셀레니움
원하는 정보에 대한 접근은 셀레니움, 정보에 대한 처리는 bs4(BeautifulSoup) 사용
-> 본인이 적합하다고 생각하는 방법 사용
- 다나와 사이트
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
#셀레니움에서 반응을 기다려야 하는 경우 - 만들어둔 모듈 사용 or 직접 time 설정해 대기 시간 조절
import time
from selenium.webdriver.support.ui import WebDriverWait
#처리대상이 일반적인 html이므로 bs4 사용 (속도 부분에서 이점)
from bs4 import BeautifulSoup
#다나와 사이트에서 애플 노트북을 검색하고 싶을 때
base_url = "https://prod.danawa.com/list/?cate=112758&15main_11_02"
path = r"C:\Users\NT551_11TH\Downloads\chromedriver-win64\chromedriver-win64\chromedriver.exe" #크롬 드라이버 주소
s = Service(path) #접속
driver = webdriver.Chrome(service=s)
driver.get(base_url)
#다나와 사이트를 웹드라이버로 접근
btn_ex_path = '//*[@id="dlMaker_simple"]/dd/div[2]/button[1]'
driver.find_element(By.XPATH, btn_ex_path).click() #확장 버튼 누르기
apple_btn_path = '//*[@id="searchMaker1452"]'
driver.find_element(By.XPATH, apple_btn_path).click() #애플 노트북 필터링
time.sleep(3) #애플만 처리해서 보내주는 시간을 기다려야 함 #아니면 그냥 노트북 나옴
#페이지 넘기기 #필터링 등등
#틀은 셀레니움, 내부 검색 정보는 bs4로
#BeautifulSoup 사용
soup = BeautifulSoup(driver.page_source, 'html.parser') #문제점 - 안 들어오는 코드 존재, 더블체크 필요
temp = soup.find("div", class_="main_prodlist main_prodlist_list").find_all("li",
class_="prod_item prod_layer")
for i_data in temp :
print(i_data.find("a",{"name" : "productName"}).text.strip())
print("*"*50)- api가 sample curl 로 존재할 때 (python 코드 없을 때)
사이트에 넣어서 바꾸기
https://curlconverter.com/
pandas_csv
pandas 불러올 때 : pd.read_~~
pandas 출력할 때(내보낼 때) : df.to_~~
데이터 형식 : csv, xls/xlsx [ 파일 ]
json, xml [ 웹, 서로 다른 os /sw일 때 ]
mysql, mssql [ 서버 ]
- csv
구분자sep: ","
data.to_csv(" ", sep - ",", index = False, header = False)
json/xml - excel
더 무거움
2차원 엑셀 시트 여러개 -> 3차원 = 2차원 DF에 연결
!gdown 1K2aMT6pW8zlapiuPKSvTOrZcKWwCDLUE
path = '/content/07_surveys_excelformat.xls'
data = pd.read_excel(path, sheet_name = "Sheet1")
#정확한 시트 이름 지정(엑셀 열어보고 확인해야함)
* colab의 경우 구글 드라이브에 연동하여 사용
1.from google.colab import drive
drive.mount('/content/drive')
2.from google.colab import files
my_file = files.upload()
3.!gdown 1sNBvg5jvyJojUDCAhzE4DU0VzXSQc2pv
ㄴ 구글 드라이브에서 공유할 문서 설정. 해당 문서 id값 다운로드!
Pandas DF 연결
1. 이어 붙여서 연결
pd.concat([합칠 대상1, 합칠 대상2, ...], axis = 0/1) #옆으로(1) or 아래로(0, default) 붙일지
ignore_index= T/F - 기존 인덱스 꼬이거나 중복될 경우 기존의 가로 인덱스 무시하고 0~n 정수 인덱스 부여
column key(가로 인덱스)가 같을 경우.. ?
index가 동일하더라도 옆으로 붙일 때 ... 2배*2배 됨
옆으로 합친 df중에서, df2 기준으로 보겠다면
pd.concat(df1,df2], axis = 1),(reindex(df2.indtx)
2. 특정 조건에 맞춰 연결 (sql-join, pd.merger)
sql = select * from L left join R on L.id = R.ids
pandas = pd.merge(L-DF, R-DF, how = '어떻게', left_on = L-DF의 기준 컬럼명, right_on = R-DF의 기준 컬럼명(들))
기준 : 세로 컬럼명 / 가로 인덱스
ex/ pd.merge(baseaball_player, baseball_team,
how = 'left', #기준
left_on = "team_no", right_on = "team_id")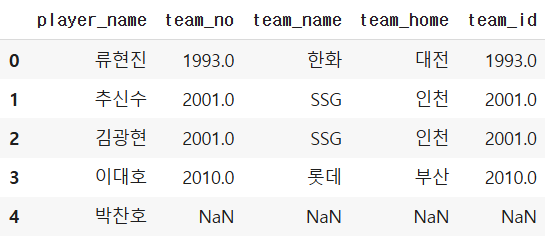
1:1, 1:n 매칭이냐에 따라서 합쳐진 데이터 수가 달라질 수 있음.
ex/ 팀 DF 중심으로 선수 정보 붙이기
양쪽 다 살리고 싶을 때 (inner join , 교집합)
pd.merge(baseball_player, baseball_team,
how="inner",
left_on="team_no", right_on="team_id")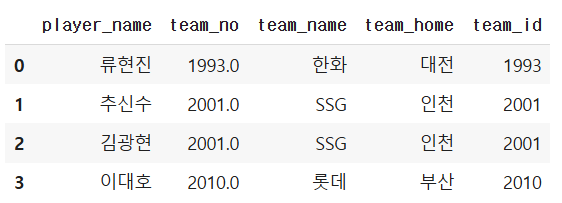
3. Exclusive join
조건검색 & 필터링
sql - where ~~ / pandas - 불리언 인덱싱
(팀 기준)
temp = pd.merge(baseball_player, baseball_team,
how="left",
left_on="team_no", right_on="team_id")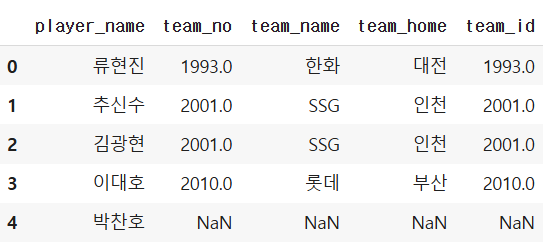
temp[temp.loc[:,' '].isnull()] 결측치 찾기(filtering)

4. Full join
하나라도 누락된 데이터 찾기 - 양쪽 다 체크
temp = pd.merge(baseball_player, baseball_team,
how="outer",
left_on="team_no", right_on="team_id")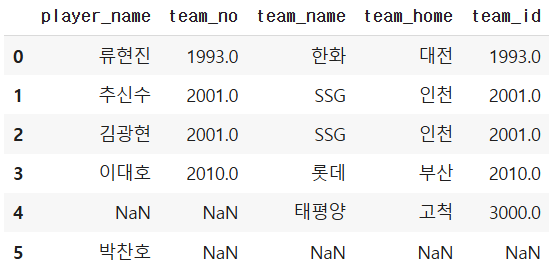
temp[(temp["team_id"].isnull()) | (temp["team_no"].isnull())]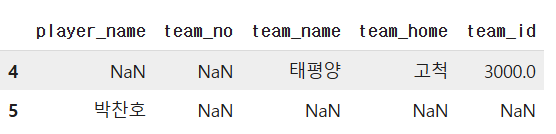
연결의 기준이 하나는 컬럼에, 하나는 가로 인덱스에 존재할 때
컬럼 => left_on = " "
가로 인덱스 => right
(선수 기준)
pd.merge( baseball_player, baseball_team,
how="left",
left_on="team_no", right_index=True)
(팀 기준)
pd.merge( baseball_player, baseball_team,
how="right",
left_on="team_no", right_index=True).reset_index()DF 합치다가 인덱스 꼬이면
reset_index => 정수 인덱스로 반환해줌
rename 으로 인덱스 이름 다시..
Pandas NaN
결측치 데이터 처리
from numpy import nan as NA
import pandas as pd-
결측 데이터 지우기
data.dropna() : NaN 있는 데이터 지울 때
axis = 0/1 (가로줄/세로줄), how="all"(전부 결측인 데이터만 제거), thresh=(기준 정상 데이터 개수, 이 이하면 삭제)
* drop : 특정 줄 지울 때 -
결측 데이터 채우기
평균, 중앙값, 최빈값 등 대표값을 주관적으로 선택하여 채운다.
data.fillna({0: x, 1: y}) : 1번 col 결측치 x으로 채우고, 2번 col 결측치 y로 채운다.
DF 변경
피벗테이블 형식, 수집된 데이터를 원하는 항목/속성/기준으로 바라보고자 할 때
가로 index / 세로 values + 항목별로 쪼개려면 columns / aggfunc : 값의 종류
pd.pivot_table( data,
index = [' '],
values = [' '],
margins = True) #총계처리새로운 틀에 데이터 넣기 - 원본 데이터가 아닌 대표값이 사용됨
(값을 채우는 방식에 특별한 언급을 안 하면 평균값이 사용됨 -> aggfunc = ["sum"] 추가 / 여러개 가능 ["sum", "mean", "count"])
index 여러 개 가능 (더 큰 상위 범위 나타내기..)
value 여러 개 가능 (여러 value 각각)
Dict 형식 적용 : columns
index마다 다른 value값을 나타내고 싶을 때
columns = [ ]
aggfunc = { "value값" : " " , : , ..}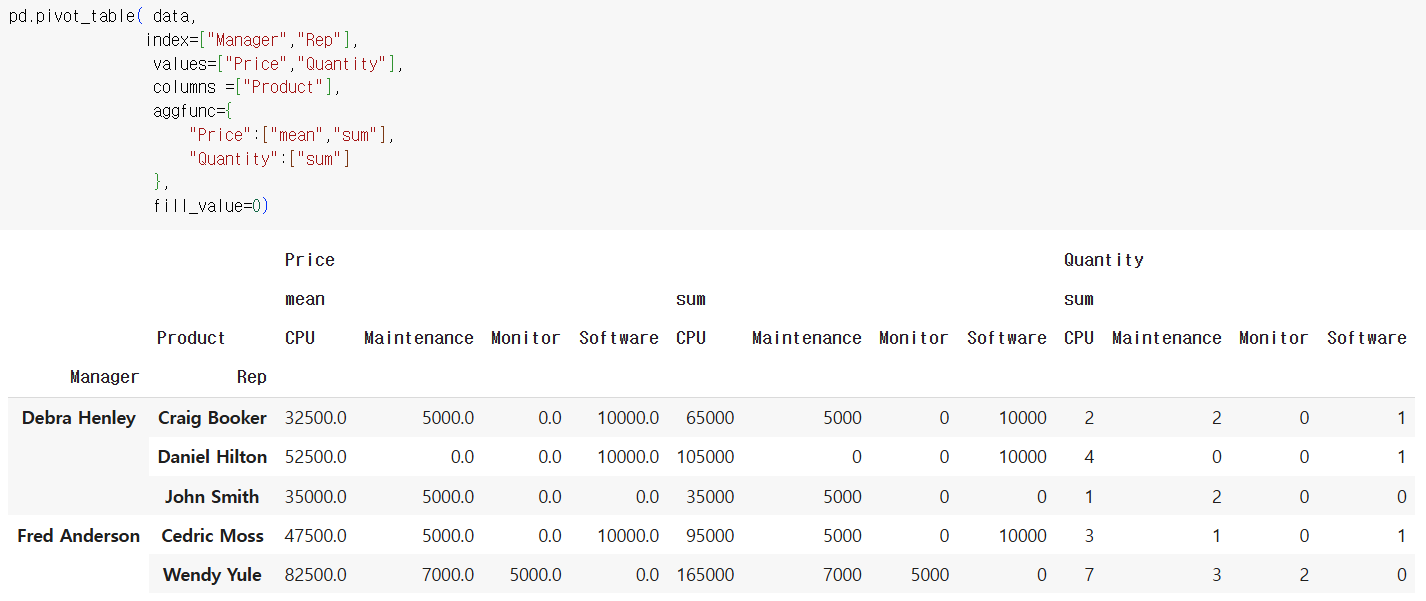
cf) pandas에 DF 재형성할 때 : pivot_table, groupby
