
딥러닝
Deep Neural Network(DNN)은 여러개의 hidden layer를 갖는 MLP를 칭한다.

machine learning에서 각 layer는 데이터의 각 특징을 뽑아낸다. 데이터가 복잡할수록 데이터를 단계적으로 표현하는 것이다.
예를 들어 사과 이미지를 분류하기 위해 각 layer에서 color, shape, texture 같은 특징들을 뽑아내게 된다.
이는 layer가 깊어질수록 고차원의 정보를 담게 된다.
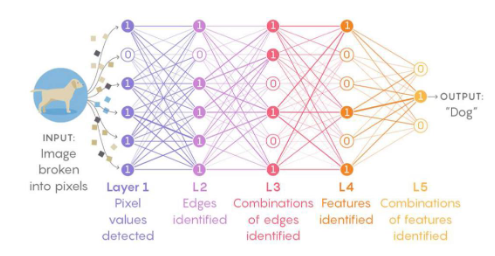
Deep vs Shallow
이론적으로 layer가 얕으면 많은 computational elements (hidden neurons)이 필요하다.
90%의 정확도를 달성하기 위해 20차원의 input vector가 들어가면 1개의 hidden layer는 100개의 hidden neurons이 필요하고 5개의 hidden layer는 각 layer에서 5개의 hidden neurons을 요구하기 때문에 훨씬 효율적이다.
한 layer에서 모든 특징을 추출해야하기 때문에 많은 뉴런이 필요한 것이다.
이전에 MLP가 깊게 train되지 못했던 이유
MLP가 예전에 DEEPLY train되지 못한 이유는 다음과 같다.
- Algorithm problems
Gradient vanishing
Poor initialization- Computers were slow
- Data size was small
Gradient vanishing
이는 전 글에서 설명했던 뉴런이 포화 상태에 진입하여 w가 업데이트 되지 않는 문제이다.
sigmoid function에서 값이 0이나 1에 가까워질수록 기울기가 0이 되고 w가 업데이트 되지 않는 문제가 발생하게 된다.
when neuron saturated, no gradient flows
W를 큰 값으로 initialize를 하면 값이 포화 상태가 쉽게 되어버리고 (net -> 1 기울기 -> 0), forward 과정에서 net이 점점 커지다 발산할 수도 있다. W가 너무 작은 값이어도 gradient vanishing은 똑같이 발생한다.
Poor initialization
만약 모든 w값 들을 0으로 초기화하면 어떻게 될까?
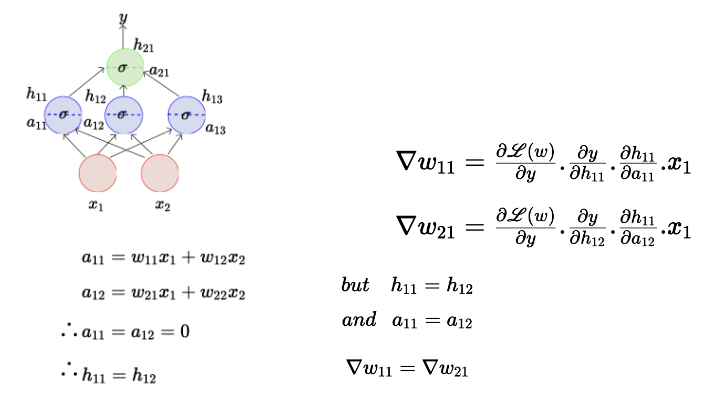
"Symmetry breaking problem" 즉, 대칭성 문제가 발생한다. 이는 동일한 값으로 학습을 진행하고 서로 다른 특징을 학습하지 못하게 된다.
즉, 다양성이 사라지게 되고 모든 뉴런이 같은 특징을 학습하게 되는 것이다.
Computer, Data
컴퓨터의 성능이 좋지 못하고 데이터가 적은 것도 이유였다.
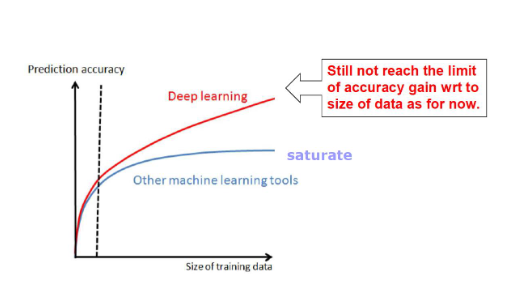
위 그림을 보면 아직 포화상태에 이르지 않았는데, 이는 더 많은 데이터가 있다면 성능이 더 좋아질 것임을 알 수 있는 그림이다.
