< 데이터프레임의 구조 >
1. .head( ) /.tail( )
메소드
df.head( ) : 앞에서 5개 행을 보여줌
df.head(n) : 앞에서 n개 행을 보여줌
메소드
df.tail( ) : 뒤에서 5개 행을 보여줌
df.tail(n) : 뒤에서 n개 행을 보여줌
2. .shape /.info( ) /.dtypes( ) /.describe( )
: 데이터 요약 정보 확인
df.shpae 데이터프레임 클래스 속성
: df에 저장된 데이터프레임의 크기(행과 열의 개수)를 튜플 형태로 보여준다.
df.info( ) 메소드
: 데이터프레임에 관한 기본 정보를 화면에 출력한다. (클래스 유형, 행 인덱스의 구성, 열 이름의 종류와 개수, 각 열의 자료형과 개수, 메모리 사용량)
df.dtypes 데이터프레임 클래스 속성
: 각 열의 자료형을 확인할 수 있다. 특정 열만 선택하여 적용하는 것도 가능하다.
🍊 df.열 이름.types
df.describe( ) 메소드
: 산술(숫자) 데이터를 갖는 열에 대한 주요 기술 통계 정보(평균, 표준편차, 최대값, 최소값, 중간값 등)를 요약하여 출력한다.
산술데이터가 아닌 열에 대한 정보를 포함하고 싶을 때는 inclued='all' 옵션을 추가한다.
🍊 df.describe(include = 'all')
3. .count( ) /.value_counts( )
: 데이터 개수 확인 info()메소드는 화면에 각 열의 데이터 개수 정보를 출력하지만 반환해 주는 값이 없어서 다시 사용하는데 어려움이 있따. 반면 count()메소드는 데이터프레임의 각 열이 가지고 있는 데이터 개수를 시리즈 객체로 반환한다. 단, 유효한 값의 개수만을 계산하는 점에 유의한다.
df.counts( ) 메소드
: df의 각 열의 데이터 개수를 시리즈 객체로 출력한다. 왼쪽엔 각 열의 이름이 오른쪽엔 각 열의 데이터 개수가 오른쪽에 표시된다.
df[ '열 이름' ].value_counts( ) 메소드
: 시리즈 객체의 고유값(unique value) 개수를 세는 데 사용한다. 데이터프레임의 열은 시리즈이므로, value_counts() 메소드로 각 열의 고유값의 종류와 개수를 확인할 수 있다.
행 인덱스 -> 고유값 // 데이터 값 -> 고유값의 개수
dropna=True 옵션을 설정하면 데이터 값 중에서 NaN을 제외하고 개수를 계산한다.
옵션을 따로 지정하지 않으면 dropna =False 옵션이 기본이다. 이때는 NaN이 포함된다.
< 통계 함수 적용 >
1. 평균값 .mean( )
: 산술 데이터를 갖는 모든 열의 평균값을 각각 계산하여 시리즈 객체로 반환한다. 특정 열 선택 가능
메소드
df.mean( )
df[ '열 이름' ].mean( )
df[[ '열 이름' , '열 이름2' ]].mean( )
2. 중간값 .median( )
:산술 데이터를 갖는 모든 열의 중간값을 계산하여 시리즈로 반환한다. 특정 열 선택 가능
메소드
df.median( )
df[ '열 이름' ].median( )
df[[ '열 이름' , '열 이름2' ]].median( )
3. 최대값 .max( ) 최소값 .min( )
: 각 열이 갖는 데이터 값 중에서 최대값과 최소값을 계산하여 시리즈로 반환한다. 특정 열 선택 가능
메소드
df.max( )
df[ '열 이름' ].max( )
df[[ '열 이름' , '열 이름2' ]].max( )
- 산술데이터를 가진 열에 대해서는 가장 클 숫자를 찾아서 최대값으로 반환한다.
메소드
df.min( )
df[ '열 이름' ].min( )
df[[ '열 이름' , '열 이름2' ]].min( )
- 산술데이터를 가진 열에 대해서는 가장 클 숫자를 찾아서 최소값으로 반환한다.
<공통>
- 문자열(object) 데이터를 가진 열에 대해서는 문자열을 ASCII 숫자로 변환하여 크고 작음을 비교한다.
- 산술 데이터에 문자가 포함되어 있으면 다른 숫자 값까지 전부 문자열로 인식된다.
4. 표준편차 .std( )
:산술 데이터를 갖는 열의 표준편차를 계싼하여 시리즈로 반환한다. 특정 열 선택 가능
문자열 데이터를 가진 열에 대해서는 계산을 하지 않는다.
메소드
df.std( )
df[ '열 이름' ].std( )
df[[ '열 이름' , '열 이름2' ]].std( )
4. 상관계수 .corr( )
:두 열 간의 상관계수를 계산한다. 산술 데이터를 갖는 모든 열에 대하여 2개씩 서로 짝을 짓고, 각각의 경우에 대하여 상관계수를 계산한다. 문자열은 계싼이 불가능하기 때문에 포함하지 않는다. n개의 변수를 각각 행과 열에 위치하여 데이터프레임을 만들고, 각 경우의 수에 대하여 상관계수를 표시한다.
메소드
df.corr( )
df[[ '열 이름' , '열 이름2' ]].corr( ) 2개 이상의 열 이름

< 판다스 내장 그래프 도구 활용 >
그래프를 이용한 시각화 방법은 데이터의 분포와 패턴을 파악하는데 크게 도움이 된다.
판다스는 Matplotlib 라이브러리의 기능을 일부 내장하고 있어서, 별도로 임포트하지 않고도 간단한 그래프를 손쉽게 그릴 수 있다.
df.plot(kind='그래프종류')
🍕판다스의 내장 plot() 메소드 - 그래프 종류🍕
- line(선그래프)
- bar(수직 막대 그래프)
- barh(수평 막대 그래프)
- his(히스토그램)
- box(박스 플롯)
- kde(커널 밀도 그래프)
- area(면적 그래프)
- pie(파이 그래프)
- scatter(산점도 그래프)
- hexbin(고밀도 산점도 그래프)
1. 선 그래프 .plot(kind='line')
: 데이터프레임(또는 시리즈) 객체에 plot()메소드를 적용할 때, 다른 옵션을 추가하지 않으면 가장 기본적인 선 그래프를 그린다.
선 그래프 : df.plot()
-
기본
x축 = 행 인덱스
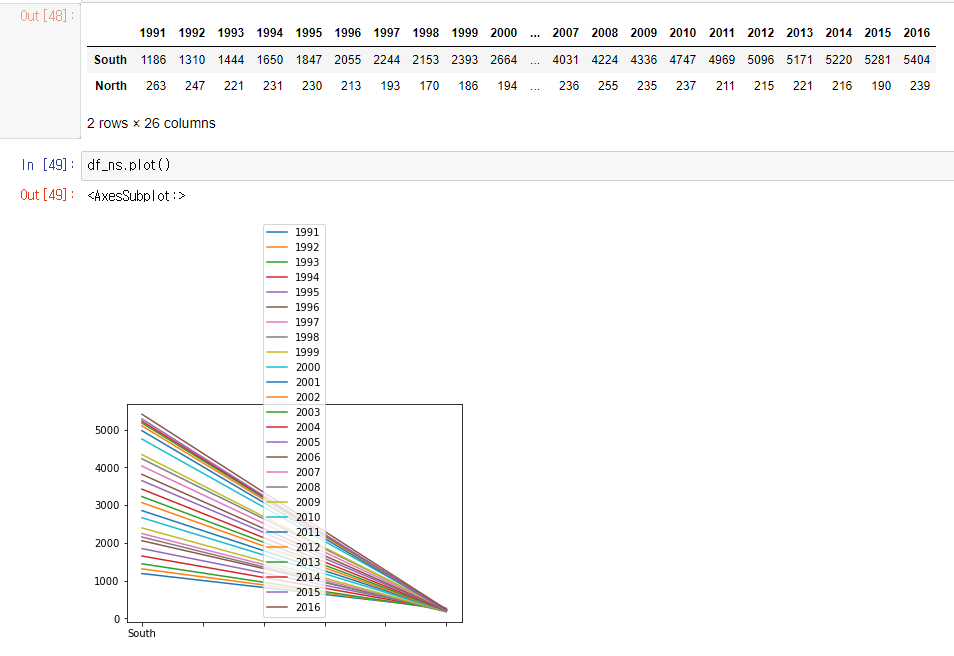
-
그래프의 목적 : 시간에 흐름에 따른 연도별 발전량 변화 추이를 보기 위해서
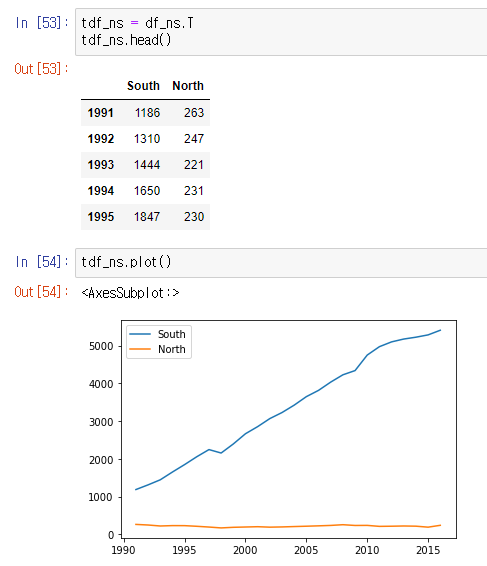
x축 : 연도 값 ( 열 이름을 구성하고 있는 연도 값이 행 인덱스에 위치하도록 행렬을 전치하기 )
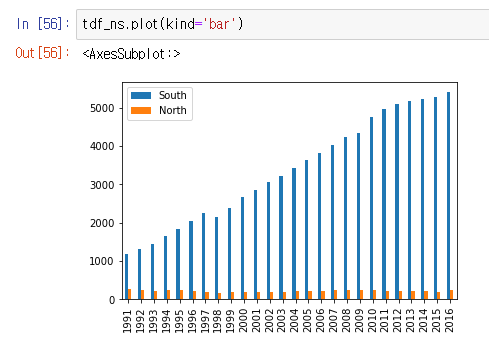
2. 막대 그래프 .plot(kind='bar')
:선그래프가 아닌 다른 종류의 그래프를 그리려면, kind 옵션에 그래프 종류를 지정한다.
세로 막대 그래프 : df.plot(kind='bar')
가로 막대 그래프 : df.plot(kind='barh')

3. 히스토그램 .plot(kind='hist')
: 데이터프레임의 도수 분포를 나타낸 그래프이다.
x축 = 계급 , y축 =빈도수(Frequency)
히스토그램 : df.plot(kind='hist')

4. 산점도 .plot(kind='scatter',x='',y='')
: 특정 두 변수의 관계를 산점도로 나타내는 그래프이다.
scatter 그래프를 사용하기 위해서는 열 중에서 서로 비교할 두 변수를 선택해야한다.
산점도 : df.plot(kind='scatter', x='열 이름', y='열 이름')
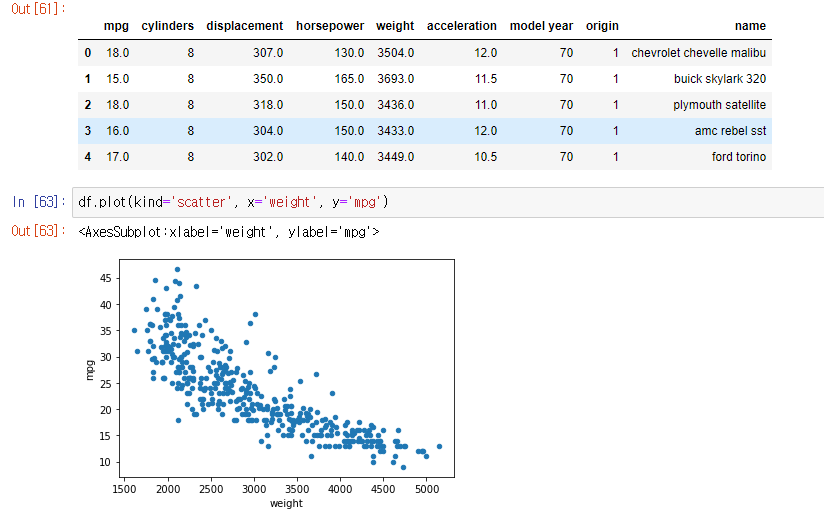
- 차량의 무게(weight)가 클수록 연비(mpg)는 전반적으로 낮아지는 경향을 보인다. 차량의 무게와 연비는 역(-)의 상관관계를 갖는다고 해석할 수 있다.
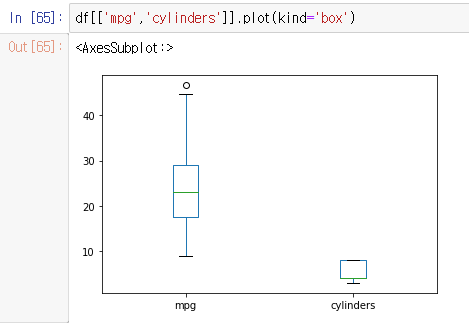
5. 박스플롯 .plot(kind='box')
: 특정 변수의 데이터 분포와 분산 정도에 대한 정보를 제공한다.
데이터프레임 열에 plot 메소드를 사용한다.
박스플롯 : df[['열이름','열이름']].plot(kind='box')