
개요
Bias와 Variance의 개념을 알아보자.
먼저 다음 복잡한 모델과 간단한 모델을 보자.
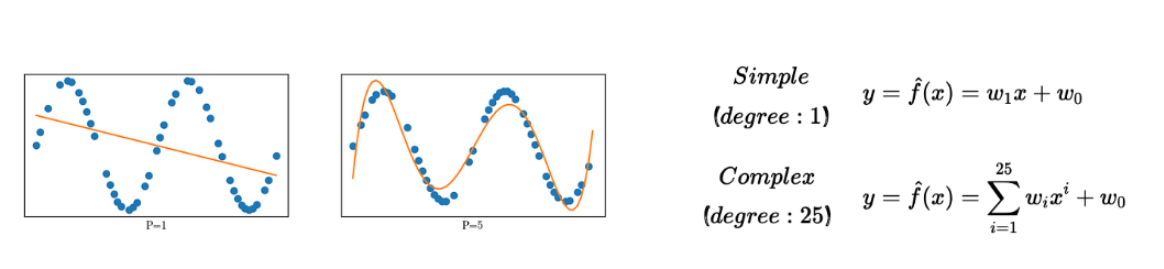
training data를 n개의 sample들로 나누어, 이 복잡한 모델과 간단한 모델을 학습시켜 보자.
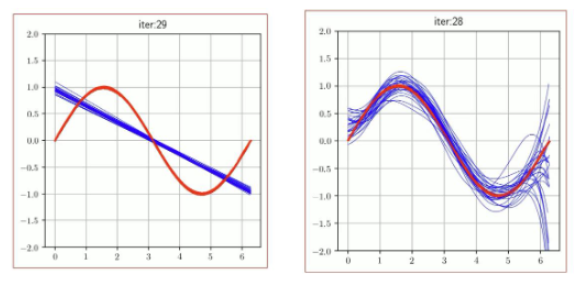
파란색 선은 학습된 모델이고 빨간색 선은 정답이다.
그림에서 확인할 수 있듯이 간단한 모델은 서로가()크게 다르지 않지만 정답을 잘 맞추지 못한다는 것을 알 수 있다. (under fitting)
반면에, 복잡한 모델은 정답을 잘 맞추었지만 서로가 많이 다르다는 것을 알 수 있다. (high variance)
Bias
bias는 다음과 같이 정의한다.
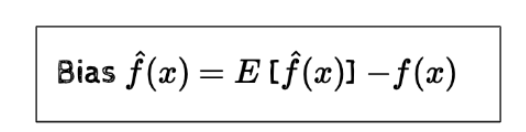
들의 평균과 정답의 차이로 정의한다.
즉, 모델과 예측 모델의 차이라고 생각할 수 있다.
위에서 볼 수 있듯이 simple model은 bias가 높고 complex model은 bias가 낮음을 알 수 있다.
Variance
variance는 다음과 같이 정의한다.
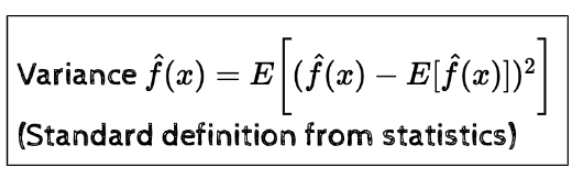
와 나머지 들의 차이이다.
즉, 예측한 모델들 간의 차이로 생각할 수 있다.
위에서 볼 수 있듯이 simple model은 variance가 낮고 complex model은 variance가 높음을 알 수 있다.
Bias - Variance Tradeoff
위에서 확인할 수 있듯이 Bias와 Variance는 tradeoff 관계를 갖음을 알 수 있다.
-
simple model: high bias, low variance
-
complex model: low bias, high variance
학습 방향
우리의 목표는 (unseen) test data에서 error를 줄이는 것이다.

위와 같이 Bias와 Variance를 둘 다 줄이도록 학습시켜야 한다.
다음 그림을 보자. (파란색 선은 train error, 빨간색 선은 test error)
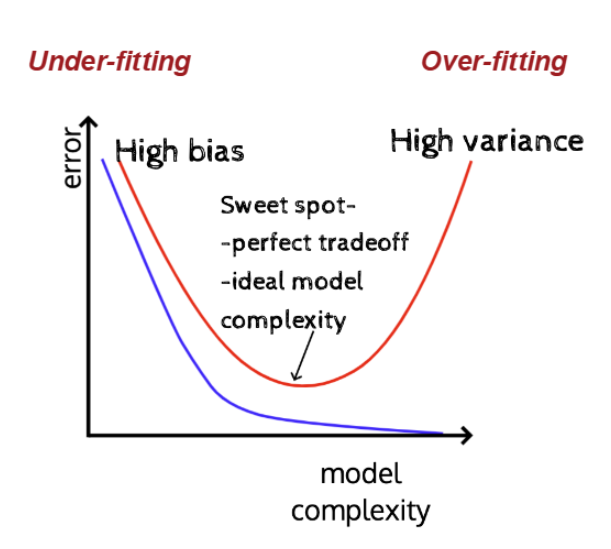
model의 complexity가 올라갈수록 train error는 줄어들지만 반대로 test error는 크게 높아짐을 알 수 있다.
이는 model의 complexity가 너무 올라가면 개별 데이터 셋의 noise까지 과도하게 학습하여, 일반적인 경우를 잘 표현하지 못하게 되는 것이다. 이러한 문제를 Over-fitting이라 한다.
complex model의 variance가 높은 이유도 바로 이 때문이다. 개별 데이터 셋을 과도하게 학습하다보니, 서로가 너무 달라지는 것이다.
우리는 이를 방지하기 위해 Under-fitting과 Over-fitting의 사이인 Sweet spot을 잘 찾아서 모델을 학습시켜야 한다.
Regularization
사실 DNN은 매우 복잡한 모델이고 많은 parameter를 갖는다. 그렇기 때문에 쉽게 Over fitting될 수 있어서 Regularization이 필요하다.
