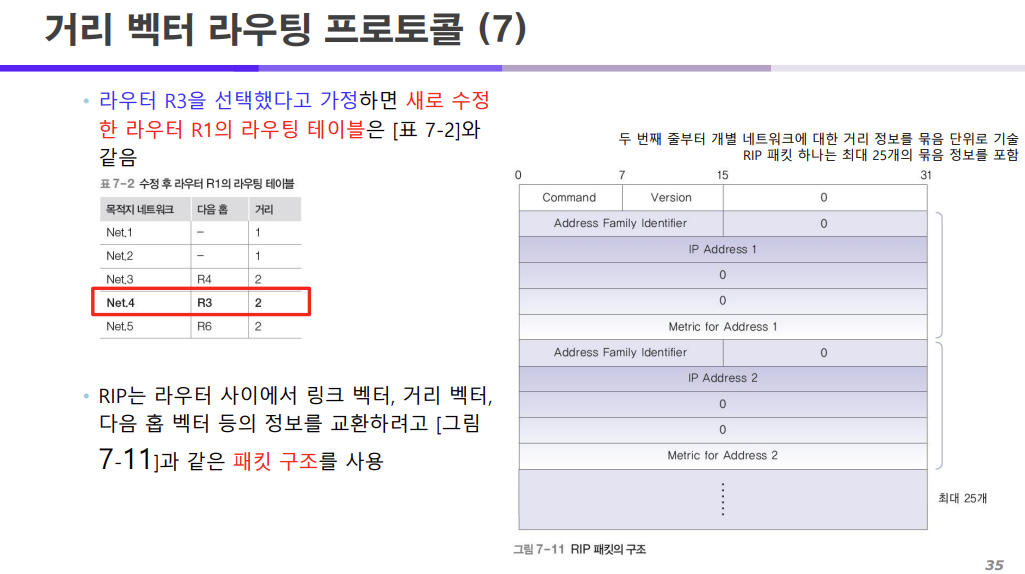
라우터 R3을 선택했다고 가정하면 새로 수정된 라우터 R1의 라우팅 테이블은 위와 같이
다음 홉이 R3로 변하게 되고 R3로 변하면서 거리 또한 3에서 2로 변하게 된 것을 확인할 수 있다.
RIP는 라우터 사이에서 링크 벡터, 거리 벡터, 다음 홉 벡터 등의 정보를 교환하기 위해서
오른쪽 표와 같은 패킷 구조를 사용한다.
오른쪽 표는 네트워크 계층에서 라우팅 프로토콜을 사용했을 때 사용되는 패킷 데이터의 헤더 부분이 이러한 필드로 구성되어 있다는 것을 보여준다.
표를 자세히 보면
- COMMAND,
- VERSION,
- ADDRESS FAMILY IDENTIFIER,
- IP ADDRESS,
- METRIC
이렇게 구성되어 있는 것을 알 수 있다.
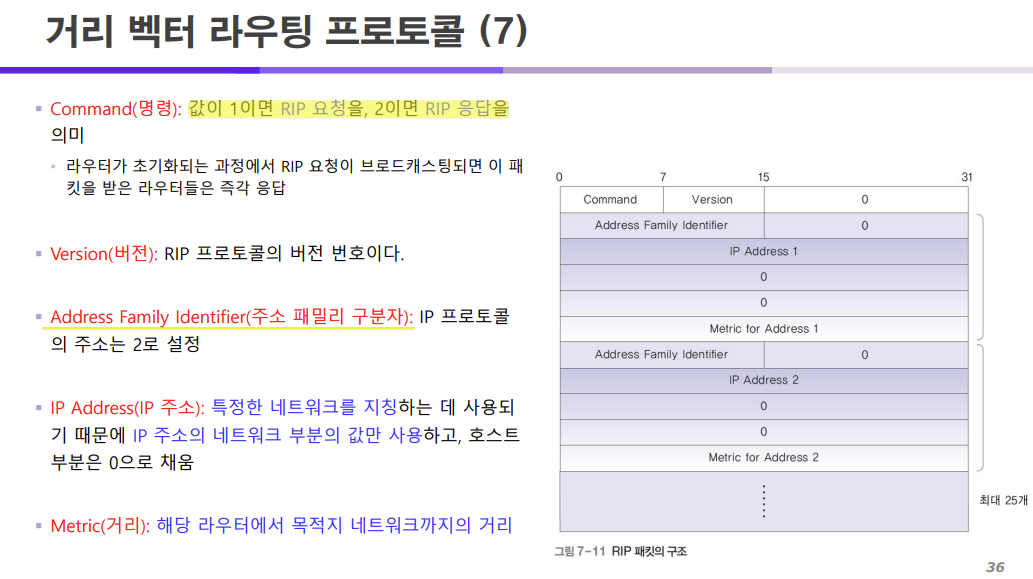
이 필드들은 기억할 필요는 없고 이러한 필드들로 구성된다는 것만 알아두자.

링크 상태 라우팅 프로토콜
링크 상태 라우팅 프로토콜에 대해서 살펴보자.
이 링크 상태 라우팅 프로토콜은 거리 벡터 라우팅 프로토콜의 단점을 보안하고자 나온 프로토콜이다.
거리 벡터 라우팅 프로토콜의 단점 :
거리 벡터 라우팅 프로토콜의 경우 전체 네트워크에서 각 개별 네트워크까지의 도착 거리 정보가 공유됐었다.
그러다 보니 네트워크가 1, 2, 3, 4, 5가 있으면 라우터 1은 총 5개의 데이터를 통째로 전달했어야 했고 이런 경우 네트워크의 규모가 커지게 되면 이러한 거리 정보가 원활하게, 정확하게 전달되는 것이 어렵다.
그래서 이를 해결하기 위해 링크 상태 프로토콜은 공유하는 정보의 범위를 조금 더 좁히도록 한다.
아까 거리 벡터는 전체에 대한 정보였다면, 링크 상태는 내 가까운 것들에 대한 정보만
즉
개별 라우터가 이웃 라우터까지의 거리 정보를 구한 후에
이를 네트워크에 연결된 모든 라우터에게 통보하는 형식으로 진행된다.
이때 통보하는 과정에서 사용하는 기법이 플러딩 기법이며
플러딩 기법을 사용해 홍수처럼 모든 네트워크에 있는 구성원들에게 데이터를 흘려보낸다.
근데 플러딩 기법의 경우 나갈 수 있는 모든 출구로 데이터를 흘려보내는 기법이라 네트워크의 크기가 크면 네트워크가 감당할 수 있는 용량을 넘을 수 있는 문제가 있기 때문에
데이터가 살아 있을 수 있는 시간 주기를 설정해 놓고 흘려보내거나
데이터가 지나갈 수 있는 라우터의 수를 지정해 놓고 흘려보내
일정 시간이 지나거나 일정 갯수의 라우터를 지나면 자연스럽게 사라지도록 설정한다.
이 링크 상태 라우팅 프로토콜의 대표적인 프로토콜이 바로 TCP/IP 기반의 인터넷에서 사용하는 "OSPF"라는 프로토콜이다.
링크 상태 라우팅 프로토콜도 거리 벡터 라우팅 프로토콜과 같이 내부 라우팅 프로토콜이다.

지금까지는 내부 라우팅 프로토콜에 대해서 봤고
이제는 외부 라우팅 프로토콜을 확인해보자.
A라는 자율 시스템과 B라는 자율 시스템, 서로 다른 자율 시스템 사이에서 공유하기 위해 사용되는 라우팅 프로토콜이 바로 외부 라우팅 프로토콜이다.
외부 라우팅 프로토콜의 대표적인 프로토콜이 바로 BGP이다.
BGP = 서로 다른 종류의 자율 시스템에서 동작하는 라우터가 라우팅 정보를 교활할 수 있도록 도와줌.
내부 라우팅 프로토콜의 경우 거리 정보를 가지고 서로 공유를 하며 중요하게 여겼지만
외부 라우팅 프로토콜의 경우 경로 벡터 프로토콜을 사용하는데 경로 벡터 프로토콜의 경우
경로에 관한 거리 정보 값이 크게 중요하지 않다.
그 이유는
외부 라우팅 프로토콜은 같은 자율 시스템 내에서가 아니라 서로 다른 자율 시스템끼리 공유하기 위해 사용되는 것이기 때문에 규모가 너무나 다르기 때문에 거리가 별로 따질 필요가 없다.
그래서 거리 정보 대신에 경로 벡터를 사용하고 거리 정보 값이 크게 중요하지 않다.
또한 외부 라우팅 프로토콜의 경우 갯수도 적기에 크게 중요하지 않다.
외부 라우팅 프로토콜의 경우엔 단순 상대방이 어디에 있는지에 대한 경로에 정보만 가지고 라우팅을 진행한다.
아래 메시지들은 가볍게 읽어만 보자.
