
개요
저번 글에서 over fitting을 막기 위해 Regularization이 필요함을 말했다. Bias & Variance
이번 글에서는 다음의 Regularization 기법을 알아보도록 한다.
-
L1/L2 normaliztion
-
Data augmentation
-
Parameter Sharing, tying
-
Early stopping
-
Ensembles
-
Dropout
L1/L2 normalization
L1 normalization
먼저 L1 normalization은 다음과 같이 정의한다.
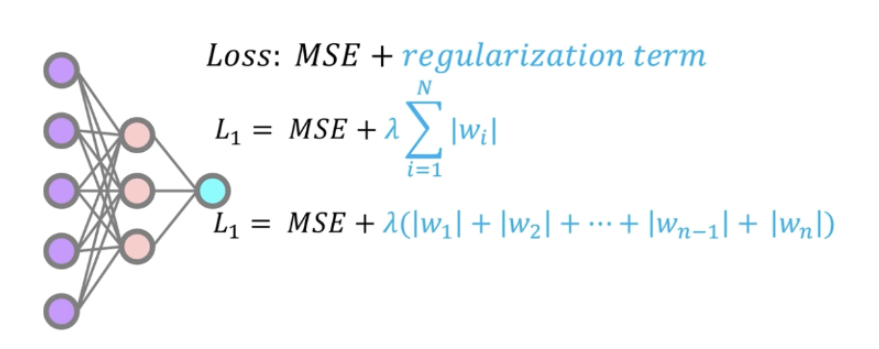
Loss에 regularization term인 을 더해준다.
W에 를 곱해주어 Loss를 계산하면 어떻게 되는지 살펴보자.
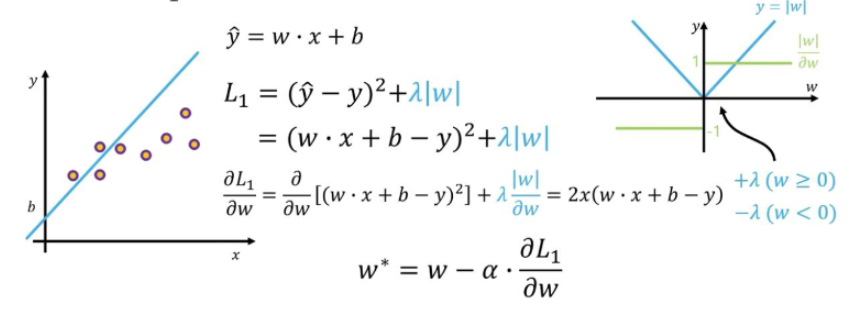
위와같이 w를 업데이트 할 때, w가 양수일 때는 를 더해주고 음수일 때는 를 더해준다.
이렇게 하면 불필요한 w를 없애줄 수 있다.
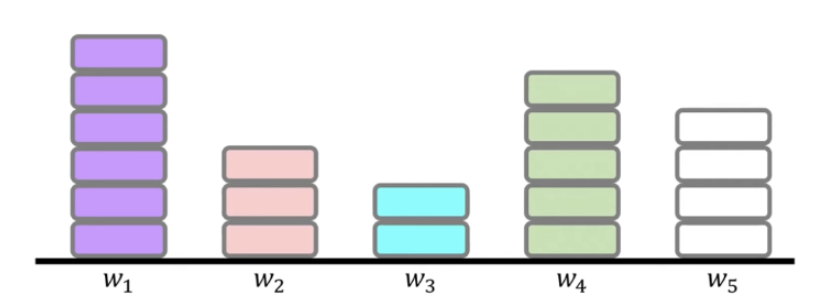
w가 위와 같이 양수라면, w를 업데이트 할 때 를 더해 줄 것이다. 는 크기가 작다. 를 몇번만 더해주어도 0이 될 것이다. 즉, 불필요했던 를 없앰으로써 model의 complexity를 줄일 수 있게 된 것이다.
L2 normalization
L2 normalization은 다음과 같이 정의한다.
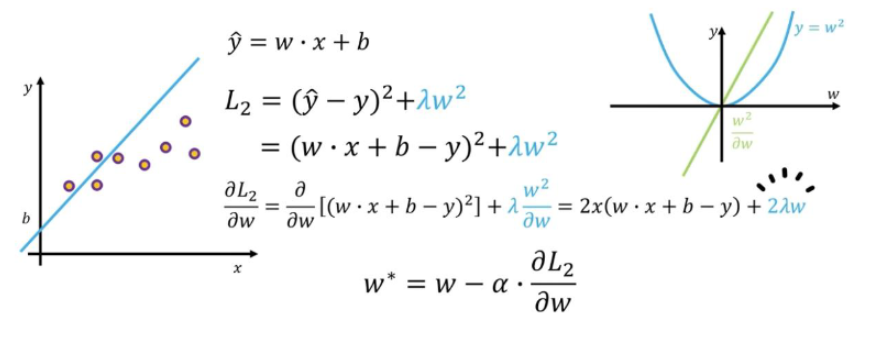
L1과 달리 을 더해주어 w의 크기에 더 민감하게 반응하도록 정의했다. 즉, 큰 w는 더 많이 영향을 받게되는 것이다.
Data augmentation
quality가 좋고 representative한 데이터를 많이 모으는 것이 overfitting을 피하는데에도 좋다. 그러나 현실적으로 이런 좋은 데이터를 많이 얻는 것은 매우 어렵다.
그렇기 때문에 우리는 training datapool을 넓히기 위해 artificial training data를 만들 것이다. 이를 Data augmentation (데이터 증강)이라 부른다.
Data augmentation은 다음 두 가지 방법이 있다.
-
Label-preserving augmentations
-
Label-perturbing augmentations
Label-preserving
우리는 데이터를 가공해도 데이터의 label은 그대로인 사실을 이용할 것이다.
일반적으로 더 많은 데이터가 있으면 더 학습을 잘한다.
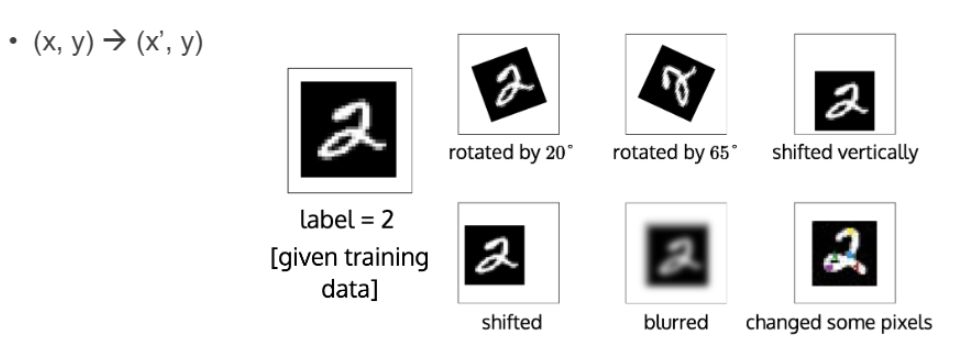
위처럼 데이터를 회전하고 blurred 처리하고 이동시키는 등, 데이터를 가공한다.
Label-perturbing
mixup이라는 기법인데 이는 x(데이터)와 y(label) 둘 다 수정하는 기법이다.
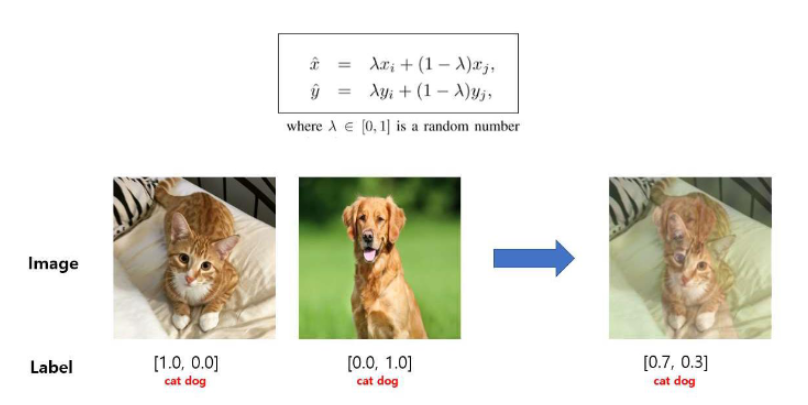
cat과 dog를 합성해서 label을 cat일 확률 0.7, dog일 확률 0.3으로 만든 것이다.
이런 방식이 모델을 학습하는데 꽤나 효과적이다.
이외에도 이미지를 자르고 붙이고 밝기를 낮추고 올리고 해상도를 낮추고 올리고 이미지의 특정 부분을 자르고 합성시키는 등 매우 다양한 방법으로 data를 가공한다.
또한 더 많은 데이터를 얻기위해 요즘은 game industry에서 현실에서는 구하기 힘든 데이터들을 획득한다고 한다.
Parameter Sharing
CNN에서 이미지를 다룰때 많이 사용되며, W를 여러곳에서 공유하여 단순화한다.
이는 연산량을 줄일 수 있고 공유된 W는 데이터의 공간적/시간적 패턴을 더 잘 학습하도록 도와, 오버피팅을 방지하는 데 도움이 된다.
Parameter tying
특정 모델 구조에서 두 개 이상의 다른 레이어 또는 연산이 동일한 가중치를 공유하도록 강제하는 기법이다. Parameter Sharing과 개념적으로 유사하지만, 보다 명시적으로 특정 파라미터를 동일하게 유지하도록 설정하는 것을 의미한다.
Parameter Sharing은 모델 아키텍처 자체(CNN 등)에서 자연스럽게 발생하는 경우가 많고, Parameter Tying은 수동으로 특정 가중치를 공유하도록 설정하는 방식이다.
Encoder-Decoder에서 사용한다.
Early stopping
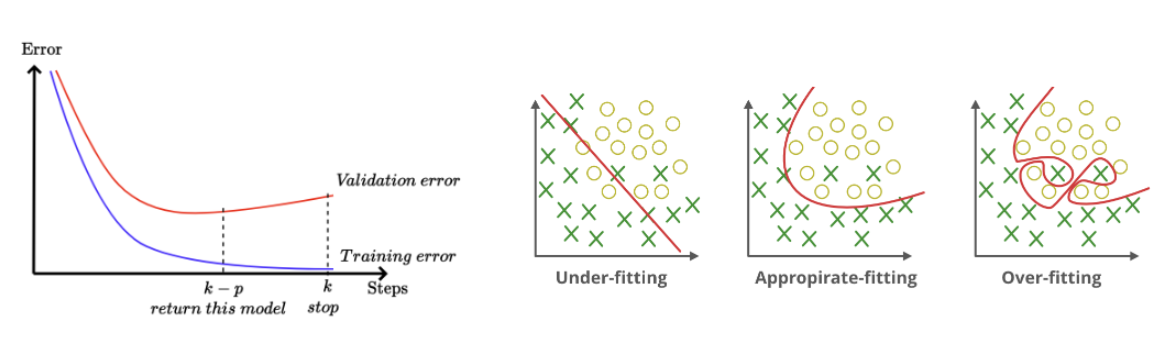
모델 학습을 언제 종료시킬지 정하는 것이다. 위 그림의 경우엔 k번째에서 멈추려고 한다.

가 weight이다. weight를 업데이트 하는데 중간 중간에 ValidationSetError()를 측정한다.
현재의 error가 더 작을 경우, weight를 업데이트 하고, 현재의 error가 더 클 경우(위의 그림에선 k - p 이후) j += 1을 해준다. 이러한 작업을 j가 p보다 작을 때까지 반복해준다.
이런식으로 모델을 학습한다.
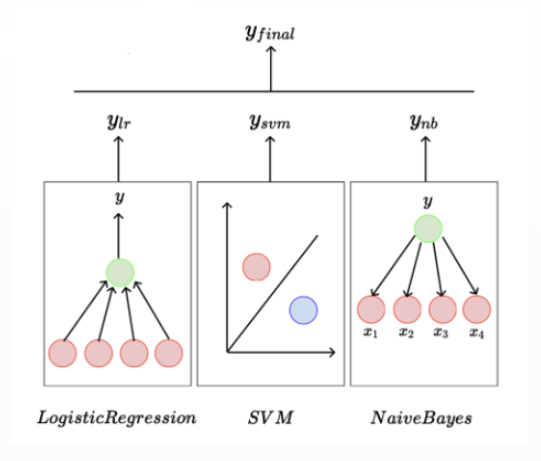
Ensembles
여러 모델로 학습을 시킨뒤 이들의 평균을 구한다는 개념이다.
-
각각의 모델을 다른 데이터 셋으로 학습시킬 수 있다.
-
단일 모델의 checkpoint를 여러개 둔다. (100번, 1000번, ...)
-
같은 모델을 다르게 초기화 한다.
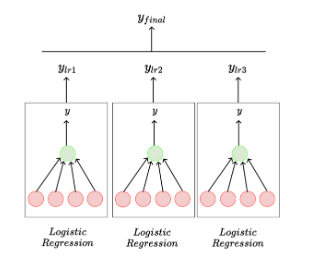
이러한 Ensemble은 성능을 올리기는 좋지만 비용이 매우 비싸다.
Dropout
dropout은 computational overhead 없이 효과적으로 뉴런들을 학습시킬 수 있고, 특정 뉴런에 의존 하는 것을 방지해준다.
dropout은 학습 과정에서 일부 뉴런을 랜덤하게 제거(0으로 설정)한다. (일반적으로 p=0.5)
N개의 노드로 개의 모델을 만들 수 있는 것이다.

이를 통해 신경망이 다양한 서브 네트워크의 앙상블(ensemble) 효과를 내며, 일반화 성능이 좋아진다.
다음 그림을 보면 오른쪽 두 모델이 서로 다른 모델처럼 동작하는 것을 알 수 있다.
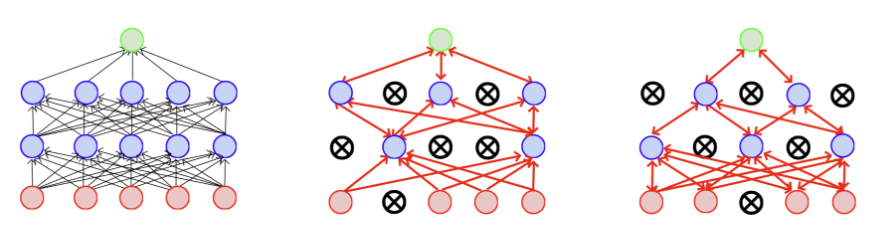
또 이는 co adaptation 문제를 막을 수 있다. co adaptation 문제는 모든 weight들이 한번에 학습되면 특정 weight에 의존적으로 학습이 되는 문제이다.
즉, 특정 뉴런에 의존적으로 학습하는 것을 막을 수 있는 것이다.
Summary
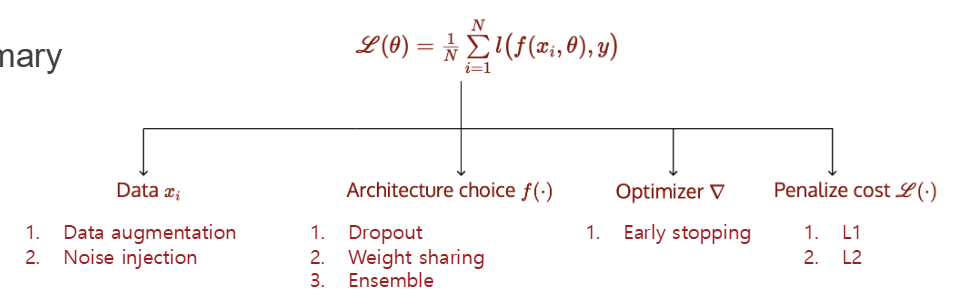
먼저 Good convergence가 가장 우선시 되어야 하고, 그 다음 generalization issue를 다룬다.
Good convergence가 Good generalization이 되는 것은 아니기 때문에 이도 같이 고려해야한다.
