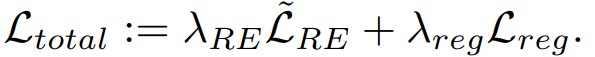
3줄 정리
- VLM들이 explicit하게 hierarchical understanding을 목표로 한 학습을 시키지 않았음에도, hierarchical understanding 능력을 가지고 있더라~ 그래서 VLM에서 본격적으로 hierarchical understanding 학습 & 데이터셋 구축함
- 기존에 hierarchical understanding 학습시킬 때 Entailment Cone(EC) framework를 사용하는데, 얜 EC 기반 objective들로 train from scratch해야하고, hyperbolic space에서 작동하는 단점 있음 (반면,VLMs는 Euclidean space에서 작동)
또 strong constrain(cone 내부에 contrastive pair을 가둔다)을 검 - 그래서 Radial Embedding (RE) framework은 RE Loss를 정의해서, postive pair 내의 다른 tier들끼리의 외각은 작게(가까워지게), 같은 tier의 negative pair끼리의 외각은 크게(멀어지게)으로 학습시킴
- 여기선 paired encoder VLMs(e.g. CLIP)에 대해서만 RE framework 적용함
- RE를 적용했더니, HierCaps 데이터셋에 finetuning시키지 않았을 때 & 시켰을 때 모두 기존에 비해 CLIP zero shot inference 성능이 오름
Abstract
Motivation
- CLIP과 같은 VLM은 text와 image를 공통된 semantic space 상에서 분석하는데는 강력하지만,
이런 모델들은 image를 설명하는 text들의 계층적 구조를 explicitly(명시적으로) 모델링하진 않음 - 반면, 기존 multimodal hierarchical representation learning method들은 비용이 많이 드는 training from scratch가 필요함
& SOTA multimodal foundation model에 내재된 knowledge를 충분히 활용하지 못하는 문제점 있음
Goal
- 기존 foundation model들의 knowledge를 보니까, 직접적으로 이런 목적의 학습을 수행 안 했음에도 불구하고,
visual-semantic hierachies를 이해하는 능력이 나타나는 현상을 발견함(emergent understanding) - 우리는 hierarchical understanding을 탐색하고 최적화할 수 있는 Radial Embedding (RE) framework을 제안함
- image–text representations의 hierarchical knowledge를 study할 수 있는 벤치마크인 HierarCaps dataset 구축
Result
- foundation VLM이 zero shot hierarchical understanding 가능, 기존에 hierarchical understanding을 위해서 설계된 모델들보다 더 높은 성능 보임
- foundation model들이 text-only fine-tuning을 통해 기존 pretraing으로 얻은 knowhierarchical reasoning을 위해 더 잘 align될 수 있음
Introduction
Motivation
-
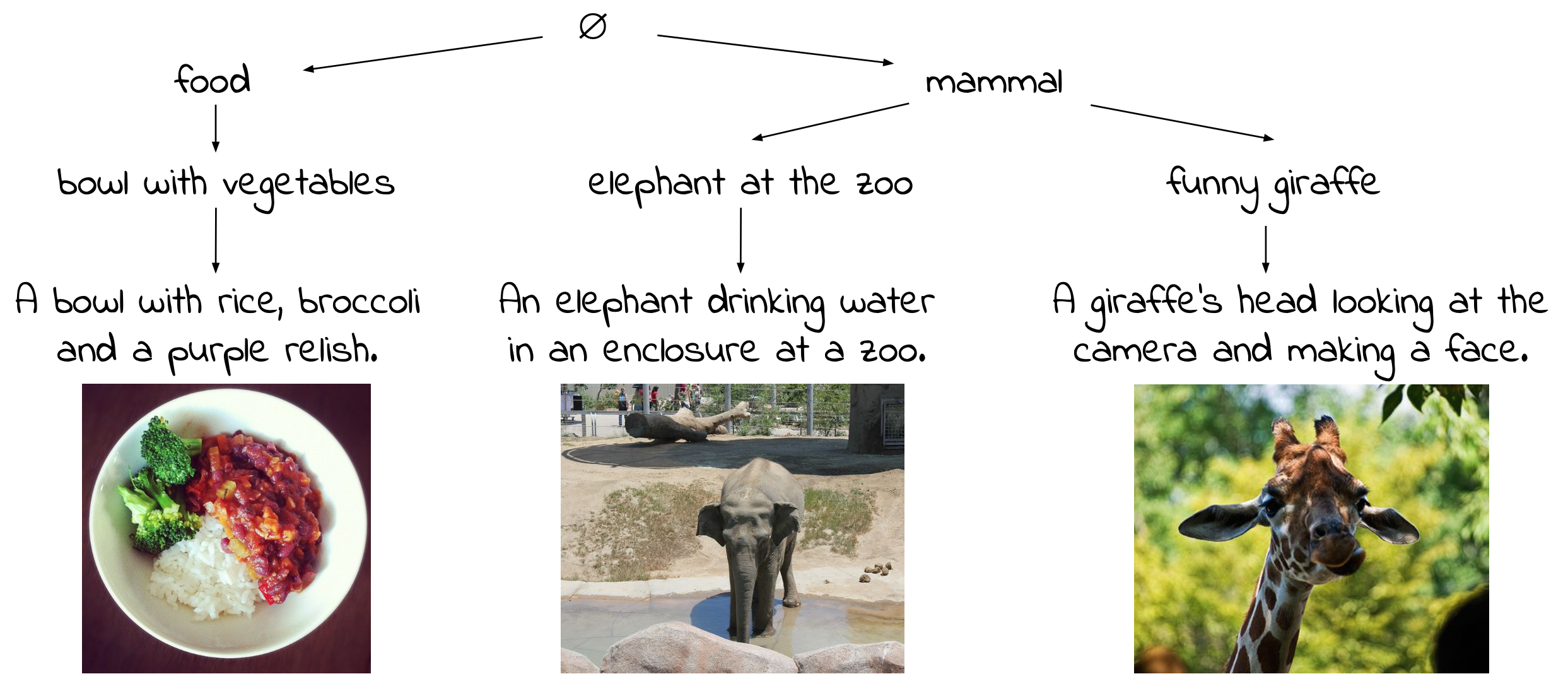
보통의 사람은 parrot을 봤을 때 bird, animal임을 안다. 더 자세히 아는 사람은 ring-necked parakeet임을 알 수도 있음
-
image와 possible description들은 visual-semantic hierarchy를 형성함
이때 visual-semantic hierarchy = directed graph of logical entailment (implication) between items

-
mammal은 #개의 image를 설명할 수 있음
-
반면 funny giraffe는 smaller subset을 설명함
-
각 image는 가장 specific한 description과 closest함 (e.g. A giraffe’s head looking at the camera and making a face.)
배경
image에서 계층적 구조가 광범위하게(ubiquitous) 나타나므로, 이상적인 VLM은 인간과 유사한 방식으로 이를 이해할 수 있어야 함
but CLIP과 같은 SOTA VLM들은 text-image matching과 같은 task에 학습되어, hierarchical knowledge를 명시적으로 학습하진 않았음
의문점 제기
Q. Do such VLMs develop an emergent understanding of visual-semantic hierarchies?
=> 이러한 understanding을 한다면, 블랙박스 모델인 foundation model들의 inner working을 알 수 있음
=> 기존 연구들은 hierarchical understanding이 image classification과 같은 task에서 inductive bias(귀납적)으로 작용해서 성능 향상시킨다고 밝힘
연구 목적
- zero-shot & fine-tuned settings을 통해 emergent knowledge가 존재하는지 확인하기
- 이 knowledge가가 hierarchical task으로의 transfer learning에 쓰이는 initialization으로 활용될 수 있는지 판단하기
Radial Embedding (RE) framework
등장 배경
- 우선 continuous space에서 hierarchical entailment을 표현하는 geometry를 정의해야함
- 기존 연구에선 text간 or image간의 logical entailment 를 partial order relation으로 나타냄
- Entailment Cone(EC) framework : origin 원점에서 멀리 방사되는 cone(원뿔)으로 나타냄
- 단점 : 이런 연구들은 EC 기반의 objective들로 model을 train from scratch해야함
& 일반적으로 hyperbolic space에서 작동하는 한계 - 반면 최신 foundation VLM들은 보통 Euclidean space에서 작동함
새롭게 제안하는 것
- foundation VLMs의 emergent hierarchical geometry을 더 잘 모델링하기 위해 Radial Embedding framework 제안
- hierarchical understanding in VLMs를 향상시키기 위해, model을 fine-tuning할 수 있는 RE-based contrastive objective를 제안함
HierarCaps dataset
challenges
- visual-semantic hierarchies를 위한 GT data가 없음
- 기존 dataset들은 image가 single / unrelated reference caption들과 짝지어져 있음
새롭게 제안하는 것
우리는 HierarCaps dataset을 제안
- 대용량 image caption Internet data w/ hierarchical text generation by LLM & NLI
- 1K-item test set
- evaluation metrics for benchmarking visual-semantic hierarchical understanding & quantifying the multimodal hierarchical knowledge
(기존 work들은 정성적 평가 밖에 안 했음) - 우리 approach는 pretrained knowledge를 retain하면서 적용됨
2. Related work
V&L representation learning
- multimodal representations는 explicitly optimized되지 않았음에도 불구하고, emergent(자발적) geometric properties를 나타냄
예시)
CLIP의 semantic space에서의 벡터 연산이 semantic relationship과 상관관계 가짐
=> word embeddings의 well-known properties와 비슷함
Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning논문에 따르면...
- CLIP space에서의 text와 image embeddings의 geometry(기하학적 구조)를 분석한 결과,
각 modality가 좁은 cone 내부에 포함됨- 이 cone들끼리는 consistent cross-modal gap이 존재함
- 이와 유사하게, 우리 연구도 V&L representation에서의 emergent geometry of hierarchies를 탐색함
- 우리의 text-only alignment approach은 기존 VLM들의 textual representation이 가지는 한계점들을 보완하고,
기존 VLM들의 추가적인 textual understanding으로 adapt시키는 연구들과 유사함
Hierarchical multimodal reasoning
- Image는 다양한 granularity level의 텍스트로 설명될 수 있음
=> 다양한 방식으로 학습되거나 활용될 수 있는 계층 구조를 형성함
< 다양한 approach들 >
1. text-image pair으로 hierarchical concept inference함
- text와 image embedding을 jointly 학습시킴
- concept의 genearlity(일반성) & logical entailment 구조를 implicitly(암묵적으로) infer함
2. 다양한 수준의 detail과 다른 regions에 attention을 가진 이미지에서 texts or knowledge graphs를 생성
방법론들
- Controllable Captioning : 생성하는 텍스트를 제어하는 방법 ([10, 19])
- Contrastive Captioning : 서로 다른 대상 간 차이를 강조하는 설명을 생성 ([16, 40])
- Dense Captioning : 이미지의 여러 객체에 대한 자세한 설명을 제공 ([27])
- Guided Decoding : 특정 조건을 반영하여 캡션을 생성 ([30])
- Scene Graph 생성 : 객체 간 관계를 그래픽 구조로 표현 ([73])
3. GT annotations에 포함된 hierarchical structure를 이용하여 task의 prediction 성능 향상 (e.g. image classification)
- categorical image labels의 concept hierarchies를 사용함
- 반면 우리 벤치마크는 entailment hierarchies로 배열된 free text로 구성됨
4. neural VLM로 학습된 semantic hierarchies 이해하는 연구
-
Exploring hierarchical graph representation for large-scale zero-shot image classification. ECCV (2022)
: VLM은 세밀한 개념(fine-grained concepts)과 이미지를 매칭하는 데 뛰어난 성능을 보이지만,
일반 개념(general concepts) (e.g. leopard vs. feline) 에 대해서는 성능이 떨어지는 경향이 있음. -
Exploring hierarchical graph representation for large-scale zero-shot image classification. ECCV (2022)
: CLIP은 WordNet에서 concept hierarchies을 활용하여 explicitly 학습된 모델 보다 ImageNet classification 성능이 높을 수 있음. -
Chils: Zero-shot image classification with hierarchical label sets. In: International Conference on Machine Learning.
: inference 중에 concept hierarchies를 활용하는 zero-shot classification pipeline by CLIP을 제안함. -
Hyperbolic image-text representations. PMLR (2023)
: neural hyperbolic V&L embeddings 을 도입하여, 계층적 이미지-텍스트 매칭(hierarchical image-text matching) 성능을 개선, 이 task에 대해 정량적 평가함
Hierarchical embeddings
- hypernymy처럼, semantic relationships를 모델링하기 위한 embedding 학습을 목적으로 text(주로 words)를 계층적으로 접근한 많은 연구들 있음
- 많은 연구에서 item 간의 관계를 직접 표현하는 geometric object를 이용해서 데이터를 모델링함
- 특히 hierarchical graphs를 표현하는 데 hyperbolic manifolds(쌍곡선 다양체) 사용
- Poincaré embeddings for learning hierarchical representations (2017)에선 hyperbolic word embeddings 도입
- 후속 연구에서는 hyperbolic space의 다양한 모델, geometry of entailment relationships, 임의 길이의 텍스트로의 확장을 연구함
- 최근 연구에서는 컴퓨터 비전의 다양한 tasks과 multimodal learning에도 hyperbolic learning(쌍곡선 학습) 적용
- text-image data의 hierarchical nature(계층적 특성) & entailment cone framework에서 영감을 얻었지만, hyperbolic space에서 from scratch로 학습하는 대신 Euclidean space에 embedding된 CLIP과 같은 기존 pretrained models의 강력한 knowledge을 활용하는 데 중점을 둠
3. Preliminaries
Notation
cosine similarity function between two vectors
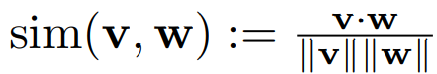
angle spanned by three points a, b, c in space
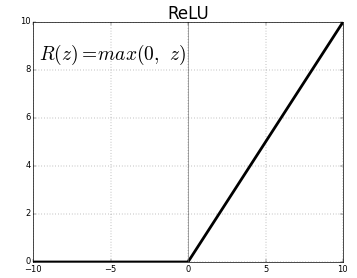
positive part (ReLU) function
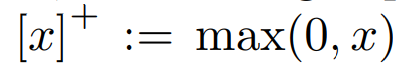
Geometric Preliminaries
embedding space M 내에서의 embedding을 고려해보자. (e.g. R^n for Euclidean embeddings)
- 우리는 item 간의 hierarchical relations을 나타내는 embeddings에 관심 있음
- embeddings e, e' ∈ M of items x,x' 는 x가 x'에 의해 entail(수반)되는 경우, 특정 geometric configuration(기하학적 구성)을 가져야 함
e.g.) text embeddings의 경우, if x =“animal” and x' =“cat” 이면, x is entailed by x'
=> 따라서 e와 e'는 embedding space에서 특정 상대적 위치(relative positioning)를 가져야 함 - r ∈ M은 entailment root (or simply root)
: 모든 entailment 관계의 reference point(기준점)으로 사용되는 anchor로써, space의 특별히 고정된 point - distinct한 e, e' ∈ M (also distinct from the root)을 고려했을 때, exterior angle은 다음과 같이 정의함
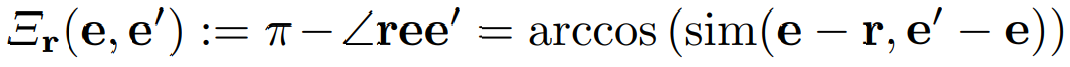
- Euclidean distance of e from the root
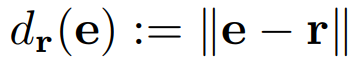
Entailment Cone Embeddings
Entailment Cone (EC) framework for hierarchical representation learning
- EC embedding은 logical entailment을 모델링하는 데 바람직한 수학적 속성인 partial order인 items 간의 defined geometric relation(정의된 기하학적 관계)를 가짐
- e.g) partial orders & logical entailment은 모두 transitivity(전이성)을 따름
(예: black cat는 animal의 일종인 cat의 한 종류이므로 black cat는 animal의 일종임).
EC setting에서 두 embedding e,e'의 관계
C는 원점으로부터 방사되는 convex cone(볼록 원뿔) with half-aperture angle θ
- θ가 root r에서 e까지의 거리에 따라 달라지는 함수 θr(e)로 정의되는 경우,
Euclidean space에서는 상수 ϵ > 0인 경우 sin θr(e) = ϵ/dr(e)로 partial order임
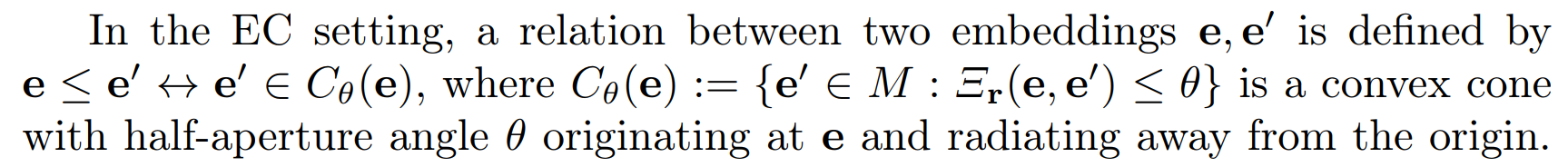

EC framework에서 positive excess은 partial order 관계를 만족하도록 entailment relation를 가진 input pairs을 encourage하기 위한 margin loss
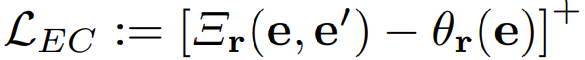
fig 2 왼쪽 부분에서 볼 수 있듯이
if (e,e')가 embeddings of a pair of items in an entailment relationship (e.g. animal and cat) ,
then 이 loss는 if e'가 entailment cone를 벗어나는 경우, e'를 cone Cθr(e)(e) 내부로 push함
4. Radial Embeddings
EC의 assumptions을 완화하고 optimization method을 수정하여 pretrained foundation VLMs이 학습한 representations과 호환되도록 하는 Radial Embedding (RE) framework 설명하겠다~
- foundation VLM representations은 일반적으로 generic concepts을 보다 related, more specific concepts에 비해 central locations(중앙 위치)에 배치한다는 것이 기본 observation이었음
- 직관적으로 이는 similar concept들이 함께 클러스터링되도록 하는 CLIP과 같은 모델의 contrastive objective와 일치함
e.g.) animal의 embedding은 dog, zebra, fish와 같은 related, specific concepts과 가까워야 하므로 더 중앙에 위치할 것으로 예상됨
=> 새로운 계층 구조를 제안해야겠다! - 이러한 계층 구조를 uncover(발견) 그리고 optionally enhance하기 위해, pretrained foundation VLMs은 이미 고차원의 Euclidean space에서 EC의 강력한 requirement들을 반드시 따르지 않는 configuration(구성)을 학습했음
=> entailment을 entailment cone에 기반한 partial order relation으로 묶는 assumptions을 완화함 - 대신, pretrained VLMs의 고유한 hierarchical geometric configuration(계층적 기하학적 구성)을 파악하여 먼저 natural entailment root를 찾은 다음 계층적 이해를 위한 함수를 정의함
Empty String as Entailment Root
- entailment root를 식별하기 위해, 우리는 underspecified inputs(지정되지 않은 입력)에 generic semantics(일반적 의미)를 인코딩하는 VLM의 기능을 활용
- 이를 위해 거의 모든 이미지에 빈 캡션이 수반될 수 있으므로 빈 문자열 e∅를 entailment root r로 임베딩함
- 이를 통해 VLM으로 인해 encapsulated(캡슐화된) pretraining knowledge을 사용하여 학습된 embedding configurations(임베딩 구성)과 일치시킬 수 있음
- 또한 model alignment을 수행할 때 이 임베딩은 loss function의 일부로서, 모델 weights의 gradient에 영향을 미쳐서 위치를 최적화하게 됨
Measuring Genericness and Entailment with RE
- 위에서 정의한 entailment root r이 주어지면, concept genericness(개념의 일반성)을 측정하기 위해 함수 dr(-)을 사용함
- exterior angle function Ξr(-, -)을 사용해 entailment을 측정하는데, entailment cones에서 이뤄진 이전 연구들과 달리 absolute threshold을 reference(참조)하지 않고 측정된 값을 directly 사용함
=> 이를 통해 EC-based partial order의 존재와 같은 strong assumption을 하지 않고도 임베딩의 계층 구조를 활용할 수 있음
4.1 RE-Based VLM Alignment
fine-tune pretrained VLMs for enhanced hierarchical understanding 하기 위해,
contrastive objective which separates positive and negative pairs without requiring an absolute point of reference for entailment을 제안함
- 각 positive pair (e, e')에 대해 negative pair (e, e′′)이 있다고 가정해서,
configuration of hierarchical embeddings & design of HierarCaps을 활용함 - e.g.) (e, e′, e′′) : embeddings of the texts t =“animal”, t′ =“goat”, and t′′ =“portrait”
이유 : t는 t′에 의해 수반되고, t는 t′와 모순됨(따라서 t′′에 의해 수반되지 않음
따라서 contrastive RE loss function을 다음과 같이 정의함!
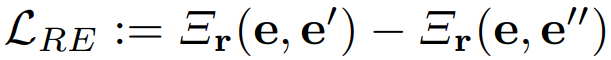
- 개념적으로 L_RE는 fig2와 같이 positive pair(e, e′)이 negative pair(e, e′′)보다 상대적으로 작은 exterior angle를 갖도록 encourage 함
- L_EC와 직접적으로 비교하면 hierarchical image–text retrieval에서 성능 향상시킴 (섹션 6.3)
또한 보충 자료에서는 마진이 무한대에 가까워질 때 대비 쌍에 적용되는 마진 EC 손실의 한계로 LRE를 도출할 수 있음을 보여드리며, 이는 경험적으로 평가에서 더 작은 마진보다 우수한 성능
- 우리는 L_RE가 기존의 contrastive loss functions와 근본적으로 다르다는 점을 강조합니다.
- standard triplet losses은 (e, e′, e′)와 같은 triplets도 고려하지만, standard case에선 e와 e′ 사이의 positive relation는 symmetric(대칭)
- 반면, 우리의 경우에는 logical entailment이 asymmetric(비대칭) 관계이기 때문에 e와 e′를 바꿀 수 없음
e.g) '염소'는 동물의 한 종류이지만 '동물'은 염소의 한 종류가 아닌 case로 확인 가능
=> contrastive learning에서 일반적으로 사용되는 유클리드 또는 코사인 거리 함수와 달리,
L_RE definition에서의 외각 항 Ξr(e, -)은 항 내부의 인수에 대해 비대칭 함수임
- 또한 L_RE는 learnable root r에 따라 달라집니다.
- 이 손실은 similar items은 가깝게, dissimilar items는 representation space에서 멀리 떨어지도록 유도하는 standard contrastive losses과는 달리,
e가 entail하는 item을 half-line(r, e)을 향해서 밀어냄
5. The HierarCaps Dataset
5.1 Design and Contents

- 이미지와 캡션이 pair을 이룬 대규모 데이터 세트가 존재하지만, 일반적으로 이미지당 하나의 캡션 또는 여러 개의 독립적인 reference texts를 포함
- visual-semantic hierarchical understanding를 evaluate하고 optimize하기 위해, logical hierarchy로 배열된 여러 개의 valid texts와 짝을 이루는 images를 포함하는 새로운 dataset & benchmark인 HierarCaps를 제안
- 이 데이터를 생성하기 위해 기존 이미지 캡션 데이터 세트와 LLM- and NLI-guided hierarchy generation procedure를 사용
- train set는 완전 automatically 생성
- test set는 clean evaluation benchmark로 사용할 수 있도록 manually(수동으로) curated & corrected
구성
- images with paired hierarchical caption data
73K-item train set & 1K-item test set - 각 item은 4 tiered 계층 구조로 구성
- lexical & textual entailment task들을 포괄하기 위해서, 최소한의 추가 데이터로 ground-truth Internet image captions을 보완하여 설계됨
- Lexical entailment (어휘적 수반) : logical relation between words
e.g) cat implying animal (as a cat is a type of animal) - Textual entailment : logical implication between full texts
e.g) this is a large cat implying this is a cat - HierarCaps caption hierarchies의 처음 2개의 tier : 보통 single words or short phrases를 포함하므로 lexical entailment에 해당
마지막 2개 tier : 더 긴 text들의 textual entailment에 해당
=> 이런 방식으로 HierarCaps를 사용한 trainig or evaluating은 2가지 종류의 entailment에 대한 hierarchical understanding을 포함
이것들 둘다 NLP & multimodal learning에서 중요한 interest임
image의 4 tier captions
- 각 image는 4개의 accompanying positive caption들 가짐
- 4번째 tier가 가장 specific함 = image-caption dataset에서의 original caption임
- 나머지(1,2,3번째 tier)의 text들은 LM으로 생성된 거임
=> logical entailment hierarchy 형성함
(e.g. animal → goat → goat on island → a goat eating leaves of a lemon tree on the island)
train set의 image엔 4개의 반대되는 negative captions
-
same tier의 corresponding positive item과 logically contradict & previous tier의 positive item을 entailing
e.g. frog in tier 2 of the figure entails animal, while contradicting goat. -
fine-tuning을 위해 HierarCaps를 사용하면, 각 tier의 positive & negative는 RE framework의 loss function에 필요한 pair로 짝지어진 contrastive data를 제공함 (섹션 4.1참고)
5.2 Dataset Construction
- Conceptual Captions (CC) dataset
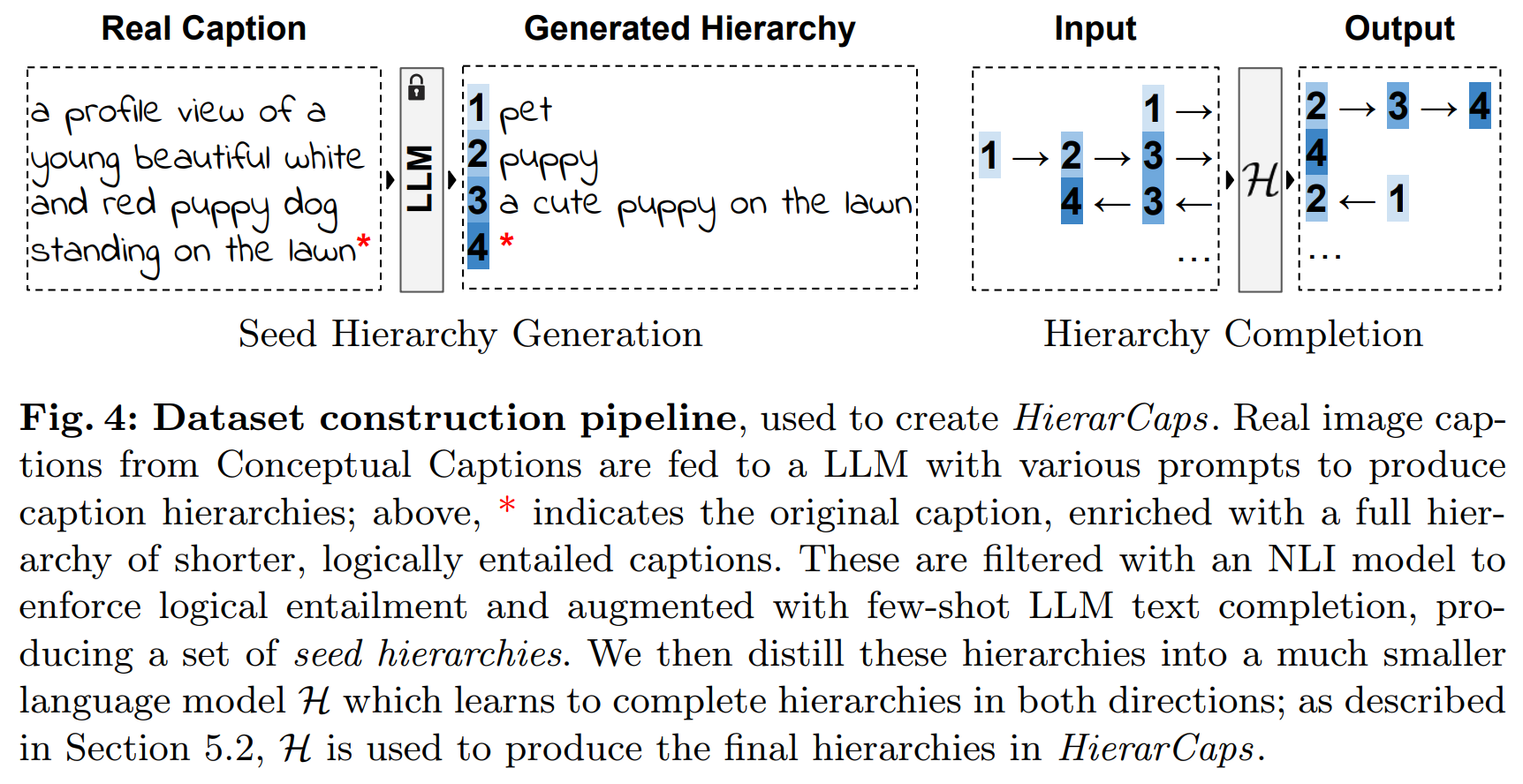
- automatically create seed data using captions from train set of CC
: using SOTA LLM Llama2 - text generation & 강력한 natural language inference (NLI) filtering을 통해 logical entailment를 enforce(강제)함 - prompt로 각 tier에 대해 desired output을 생성하도록 함
- 이 process가 inefficient & only 적은 case에 대해서만 성공하기에,
Llama2로 in-context completion을 써서 더 많은 synthetic hierarchies를 augment함 - 이 example의 핵심을 더 작은 Language model H(encoder-decoder model Flan-T5 사용함)로 distill(추출)하여,
input detailed caption이 주어지면 valid positive hierarchy를 생성하는 방법을 학습 - 모든 input captions (our train set을 위한 CC train captions, our test set을 위한 COCO validation captions)에 대해 이 모델을 실행
- H는 양방향(specific to general & general to specific)으로 caption hierarchies을 완성하도록 train됨
train set에서는 positive hierarchies을 생성한 후 general→specific 방향으로 model H를 run하여 의도적으로 negative captions을 hallucinate
- text 간의 correct entailment 및 contradiction 관계를 보장하기 위해 모든 output들은 NLI로 filtering됨
- 73K automatically-generated train items
& manually review & correct해서 1K test items => clean evaluation benchmark로 만듦
- 이때 75% of automatically-generated items이 fully valid했음
- 나머지는 minor한 오류 있었음
6. Experiments
Models Considered
dual encoder VLMs (i.e. paired text and image encoders)
- CLIP & OpenCLIP
Full Alignment Framework
- HierarCaps train set의 각 caption hierarchy는 4개의 positive captions & 4개의 negative captions 가짐
- 각 tier에 대해 caption triplets을 사용해서 RE loss 계산
- mini batch 내에서 hard example mining해서 각 tier 1~3의 RE loss를 aggregate함
- fine-tuned text embedding들이 original 값에서 벗어나지 않도록 하는 additional loss term을 추가함
주어진 image’s ground-truth caption text의 fine-tuned embeddings & corresponding original (pretrained, not fine-tuned) embeddings 에 대해, 다음과 같이 loss 정의함
regularization loss
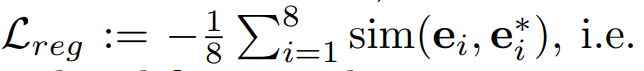
total loss for fine-tuning