
-
IP 프로토콜은 비연결형 방식의 프로토콜이다.
-
IP 프로토콜의 주요 기능은 패킷을 분할하고 병합하는 기능이며
(위의 계층에서 내려온 데이터가 너무 크면 분할해서 전달할 수 있음) -
데이터 체크섬은 제공하지 않고 헤더 체크섬만 제공한다.
(체크섬을 만들 때 전체 데이터를 가지고 체크섬을 만드는 것이 아니라 헤더 부분의 정보를 가지고 체크섬을 만듦) -
Best Effort 원칙에 따른 전송 기능을 제공
(최선을 다해 데이터를 전달하지만 데이터가 목적지에 당도하는지에 대해서는 신경쓰지 않는다.)
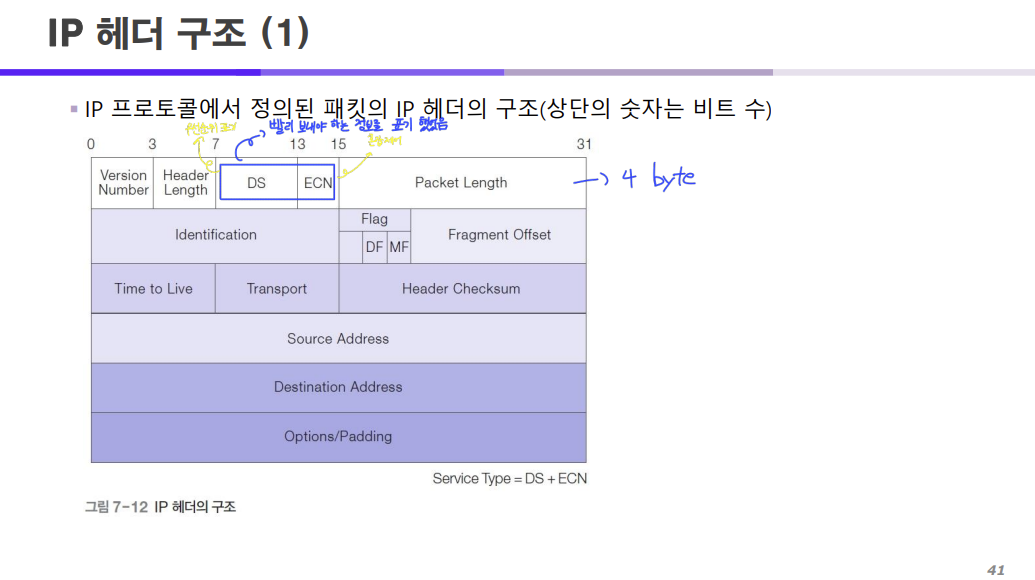
IP 프로토콜에서 IP 헤더는 이와 같은 구조로 형성되어 있다.
각각의 줄은 4바이트로 구성되어 있으며 총 6개의 줄로 이 헤더의 용량은 24바이트이다.
근데 주로 마지막 줄인 OPTIONS 부분은 사용하지 않기 때문에 20바이트만 헤더로써 할당을 받는다.
아래에서는 각각의 필드들이 하는 역할에 대해서 살펴보자.

- DS/ECN
DS/ECN은 8비트가 할당되어 있는데
예전에는 이 부분이 합쳐져서 SERVICE TYPE이라는 필드로 정의되어
패킷의 우선순위, 지연, 전송률, 신뢰성 등의 값을 지정했다.
이 service type은 패킷을 다른 패킷보다 먼저 보내거나 늦게 혹은 반드시 목적지에 당도하도록 설정 값을 매기는 필드였다.
이 service type의 앞에 3비트는 우선순위를 표기하는 용도로 사용된다.
그리고 뒤에 각각 1비트는 지연, 전송률, 신뢰성을 표기하도록 하고
마지막 2비트는 아직 정해둔 것이 없고 미정으로 둔 것이다.
근데 지금은 필드가 8비트를 가지고 2개로 나뉘어 지면서 6비트는 DS로 2비트는 ECN으로 사용된다.
ECN은 우리가 앞에서 봤듯이 혼잡이 생겼을 때 이를 알리는 용도로 사용되었다.

ECN은 2비트로
- 00 : IP 패킷이 ECN 기능을 사용하지 않는다.
- 01 : TCP 프로토콜도 ECN 기능을 지원한다.
- 10 : TCP 프로토콜도 ECN 기능을 지원한다.
- 11 : 라우터가 송신 호스트에 혼잡을 통지할 때 사용한다.
이렇게 표현된다.
DS 필드는 6비트로 이전에 service type 필드가 했던 역할을 진행한다.
DS 필드 값은 우선순위, 차등 서비스의 기준이 되는 레이블 값으로 64개의 트래픽 클래스를 정의한다.
DS 서비스는 비교적 단순한 원리에 의하여 차등화된 서비스를 제공하지만
내부적인 처리 과정은 복잡한 구조에 의하여 이루어진다.

다음으로 IP 프로토콜은 상위 계층에서 내려온 전송 데이터가 패킷 하나로 전송하기에 너무 큰 경우 이를 분할해 전송하는 기능을 제공한다.

필드는 이 부분이며 각각의 필드 부분이 하는 역할을 살펴보자.

- Identification
Identification 필드는 우리가 일반적으로 데이터를 분할하지 않고 보낼 때와 데이터를 분할하고 보낼 때 이 2가지를 구분하기 위한 용도로 사용된다.
데이터를 쪼개서 보내는 경우엔 나중에 데이터를 다시 합쳐서 읽어야 하기 때문에
이러한 Identification 필드가 필요한 것이다.
쪼개진 데이터들은 모두 동일한 값이 Identification 필드에 저장되고
쪼개지지 않은 데이터는 Identification 필드에 그냥 번호가 매겨진다.
잠시 예를 통해 확인해보자.
1번 데이터 = 쪼개지지 않음 = Identification 필드 값 = 1
2번 데이터 = 5개로 쪼개짐 = 쪼개진 모든 데이터의 Identification 필드 값 = 2
3번 데이터 = 3개로 쪼개짐 = 쪼개진 모든 데이터의 Identification 필드 값 = 3
즉 쪼개진 데이터는 각각의 패킷 데이터들은 Identification 필드에 동일한 번호가 기재한다.
이렇게 구성하게 되면 수신하는 측에서 데이터를 받을 때 어떤 데이터들이 쪼개진 데이터인지 확인할 수 있다.
이렇게 되면 이후 병합할 때도 쉽게 병합이 가능해진다.
- DF
DF 필드의 경우 패킷의 분할을 막는 역할을 한다.
DF 필드의 값을 1로 주게되면 해당 패킷을 분할하지 못하도록 막을 수 있게 된다.
이를 사용하는 이유는 수신 호스트가 분할되어 입력된 패킷들을 병합하는 기능이 없을 경우 사용된다.
따라서 중간에 네트워크에서 자신이 처리 가능한 패킷의 크기보다 큰 IP 패킷에 DF 필드가 1인 경우 분할 기능을 수행하지 않고 패킷을 버리게 된다.
어쳐피 보내도 수신 호스트가 합치는 기능이 없기에 사전에 크기를 넘어버리면 버려버리는 것이다.

- MF
MF는 분할된 데이터를 연속적으로 보내면서 끝을 알려주는 기능이다.
우리가 분할된 데이터를 보내는 경우 이 데이터들은 연속해서 전동되기에 MF 필드 값을 1로 설정해
아직 분할된 데이터를 보내는 중이야!
이렇게 알려줄 수 있다.
그리고 이후 MF 필드 값이 0인 데이터가 도착하면
아 이제 분할된 데이터가 끝났음을 인식하여 알 수 있도록 하고 이후 병합할 때 사용된다.
Fragment Offset
Fragment Offset은 데이터가 4개로 분할되었을 때 분할된 데이터가 각각 어느 위치에 있었는지 알기 위한 기능이다.
우리가 데이터를 4개의 패킷으로 쪼개게 되면 각각이 어느 위치에 존재했던 패킷인지 알고 있어야 한다.
따라서 이를 기록해 두는 곳이 바로 Fragment Offset 부분이다.
위 PPT에는 Fragment Offset이 12비트가 할당되어 있다고 하지만 이는 틀렸고
13비트가 할당된 부분이며
Fragment Offset 안에 저장되는 값은 분할 전 데이터에서 위치하는 상대 주소 값이 저장된다.
그리고 8바이트의 배수로 데이터를 쪼개게 된다.
PPT 수정
= 12비트 -> 13비트, 8비트 -> 8바이트
이제

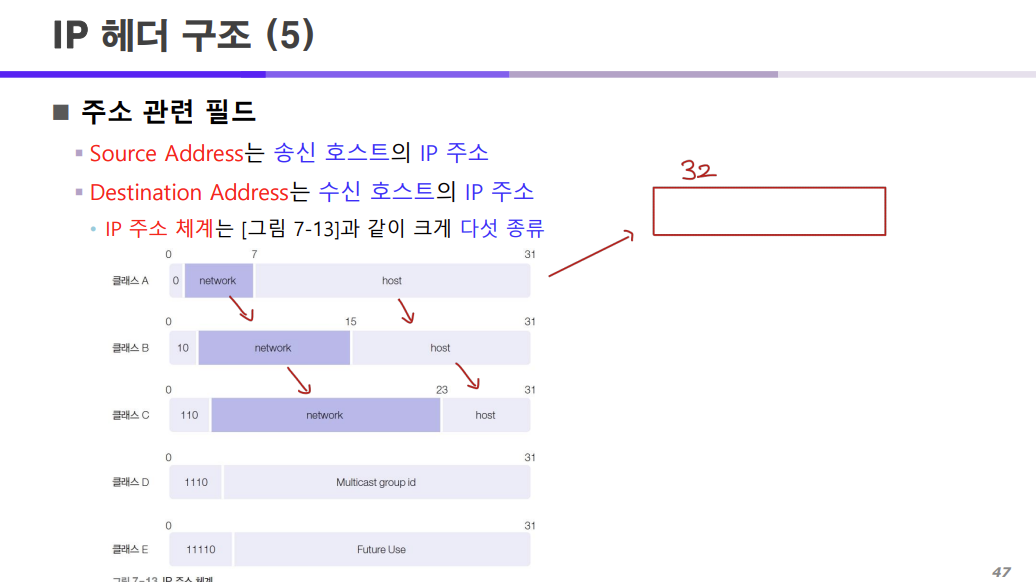
Source Address와 Destination Address 필드 부분에 대한 내용을 보자.
Source Address은 송신 호스트의 IP 주소를 저장하고
Destination Address은 수신 호스트의 IP 주소 값을 저장한다.
예전에는 IP 주소를 할당할 때 위 사진과 같이 클래스 A, B, C, D, E 5가지 클래스로 구분해서 할당을 진행했다.
클래스 A, B, C는 유니캐스팅에서 이용되고
클래스 D는 멀티캐스팅
클래스 E는 미정으로 나중에 정해지면 쓰겠다고 한 클래스이다.
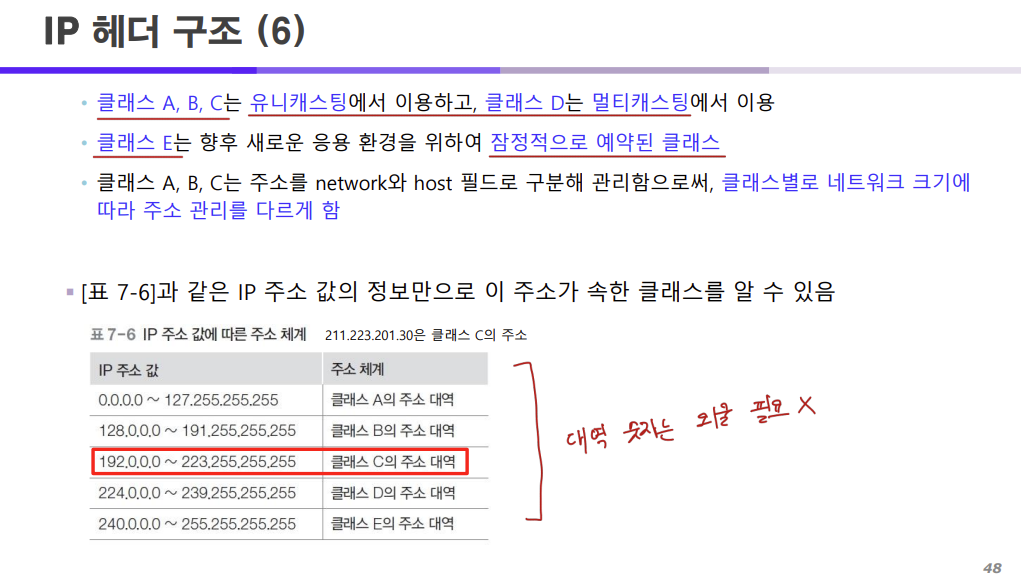
위 각각의 클래스와 클래스의 대역은 외우지 않아도 되고 시험에 나오지 않는다.
다만 IP 프로토콜을 공부할 때 자주 나오는 내용들이다.
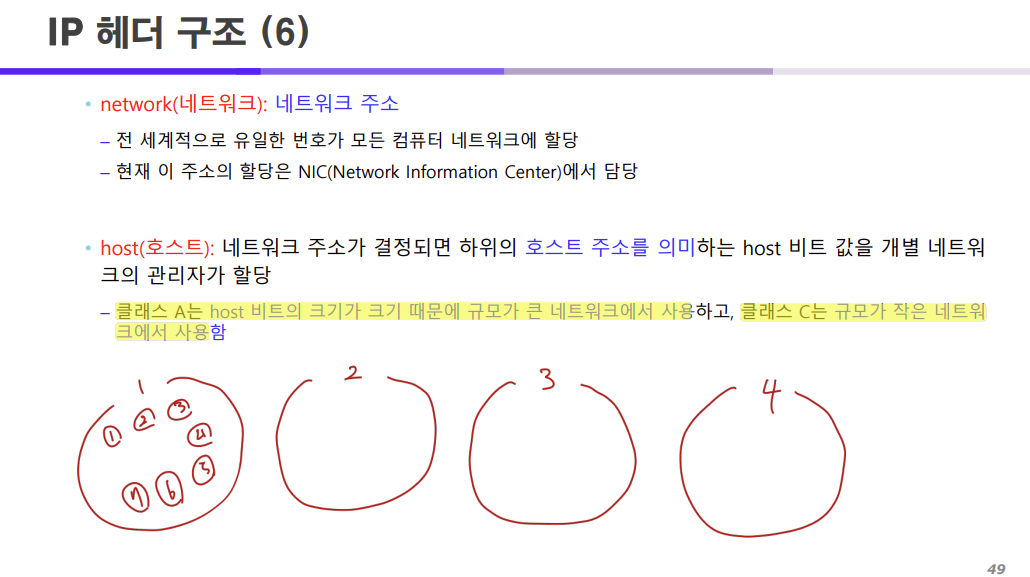
우리가 Source Address와 Destination Address를 볼 때 network와 host가 있었는데
각각은 모두 네트워크의 주소와 호스트의 주소를 의미한다.
위 그림과 같이 각 마을의 번호 1, 2, 3, 4가 네트워크의 주소이고
마을 내에 집들이 존재하는데 이 집들을 구분하기 위해 매긴 번호가 바로 호스트 주소이다.

그럼 이제 마지막으로 IP 프로토콜의 헤더 중 1번째 줄과 3번째 줄, 마지막 줄에 있는 필드에 대해서 살펴보자.
1번째 필드는 다음과 같이
- Version Number
- Header Length
- DS
- ECN
- Packet Length
가 존재하고
DS와 ECN은 이전에 다뤘으니 잠시 넘어가자.

- Version Number
먼저 Version Number은 IP 프로토콜의 버전 번호를 기록한다.
현재 IP 프로토콜의 버전은 IPv4, IPv6 이렇게 존재하며 이 둘은 크기 차이라고 생각하면 된다.
- Header Length
Header Length는 헤더 길이에 대한 정보가 저장되는 부분으로 헤더 길이를 저장할 때는 현재 우리가 보는 헤더는 총 6줄이지만 마지막 줄은 거의 사용하지 않기 때문에 일반적으로 5가 기록된다.
마지막 줄을 뺀 5를 이곳에 기록한다.
- Packet Length
Packet Length 필드는 IP 헤더까지 포함한 전체 데이터의 길이를 저장하는 부분이다.
일반적으로 IP 패킷의 크기는 8192 바이트를 넘지 않는다.

다음으로 3번째 줄에 있는 필드들을 확인해보자.
3번째 줄에 존재하는 필드들은 아래와 같고
- Time To Live
- Transport
- Header Checksum
으로 구분된다.
- Time To Live
Time To Live는 패킷 전송 과정에서 패킷이 올바른 목적지를 찾지 못하게 되면 수신 호스트에 도착하지 못하고 네트워크 내부를 계속 떠돌게 되는데 이러한 현상을 막기 위해
일정한 시간을 지정해 이 시간안에 도착하지 못하면 패킷이 사라지도록
패킷의 생존 기간을 지정하는 필드이다.
Time To Live가 지나 사라진 패킷은 버려지고 패킷 송신 호스트에 ICMP 오류 메시지가 전달된다.
- Transport
Transport은 위의 계층이 무슨 프로토콜을 사용하는지 알리는 목적으로 사용된다.
Transport 필드 값에 따라 6은 TCP, 17은 UDP, 1은 ICMP로 구분된다.
- Header Checksum
Header Checksum은 전송 과정에서 발생할 수 있는 헤더 오류를 검출하는 기능이다.
이 Header Checksum은 헤더의 정보를 가지고 체크섬을 만든다.
따라서 헤더에 대한 오류 검출만 진행하고 데이터 오류 검출은 하지 않는다.

가장 아래 줄에는
- Options
- Padding
이 존재한다.
- Options
Options은 네트워크 관리나 보안처럼 특수한 용도로 이용된다.
- Padding
Padding은 IP 헤더의 크기가 32비트인데
이 필드 전체의 크기가 32 비트에 맞지 않으면 뒤에 0을 붙여서 32 비트를 채우는 것이 패딩이다.
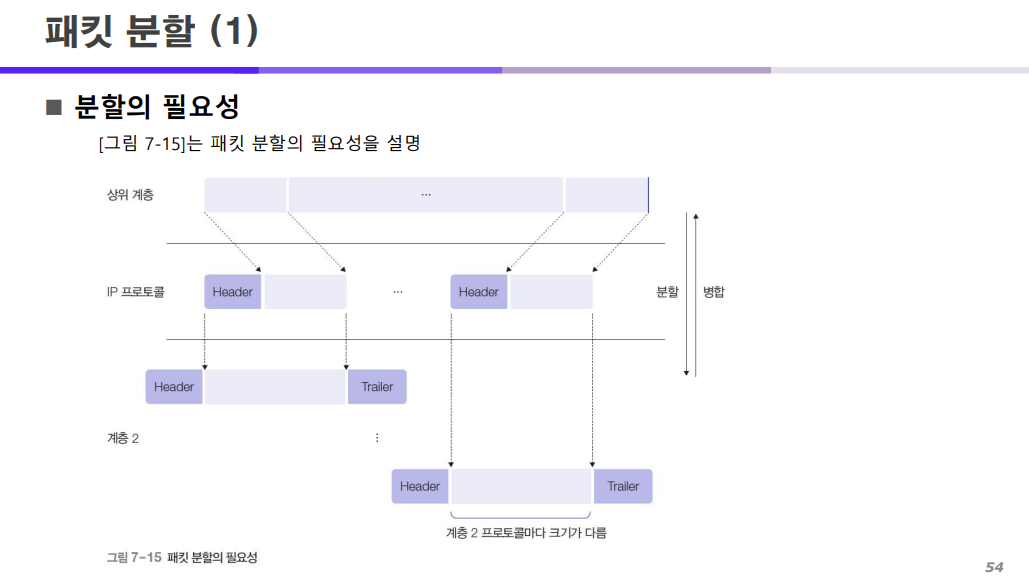
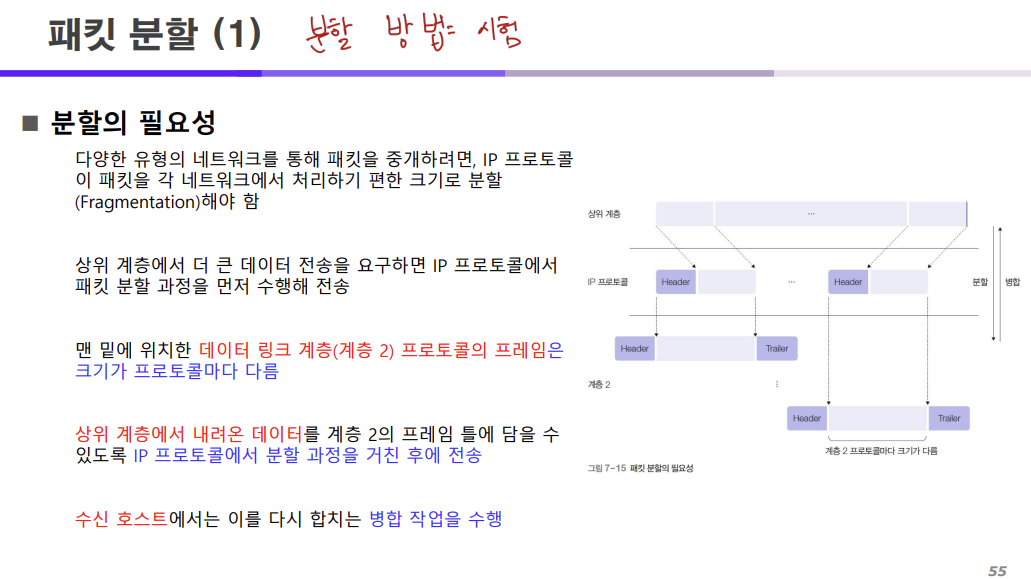
분할이 필요한 이유는 네트워크에 데이터를 흘려 보낼 때 제한된 크기에 맞춰서 데이터를 흘려보내기 위해 분할을 진행하는 것이다.
조금 더 자세하게 말하면
2계층(데이터링크계층)에서 사용되는 프로토콜의 종류(토큰링, 토큰버스 등등)에 따라 사용되는 프로토콜도 다르다.
따라서 데이터링크 계층에서 사용하는 프로토콜의 종류에 따라 이 프레임의 크기도 달라지는데
우리는 이 프레임의 크기에 맞춰서 데이터를 쪼개고 그 아래 계층인 데이터 링크 계층으로 보내야 하는 것이다.
그래서 위의 계층에서 내려온 데이터를 IP 계층에서 데이터 링크 계층의 프로토콜의 종류에 따라 달라진 프레임 크기에 맞춰서 데이터를 분할하도록 하고
분할된 데이터를 데이터링크 계층과 물리 계층을 통과해 전달되는 것이다.
그럼 이제 분할의 예를 한 번 살펴보자.
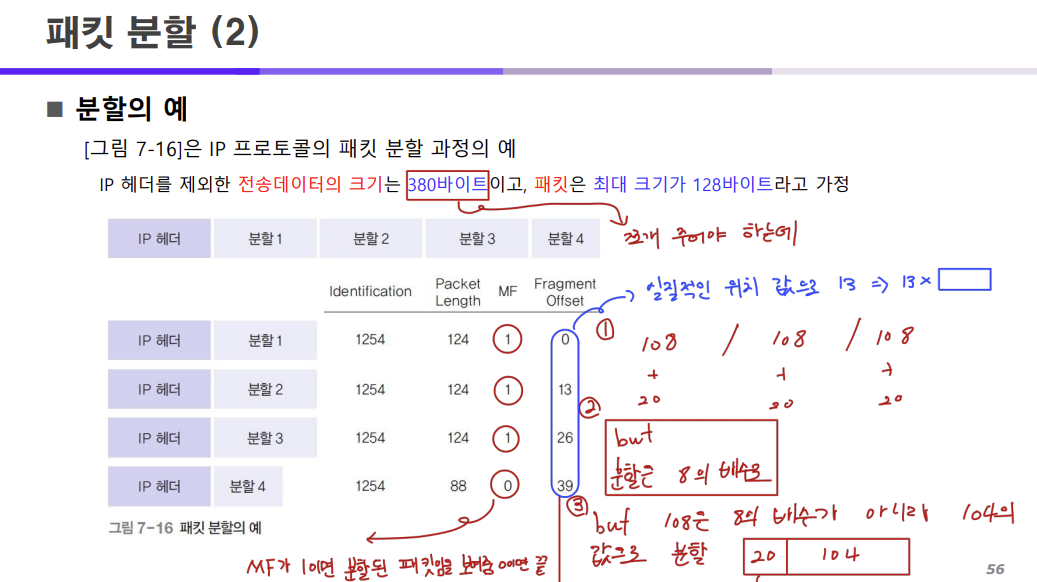
위에서 내려온 데이터의 크기 - 380 바이트
패킷의 최대 크기 - 128 바이트
그냥 가볍게 128 바이트로 쪼개면 되는 것이 아니라 다음 과정을 거쳐야 한다.
우리가 일반적으로 20 바이트에는 헤더에 대한 정보가 담긴다고 했으니
패킷의 128 중 20을 뺀 108 바이트에 데이터를 저장할 수 있다.
그럼 380 바이트를 108 바이트에 집어 넣을 수 없으니까 쪼개야 하는데
이 380 바이트는 다음과 같이 쪼개진다.
우리가 위에서 IP 헤더의 2번째 줄에 있는 Fragment Offset이 데이터는 8의 배수로 분할된다고 했기 때문에
108은 8의 배수가 아니기에 108을 8로 나누면 104와 4가 남는다.
따라서 데이터는 104의 크기로 저장될 수 있다.
그럼 데이터는 104 바이트가 저장될 수 있으니까
380 = 104 + 104 + 104 + 68
이렇게 나누어지기에 380 데이터는 104, 104, 104, 68로 나뉘어진다.
이후 IP 헤더의 크기를 더해주면 패킷의 전체 크기는 다음과 같이
124, 124, 124, 88이 된다.
패킷 분할 계산 방법
조건 :
전송 데이터의 크기 = 380
패킷의 최대 크기 = 128
풀이 :
128 - 20(헤더의 크기) = 108
108을 8로 나눈 나머지 = 4
108 - 4 = 104이때 104가 최대 데이터의 크기
따라서 380을 최대 데이터로 분할하면 104 + 104 + 104 + 68이 나옴
각 최대 데이터에 헤더 값을 추가하면 124 + 124 + 124 + 88이 나옴즉 380은 4개의 데이터인 104, 104, 104, 68로 나뉘어지고
각각의 데이터는 헤더를 더해 크기가 124, 124, 124, 88인 패킷이 된다.


이를 설명한 내용이 위와 같다.
Fragment Offset의 값은 실제 위치 값으로 데이터를 쪼개기 전에 각 부분들어 어느 위치에 있었는지에 대한 설명이다.
기재되는 값은 상대적인 값이 기재되고
실제 위치는 x 8을 해줘야 한다.
Fragment Offset의 값 X 8을 하면 나오는 실제 위치가 나온다.
실제 위치 = 0, 104, 208, 312를 의미한다.
MF 필드는 1일 때 뒤에 분할된 데이터가 온다는 의미이고
0이면 분할된 데이터 중에서 마지막 데이터라는 의미이다.
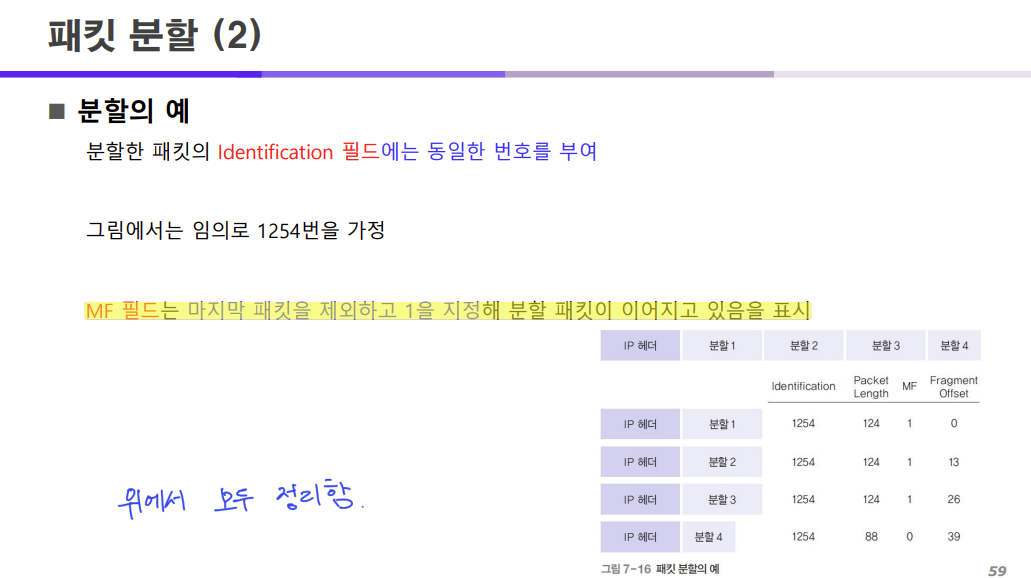
Identificaion 필드의 경우 동일한 숫자로 표함함으로써 위 4개의 패킷이 하나의 데이터라는 것을 의미한다.
Identificaion에 할당된 숫자는 모두 임의의 값이지만 하나의 숫자로 표현됨으로써 하나의 데이터라는 것을 표현한다.
