Retrieval-Augmented Layout Transformer for Content-Aware Layout Generation(RALF)[CVPR 2024]
논문 리뷰
Abstract
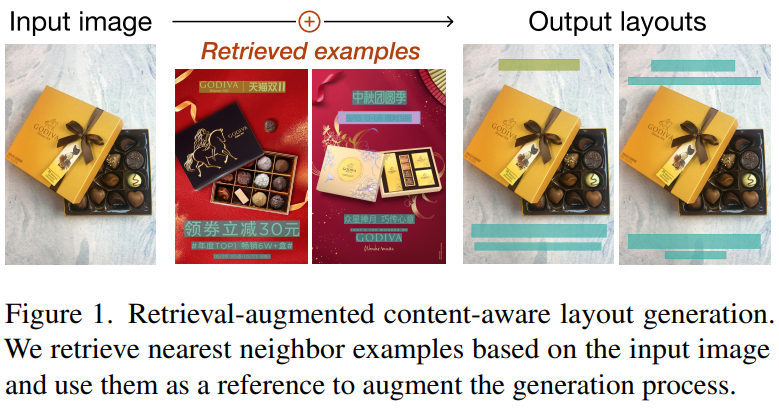
- Content-aware graphic layout generation : 이커머스 제품 image와 같이 주어진 콘텐츠에 따라 시각적 요소를 자동으로 정렬하는 것이 목표임
- high-dimensional layout 구조 학습을 위한 제한된 training data 문제 겪음
- 이 논문에서는 간단한 retrieval augmentation(검색 증강)을 통해 generation quality 향상 가능하다는 걸 보여주겠다!
- RALF : input image 기반으로 nearest neighbor layout example을 retrieve(검색)하고, 그 결과를 autoregressive generator에 공급함
Contributions
- retrieval augmentation(검색 증강)이 content-aware layout generation(콘텐츠 인식 레이아웃 생성)의 데이터 부족 문제를 효과적으로 해결한다는 사실을 발견함
- 레이아웃 생성 작업에 검색 증강 기능을 통합하도록 설계된 Retrieval-Augmented Layout Transformer (RALF)를 제안함
- 광범위한 평가를 통해 RALF가 다양한 시나리오에서 고품질 레이아웃을 잘 생성하고, baseline보다 훨씬 뛰어난 성능을 보임
배경지식
Saliency map
Definition
-
사람이 사물을 인지하는 방법이 Pixelwise하지 않다는 점에서 착안된 방법
- 사람은 특정 사물을 인지할 때, 왼쪽 위~오른쪽 아래로 차례대로 훑어가며 바라보지 X
- 눈에 띄는 영역 or 객체를 가리키는 관심 영역을 먼저 인지하여 그곳에 시선 집중함
ex) 그림에서 개를 인지하지 위해 개가 있는 영역을 먼저 본다 -
화면에서 눈에 띄는 영역, 즉 다른 영역에 비해 픽셀값의 변화가 급격한 부분들을 모아서 매핑함
=> 결과적으로 관심 있는 물체를 관심 없는 배경으로부터 분리시킴

Usage
- 장점 : 이미지에서 중요한 특징 부분들만 모아줄 수 있다
- Object Detection(객체 인식), Scene Classification(장면 분류), Action Recognition (행동 추적)등의 분야에서 사용됨

Method
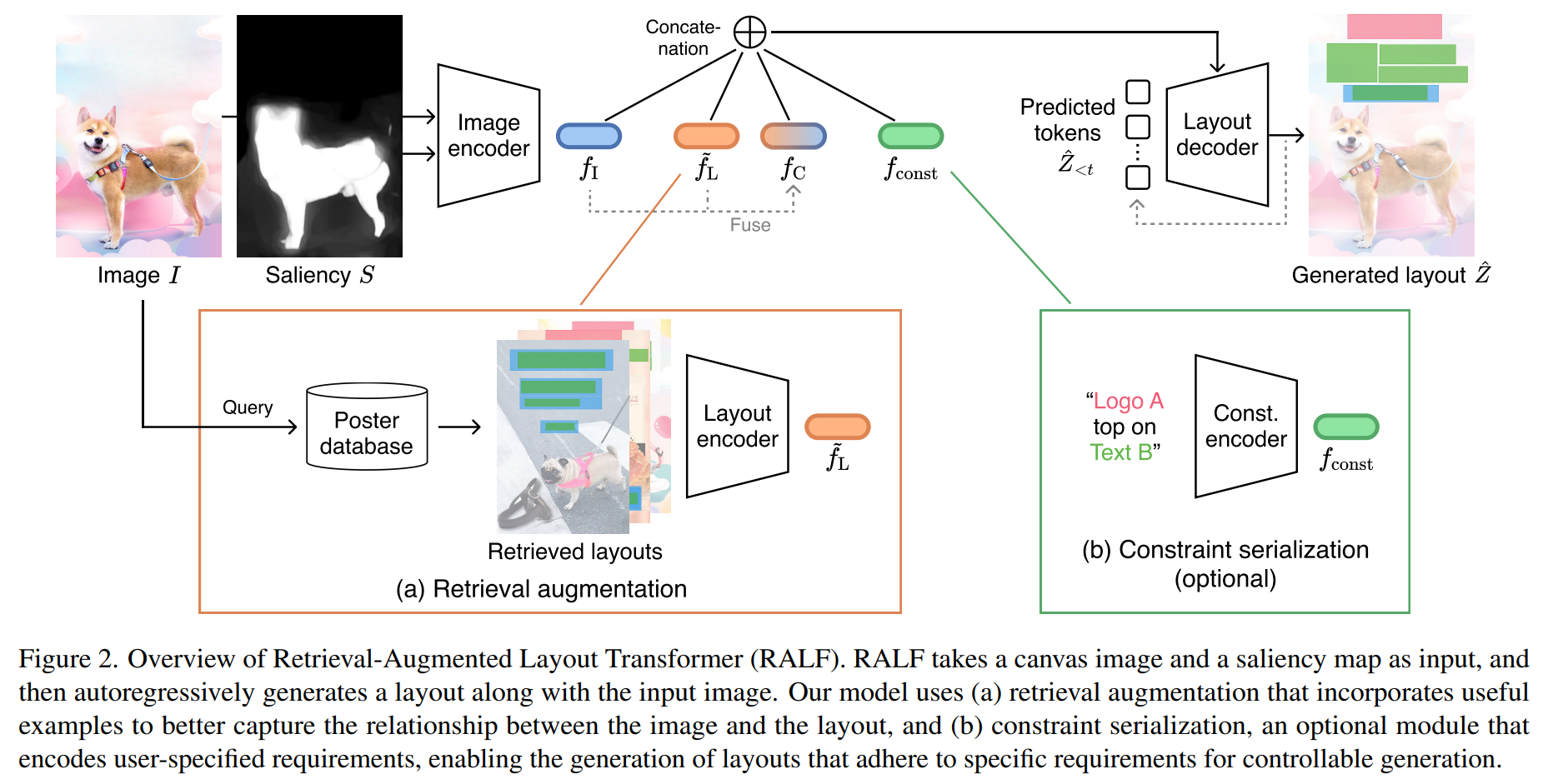
a. retrieval augmentation : image와 layout 간의 관계를 더 잘 포착하기 위해 유용한 example을 통합하는 과정
b. constraint serialization(제약조건 직렬화) : 유저가 지정한 요구사항을 인코딩하는 옵션 모듈, control 가능한 특정 요구사항을 만족하는 레이아웃 생성 가능
Retrieval-Augmented Layout Transformer Model의 4가지 module
1. image encoder
- input : canvas & saliency map
- output : feature
- = down-sampled height, width
- = depth of the feature map
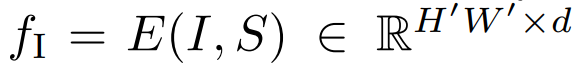
- content-aware approach들에서 흔히 사용되는 부분임
- 여기선 Baseline model인 CGL-GAN(Composition-aware Graphic Layout GAN)의 구조를 따랐음
- CNN backbone으로 ResNet50 & Transformer encoder로 구성됨
2. retrieval augmentation module
- image feature 를 augmented feautre 로 transform시켜줌
3. optional constraint encoder
- element 타입, 좌표, element 간 관계와 같이 원하는 레이아웃 속성에 대한 추가 instruction(명령어)을 통해 레이아웃 생성 프로세스를 control 가능
<과정>
1) Transformer encoder-based model을 채택하여, 명령어를 고정된 차원 벡터 로 인코딩함
- n = task별 sequence 길이
2) 를 augmented feature 과 연결하여 layout에 공급
4. layout decoder
- Transformer decoder를 사용하여 레이아웃 를 autoregressively(자동 회귀적으로) 생성함
- token에서 시작하여 decoder는 retrieval augmentation 모듈의 side feature sequence 과 constraint encoder의 optional sequence 에 cross attention을 적용하여 반복적으로 output token을 생성함
- 우리 모델과 이전 접근 방식 간의 주요 차이점 : 생성 과정에서 모든 속성을 1개의 sequence로 flatten하여 콘텐츠에 구애받지 않는 레이아웃 생성에 효과적임
- 식 (1)에서 설명한 바와 같이, 속성별 주의력을 사용하여 5T +1 단계로 레이아웃 토큰을 하나씩 생성합니다. 반면, GAN 기반 모델[18, 53]은 한 단계로 생성하고, ICVT[7]는 요소별 attention을 사용하여 T 단계로 생성합니다.
Retrieval Augmentation
step
1. Layout retrieval : DB에서 참조할 레이아웃을 검색
2. Encoding retrieved layouts : 이 레이아웃들을 feature 표현으로 encoding
3. Feature augmentation : 모든 feature들을 최종 augmented feature 으로 합침
4. Experiments
4.1. Datasets
-
PKU : 3가지 요소 카테고리 - logo, text, underlay
- 9974 annotated posters(ex: layouts, corresponding images), 905 unannotated canvases -
CGL : 3가지 요소와 추가적으로 embellishment element(꾸미는 요소) 포함
- 60548 annotated posters, 1000 unannotated canvases -
CGL과 PKU의 포스터를 inpainting함
Underlay란?
- 레이아웃 디자인에서 배경 역할을 하는 요소들
- 텍스트나 로고 같은 주요 콘텐츠 요소 위에 배치되는 배경 이미지나 그래픽
annotated posters와 unannotated canvases의 차이

4.2. Evaluation Metrics
Graphic metrics
- canvas를 고려하지 않고 생성된 레이아웃의 퀄리티를 평가함
1. FID(↓) : contentagnostic layout generation(콘텐츠에 구애받지 않는 레이아웃 생성)의 기본 metric(지표)
=> content-aware scenario(콘텐츠 인식 시나리오)에서 해당 지표를 채택
2. Underlay effectiveness (Und ↑) : 전체 underlay 요소에 대한 유효한 underlay 요소의 비율
- non-underlay 요소를 완전히 cover하는 경우 -> 1점
- 그렇지 않는 경우 -> 0점
3. Overlay (Ove ↓) : underlay 요소를 제외한 모든 요소 쌍의 평균 IoU(Intersection over Union)
Content metrics
- 생성된 레이아웃이 canvas에 조화로운지 평가함
1. Occlusion (Occ ↓) : saliency map S와 레이아웃 요소 사이의 겹치는 영역에서 평균 saliency값을 계산함
2. Readability score (Rea ↓) : non-flatness of text
elements를 평가함
- 레이아웃 요소들로 image space의 수평 및 수직 축을 따라 gradients 계산
4.3. Baseline Methods
CGL-GAN(Composition-aware Graphic Layout GAN)
- Transformer 구조를 사용하는 non-autoregressive encoder–decoder 모델
- empty or 레이아웃 제약 조건을 decoder로 받아들임.
DS-GAN
- CNNLSTM 아키텍처를 사용하는 non-autoregressive 모델
- 내부 정렬 알고리즘으로 인해 제약조건이 없는 task에만 적용 가능
ICVT
- Transformer & 조건부 VAE를 결합한 autoregressive 모델
LayoutDM†
- 제약된 생성 작업을 많이 처리할 수 있는 discrete state-space diffusion(이산 상태 공간 확산) 모델
- 원래 content-agnostic layout generation(콘텐츠에 구애받지 않는 레이아웃 생성)을 위해 설계되었음 => input image를 허용하도록 모델을 확장함
Autoreg Baseline
- retrieval augmentation이 없는 RALF와 동일
Real Data
- 실측 데이터로, upper bound로 고려
- test split에서 sample을 추출하기 때문에 validation split을 사용하여 FID 점수를 계산함
Top-1 Retrieval
- generator가 없는 가장 가까운 이웃 레이아웃
- 검색 전용 retrieval-only baseline으로 고려
4.5. Unconstrained Generation
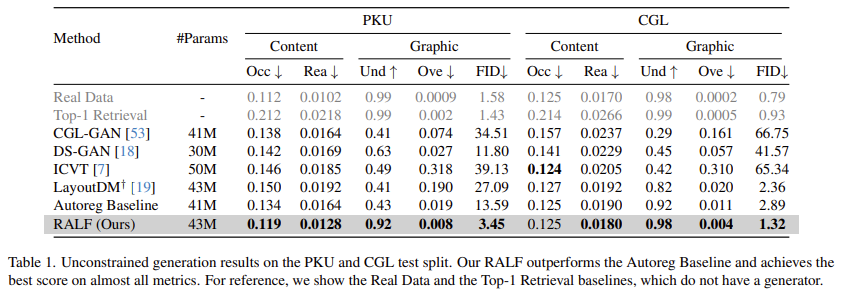
Baseline comparison
annotated test split without user constraints에 대한 정량적 평가 결과
unannotated test split에 대한 정량적 평가 결과
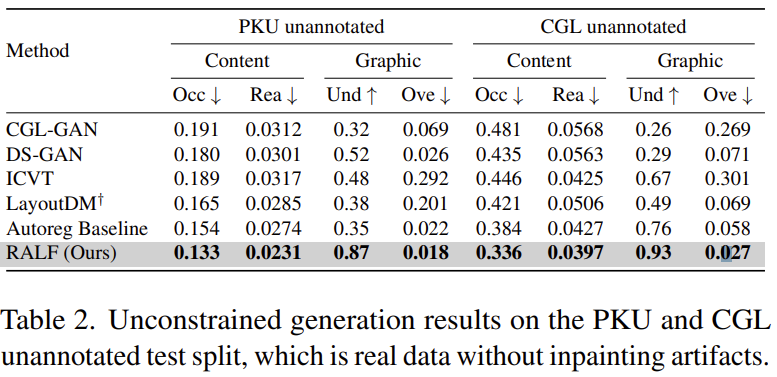
Effectiveness of retrieval augmentation
- retrieval augmentation이 Autoreg Baseline을 크게 향상시킨다!
Qualitative results
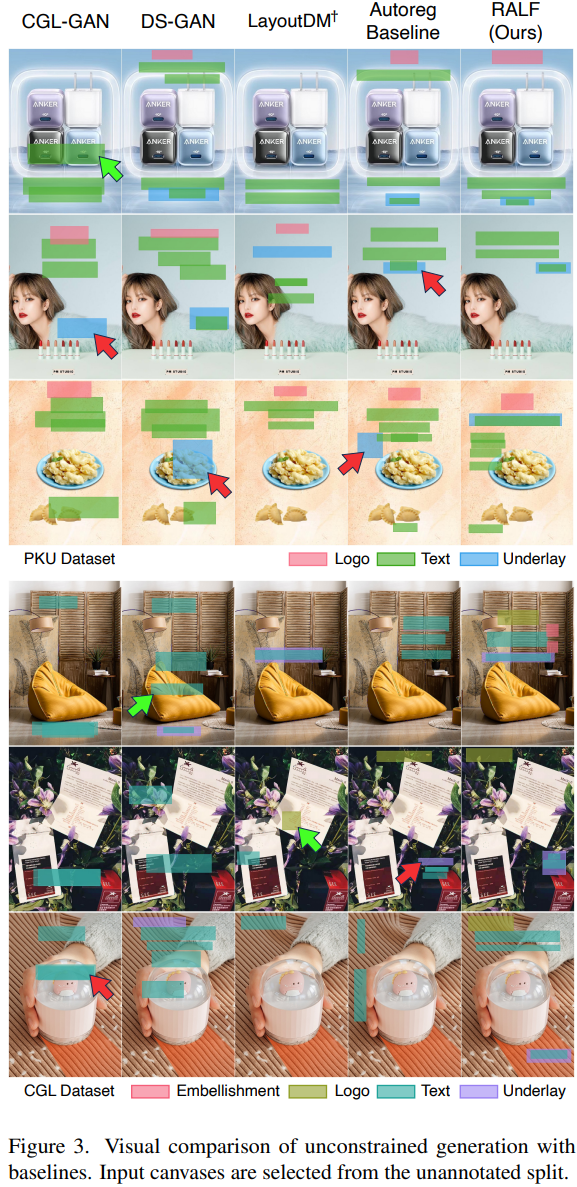
- RALF가 잘 맞고 겹치지 않으며 합리적인 레이아웃을 생성할 수 있음
- 기존 방법은 빨간색 화살표로 표시된 것처럼 정렬이 잘못된 언더레이 장식과 겹치는 텍스트 요소를 생성하는 경우가 많음
- 녹색 화살표 : 눈에 잘 띄는 영역에 나타나는 바람직하지 않은 요소
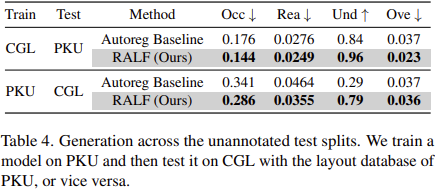
Training dataset size
- Training dataset 크기에 관계없이 검색 증강이 효과적
Retrieval size (K)
- retrieved layouts 개수 K에 highly sensitive하지 않음
- 검색 증강은 검색된 1개의 레이아웃으로도 성능을 크게 향상시킴
- K를 증가시키면 FID가 개선됨

- K = 1의 결과는 생성된 레이아웃이 기준 레이아웃과 유사한 반면, K = 16의 결과는 다양한 레이아웃이 생성됨
Constrained Generation
- Category → Size + Position (C → S + P) : element type을 가져와 각 element의 크기와 위치를 생성
- Category + Size → Position (C + S → P) : 주어진 element 카테고리와 크기를 기준으로 element 위치를 생성
- Completion : 부분적으로 배치된 element를 사용하여 전체 레이아웃을 생성
- Refinement : 정규 분포에 기반하여 element가 ground truth에서 벗어난 어수선한 레이아웃을 수정
- Relationship : element types & 공간적 관계에 따라 결정, element 쌍의 크기와 위치에 따라 결정
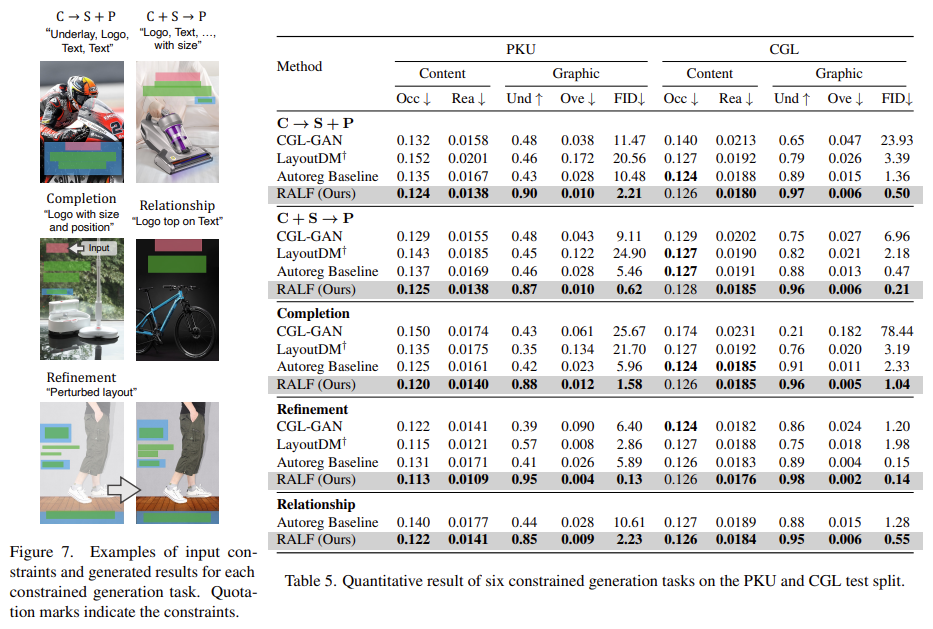
참고한 글
