<TIL-16> 웹 크롤러 개발 코드 리뷰_(프로그래머스를 통해 검색되는 파이썬 개발자 채용 공고 CSV로 저장하기)_utilize selenium, pandas
0

1. 개발동기
- 약 1주 전 처음으로 웹 크롤러 개발에 도전했을 때, requests 와 Beautifulsoup, csv 라이브러리를 활용하였다. 당시 적은 지식이지만 requests를 활용해 URL을 불러오고, Beautifulsoup 라이브러리에 있는 html.parser를 활용하여 html의 Tag들을 해석하는 개념을 알게 되었다. 특히 Beautifulsoup의 find메서드를 활용하여, 내가 원하는 Tag와 class의 내용을 가지고 오는 것에 흥미를 느끼게 되었다.
이후 공부를 계속 하면서, selenium 라이브러리를 알게 되었고 cromedriver를 활용하여 웹의 동작을 자동화 할 수 있다는 것에 관심을 가지게 되었다. 특히 selenium으로 크롤링을 할 경우 1주전 공부했던 개념과 매우 흡사하다고 판단하여, 이번에는 selenium을 활용한 웹 크롤러를 개발해 보고 싶었다.
2. 전체 코드 및 리뷰
-
총 3개의 파일로 나누어 모듈과 메서드를 관리했다.
job_search.py
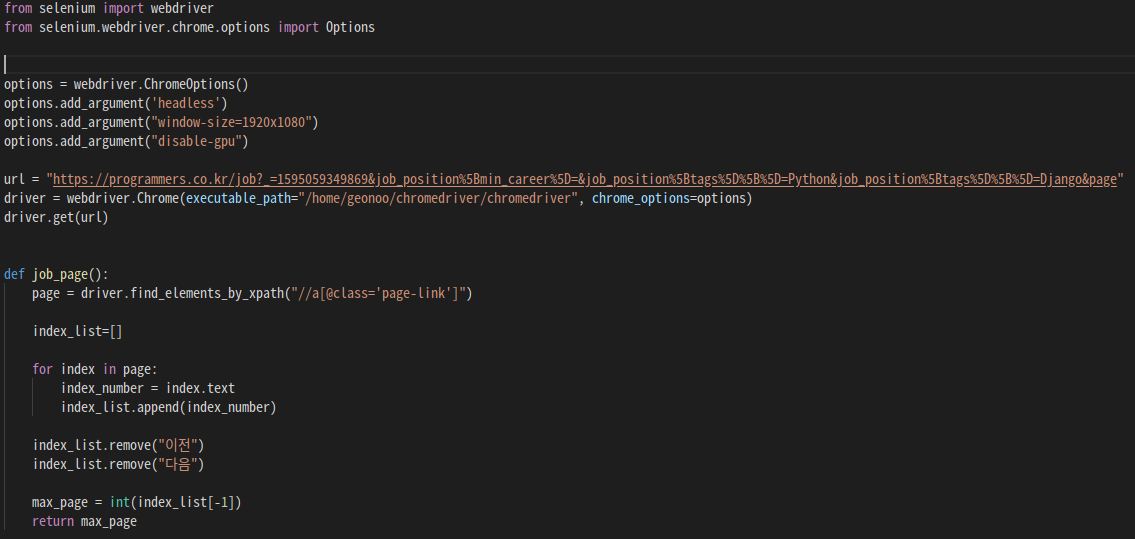
2-1. 크롬 드라이버 실행하기 (전역 변수)
- 내가 크롤링 하고 싶은 페이지의 url을 url변수로 선언하였다.
- 먼저 크롬드라이버를 실행시켜야 하기 때문에, driver = webdriver.Chrome(크롬드라이버가 있는 위치)로 선언하였다.
- driver.get(url)을 통해 내가 원하는 url을 크롬드라이버로 실행 시켰다.
- 크롬을 백그라운드로 실행시키고 싶었는데, 이유는 뒤에 설명 하겠다. 이를 가능하게 해주는 라이브러리를 먼저 import 시켜야 한다.
from selenium.webdriver.chrome.options import Options - 3가지 크롬 옵션을 설정해 주어야 크롬이 백그라운드에서 실행하게 된다.
options.add_argument('headless') options.add_argument("window-size=1920x1080") options.add_argument("disable-gpu") - 크롬 드라이브가 실행 될 때, 설정된 옵션을 적용하겠다고 알려주어야 한다.
excutable_path= 는 크롬드라이브가 있는 위치이고, chrome_options= 내가 설정한 옵션으로 실행시키겠다는 뜻이다.driver = webdriver.Chrome(executable_path="/home/geonoo/chromedriver/chromedriver", chrome_options=options)
- 옵션을 설정하기 위해 option라이브러리를 따로 import해야 된다는 것을 몰라 고생했다...
2-2. 검색 결과에 따라 나오는 페이지 수 추출
- 내가 크롤링 하려는 검색결과 페이지는 위와 같이 구성되 있었다.
- 먼저 페이지는 숫자로 구성되어 있고, 처음과 끝은 텍스트로 '이전'과 '다음' 이라는 text로 되어 있다.
- 먼저 페이지를 구성하고 있는 Tag를 선택했다.
page = driver.find_elements_by_xpath("//a[@class='page-link']")
- find_elements_by_xpath로 찾은 Tag는 리스트 형식으로 저장된다.
- for 반복문을 활용하여, page리스트의 각 태그들을 text형식으로 바꿔주고, 미리 선언했던 빈 리스트 변수에 저장한다.
- 현재 url의 page리스트는 ['이전','1','2','3','4','다음]으로 구성되어 있으므로, list.remove('이전') list.remove('다음')으로 리스트에서 빼준다.
- 리스트에서 남은 1,2,3,4 중 가장 끝 '4'만 int형으로 변환 시켜준다. (만약 업데이트로 인해 페이지의 수가 변한다 하더라도, range함수를 활용해 가장 끝에 수만 입력해 준다면 대응할 수 있기 때문이다.)
max_page = int(list[-1])
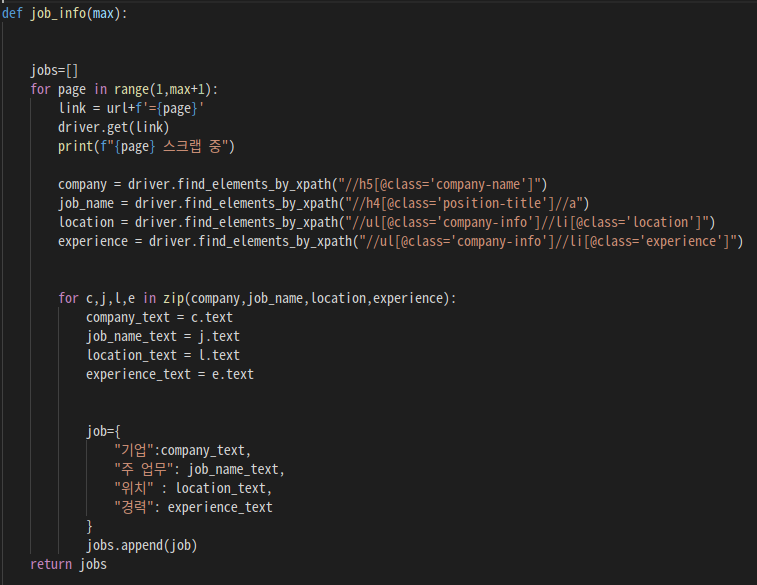
2-3. max_page만큼 각 페이지를 돌면서, 선택한 Tag의 내용을 끌어온다.
-
1 부터 max_page+1 만큼 먼저 각 페이지를 열 수 있도록 해준다.
for page in range(1,max+1):
range(max_page)로 반복문을 돌릴경우, 현재 max_page는 4이므로, 0~3까지 출력되게 된다. 1부터 3+1까지 range해준다.
-
각 페이지를 이동 할 수 있도록 url의 규칙을 찾았다.
해당 url은 마지막에 "url"+"=1"과 같이 구성되어 있었기에, "=1","=2","=3","=4"로 각 페이지를 이동할 수 있게 해줄 수 있었다.for page in range(1,max+1): link = url+f'={page}' driver.get(link)page 변수에 1,2,3,4가 들어가게 되고, page 1, page 2, page 3, page 4 가 순차적으로 열린다.
-
내가 찾고 싶은 Tag를 xpath방식으로 찾고, 여러 리스트의 요소들을 한번에 text로 변환하기 위해 zip함수를 활용했다.
for c,j,l,e in zip(company,job_name,location,experience): company_text = c.text job_name_text = j.text location_text = l.text experience_text = e.text
-
text로 변환 된 tag의 내용들은 job딕셔너리에 먼저 담긴 후, jobs리스트로 변환 해준다.
CSV파일로 저장하기 위함.
save_job.py
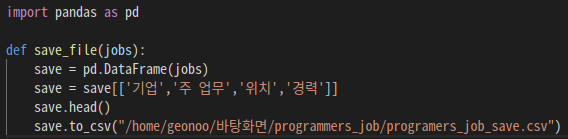
2-4. pandas 라이브러리를 활용하여, 리스트로 반환 된 value값을 CSV파일로 저장
- pandas 라이브러리를 먼저 import 한다.
- 어떤 리스트를 데이터로 다룰지 선택해준다. pd.DataFrame()
save = pd.DataFrame(jobs) - csv파일로 변환 시 각 요소들의 제목(head)를 설정해 줄 수 있다.
save = save[['기업','주 업무','위치','경력']] save.head() - csv파일로 저장시 어디에, 어떤 이름으로 저장 할 지 설정해준다.
save.to_csv("/home/geonoo/바탕화면/programmers_job/programers_job_save.csv")scrap_action.py
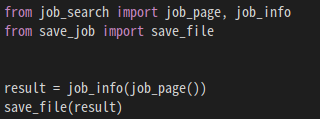
2-5. 실행
- result 변수는 job_page: 처음 부터 끝페이지 까지의 job_info: 채용정보를 저장한다.
result = job_info(job_page()) - 저장된 result리스트를 save_file(): CSV파일로 저장한다.
3. 오류가 발생했던 구간
3-1. 채용 정보 태그가 읽히지 않는 오류
- Tag를 불러오기 위해 작성한 첫 코드 오류
location = driver.find_elements_by_xpath("li[@class='location']")
- 원인:
부모인 ul태그를 무시한채, 바로 자식인 li태그를 불러왔기 때문에 오류 발생
- 해결:
ul태그를 먼저 찾고, 자식인 li태그를 불러옴으로 해결 되었다.
3-2. 함수 호출로 실행 시, xpath값을 모두 찾을 수 없는 오류 발생
- 오류 내용 요약
ConnectionRefusedError: [Errno 111] Connection refused
During handling of the above exception, another exception occurred:
Traceback (most recent call last):- 원인:
호출중인 모듈에서 driver.quit()이 먼저 실행 되고 있었음.
크롤링 완료 후 크롬드라이버 창을 닫기 위해, 실행한 명령어가 먼저 작동하면서 크롤링을 완료하지도 않은채 크롬드라이버를 닫아버림
- 해결:
-. 오류를 읽어 본 결과 요약하자면 connection refused 되었음
-. 예외를 처리 중에 다른 예외가 발생했음
-. 함수 호출 중 생긴 오류를 최근 순서대로 보여주는 Traceback 오류내용은, xpath방식으로 태그를 긁어 올 수 없다고 함
-. 코드가 실행되는 모양과 오류내용을 연결하여 유추해본 결과, 크롬창이 켜짐과 동시에 꺼지는 것이 혹시 연결이 거부된다는 뜻인지 생각 하게 됨.
-. drive.quit()을 지우고 실행한 결과 정상 작동
-. 그렇다면 크롬창을 아에 띄우지 말고 백그라운드 동작을 시키는 것으로 해결.
3. 깃허브 주소

꾸준하게 공부하기