논문 원문 링크 : https://arxiv.org/pdf/2306.03514
Abstract
- RAM : manual annotations 대신에 large-scale image-text pairs를 이용하여 image tagging을 하는 strong foundation model
- zero-shot ability to recognize any common category with high accuracy
4가지 key step
- automatic text semantic parsing을 통해 annotation-free image tags를 대규모로 얻음
- original text와 parsed tags로 각각 supervised해서, caption
& tagging tasks를 unify(통합)하여 automatic annotation을 위한 preliminary model을 학습시킴 - data engine을 사용하여 additional annotation 생성하여 잘못된 주석 clean
- retrained with the processed data & fine-tuned using a smaller but higher quality dataset
tagging capabilities of RAM을 여러 benchmarks에서 evaluate했더니 CLIP & BLIP보다 훨씬 좋은 zero-shot performance를 관찰함
fully supervised manners을 surpass하고 Google tagging API와 경쟁적인 성능 보임
1. Introduction
- SAM : data scaling-up을 통해 zero-shot localization 능력 가짐
하지만, semantic label을 ouput하는 능력이 부족함 - Multi-label image recognition = image tagging
목표 : 주어진 image에 대해 multiple labels를 recognize하여 semantic labels을 제공 - multi-label classification, detection, segmentation, and vision-language approaches의 기존 model들은 tagging에서 굉장히 poor한 성능 보임
Image tagging을 방해하는 2가지 요소
- large-scale high quality data를 수집하는 데의 어려움
: a lack of a universal and unified label system and an efficient data annotation engine - large-scale weakly-supervised data를 활용하여 open-vocabulary & powerful model을 구성하기엔 efficient & flexible model design이 부족함

- RAM은 다른 모델들에 비해 중요한 파트를 빼먹지 않고 더 valuable tags를 recognize함
RAM이 challenge를 해결한 방법
Label System
- universal & unified label system 구축
- academic datasets (classification, detection, and segmentation) + commerical tagging products(Google, Microsoft, Apple)를 incorporate시킴
- text로부터 public tags + common tags merge하는 방식 => 6449개 정도의 대부분의 common labels를 커버함
- 나머지 open-vocabulary label은 open-set recognition을 통해서 identify됨
Dataset
- tagging을 위해 large-scale image-text data 사용
- texts parsing하고, automatic text semantic parsing을 통해서 image tags 얻음
Data Engine
- web에서 얻은 image-text pairs는 noisy하기에, label에 오류 있을 수 있음
- annotation quality 향상을 위해, data engine 디자인함
- missing label을 해결하기 위해, additional tags를 생성하기 위해 기존의 모델들을 활용함
<과정>
1. image 내에서 다른 tag들에 대응되는 specific regions를 localize
2. 같은 class내에서 outliers 제거
3. whole images & 각 tag들에 대응되는 regions 사이에 상반된 예측을 보이는 tag를 filter out함
Model
=> Tag2Text와 달리 zero-shot 일반화 가능
- Tag2Text는 original image encoder와 함께 lightweight recognition decoder를 사용하여 image tagging과 caption을 통합함으로써 뛰어난 이미지 태깅 능력 입증
- but Tag2Text의 효과는 fixed & predefined categories를 recognize하는 데만 제한됨
- 반면, RAM은 semantic information를 label queries에 통합하여 이전에 unseen인 categories로 일반화시킬 수 있음
RAM의 장점
- Strong and general
- Reproducible and affordable
- Flexible and versatile
2. Recognize Anything Model
2.1. Model Architecture
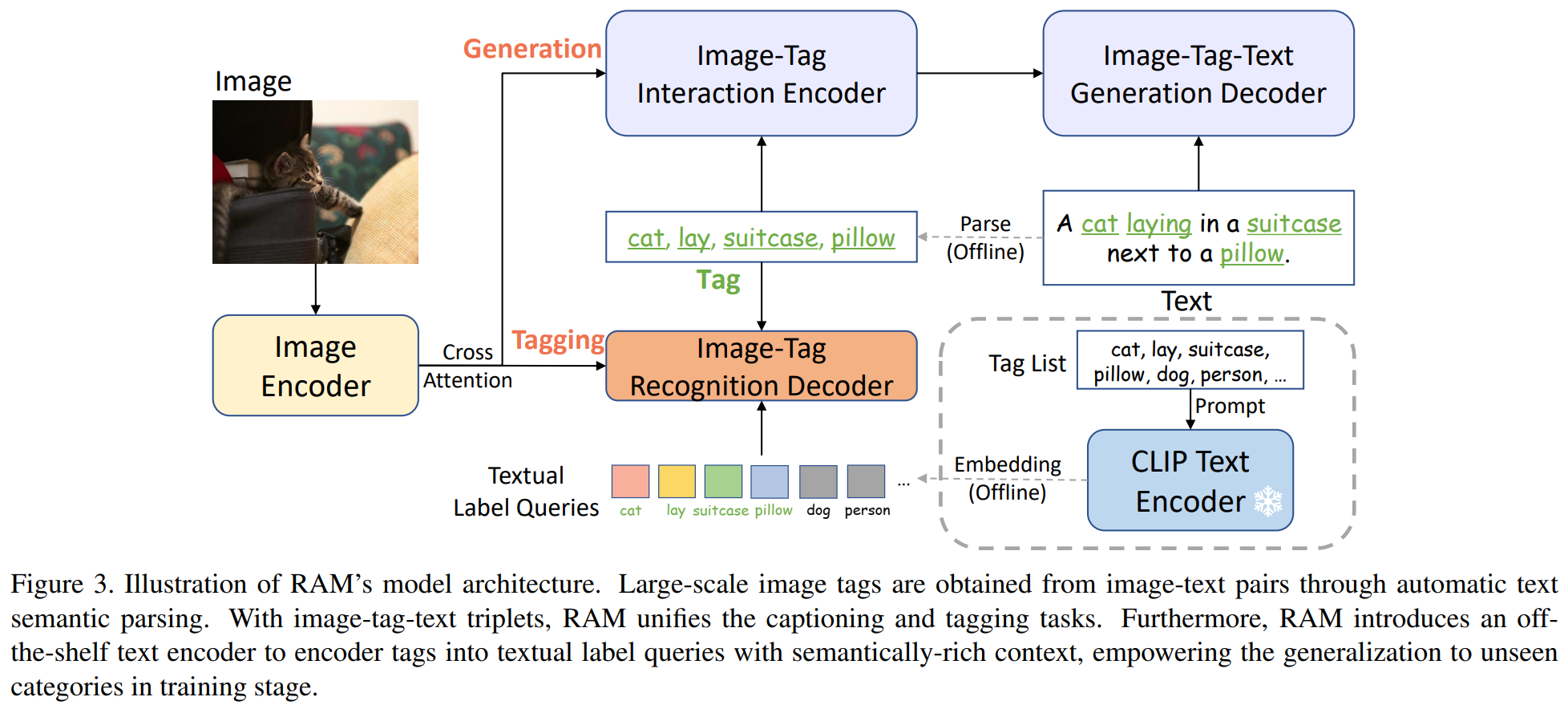
- 전체 아키텍쳐는 Tag2Text랑 비슷함
- 3가지 key modules의 역할
image encoder : feature extract
image-tag recognition decoder : tagging
text generation encoder-decoder : captioning
Image Tagging
- input image 내에 각 category의 존재 여부를 predict하는 것
- image-tag recognition decoders 내부에서 image features는 label queries와 interact함 => 각 category에 대한 logits 얻음
- text로부터 parsing된 tags는 GT label로 사용됨
- Asymmetric Loss가 optimization에 사용됨
- image & text를 globally align하는 CLIP과 달리, RAM은 automatic attention mechanism에 기반하여 image region features & tags를 align함
=> 이렇게 fine-grained alignment하면 RAM이 image의 여러 regions내에서 다양한 semantic tags를 잘 identify하게 됨
Image Captioning
- text generation encoder-decoder을 통해 할당된 tags와 함께 image feature에 기반하여 discriptive(설명) text들 생성하는 것
- training stage : recognition decoder가 text에서 parsing된 tag를 예측하는 방법을 학습
- inference stage : image caption에 보다 explicit한 semantic guidance을 제공하는 tags를 예측
=> image-to-tags를 연결하는 다리 역할함
2.2. Open-Vocabulary Recognition
- Tag2Text와 비교했을 때 Open-Vocabulary Recognition을 도입한 게 발전의 핵심임
- Tag2Text : fixed set of categories만 recognize 가능
- RAM : recognize any category
Textual Label Queries
-
semantic information을 recognition decoder의 label queries에 통합시킴
=> training stage에서 이전에 unseen인 categories로의 일반화를 가능하게 함 -
off-the shelf(기성품) text encoder를 사용하여 label system의 개별적인 tags encoding함
=> semantically rich context를 가진 textual label queries 얻음 -
반면, original recognition decoding에 사용됐던 label querie는 randomly initialized learnable embedding이어서, unseen categories와 semantic relationship이 없음
=> predefined seen categories에만 국한됨
Implementation Details
- image encoder : Swin-transformer
why? vision-language & tagging domain 둘다에선 ViT보다 성능 좋아서 - text generation에 사용된 encoder-decoder : 12 layers의 transformers로 구성
- tag recognition decoder : 2 layers의 transformers로 구성
- off-the shelf text encoder로 CLIP text encoder를 쓰고, prompt ensembling 해서 textual label queries 얻음
- CLIP image encoder로 image feature 뽑아서 image-text feature alignment을 통해 unseen categories에 대한 model의 recognition 능력 향상시킴
2.3. Model Efficiency
3. Data
3.1. Label System
label system을 공식화하는 데 적용된 3가지 guiding 원칙
- image-text pairs로 자주 등장하는 tag는 image description에서 representational 중요도가 높기에 더 valuable
- 다양한 domains & contexts가 tag에 표현돼야 함
tag의 conception엔 다양한 source의 objects, scenes, attributes, actions를 포함됨
=> complex & unseen scenarios에 대한 model generalization에 도움 됨 - tag의 양은 적당해야 함
tag 수가 너무 많으면 annotation costs 많이 들 수 있음
labeling 과정
-
SceneGraphParser를 조금 수정해서 pretraining datsets 중 14 million sentences 를 parsing해서 tag들로 만듦
-
top-10k 가장 많이 등장하는 tag들 중 직접 tag들을 고름
=> 의도적으로 classification, detection, segmentation을 위한 여러 유명 데이터셋들을 커버치도록 골랐음
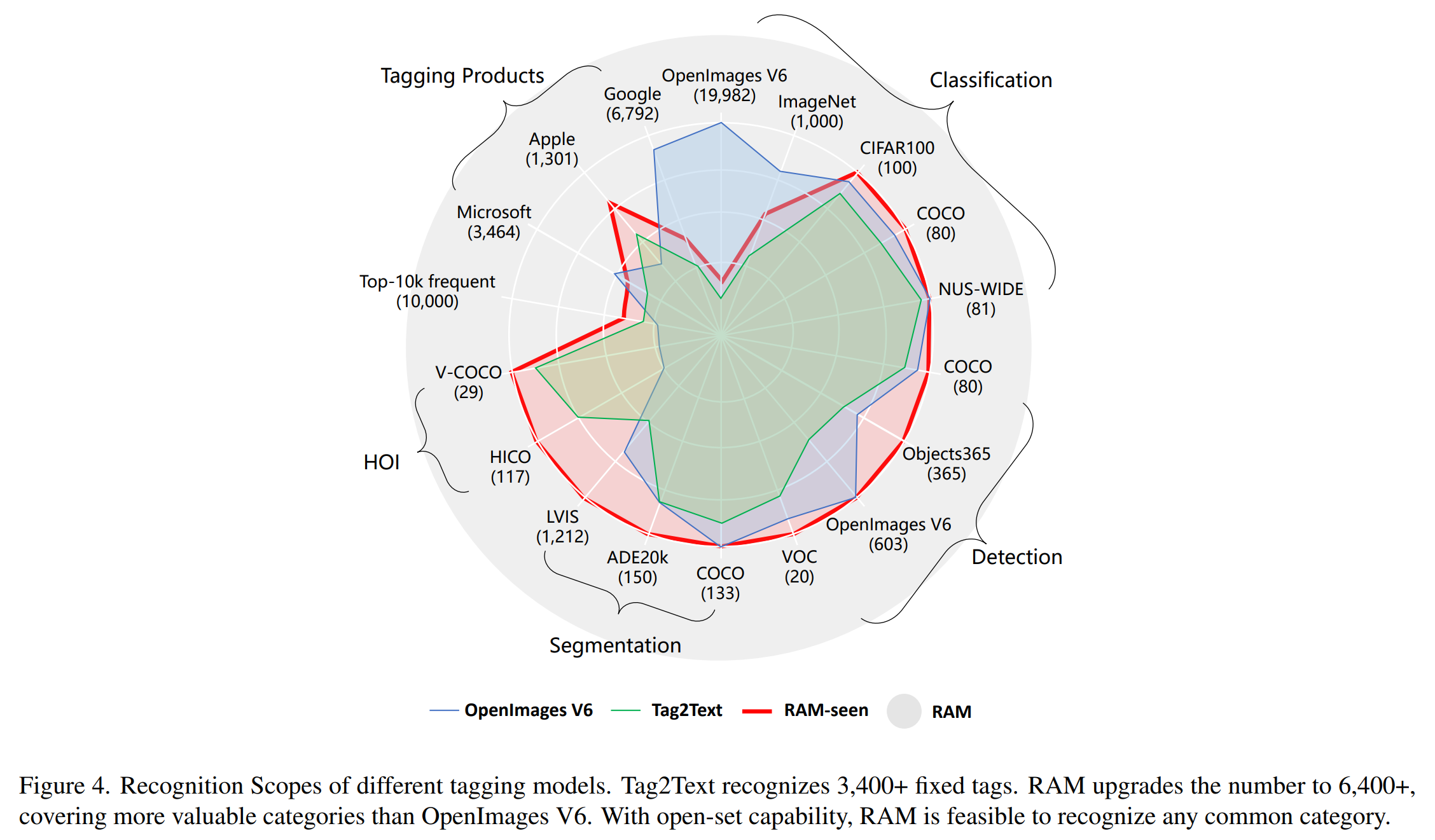
-
여러 방법들로 중복 없애기
- 최종적으로 RAM은 최대 6449개의 fixed tags를 recognize 가능
(Tag2Text보다 훨씬 많고 가치 있는 태그의 비율도 더 음) - 중복성을 줄이기 위해 수동 확인, WordNet 참조, 태그 번역 및 병합 등을 통해 동의어를 수집
=> 동일한 동의어 그룹 내의 태그에는 동일한 태그 ID가 할당됨
=> 라벨 시스템에서 4585개의 태그 ID가 생성
3.2. Datasets
- BLIP & Tag2Text와 유사하게 우리 모델을 많이 쓰이는 오픈소스 데이터셋에 pretrain시킴
- 4M setting : two human-annotated datasets, COCO (113K images, 557K captions)
Visual Genome (101K images, 822K captions)
Conceptual Captions (3M images, 3M captions)
SBU Captions (849K images, 849K captions) - 14M setting : builds upon the 4M setting, with the addition of Conceptual 12M (10M images, 10M captions)
3.3. Data Engine
Generation
- 초기 단계에서는 Tag2Text에서 사용된 approach과 유사하게, image에서 크롤링된 캡션에서 파싱된 캡션과 태그를 사용하여 baseline model을 train
- 그후 baseline model을 활용하여 각각 generative & tagging 기능을 활용하여 캡션과 태그를 보완
- original 캡션과 태그는 생성된 캡션과 대응되는 파싱된 태그, 그리고 생성된 태그와 함께 merge되어 임시 데이터 세트를 형성
- 이 단계를 거치면 4M 이미지 데이터 세트의 태그 수가 1,200만 개에서 3,980만 개로 크게 확장
Cleaning
- incorrect tags 문제를 해결하기 위해 먼저 Grounding-DINO를 사용해 모든 이미지 내에서 특정 카테고리에 해당하는 영역을 식별하고 crop해냄.
- K-Means++를 기반으로 이 카테고리의 영역을 클러스터링하고 이상값 10%와 관련된 태그를 제거
& baseline model을 사용하여 이 특정 카테고리의 예측이 없는 태그도 제거
