InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions [CVPR 2023 Highlight]
논문 리뷰
목록 보기
7/16
0. Abstract
- 최근 몇 년간 대규모 비전 트랜스포머(ViT)가 크게 발전한 것에 비해 CNN 기반의 대규모 모델은 아직 초기 단계에 머물러 있음
- 이 연구에서는 ViT와 같이 매개변수와 학습 데이터를 늘려서 이득을 얻을 수 있는 새로운 대규모 CNN 기반 기초 모델인 InternImage를 소개함
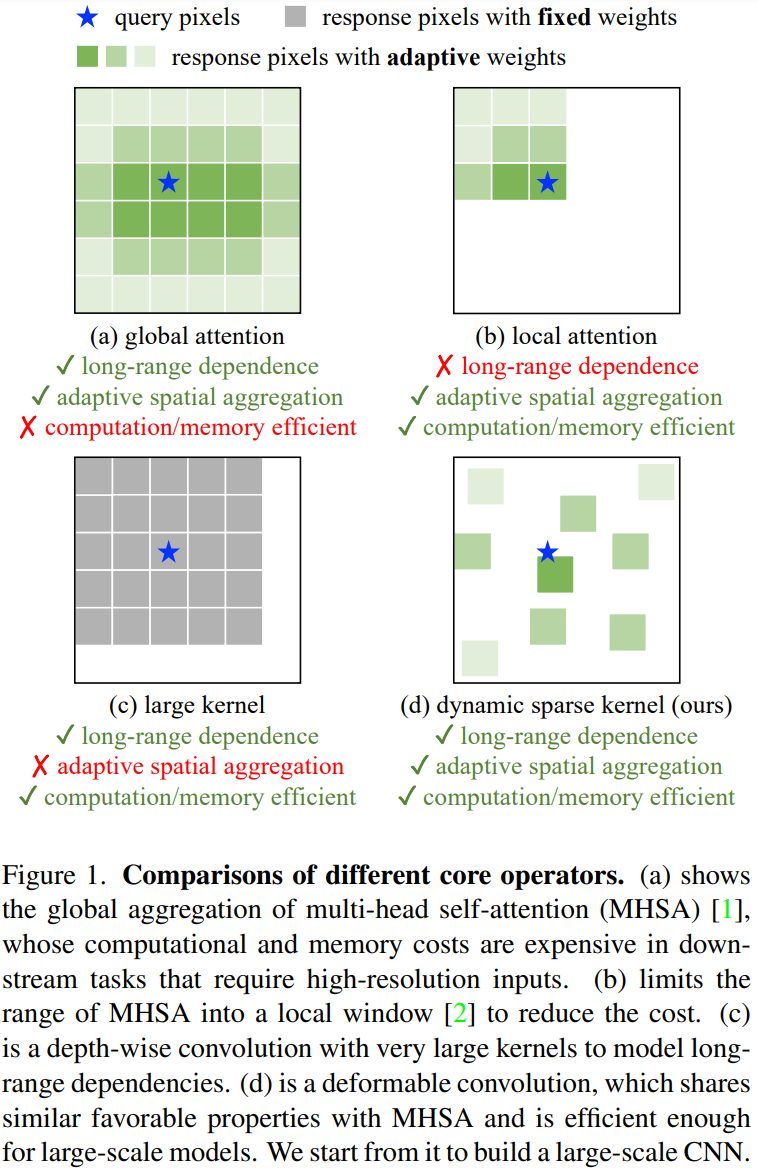
- 대규모 고밀도 커널에 초점을 맞춘 최근의 CNN과 달리, InternImage는 변형 가능한 컨볼루션(deformable convolution)을 핵심 연산자로 채택하여 detection 및 segmentation과 같은 downstream 작업에 필요한 큰 유효 수용 필드를 가질 뿐만 아니라 input & task 정보에 따라 조절되는 adaptive spatial aggregation를 갖춤
- 그 결과, 제안된 InternImage는 기존 CNN의 엄격한 귀납적 편향성을 줄이고 ViT와 같은 대규모 데이터에서 대규모 파라미터로 더 강력하고 견고한 패턴을 학습할 수 있게 함
- 이 모델의 효과는 ImageNet, COCO, ADE20K 등 까다로운 벤치마크에서 입증됨
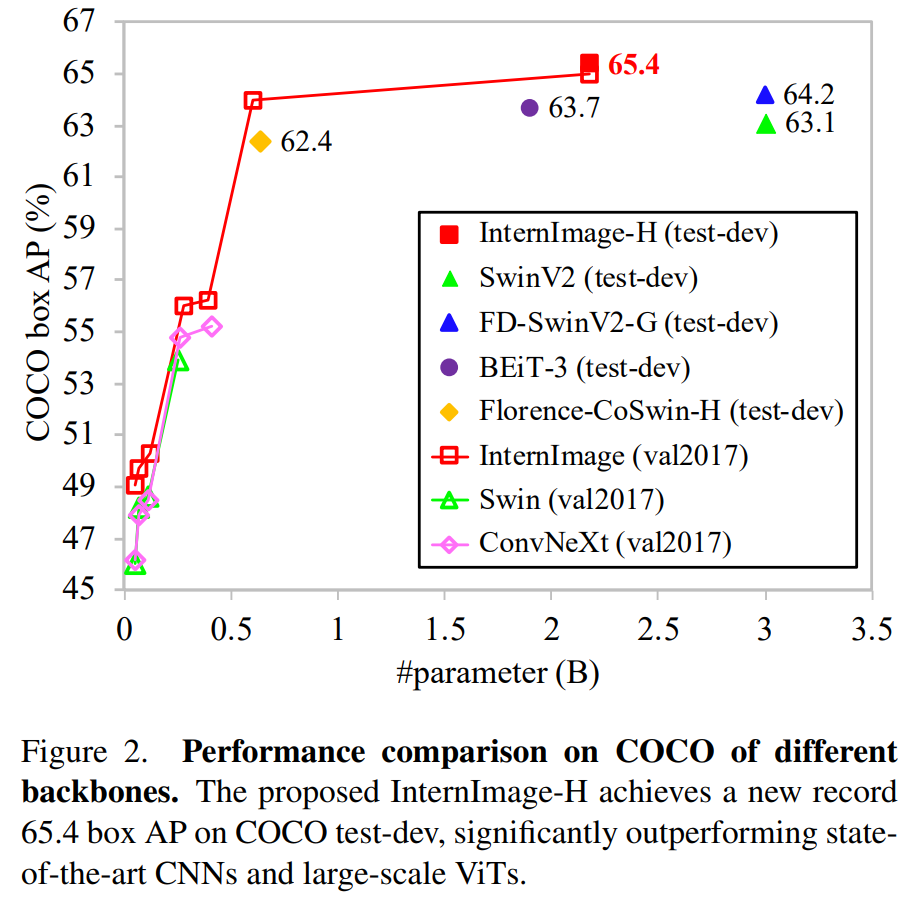
InternImage-H는 COCO 테스트 개발에서 65.4mAP, ADE20K에서 62.9mIoU라는 신기록을 달성하며 현재의 주요 CNN과 ViT를 능가하는 성능을 보임
Main Contributions
(1) 새로운 대규모 CNN 기반 파운데이션 모델인 InternImage 소개
10억 개 이상의 파라미터와 4억 개의 훈련 이미지로 효과적으로 확장하고 최첨단 ViT와 비슷하거나 더 나은 성능을 달성한 최초의 CNN으로, 컨볼루션 모델이 대규모 모델 연구에서도 탐구할 만한 가치가 있는 방향임을 보여줌
(2) 개선된 3×3 DCN 연산자를 사용하여 long-range dependencies & adaptive spatial aggregation를 도입하여 CNN을 대규모 환경으로 성공적으로 확장
- 맞춤형 기본 블록, 스택 규칙, 연산자 중심의 스케일링 전략을 살펴봄
- 이러한 설계는 연산자를 효과적으로 활용하여 모델이 대규모 파라미터와 데이터로부터 이득을 얻을 수 있음
(3) proposed model을 image classification, object detection, instance / semantic segmentation 등 대표적인 vision task에서 평가함
- 이때 model size을 3,000만에서 10억에 이르는 ranging하여 SOTA CNN 모델 & large-scale ViT 모델들과 비교함
- data는 100만에서 4억에 이르는 데이터들을 대상으로 비교함
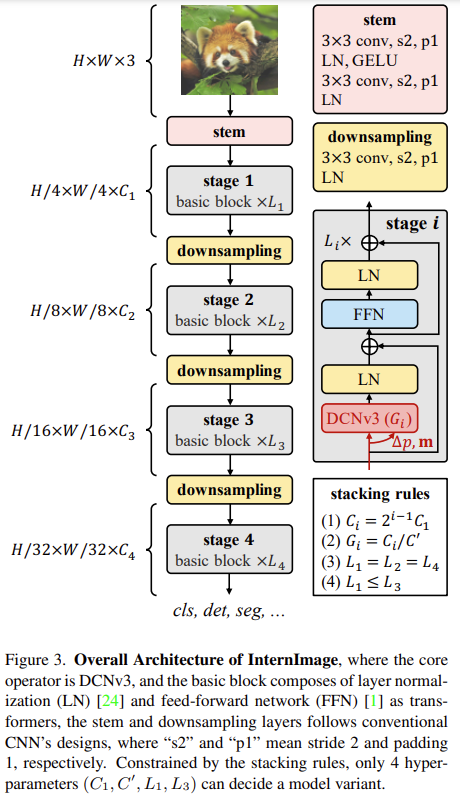
3. Proposed Method
3.2. InternImage Model
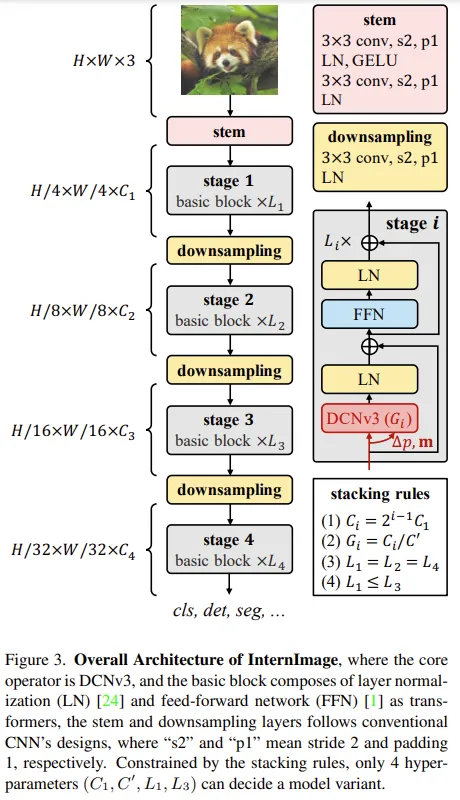
Basic block
Stem & downsampling layers
4. Experiment
3 tasks
- Image Classification
- Object Detection
- Instance & Semantic Segmentation
4.1 Image Classification
- InternImage-T/S/B : ImageNet-1K (∼1.3 million) for 300 epochs로 학습
- InternImage-L/XL : 먼저 ImageNet-22K(∼14.2 million) for 90 epochs train 한 이후 fine-tuned on ImageNet-1K for 20 epochs
- To further explore the capability of our model and match the large-scale private data used in previous methods [16, 20, 59], we adopt M3I Pre-training [60], a unified pre-training approach available
for both unlabeled and weakly-labeled data, to pre-train
InternImage-H on a 427 million joint dataset of public
Laion-400M [61], YFCC-15M [62], and CC12M [63] for
30 epochs => fine-tune the model on ImageNet1K for 20 epochs.
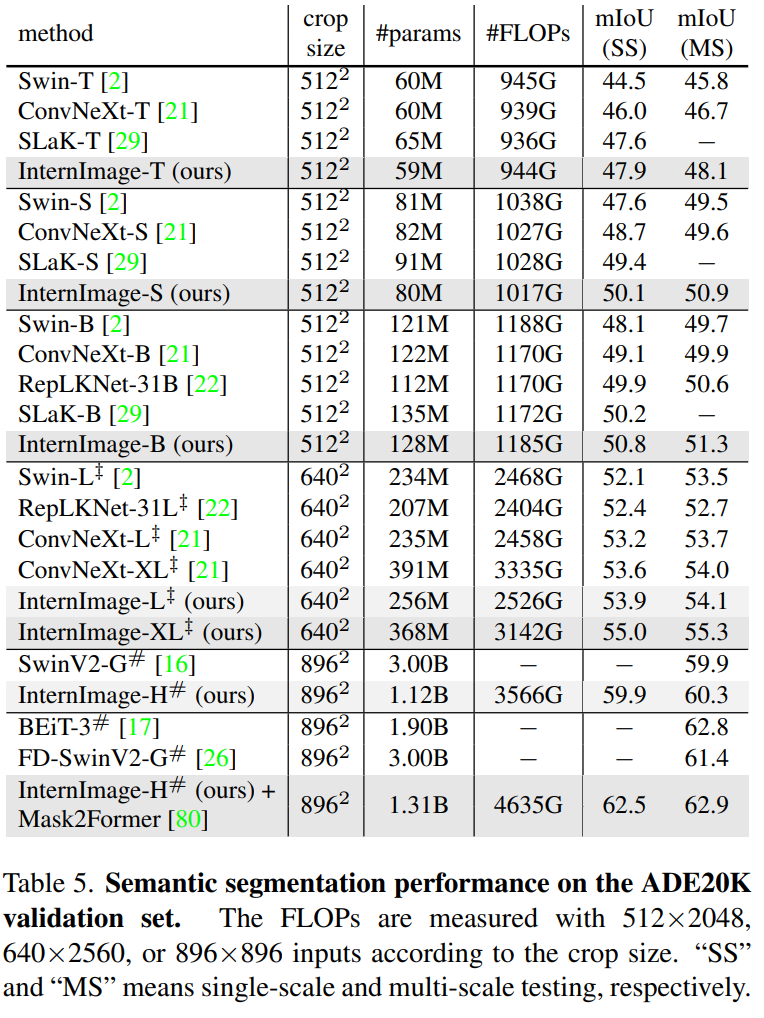
4.3 Semantic Segmentation
Settings
- initialize backbone with pre-trained classification weights
- train our models with with UperNet on ADE20K 데이터셋 for 160k iterations
- compare fairly with previous CNN-based and transformer-based backbones
- 나중에 성능 올리려고 Mask2Former도 같이 사용함
ADE20K
- evaluate our InternImage models on the ADE20K dataset, and initialize them with the pre-trained classification weights
- InternImage-T/S/B models : AdamW로 optimize, initial learning rate = 6×10−5
- InternImage-X/XL : AdamW로 optimize, initial learning rate = 2×10−5
- The learning rate is decayed following the polynomial decay schedule with a power of 1.0.
- crop size = 512 for InternImage-T/S/B, and 640 for
InternImage-L/XL - All segmentation models are trained using UperNet with a batch size of 16 for 160k iterations, and compared fairly with previous CNN-based and transformer-based backbones.
Cityscapes
we use Mask2Former [80] as the segmentation framework.
1. pre-train on Mapillary Vistas 데이터셋
2. fine-tune on Cityscapes for 80k iterations
- crop size : 1024×1024
- InternImage-H achieves 87.0 MS mIoU on the validation
set, and 86.1 MS mIoU on the test set

안녕하세요😊 컴퓨터비전을 공부하고 있는 대학원생입니다 🙌