
개요
MLP가 무엇인지 알아보고 이를 학습하기 위한 Activation Function들과 Backpropagation을 알아본다. 또 추가로 multi class classification에서 MSE(LMS)와 CE중 무엇이 더 수렴이 잘되는 지 알아본다.
MLP
perceptron이 무엇인지 잘 모른다면 다음 글을 확인하자. Perceptron 이란?
MLP란 Multi-Layer-Perceptron 즉, input layer와 output layer의 사이에 hidden layers가 들어간다.
이러한 MLP로 single perceptron으로 풀지 못했던 non-linealry-separable한 문제도 풀 수 있다.
layer들이 추가되며, 데이터 표현력이 높아지는 것이다.
다음은 XOR문제를 MLP로 푸는 것이다.
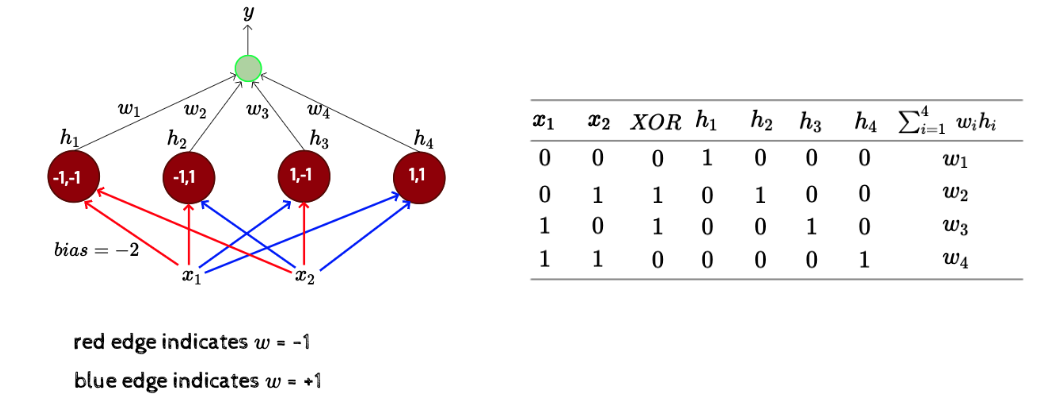
는 0으로 만들고 은 1로 만들면 원하는 결과를 얻을 수 있다.
만약 다음과 같이 input이 3개로 늘어나면 몇개의 perceptron이 필요할까?
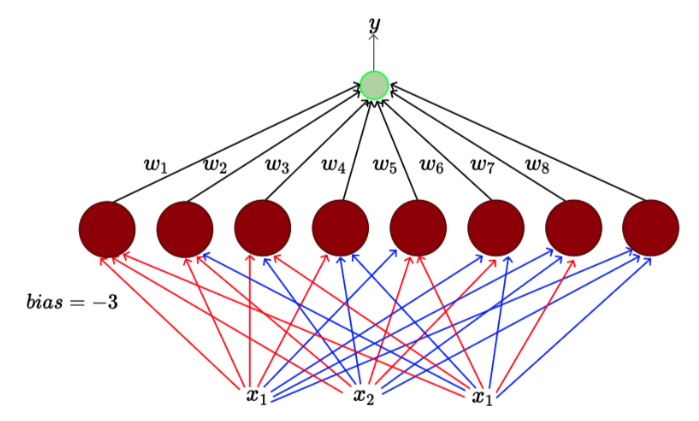
output layer를 포함해서 개가 필요하다.
일반화하면 boolean function에서 입력이 n개일 때, layer는 개가 필요하다. 이는 최대 만큼 있으면 무조건 풀 수 있고 이보다 적은 경우에도 풀 수 있으니 혼동하면 안된다.
MLP는 이런 모든 boolean function을 표현할 수 있다.
Activation Function
MLP에선 각 layer를 통과할때 마다 activation function(활성화 함수)를 적용한다. 이를 하지 않으면 아무리 많이 layer를 쌓아도 single layer가 된다.
그렇기 때문에 여러 activation function들을 골라 적용해준다.
Step function, Sigmoid function
활성화 함수중 먼저 step function을 알아보자. step function은 다음과 같이 정의되어 있다.
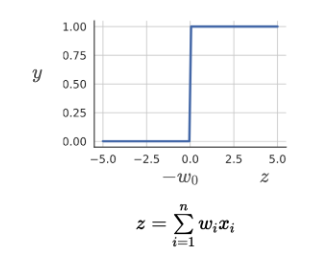
이는 너무 sharp해서 real world에서 적용하기 쉽지 않다. 그래서 이보다 더 smooth한 Sigmoid function을 사용한다.
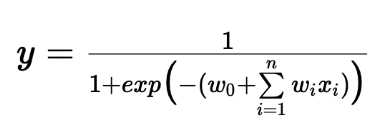
괄호 안에 있는 부분을 p라 하면 p가 점점 커질수록 1과 가까워지고 p가 작아질수록 0과 가까워지는 것을 알 수 있다.
둘을 비교하면 다음과 같다.
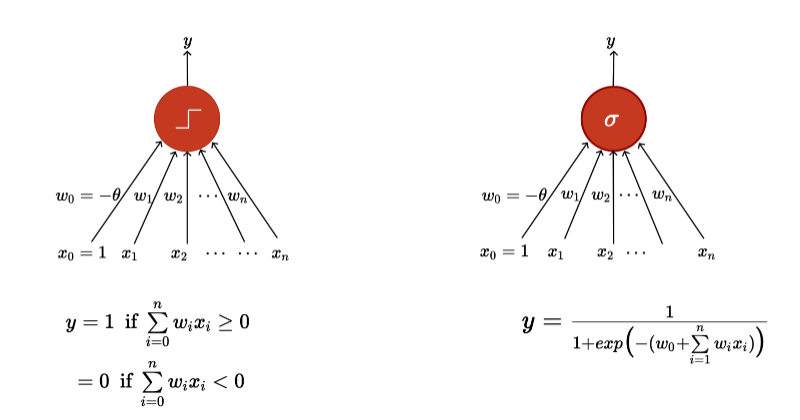
그래프 모양에서 차이를 확실히 알 수 있다.
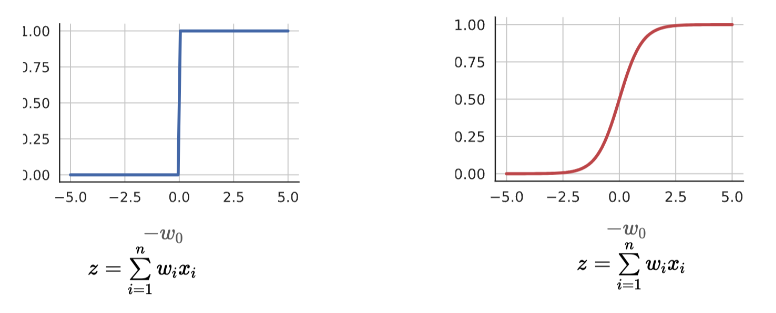
추가로 Sigmoid에서 중요한 점은 미분가능하다는 성질인데 이는 학습을 하기위해서 매우 중요한 포인트가 된다.
나머지 활성화 함수들
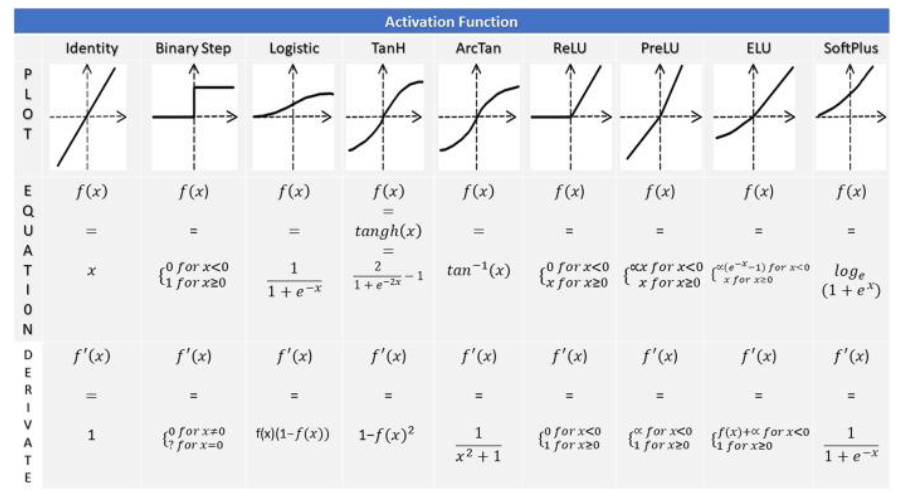
Supervised leaning
지도학습은 정답이 있는 데이터로 학습을 시키는 것을 말한다.
즉, MLP에서 출력값 와 desired(정답)의 차이인 error(오차)를 줄일 수 있는 최적의 를 찾는 과정이다.
Supervised leaning에서 사용하는 model중 하나가 MLP인 것이고, weight(W)와 bias(b)가 parameter이며, LMS 등이 Learning algorithm이고, 학습을 시키기 위한 Guide가 Objective/Loss/Error function이다.
Learning Parameters
이제 최적의 W를 찾아야하는데 이를 어떻게 찾을 수 있을까?

처음 생각해볼 수 있는 건 W와 b를 random하게 대입해보면서 Loss가 낮은 값을 찾는 것인데 이는 사실상 불가능하기 때문에 Gradient를 사용한다.
Gradient Decent
gradient(∇)는 함수가 가장 빠르게 증가하는 방향이다. error 함수가 가장 빠르게 증가하는 방향(∇)의 반대쪽으로 가면 error를 낮출 수 있지 않을까?

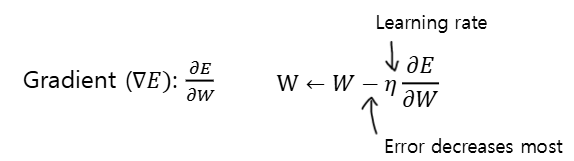
이런식으로 W를 업데이트 해주는 것이다.
LMS (Least Mean Square)
Error 함수가 LMS(평균제곱오차)일 때, 을 업데이트 하는 방법을 알아보자.
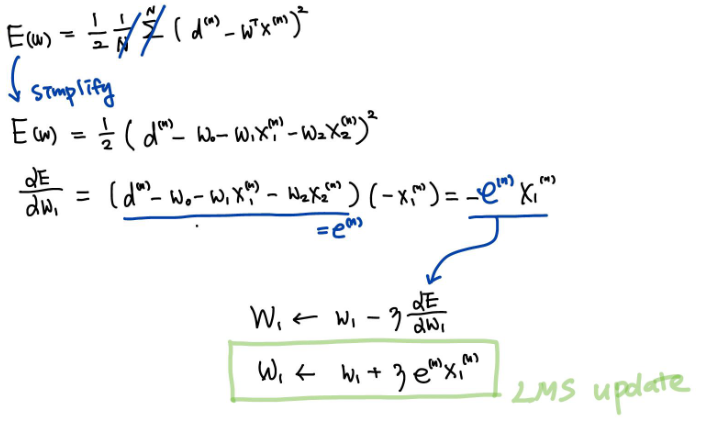
위에서는 활성화 함수를 적용하지 않았다. 활성화 함수를 적용했을 땐 어떻게 되는지 알아보자.
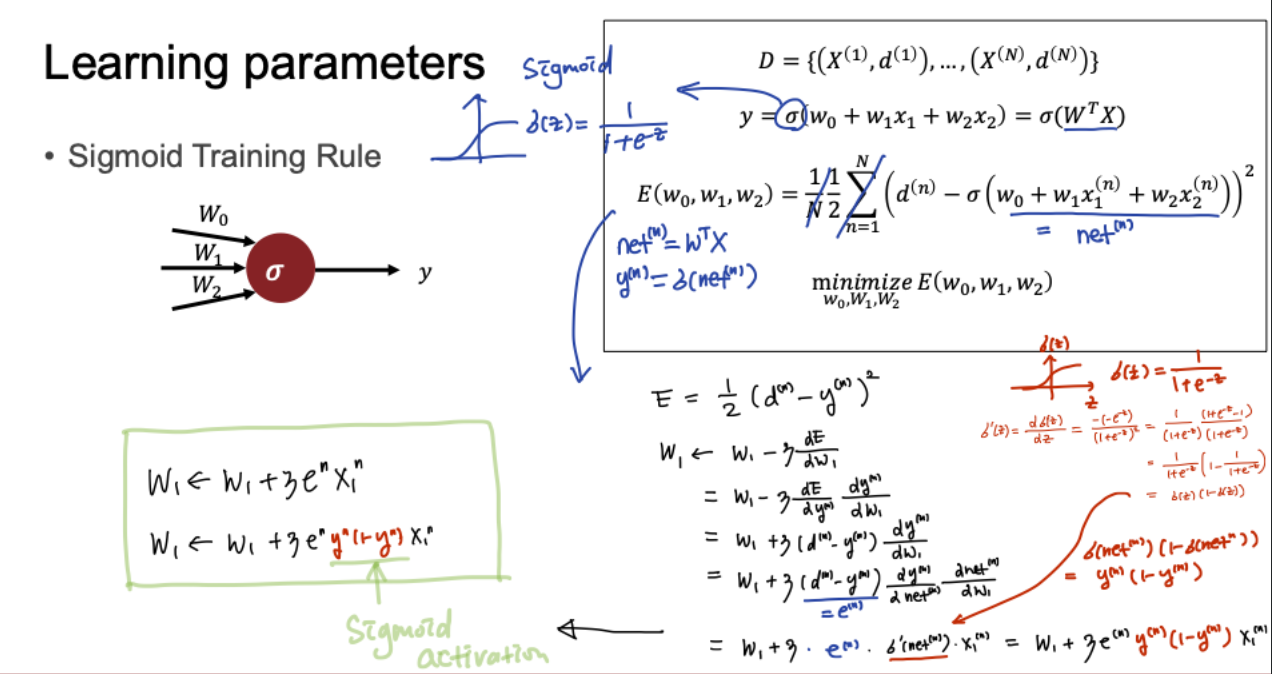
를 간단히 이라 한다.
Sigmoid 활성화 함수를 적용하면 다음과 같이 이 추가되었음을 알 수 있다.
이제 MLP에서 gradient decent하는 법을 알아보자.
MLP Gradient Decent
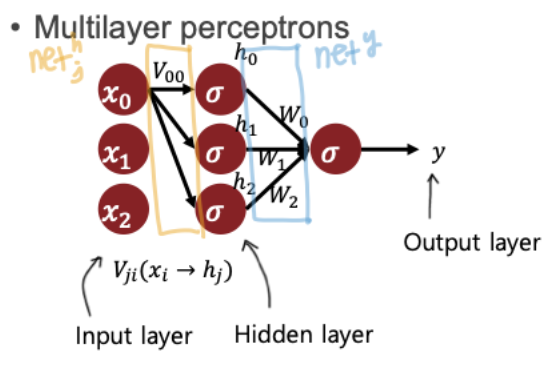
위와 같이 에서 로 가는 것을 라 하고 다음을 라 한다.
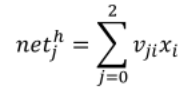
hidden to output

input to hidden
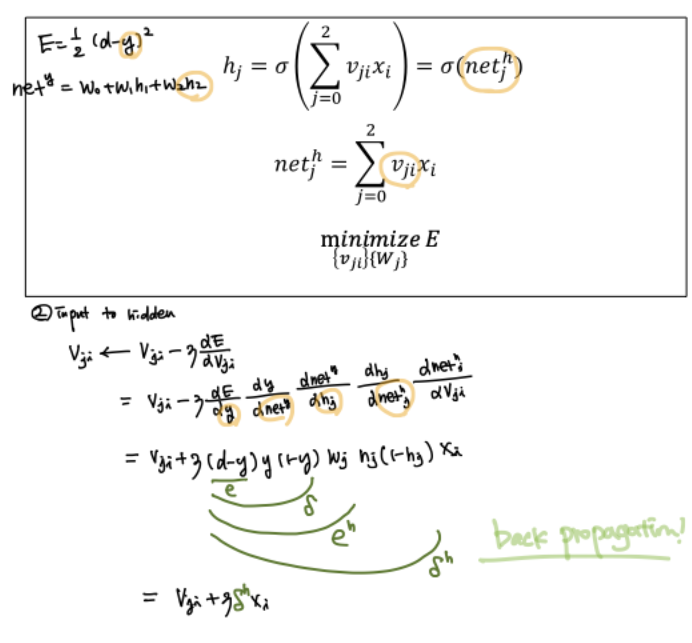
위에서 보이듯이 뒤에서부터 앞으로(backword) error가 누적되고 있다. 이를 back propagation이라 한다.
Back Propagation

- 처음 W값을 초기화 한다.
- input -> ouput으로 forward pass하고 back propagation으로 error를 계산한 뒤, MLP의 모든 weights를 업데이트 한다. 이 한번을 Iteration이라 한다.
- 두 번째 데이터 셋에 대해서 같은 과정을 반복한다.
- Q 번째 데이터 셋에 대해서 같은 과정을 반복한다. 이를 One epoch가 끝났다고 한다.
- 다시 앞으로 가서 여러번 epoch 반복
SGD
위와 같은 과정을 Stochastic Gradient Decent (SGD)라 한다. weight를 업데이트 할 때, 데이터를 하나 보고 한번 업데이트 하고 반복한다. (batch size = 1) 그렇기 때문에 데이터 하나 하나에 영향을 많이 받고 노이즈(튀는 데이터)가 있으면 수렴이 잘 안될 수 있다.
대신 데이터 한 세트 마다 업데이트를 하므로 속도는 빠르다.
BGD
Batch Gradient Decent (BGD)는 전체 데이터를 한번 다 보고 앞으로 한발짝 가는 방식이다. (batch size = N)
전체 데이터를 다 봐야하기 때문에 속도가 느리고 쉽지 않은 방식이다.
MGD
Mini-batch GD (MGD)는 SGD와 BGD의 절충안으로 batch size를 1이나 N으로 두지 않고 사이의 값으로 둔다.
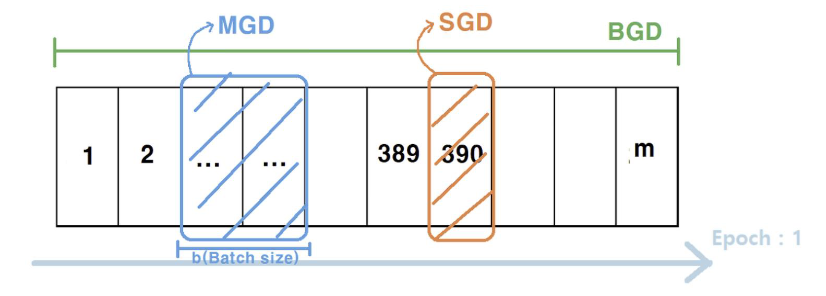
비교
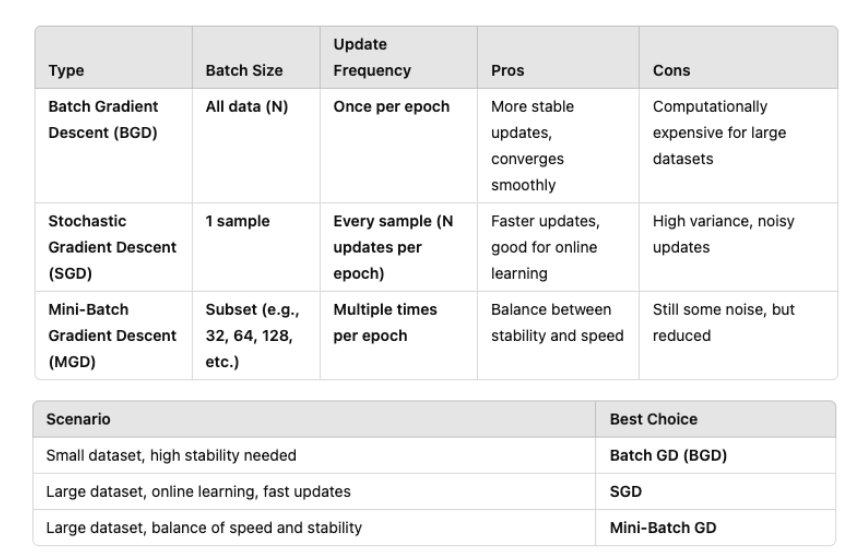
위처럼 BGD는 Iteration(step) = Epoch이고 나머지는 아님을 알 수 있다. 또 BGD는 안정적인 대신 비용이 비싸고 SGD는 빠른 대신 수렴이 힘들다는 단점이 있다. MGD는 속도와 안정성 사이의 balance를 맞췄음을 알 수 있다.
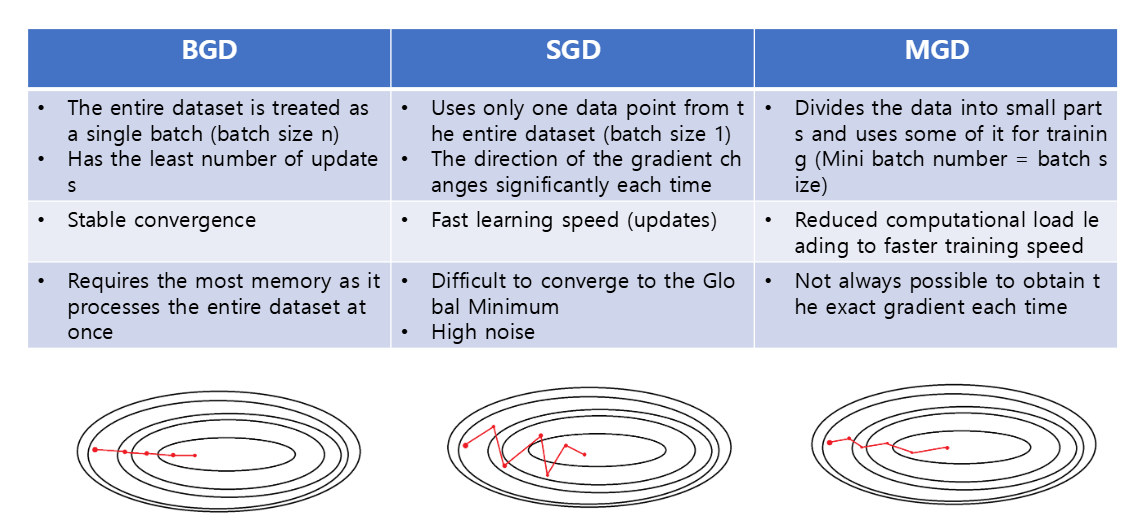
위와 같이 수렴하는 방식을 알 수 있다.
Cross Entropy
Loss Function중 우리는 LMS(평균 제곱 오차)를 사용했다. multi class classification에선 LMS말고 CE를 사용하는 것이 더 효율적이다. CE가 무엇인지 알아보고 왜 효율적인지도 알아보자.
CE
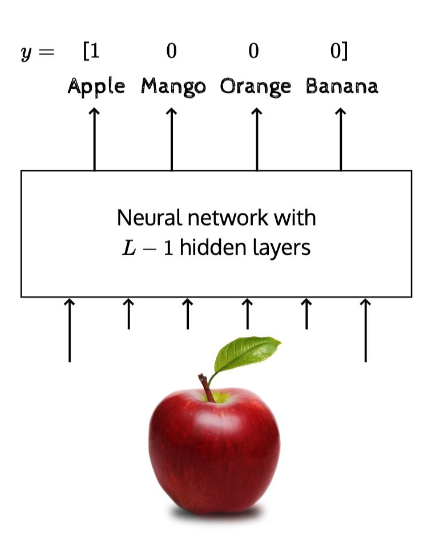
1부터 k개의 이미지를 분류해야 한다. y를 확률의 형태로 표현해보자.
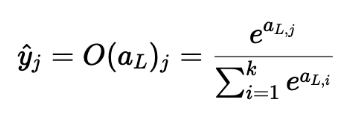
a는 activation function을 거친 값 즉, 출력 값을 뜻 한다.
L은 마지막 layer 즉, 최종 출력층의 값이다.
j는 출력 노드 중에서 j번째 클래스에 대한 출력 값을 뜻한다.
분모는 output을 다 더한 값으로, 1이고 분자는 현재 category의 값이다. 는 output layer를 의미한다.
위 함수를 softmax function이라 한다. 이는 여러 개의 클래스 중에서 이 입력이 각 클래스일 확률을 계산하는 함수이다.
결국 의 값이 1이 되어야 하기 때문에 가 1이 되도록 조정해주어야 한다.
CE는 다음과 같이 정의한다.
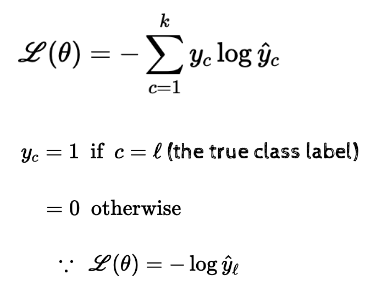
(는 정답 label이다. 정답이면 1, 아니면 0)
위 식은 실제값만 1로 두고 나머진 다 0으로 둔다는 의미. 는 추측값인데, 여기에 로그를 씌워서 one-hot 벡터와 곱해주면 1과 매칭되는 값만 남고 나머지 0과 곱해지는 의 값들은 0이 되어 사라지게 된다. 따라서 정답 인덱스의 확률에 log를 씌워주고, 1보다 작은 수에 log를 씌우면 음수니까 -를 곱해줘서 양수로 만들어주면 작업은 끝나는 것이다. 그리고 로그함수의 개형을 생각해보면 0에 가까운 값일수록 로그를 씌우면 아주아주 작은 음수가 되고, -를 붙이면 오차가 매우 커지기 때문에 이를 1과 가깝게 만들게 된다.
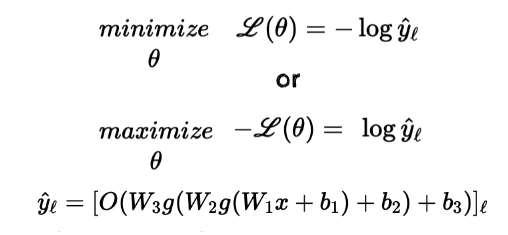
그래서 위와 같이 를 minimize 한다.
즉, 의 의미는 가 클래스에 속할 확률이고 은 0이 되는 것이 목표이다. (0이 되려면 이 1로 되어야함)
수렴에 더 효율적인 것은?
MSE(LMS)와 CE 중 수렴에 더 효율적인 것은 CE이다.
LMS의 sigmoid function은 다음과 같이 쉽게 saturation(포화) 상태에 진입한다.
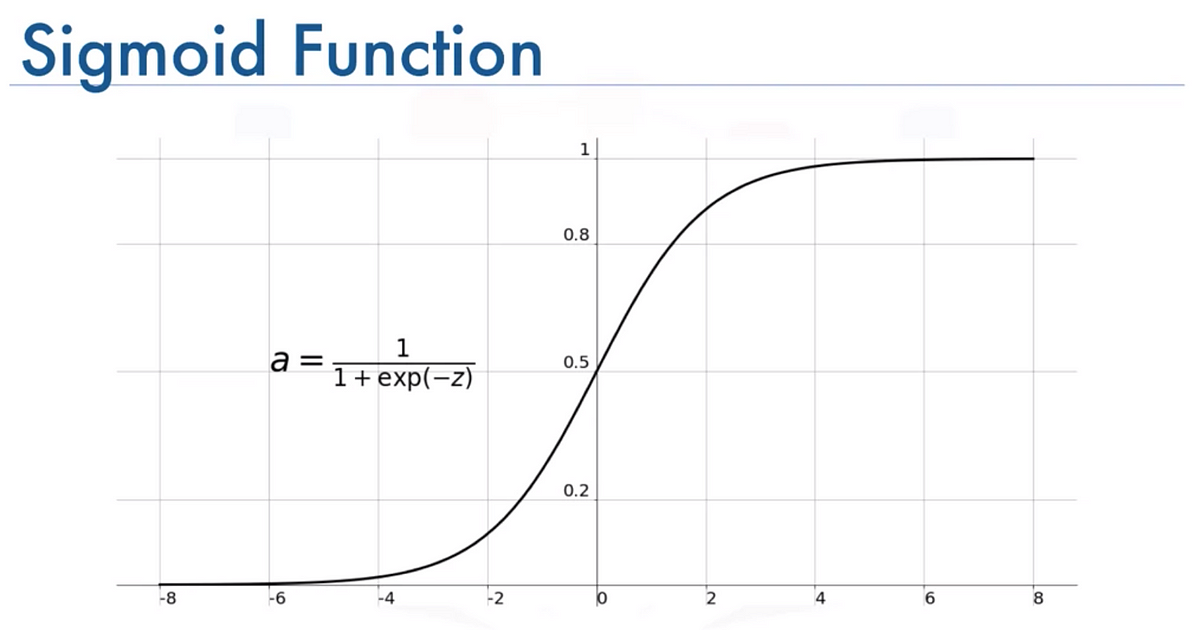
E = 이기 때문에 (그림에선 z)의 변화가 커도 E는 작다.
0이나 1에 가까워 질수록 gradient가 0에 가까워 지면서 학습이 거의 안되는 것이다.
반면 CE는 Softplus Function을 이용한다.
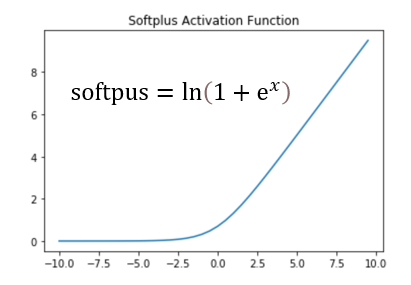
right answer로 x < 0이면 매우 작게 업데이트 되고 wrong answer를 하여 x > 0이면, gradient가 매우 크게 업데이트 된다. 즉, 강한 페널티를 주는 것이다. 이런식으로 쉽게 saturation 상태에 진입하지 않는다.
이진 CE에서 loss로 BCE를 사용하는데 식의 정리 형태가 softplus 형태가 된다는 것이니 혼동하지 않는다. 참고로 activation은 sigmoid
위에서 말한 CE는 다중 분류의 경우이다.
