4. SQL
4.1. SQL 개요
2) SQL의 특징 및 구성
(1) 비절차적 언어(선언적 언어)
실행 순서를 지정할 필요 없는 언어
DB에서 데이터 가져오는 명령 내릴 때 사용자는 자신이 원하는 바(what)만 명시
원하는 걸 처리하는 방법(how)는 명시 X
DBMS가 SQL문 번역해서 데이터 찾는 과정 담당함
(2) 2가지 인터페이스 : DBMS에 명령 내리는 방법이 2가지
- 대화식 SQL
- 내포된 SQL
(3) SQL의 3가지 언어
-
데이터 정의어(DDL) : DB의 스키마(구조)를 정의, 수정, 삭제할 때 사용
ex) CREATE, ALTER, DROP 등 -
데이터 조작어(DML) : 릴레이션의 데이터를 검색, 삽입, 삭제, 수정할 때 사용
ex) SELECT, INSERT, DELETE, UPDATE 등 -
데이터 제이어(DCL) : 데이터의 사용 권한 관리하는데 사용
4.3 데이터 정의어(DDL)
CREATE - 생성 / ALTER - 수정 / DROP - 삭제
- 하나의 문장이 끝나면 세미콜론 붙여야 함
1) CREATE TABLE
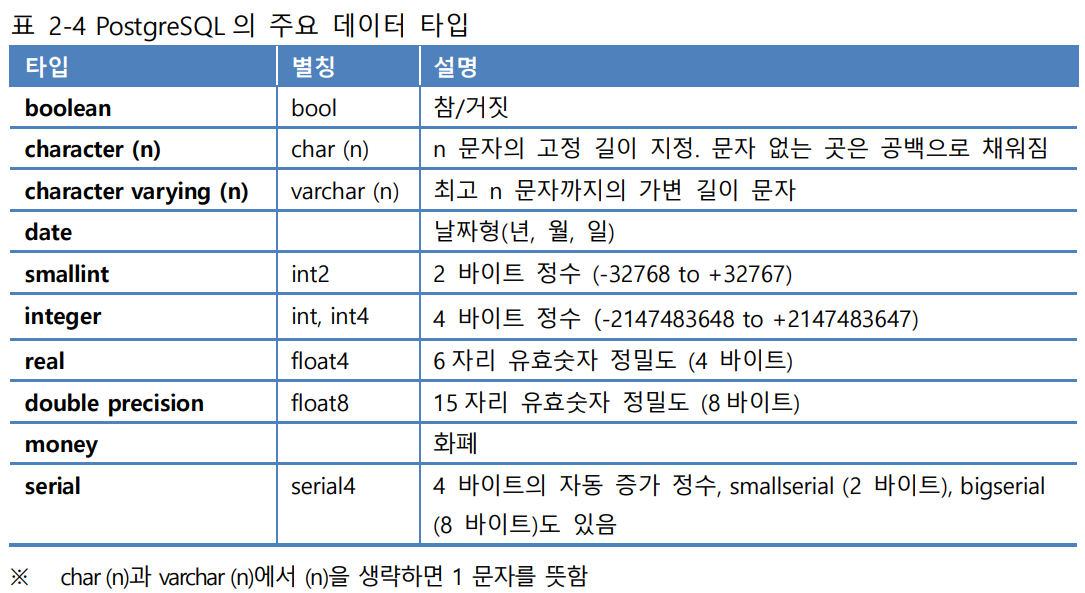
char (n) : n 문자의 고정 길이 지정, 문자 없는 곳은 공백으로 채워짐
varchar(n) : 최고 n 문자까지의 가변 길이 문자
(n 생략 시 1 문자를 의미)

2) 제약 조건
(1) PRIMARY KEY
테이블 정의 - 어떤 칼럼이 기본키인지 명시해서 기본키 제약 조건 추가해야 함
-> 기본키의 특성상 UNIQUE, NOT NULL 포함하게 됨
empno int primary key(2) NOT NULL
- 컬럼은 디폴트로 널값 가질 수 O
- NOT NULL 지정되면 INSERT문에서 이 컬럼값 반드시 입력해야 함
(3) UNIQUE
- 해당 컬럼에 중복된 값 안 갖게 함
- UNIQUE 0 & NOT NULL X -> NULL값 가질 수 O
ex) 동명 이인 입력 금지 -> empname NOT NULL
(4) DEFAULT
- 컬럼의 디폴트값 지정 가능
- 명시적으로 정의 X -> NULL값이 디폴트 값이 됨
(5) CHECK
- 컬럼이 가질 수 있는 값의 범위 지정
ex) dno값이 1, 2, 3, 4중에서만 입력되도록 하려면
dno int check(dno in(1,2,3,4))#개의 제약 조건 동시에 부여
-- deptname이 고유한 값이면서 null 못가짐 deptname char(10) unique not null, -- salary 6000000 미만, 디폴트는 1000000 salary int check(salary < 6000000) default 1000000,
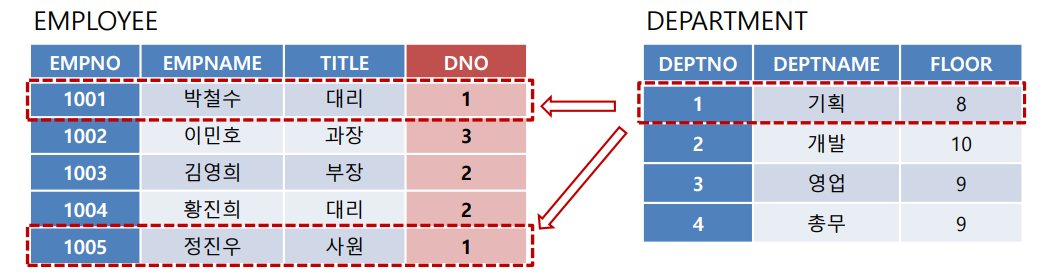
(6) FOREIGN KEY
외래키 제약 조건 (= 참조 무결성 제약 조건) 보여줌
-- employee 테이블의 supervisor 컬럼이 같은 테이블의 empno 기본키를 참조하는 외래키임
supervisor int REFERENCES empno,
-- dno 컬럼이 department 테이블의
dno int REFERENCES department(deptno)(7) 외래키 무결성 제약 조건 옵션
부모테이블에서 삭제(DELETE) or 수정(UPDATE)가 일어날 땐 참조 무결성 제약 조건 위배 가능
dno가 참조하는 부모 테이블 department에서 투플이 삭제(ON DELETE) or 수정(ON UPDATE)될 때
자식 테이블 employee에서 어떻게 동작할지를 정해줌
ON DELETE or ON UPDATE 다음엔 4가지 옵션 붙일 수 있음
-
ON DELETE RESTRICT : 삭제 작업이 안 되게 함
-- ex) department 테이블에서 어떤 투플을 삭제하면 이 투플의 deptno와 같은 dno 값을 갖는 employee 테이블의 투플들이 존재할 경우, 삭제가 되지 않음 -
ON DELETE CASCADE : 삭제된 행을 참조하는 외래키를 포함하는 모든 행도 함께 삭제되도록 함
-
ON DELETE SET NULL : 삭제된 행을 참조하는 외래키를 포함하는 모든 행이 NULL로 바뀌게 함
-
ON DELETE SET DEFAULT : 삭제된 행을 참조하는 외래키를 포함하는 모든 행이 디폴트 값으로 바뀌게 함
-
ON UPDATE CASCADE : 변경된 행을 참조하는 외래키를 포함하는 모든 행도 함께 같은 값으로 변경되게 함
-- ex) department 테이블의 3번 부서의 deptno 값을 6으로 수정하면, employee 릴레이션에서 3번 부서에 근무하는 모든 사원들의 dno 값이 자동적으로 6으로 수정됨
UPDATE DEPARTMENT
SET DEPTNO = 6
WHERE DEPTNO = 3;8) 제약 조건에 이름 부여
- ALTER TABLE에서 제약 조건 삭제할 때 해당 이름으로 삭제할 수 있음
CREATE TABLE employee (
empname char(10) CONSTRAINT uq_ename unique,
~~
);3) ALTER TABLE
: 이미 생성된 테이블의 칼럼 & 제약 조건 변경
(1) 추가
📌 제약 조건의 이름을 주어 추가 가능
-- 참조 무결성 제약 조건 추가 - ALTER TABLE의 ADD CONSTRAINT으로 추가
ALTER TABLE employee ADD CONSTRAINT fk_supervisor
FORIEGN KEY (supervisor) REFERNECES employee (empno)
ON DELETE RESTRICT
ON UPDATE CASCADE;
-- 기본키 제약 조건 추가
ALTER TABLE employee ADD CONSTRAITNT pk_empno
PRIMARY KEY(empno);
📌 컬럼 추가
ALTER TABLE employee ADD COLUMN empname char(10) not null unique;
(2) 변경
📌 컬럼의 데이터 타입 변경
ALTER TABLE employee **ALTER COLUMN** empname **TYPE** char(12);📌 컬럼에 DEFAULT, NOT NULL 제약 조건 추가 - SET 키워드 사용
ALTER TABLE employee ALTER COLUMN dno SET DEFAULT 1;
ALTER TABLE employee ALTER COLUMN title SET NOT NULL;
📌 CHECK, UNIQUE 제약 조건 추가 - ADD ~ 이러케 사용
ALTER TABLE employee ADD CHECK (salary < 6000000);
ALTER TABLE employee ADD UNIQUE (title);
📌 컬럼 이름 변경
ALTER TABLE employee RENAME COLUMN empno TO empid;
📌 테이블 이름 변경
ALTER TABLE employee RENAME TO employee2;
(3) 삭제
📌 컬럼 삭제
ALTER TABLE 테이블명 DROP COLUMN 컬럼명;
📌 ADD CONSTRAINT 로 이름을 주어 추가한 제약 조건은 DROP CONSTRAINT로 삭제 가능
ALTER TABLE employee DROP CONSTRAINT pk_empno;
📌 DEFAULT, NOT NULL 제약 조건의 삭제 - DROP 키워드 사용
ALTER TABLE employee ALTER COLUMN dno DROP DEFAULT;
(4) DROP TABLE
: 릴레이션 제거
DROP TABLE 테이블명;*) 자식 테이블에 부모 테이블을 참조하는 참조 무결성 제약 조건이 있으면
자식 테이블부터 삭제!
or ALTER TABLE 문에서 자식 테이블의 참조 무결성 제약 조건 먼저 제거하면 부모 테이블 먼저 제거 가능
4.4. 데이터 조작어(SELECT문)
1) SELECT 문의 구성
SELECT [ALL / DISTINCT] 컬럼 이름들
FROM 테이블 이름
[WHERE 검색 조건]
[GROUP BY 컬럼 이름]
[HAVING 검색 조건]
[ORDER BY 컬럼 이름 [ASC | DESC] ];(1) SELECT ~ FROM
- 기본적으로 중복 값 보여줌
- 중복 값 제거하려면 SELECT 절에 DISTINCT 키워드 사용
SELECT DISTINCT title
FROM employee(2) WHERE
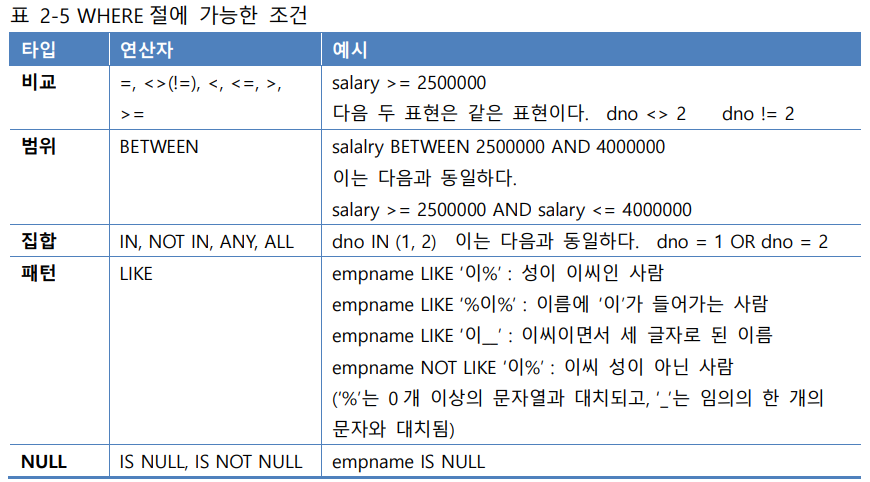
: 조건에 맞는 검색할 때 사용
📌 비교
-
비교 연산자
=, <, <=, >, >= -
부정 비교 연산자
| 연산자 | 의미 | 예시 |
|---|---|---|
| != | 같지 않음 | |
| ^= | 같지 않음 | |
| <> | 같지 않음 | where col <> 10 |
| not 컬럼명 = | 같지 않음 | where not col = 10 |
| not 컬럼명 > | 크지 않음 | where not col > 10 |
📌 패턴
LIKE ~
- % : 임의의 문자열에 대응시킴
- _ : 특정 위치에 한 문자만 대신할 때 사용
📌 널값(NULL)
- IS NULL
- IS NOT NULL
📌 논리 연산자
WHERE 절에 NOT / AND / OR 사용
- 논리 연산자 처리 순서 : 비교연산자 -> NOT -> AND -> OR
- NULL과의 연산(+, -, *, /) -> 결과는 항상 NULL임
💡 BETWEEN a AND b : 이는 (애트리뷰트 >=a AND 애트리뷰트 <= b)와 같다.
📌 집합
- IN : IN 다음의 () 안의 원소인지 판단
- NOT IN : IN의 반대
💡 IN은 OR로도 표현 가능
SELECT *
FROM employee
WHERE dno IN (1, 3)
SELECT *
FROM employee
WHERE dno = 1 OR dno = 3| 연산자 | 의미 | 예시 |
|---|---|---|
| BETWEEN A AND B | A와 B 사이(A,B 포함) | where col between 1 and 10 |
| LIKE '비교 문자열' | 비교 문자열을 포함 | where col like '방탄%' |
| IN (LIST) | LIST 중 하나와 일치 | where col in (1,3,5) |
| IS NULL | NULL 값 | where col is null |
📌 SELECT 절에서 산술 연산자 (+, -, *, /) 사용
- SELECT 절에 수식 표현해도 실제 DB내의 값이 변하는 건 아님
(4) 별칭(alias) & 투플 변수
📌 별칭(alias) : 컬럼 / 테이블에 임의로 부여하는 이름
SELECT empname, salary, salary * 1.1 AS newsalary
FROM employee
WHERE title = '과장';- AS 생략해도 됨
📌 투플 변수 : 테이블에 붙이는 별칭
-- 조인할 때 2개의 테이블에 같은 이름의 컬럼이 있을 때 구분하기 위해 사용
-> 밑에선 D랑 E임
SELECT D.deptno, D.deptname, E.empno, E.empname, E.dno
FROM department AS D, employee AS E
WHERE D.deptno = E.dno(5) ORDER BY
- 순서 명시 X -> 기본키의 값이 증가하는 순으로 출력됨
- 디폴트 정렬 순서는 오름차순(ASC) (점점 커지는...)
- 내림차순 정렬 (DESC)
- NULL : 오름차순에선 젤 마지막에, 내림차순에선 젤 위에 위치함
- SELECT 문에서 가장 마지막 절임
📌 LIMIT & OFFSET
- LIMIT n : n개 투플만 결과를 보여주삼
- OFFSET n : n개 투플을 제외하고 결과를 보여주삼
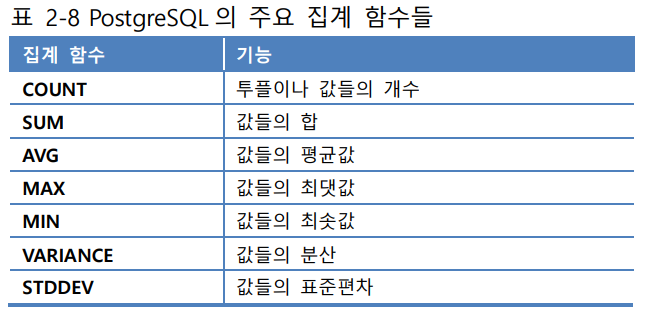
(6) 집계 함수(aggregate functions)
📌 SELECT 절, HAVING 절에만 나타날 수 있음
📌 COUNT(*)을 제외한 모든 집계 함수들 - NULL값 제거한 후 남아 있는 값들에 대해 집계 함수 값 구함
-
COUNT(*) : 결과 릴레이션의 모든 행들의 총 개수 구함
-
COUNT(컬럼) : 해당 컬럼에서 NULL이 아닌 값들의 개수 구함
-
DISTINCT가 집계 함수 앞에 사용 -> 집계 함수가 적용되기 전에 먼저 중복 제거해줌
-- MIN, MAX엔 아무 영향 없음 (당연한 소리 ^_^)
-- count(DISTINCT salary) 처럼 컬럼명 바로 앞에 DISTINCT 붙여줘야함 =.=
(7) GROUP BY & HAVING
- WHERE절로 조건 만족하는 투플들이 걸러짐
- GROUP BY절로 그룹핑
- HAVING절로 그룹들이 필터링
📌 GROUP BY
- SELECT 절에 *을 사용할 수 X
- SELECT 절엔 GROUP BY에 사용된 컬럼(들) & 집계 함수 & 각 그룹마다 1개의 값을 갖는 컬럼(들)만 나타낼 수 있음
ex) dno 값이 같은 그룹으로 묶은 후 해당 그룹마다 급여의 평균 구하기 (그룹별로 1개 값 가짐)
-- GROUP BY 안 하고 평균 급여 select 할 수 X
📌 HAVING 절
- GROUP BY 절에 의해 그룹 지어지면, 이 그룹들에 대해 HAVING 적용해서 특정 조건에 맞는 그룹들만 골라냄
- 반드시 GROUP BY 절에 나타난 컬럼 or 집계 함수만 포함해야 함!

SELECT dno, count(*) AS num, avg(salary) AS avg
FROM employee
GROUP BY dno
HAVING avg(salary) > 3000000
ORDER BY num💡 ORDER BY 뒤엔 별칭 써도 되고 count(*) 써도 됨
- 만약 GROUP BY 안 하고 HAVING 쓰면 WHERE절 만족하는 투플들의 집합을 하나의 그룹으로 취급함
8) 질의의 결합
UNION : 합집합
INTERSECT : 교집합
EXCEPT : 차집합
질의1 UNION [ALL] 질의2
INTERSECT
EXCEPT
- ALL 옵션 : 중복 투플 있으면 모두 결과에 포함시킴
- ALL 없으면 중복 투플 제거됨
