
프로그램 로딩 중에 심각한 랙이 발생했다. 프로파일러를 살펴보니 OBJ와 지형을 로드하는 과정에서 무려 2.2초나 소모되고 있었고, 심할 때는 응답없음 상태에 빠지기까지 했다.
이를 해결하기 위해 비동기(Asynchronous) 로딩을 도입하여 프레임 드랍을 잡아보기로 했다.
먼저 전에 건드렸던 청크 매니저를 살펴보자
// 메인 함수
void ChunkManager::update(const glm::vec3& playerPos, std::vector<GameObject*>& objects)
{
glm::ivec2 newCenter = worldToChunk(playerPos.x, playerPos.z);
bool centerChanged = (!initialized || newCenter != currentCenter);
std::vector<glm::ivec2> unloadedList; //이번 호출의 변동 (출력용)
std::vector<glm::ivec2> loadedList;
//좌표가 바뀌면 로드 언로드
if (centerChanged)
{
initialized = true;
currentCenter = newCenter;
//=== 1) 원하는 청크 인덱스 집합 만들기 ===
std::vector<glm::ivec2> desired; //청크 (x,z) 3x3 => 즉 9개.
setDesired(desired, newCenter);
//2) 멀어진 청크 unload
unloadedList = unloadFarChunks(desired, objects);
//3) 청크 로드 (비동기)
requestLoadChunks(desired);
}
//=== 매 프레임: pending 큐 폴링 ===
//워커가 끝낸 청크가 있으면 메인 스레드에서 GL 업로드 (프레임당 maxUploadsPerFrame 개씩)
//→ 9개 동시 spike 대신 9프레임에 분산 → "응답없음" 사라짐
loadedList = processPendingChunks(objects);
//4) 변동 있을 때만 출력
if (!unloadedList.empty() || !loadedList.empty())
{
//printChunkInfo(newCenter, unloadedList, loadedList);
}
}청크 로드 함수를 비동기 방식으로 고쳤다.
비동기 함수
비동기 로딩을 구현하면서 몇 가지 중요한 처리들이 필요했다.
lock
비동기 함수가 실행 중인데 플레이어가 움직여서 같은 청크 로딩을 또 요청하면 어떻게 될까? 불필요한 연산이 두 번 돌아가고 충돌이 날 수 있다. 그래서 현재 비동기로 처리 중인 청크인지 확인하는 로직이 필요했다.
//이미 pending 중인지 확인 — 같은 청크 두 번 의뢰 방지
bool inPending = false;
for (const auto& p : pendingFutures)
{
if (p.idx == d) //내 범위와 처리중인 pending이 같다면
{
inPending = true;
break;
}
}
if (inPending) continue;async, future
비동기 작업을 던지고 그 결과를 나중에 받으려면 std::future가 필요하다. 이를 관리하기 위해 구조체를 만들었다.
struct PendingChunk
{
glm::ivec2 idx;
std::future<ChunkMeshData> future; //워커가 만들고 있는 메시 데이터
};
std::vector<PendingChunk> pendingFutures;실제 비동기 호출은 std::async를 사용해 워커 스레드로 넘겼다.
glm::vec2 worldCenter(d.x * chunkSize, d.y * chunkSize);
PendingChunk pc;
pc.idx = d;
//비동기 호출
pc.future = std::async(
std::launch::async,
&Terrain::buildMeshData,
worldCenter,
Terrain::GRID_SIZE,
Terrain::CELL_SIZE,
Terrain::HEIGHT_SCALE,
Terrain::NOISE_SCALE,
Terrain::OCTAVES,
Terrain::SEED
);최종 코드
//비동기 청크 로딩
void ChunkManager::requestLoadChunks(const std::vector<glm::ivec2>& desired)
{
for (const auto& d : desired)
{
if (findChunk(d) >= 0) continue; //이미 chunks에 있음
//이미 pending 중인지 확인 — 같은 청크 두 번 의뢰 방지
bool inPending = false;
for (const auto& p : pendingFutures)
{
if (p.idx == d) //내 범위와 처리중인 pending이 같다면
{
inPending = true;
break;
}
}
if (inPending) continue;
glm::vec2 worldCenter(d.x * chunkSize, d.y * chunkSize);
PendingChunk pc;
pc.idx = d;
pc.future = std::async(
std::launch::async,
&Terrain::buildMeshData,
worldCenter,
Terrain::GRID_SIZE,
Terrain::CELL_SIZE,
Terrain::HEIGHT_SCALE,
Terrain::NOISE_SCALE,
Terrain::OCTAVES,
Terrain::SEED
);
//std::future는 move-only — push_back에 std::move 필수
//(안 그러면 컴파일 에러)
pendingFutures.push_back(std::move(pc));
}
}move
여기서 잠깐, 만들어진 PendingChunk 객체를 vector에 넣을 때 그냥 push_back(pc)를 하면 컴파일 에러가 난다.
std::future는 복사(Copy)가 불가능한 객체이기 때문이다. 함수가 끝나면 사라질 pc의 주소와 소유권을 벡터로 완전히 넘겨주기 위해 std::move를 사용해야 한다.
pendingFutures.push_back(std::move(pc));
결과 회수
it->future.get(); 함수는 결과 가져오는 함수,
wait_for 됐는지 안됐는지 확인하는 함수이다. 상태를 반환한다.
//=== Step 2: 비동기 청크 로딩 — 결과 회수 + GL 업로드 ===
// ready된 것들을 메인 스레드에서 Terrain 객체 생성 (Mesh GL 업로드).
std::vector<glm::ivec2> ChunkManager::processPendingChunks(std::vector<GameObject*>& objects)
{
std::vector<glm::ivec2> loadedList;
int processed = 0;
//pendingFutures 탐색
for (auto it = pendingFutures.begin(); it != pendingFutures.end() && processed < maxUploadsPerFrame; )
{
//(future.get()을 그냥 부르면 메인 스레드 차단 → 비동기 의미 사라짐)
if (it->future.wait_for(std::chrono::milliseconds(0)) != std::future_status::ready)
{
//it->future.wait_for(std::chrono::milliseconds(0) : 0초 차단 이후 상태 리턴
++it;
continue;
}
//데이터 회수
glm::ivec2 d = it->idx;
ChunkMeshData md = it->future.get();
//플레이어가 빠르게 움직여 이 청크가 이미 시야 밖으로 나갔는지 확인
//(viewRadius 안인지) — 밖이면 결과 폐기, 안이면 GL 업로드
bool inRange = (std::abs(d.x - currentCenter.x) <= viewRadius &&
std::abs(d.y - currentCenter.y) <= viewRadius);
if (!inRange)
{
//이미 멀어짐 — 만들 필요 없음, md는 그냥 소멸
it = pendingFutures.erase(it);
continue;
}
//GL 업로드 (메인 스레드 only) => 아래부턴 비동기 아님
glm::vec2 worldCenter(d.x * chunkSize, d.y * chunkSize);
Terrain* chunk = new Terrain(*shader, color, worldCenter, md);
if (textureId) chunk->setTexture(textureId);
if (normalMapId) chunk->setNormalMap(normalMapId);
if (shadowMapId) chunk->setShadowMap(shadowMapId);
chunks.push_back(chunk);
chunkIndices.push_back(d);
objects.push_back(chunk);
loadedList.push_back(d);
//다 됐으니 제거
it = pendingFutures.erase(it);
processed++;
}
return loadedList;
}최적화 결과
상상 이상으로 결과는 성공적이었다. 디버그 로그를 확인해 보니 1프레임당 처리 시간이 극적으로 줄어들었다.
Before: 67.17ms (메인 스레드에서 랙 발생)
After: 0.72ms (메인 스레드는 폴링만 하고 넘어감)
응답없음이나 화면 멈춤 현상이 완전히 사라졌고, 플레이어 이동이 매우 부드러워졌다.

before - 67.1706ms

after - 0.7225ms
한번 전체 로그를 보면서 최종적으로 얼마나 줄었는지 보자.
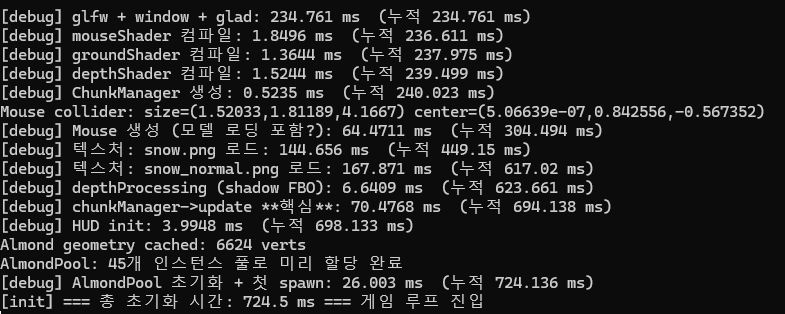
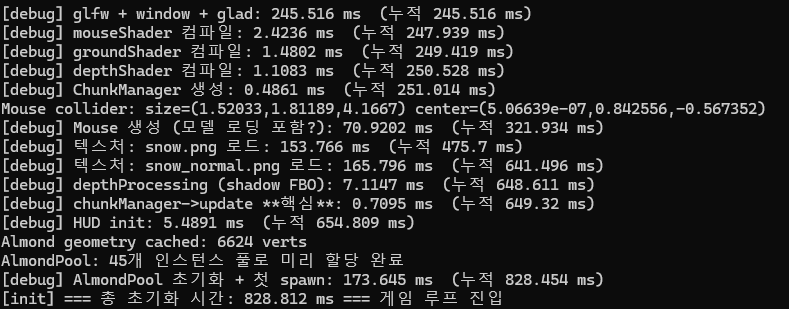
음?
원인은 CPU 코어 경쟁 때문인 것으로 추측된다. 지형 생성을 비동기로 처리하는 동시에 아몬드 생성 함수(풀 처리 코드)도 함께 실행되다 보니 코어 점유율에 병목이 발생한 것이다.
결론적으로 로딩 랙을 줄이고자 비동기 함수를 도입했지만, CPU 코어 경쟁으로 인해 시간이 더 늘어나게 되었다. 결국 현재 아키텍처에서는 비동기로 설정하지 않는 방법(동기식)이 전체 속도 면에서 더 빠르다는 것을 확인했다.
이후
코어 경쟁 문제를 해결하기 위해 동시에 실행되는 워커 스레드의 수를 제한해 보기로 했다.
maxConcurrentWorkers 값을 설정하여 시스템이 감당할 수 있는 만큼만 스레드를 동작하게 하고, 남은 작업들은 waitingQueue에 넣어 순차적으로 대기하도록 구조를 수정했다.
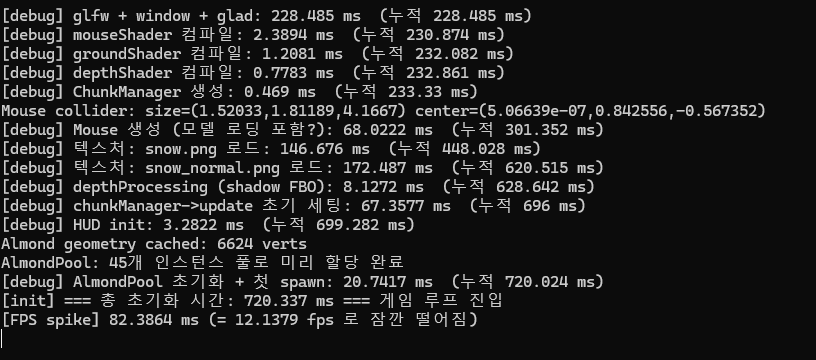
before
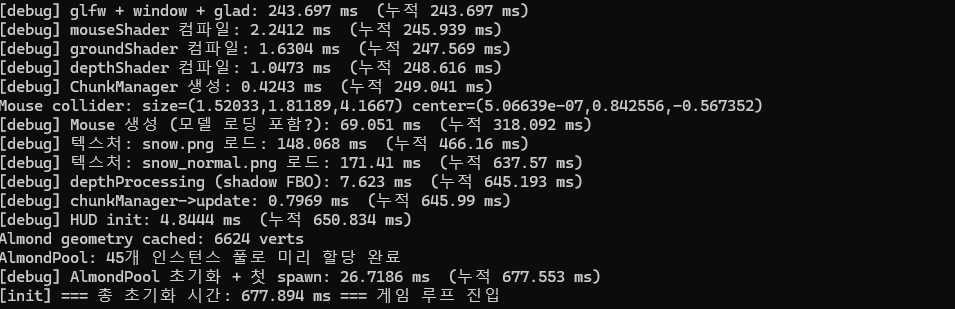
after
어? 수정 후 테스트를 진행해 보니 긍정적인 결과가 나타났다. 코어 병목 현상이 완화되면서 전체 소요 시간이 이전 대비 약 80ms 정도 추가로 단축되었다.
