논문 원문 링크 : https://arxiv.org/pdf/2311.18825
Abstract
- video에서 사람의 행동을 인식하려면 공간적 & 시간적 이해가 필요한데, 기존의 대부분의 동작 인식 모델에는 균형 잡힌 시공간적 이해가 부족함.
- 이 연구에서는 space와 time의 cross-attention(CAST)라는 새로운 2 stream 아키텍처를 제안
-> RGB 입력만으로 영상의 균형 잡힌 균형 잡힌 시공간적 이해함 - space & time expert 모델이 정보를 교환하고 시너지 예측을 할 수 있게 함
- 기존 방법의 성능이 데이터 세트의 특성에 따라 변동하는 반면, proposed method는 데이터 세트에서 일관되게 우수한 성능을 보임
1. Introduction
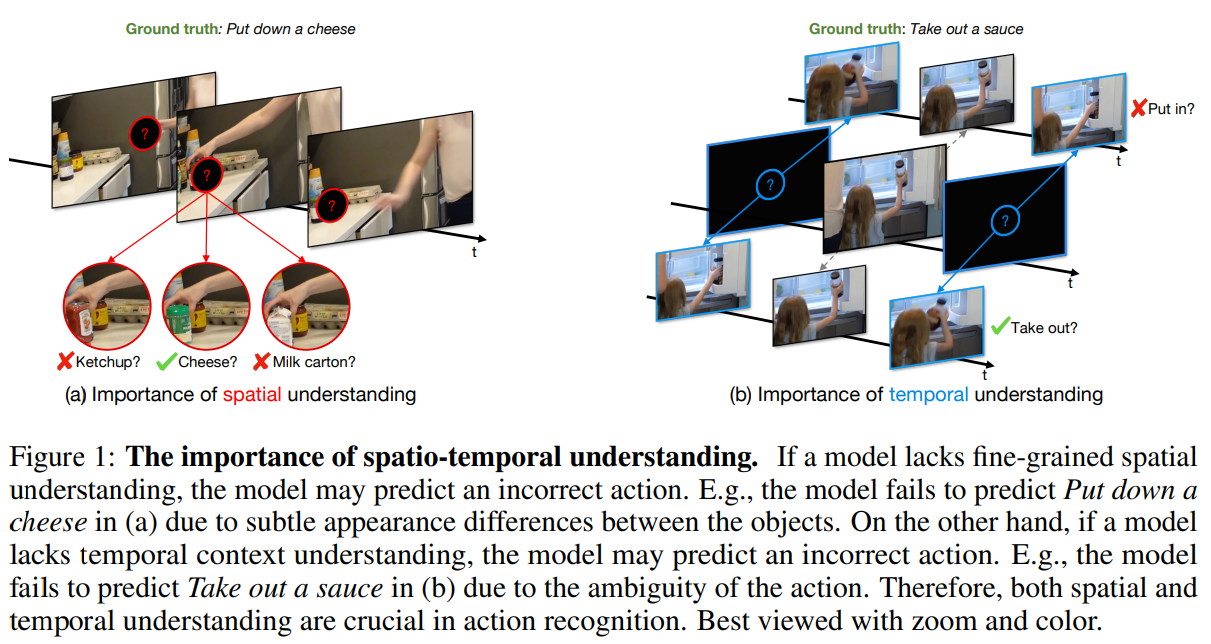
- 모델이 세밀한 spatial(공간적) 이해가 부족하면 잘못된 action을 예측할 수 있음
e.g.) 모델은 물체 간의 미묘한 외관 차이로 인해 (a)에서 '치즈를 내려놓기'를 예측하지 못함 - 모델이 temporal(시간적) 맥락 이해가 부족하면 잘못된 action을 예측할 수 있음
e.g.) 모델은 action의 모호성으로 인해 (b)에서 '소스를 꺼내는' 동작을 예측하지 못함
=> 따라서 action recognition(동작 인식)에서는 spatial 이해와 temporal 이해가 모두 중요함
Contributions
- two-stream 아키텍처인 CAST로 균형 잡힌 spatial & temporal understanding 문제를 해결
- 다양한 데이터셋에 대해 실험을 수행하여 CAST의 효과를 입증
- 광범위한 ablation study 진행
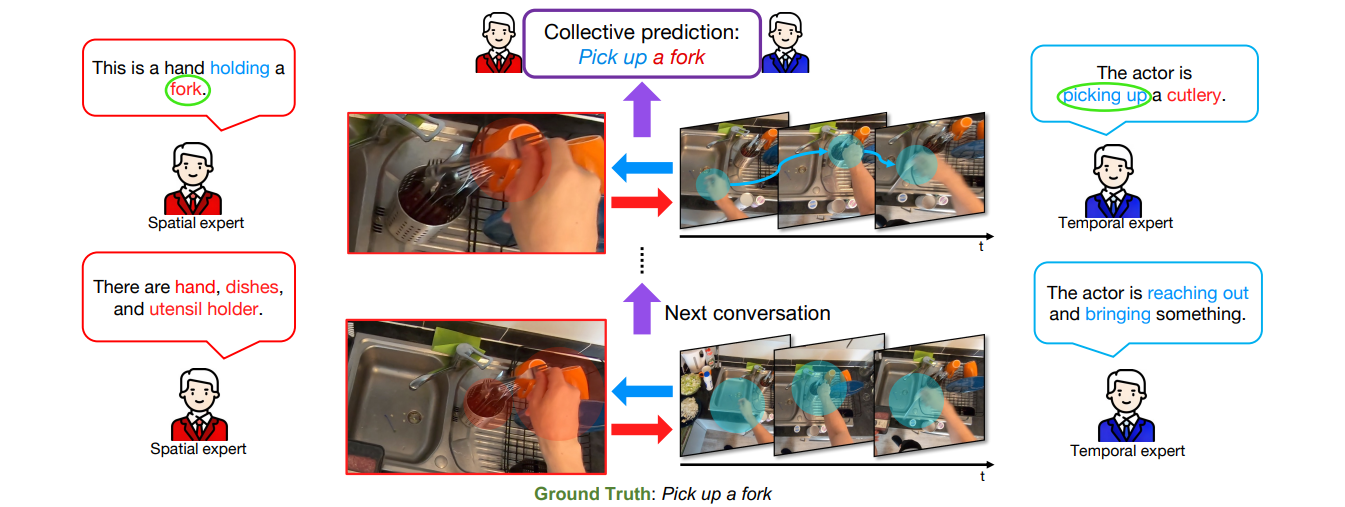
High-level illustration of the proposed method
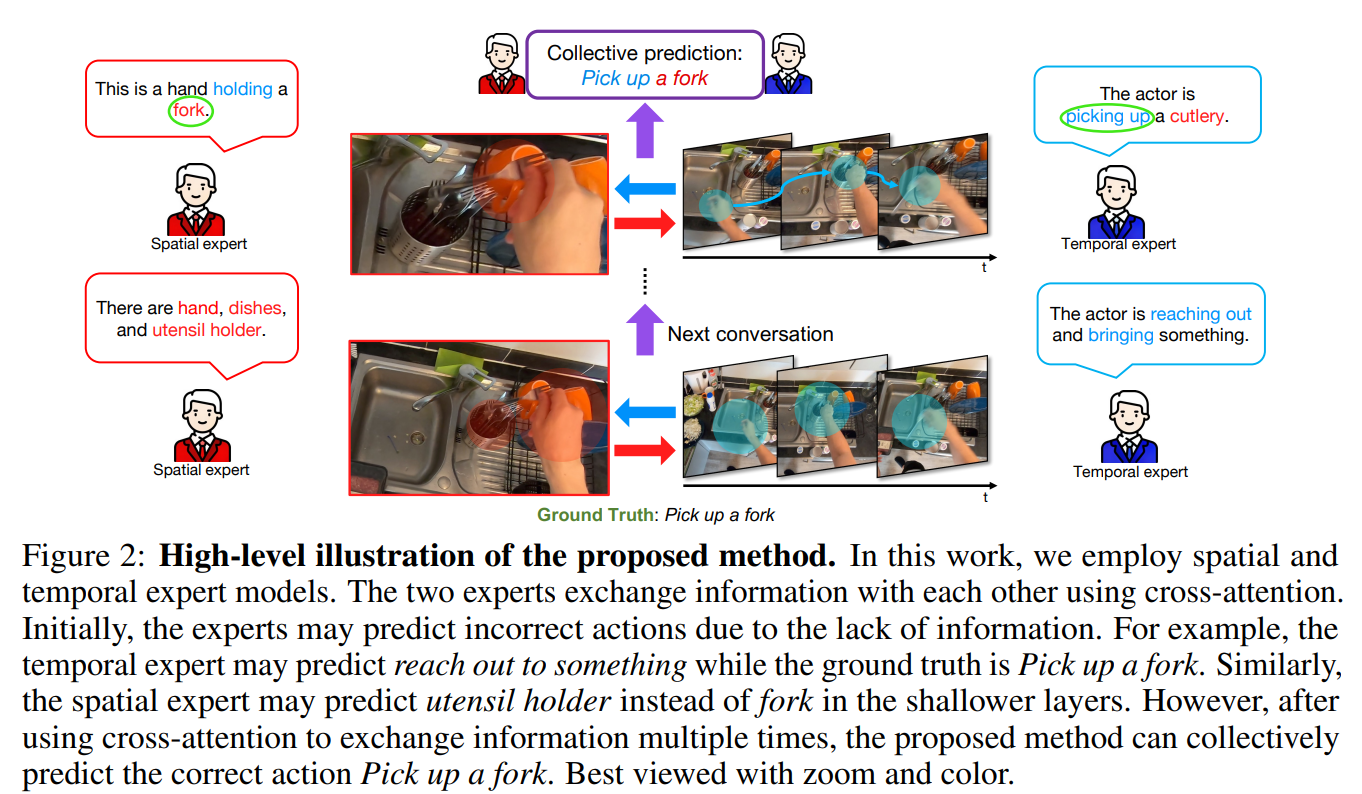
- 이 작업에서는 spatial, temporal expert 모델을 사용합니다. 두 expert는 cross attention를 통해 서로 정보를 교환함
- 처음에는 expert가 정보 부족으로 인해 잘못된 action을 예측할 수 있음
- 예를 들어, temporal expert는 '포크를 집어 들기'라는 GT가 있는데도 '무언가에 손을 뻗기'라고 예측할 수 있음
- 마찬가지로 spatial expert는 더 얕은 층에서 포크 대신 식기 홀더를 예측할 수 있음
- 그러나 cross attention를 사용하여 정보를 여러 번 교환한 후 4포크를 집는 올바른 행동을 종합적으로 예측할 수 있음
3. Method
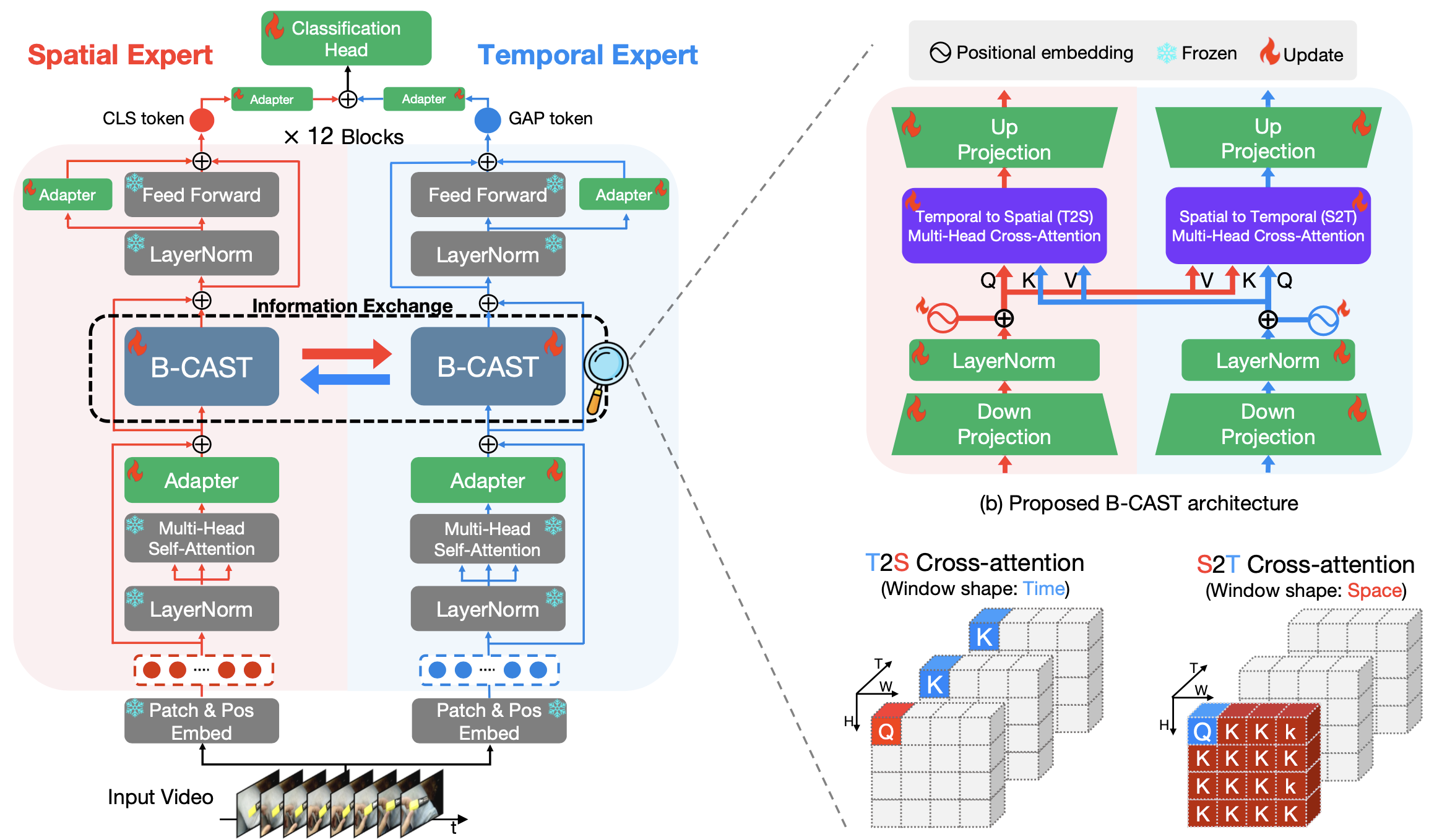
Overview
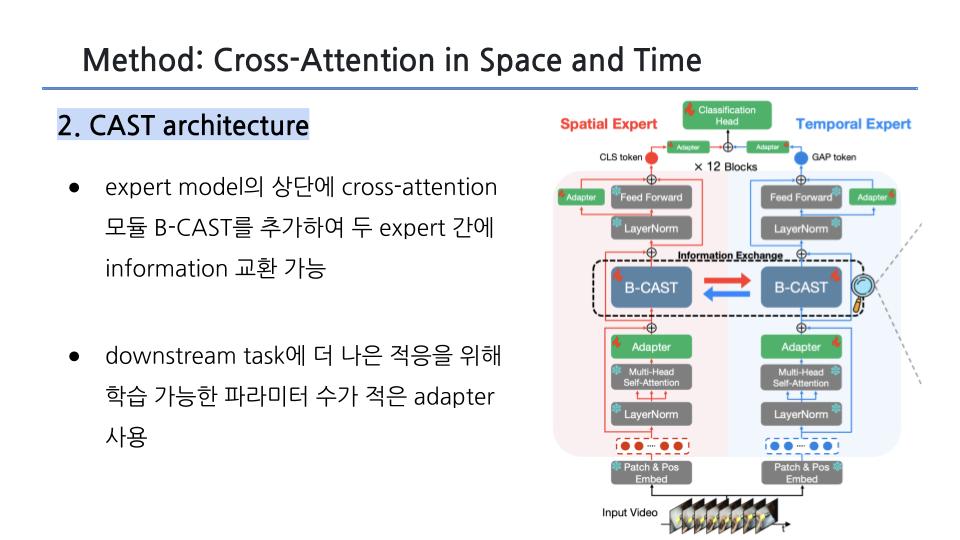
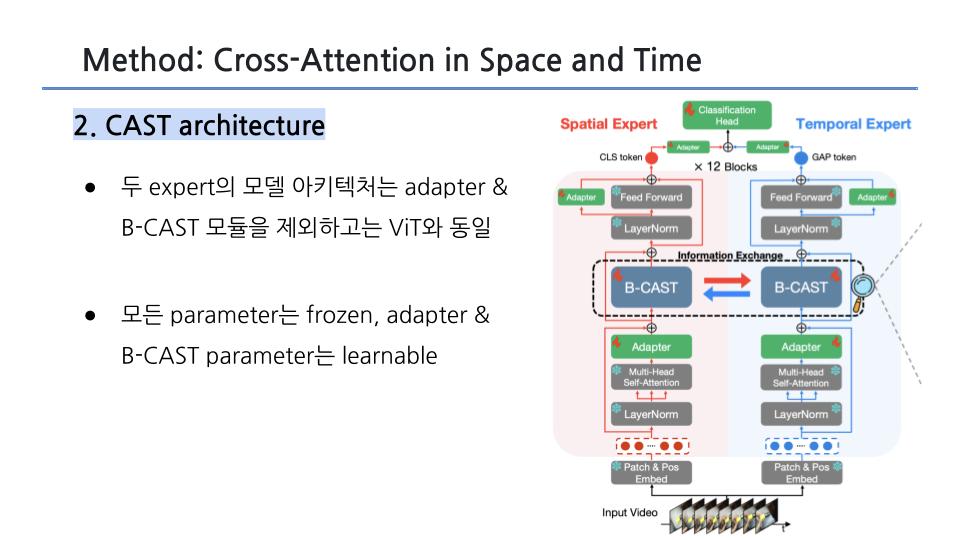
(a) CAST는 frozen(고정된) spatial & temporal expert models을 사용함
- expert model의 상단에 cross-attention 모듈 B-CAST를 추가하여 두 전문가 간에 정보를 교환하게 함
- 더 나은 적응을 위해 전문가에게 학습 가능한 파라미터 수가 적은 어댑터를 사용합니다.
(b) B-CAST는 video data의 시공간적 특징을 더 잘 이해할 수 있도록 시간-공간(T2S) 및 공간-시간(S2T) cross-attention로 구성됨
- 효율적이고 효과적인 학습을 위해 병목 현상 어댑터에 크로스 어텐션을 통합합니다.
- 각 expert에 대해 별도의 위치 임베딩을 사용합니다.
(c) T2S와 S2T cross-attention
- 쿼리가 주어지면 모델은 T2S에서는 시간 축을 따라 어텐션하는 반면, 모델은 S2T에서는 공간 축을 따라 attention 수행함
Methods


Dataset
- Action recognition
2종류의 context 잘 이해하도록, 2가지 biased dataset 이용
- Static biased dataset : Kinetics-400 (K400)
- Temporal biased dataset : Something-Something-V2 (SSV2)
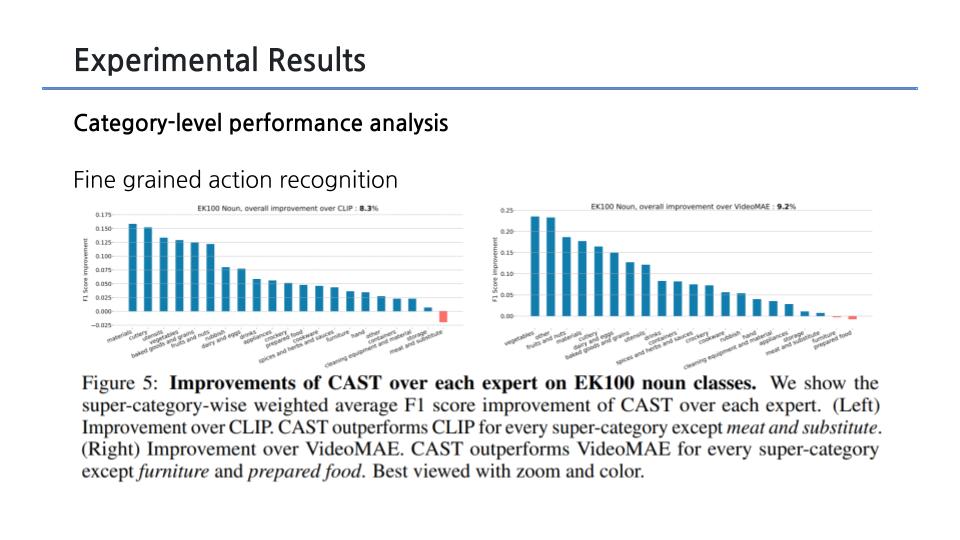
- Fine-grained action recognition
EPIC-KITCHENS-100 (EK100) : action을 동사와 명사의 조합으로 정의
- 각 dataset에서 잘 작동하는 baseline model 종류가 달랐음 ⇒ 2명의 expert가 있다고 생각 가능
→ 두 expert를 같이 쓰면 어떨까?, 2 stream networks를 사용하는 건 어떨까?
input video를 2개의 CNN으로 나눠서 spatial, temporal stram하는 기존 network ⇒ computation cost #
⇒ computational cost 낮추도록 구현하자
Method
2 expert간의 information exchange 하도록 하자
ver 1
- CLIP : spatial expert
- Video MAE : temporal expert
<2개의 independent expert 사용 방법>
1. ViT based로 구조 with frozen weights
2. adapter 이용해서 parameter-efficient learning (end-to-end 로 학습하는 것보다 굿)
3. CAST 기법 적용하여 info exchange
-
B-CAST : bottleneck 구조 내부에서 정보를 교환하는 것
-
2가지 버전의 attention 기법 이용
- T2S : temporal 정보를 흡수한 spatial feature를 만듦 (보틀넥에서 정보 들어가는 순서 다름)
- S2T : 반대임
Experiments

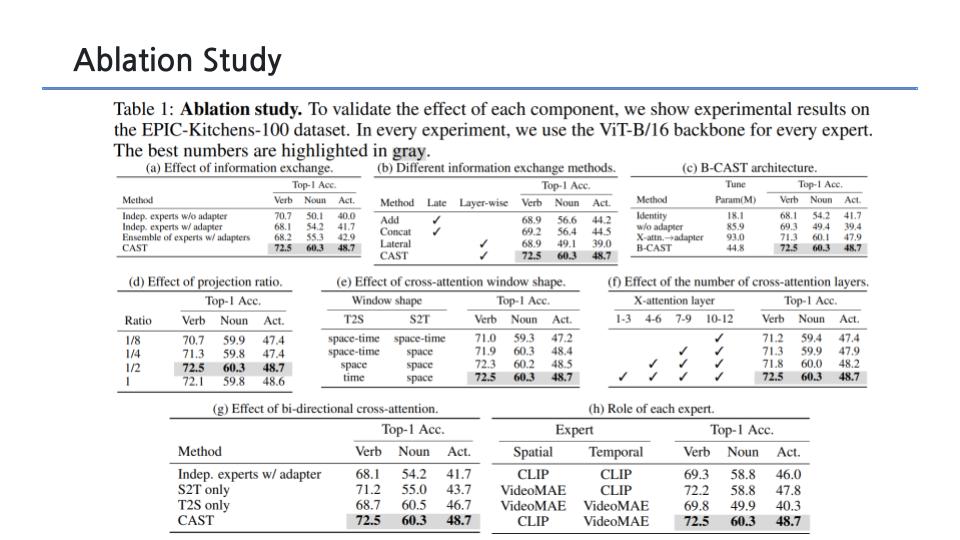
info exchange 기법으로 cross attention 쓴 이유
- add, concat, lateral 써보니까 cross attention이 젤 성능 좋더라~
why B-CAST 구조?
- baseline들과 성능 비교
- bottle next내부에서 cast 수행하는 게 실험적으로 젤 좋았음
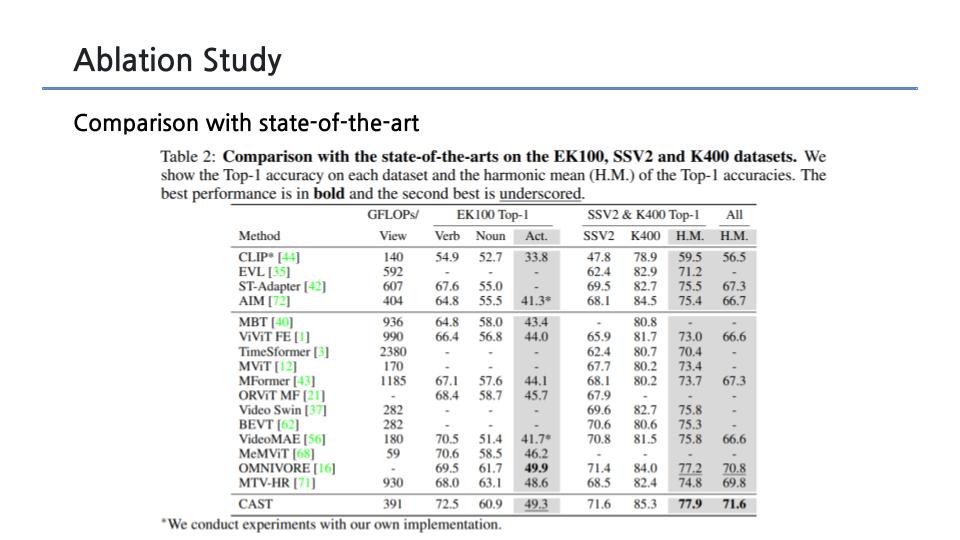
SOTA와 비교
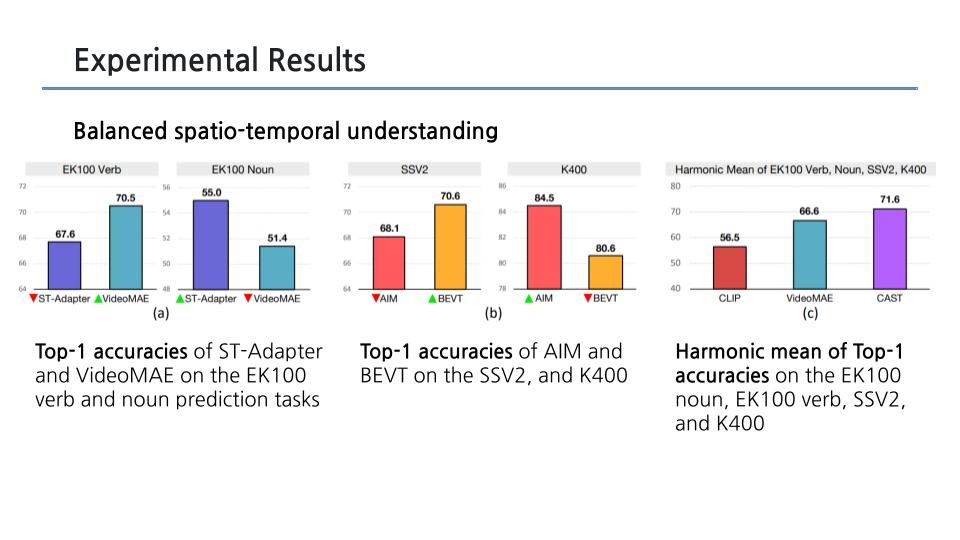
- harmonic mean of 4가지 acc 값 : 4가지 데이터셋에 적용했을 때의 acc (static biased / temporal biased dataset 2가지씩)
- hight resolution 데이터 쓰는 SOTA 보다도 잘 됐음
Future Work
RGB+Audio+Text 의 각각의 expert로 취급해서 multi modal 개발 가능

제 논문이네요 ㅎㅎ 리뷰감사합니다!