[파이썬 머신러닝 판다스 데이터 분석]
데이터과학은 데이터를 연구하는 분야이고, 데이터 자체가 가장 중요한 자원이다. 실제로 데이터 분석 업무의 80~90%는 데이터를 수집하고 정리하는 일이다. 나머지 10~20%는 알고리즘을 선택하고, 모델링 결과를 분석하여 데이터로부터 유용한 정보를 뽑아내는 분석 프로세스의 몫이다.
데이터과학자가 하는 가장 기초적이고 중요한 일은 데이터를 수집하고 분석이 가능한 형태로 정리하는 것.
판다스 라이브러리는 데이터를 수집하고 정리하는 데 최적화된 도구이다.
< Pandas Library >
서로다른 형식을 갖는 여러 종류의 데이터를 컴퓨터가 이해할 수 있도록 동일한 형식의 구조로 통합
Pandas -> Series(1차원), DataFrame(2차원) 이라는 구조화된 데이터 형식 제공
- 구성
- 여러종류의 클래스(class)
- 다양한 내장 함수(built-in function)
여기서 시리즈와 데이터프레임은 데이터 구조를 표현하는 대표적인 클래스 객체이다.
클래스의 속성과 메소드를 잘 이해하면 큰 어려움은 없을 것이다.
내장함수로는 Series(), DataFrame(), read_csv(), read_excel() 등이 있다.
- pandas 와 pd 의 차이
컴퓨터에 설치된 판다스를 파이썬 파일(확장자.py)에서 사용하려면, 판다스 라이브러리를 실행 환경으로 불러오는 작업이 필요한데 이때 "import pandas as pd" 라는 명령을 사용한다.
pandas 대신에 pd라는 약칭으로 부르겠다는 뜻이다. 만약 'as' 명령을 사용하지 않고, 'import pandas'라는 풀네임을 사용한다면, pandas.Series()라고 입력한다. 실무에서는 약칭을 더욱 자주 사용한다.
< Series 시리즈 >
🚩 Index와 Value 가 1:1 대응인 1차원 배열의 형태. (파이썬 딕셔너리와 비슷한 구조!)
1. 인덱스(Index)
- Index의 종류
-
정수형 위치 인덱스 (0,1,2, ---)
-
인덱스 이름(라벨) ('name1', 'name2',---)
=딕셔너리의 KEY
-
딕셔너리를 시리즈로 변환 : pandas.Series(딕셔너리)
-
리스트를 시리즈로 변환 : pansdas.Series(리스트)
단, 리스트를 시리즈로 변환할 때는 딕셔너리의 KEY처럼 인덱스로 변환될 값이 없다.
따라서 인덱스를 별도로 정의하지 않는 한, 디폴트로 정수형 위치 인덱스가 자동으로 지정된다.
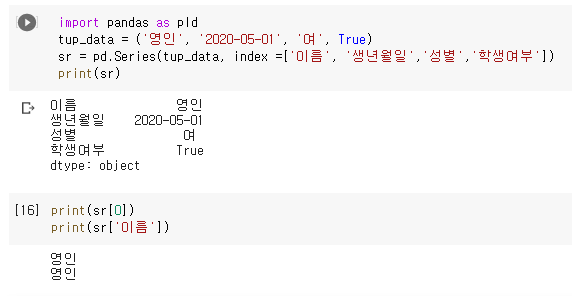
파이썬 튜플(tuple) 도 리스트처럼 정수형 위치 인덱스로 자동 지정된다.하지만, 리스트와 튜플도 Index 이름을 따로 지정할 수 있다.
왼쪽의 인덱스 위치에는 index옵션에 전달한 4개의 인덱스 이름이 표시되고, 오른쪽 데이터 값 위치에는 함수에 전달된 튜플(tup_data)의 원소 값들이 표시된다. 원소 데이터 값의 자료형(dtype)은 문자열(object)로 확인된다.

- 시리즈의 Index 속성과 values 속성을 이용하면 인덱스 배열과 데이터 값의 배열을 불러올 수 있다.

2. 원소 선택
- 원소의 주소 역할
Index를 이용해 시리즈의 원소를 선택한다.
- 정수형 위치 인덱스 : 대괄호
[ ]안에 숫자 입력 (slicing 가능) - 인덱스 이름(라벨) : 대괄호와 따옴표
[' ']안에 인덱스 이름 입력 (slicing 가능)
- 한개의 원소 선택
- 이중대괄호
[[ , ]]로 여러개의 원소 선택 (인덱스 이름에는 따옴표' '필수!)
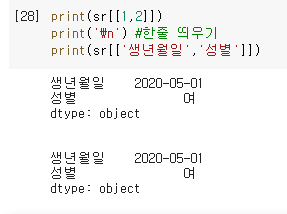
- 슬라이싱 [ : ]으로 여러개의 원소 선택 (괄호 다시 한개!)

< DataFrame 데이터 프레임 >
🚩 행과 열로 만들어지는 2차원 배열 구조. (여러 개의 시리즈들의 모임)
시리즈를 열벡터(vector)라고 하면, 데이터프레임은 여러개의 열벡터들이 같은 행 인덱스 기준으로 줄지어 결합된 2차원 벡터 또는 행렬(matrix)이다.
- 데이터의 행 : 행 인덱스(row index)
* 개별 관측대상에 대한 다양한 속성 데이터들의 모임인 레코드(recorde) / < 변수(variable) >
- 데이터의 열 : 열 이름(column name / column label)
* 공통의 속성을 갖는 일련의 데이터
🚩 엑셀과 관계형데이터베이스(RDBMS) 등 컴퓨터 관련 다양한 분야에서 사용됨.
1. 딕셔너리로 데이터프레임 만들기
-
데이터프레임을 만들기 위해서는 원소의 개수가 동일한 1차원 배열 여러 개가 필요하다.
-
딕셔너리의 키(k) 는 시리즈의 이름으로 변환되어 데이터프레임의 열 이름(column name)이 된다.
딕셔너리의 값(v) 은 각 리스트가 배열로 변환되어 데이터프레임의 열이 된다. -
딕셔너리를 데이터프레임으로 변환 : pandas.DataFrame(딕셔너리 객체)
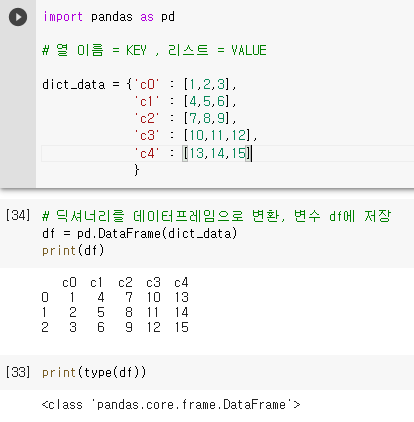
2-1. 2차원 배열 데이터(리스트,튜플)로 데이터프레임 만들기
-
2차원 배열 형태 데이터 : 여러개의 리스트/튜플을 원소로 갖는 리스트/튜플
1줄(1차원)의 리스트와 튜플이 아닌 2차원의 리스트와 튜플! -
리스트,튜플을 데이터프레임으로 변환 : pandas.DataFrame(2차원 배열)
-
리스트와 튜플의 각 리스트는 딕셔너리와 다르게 행으로 변환되는 점에 유의한다.
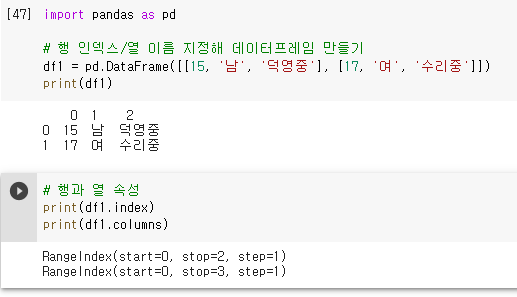
2-2. 행 인덱스/열 이름 직접 설정
2차원 배열 데이터에서 변경한 데이터프레임에서는 행 인덱스와 열 이름을 직접 설정 할 수 있으며 총 3가지 방법 정도가 있다. (딕셔너리 데이터프레임도 가능)
- DataFrame 함수 인자로 전달하여 데이터프레임으로 변활할 때 직접 지정
pandas.DataFrame( 2차원 배열, index = 행 인덱스 배열, column = 열 이름 배열)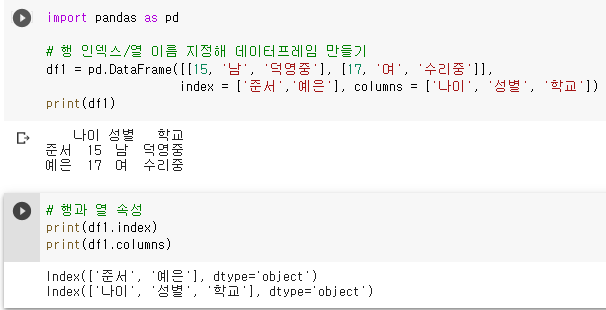
- 데이터프레임 df의 행 인덱스와 열 이름 객체를 나타내는 df.index와 df.columns의 속성에 새로운 배열을 할당하는 방식으로 변경
행 인덱스 변경 : DataFrame 객체.index = [새로운 행 인덱스 배열]
열 이름 변경 : DataFrame 객체.columns = [새로운 열 이름 배열]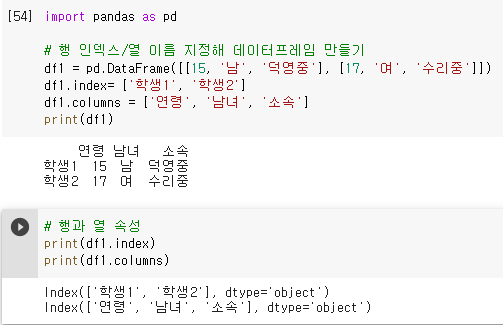
- 데이터프레임에 rename( ) 메소드를 적용하면 행 인덱스 또는 열 이름의 일부를 선택하여 변경할 수 있다.
단, 원본 객체를 직접 수정하는 것이 아니라 새로운 데이터프레임 객체를 반환하는 점에 유의한다. 원본 객체를 변경하려면 inplace=True 옵션을 사용한다.
행 인덱스 변경 : DataFrame 객체.rename(index={기존 인덱스:새 인덱스,---})
열 이름 변경 : DataFrame 객체.rename(columns={기존 이름:새 이름, ---})
🍏 문자열로 저장된 열 이름을 정수형 데이터로 변환 하는 법 🍏
: 그래프 사용 시
df.columns = dfcolumns.map(int)3. 행/열 삭제 .drop( )
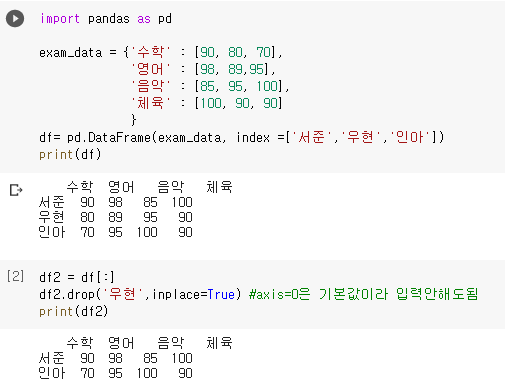
데이터프레임의 행 또는 열을 삭제하는 명령으로 drop( ) 메소드가 있다.
동시에 여러개의 행 또는 열을 삭제하려면 리스트 형태로 입력한다.
단, drop() 메소드는 기존 객체를 변경하지 않고 새로운 객체를 반환하는 점에 유의한다. 따라서 원본 객체를 직접 변경하기 위해서는 inplace=True 옵션을 추가하던지 df=df.drop() 처럼 반환된 객체를 기존 변수에 저장하여 대체해준다.
행 삭제 : DataFrame 객체.drop('행 인덱스' 또는 ['배열'], axis=0)
열 삭제 : DataFrame 객체.drop('열 이름' 또는 ['배열'], axis=1)-
행 삭제하기
: DataFrame 객체.drop('행 인덱스' 또는 ['인덱스1', '인덱스2',--], axis=0)

-
열 삭제하기
: DataFrame 객체.drop('열 이름' 또는 ['열 이름1','열 이름2'.--], axis=1)


4. 행/열 선택 (행만 .loc[' '] .iloc[ ] 사용, 열은 사용X)
-
특정 행 선택하기
: .loc[' '] / .iloc[ ]
💗.loc : 인덱스 이름을 기준으로 행을 선택할 때(index label),범위지정 ['a' : 'c']
💙.iloc : 정수형 위치 인덱스를 사용할 때(integer position),범위지정 [3:7]1) 1개 행만 추출 (행과 열이 바뀜. 이중괄호 사용 후 한번 더 바뀜.)


2) 여러 행 추출!
-
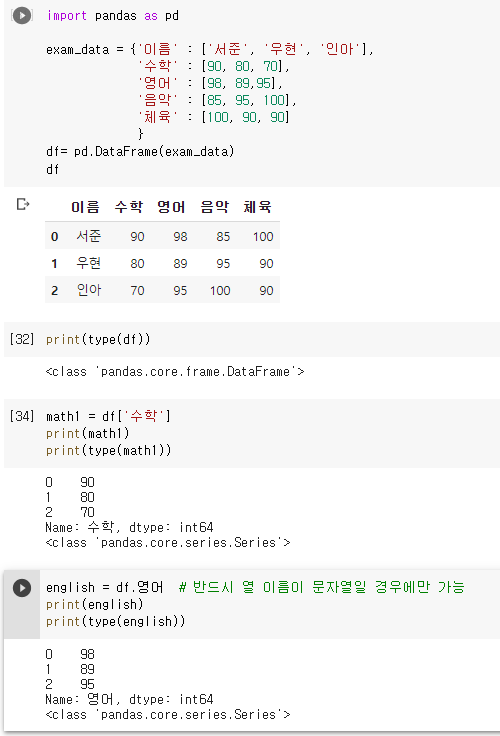
특정 열 선택하기
: df[ '000' ] / df. 000 / df[[ '000' ]]
💗 Series 객체로 반환될 경우df['열이름'] /df.열이름 (한개 열 이름)
💙 DataFrame 을 반환할 경우이중대괄호 [[' ']] (한개 또는 여러개 열 이름)
1) 1개 열만 추출 (2가지 방법) : 선택한 열이 Series 객체로 추출됨
1. df[ '열 이름' ] 2. df.열 이름 (반드시 열 이름이 문자열일 경우만)
2) 1개 이상의 열 추출 : 선택한 열을 DataFrame 으로 반환
이중대괄호 df[[' ',' ',--]] / df[[' ']] (1개 열만 사용해도 DF로 반환함.)

5. 행/열 추가
- 행 추가하기 : .loc[ ] 인덱서 사용.
하나의 데이터 값을 입력하면 행의 모든 원소에 같은 값이 추가되고, 열의 개수에 맞게 배열 형태로 여러개의 값을 입력하면 배열의 순서대로 열 위치에 값이 하나씩 추가된다. 또한 행 벡터 자체가 배열이므로, 기존 행을 복사해서 새로운 행이 그대로 추가할 수도 있다.
행추가 : DataFrame.loc['새로운 행 이름'] = 데이터 값 (또는 배열)
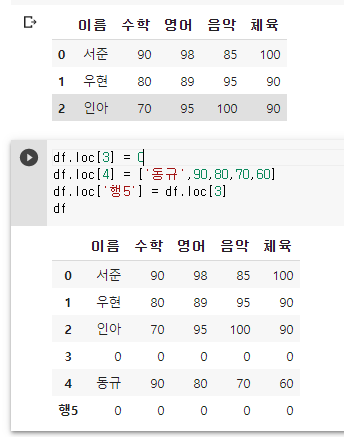
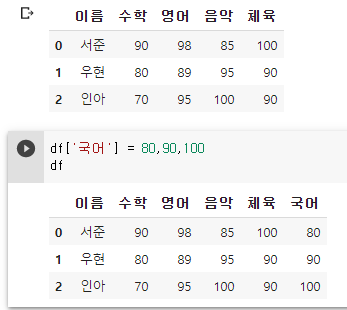
- 열 추가하기
:열 추가 : DataFrame 객체[ '추가하려는 열 이름' ] = 데이터 값
6. 원소 선택
: 데이터프레임의 행 인덱스와 열 이름을 [행, 열] 형식의 2차원 좌표로 입력하여 원소 위치를 지정함.
인덱스 이름 : DataFrame 객체.loc[행 인덱스, 열 이름]
정수 위치 인덱스 : DataFrame 객체.iloc[행 번호, 열 번호]
💗 원소 반환 : 원소가 위치하는 행과 열의 좌표를 입력
💙 Series 객체로 반환 : 1개의 행과 2개 이상의 열 or 2개 이상의 행과 1개의 열
💛 DataFrame 을 반환 : 2개 이상의 행과 2개 이상의 열
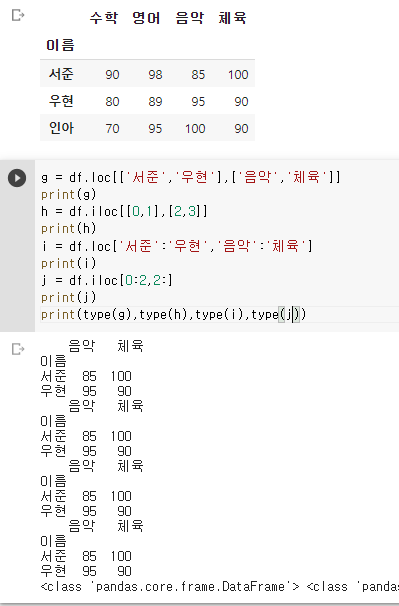
1) 원소 1개 추출
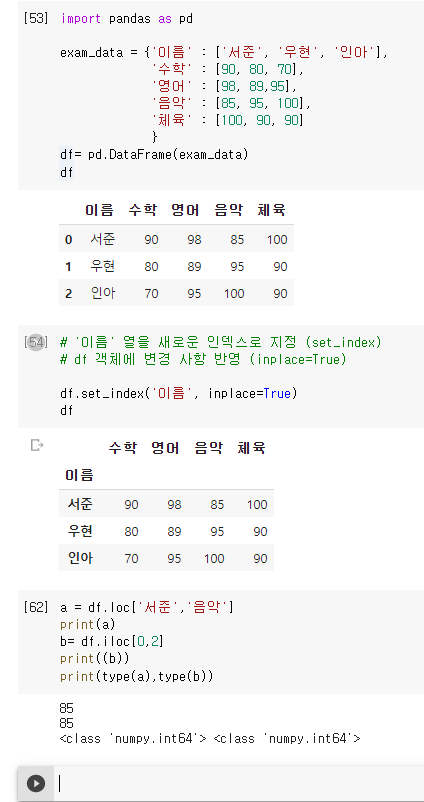
2) 원소 2개 이상 추출 (type = Series)
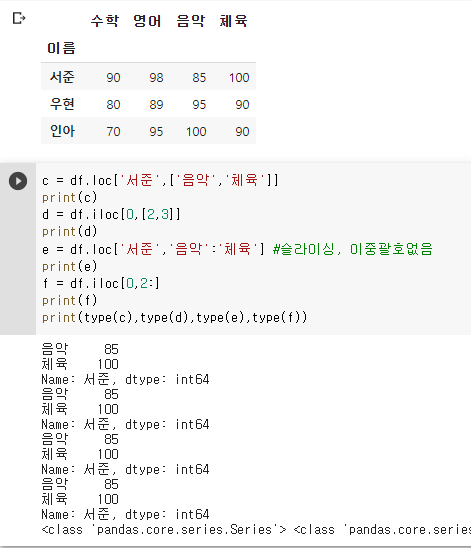
3) 형 인덱스와 열 이름 각각 2개 이상 추출 (type = DataFrame)
7. 원소 값 변경
: 데이터프레임의 특정 원소 1개 또는 여러개를 인덱싱과 슬라이싱 기법으로 선택하고 새로운 데이터 값을 지정해주면 원소 값이 변경된다.
원소 값 변경 : DataFrame 객체의 일부분 또는 원소를 선택 = 새로운 값
-
원소 1개 값 변경
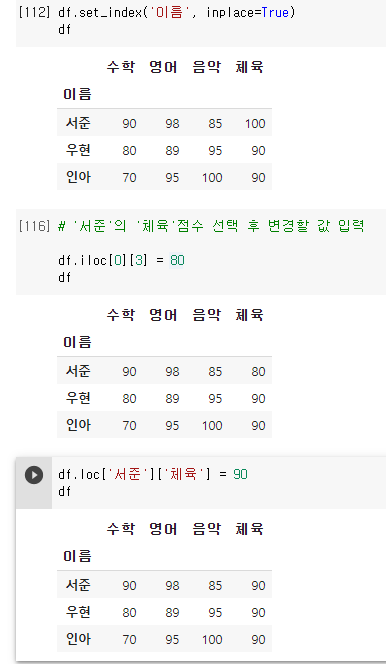
-
원소 여러개 값 변경
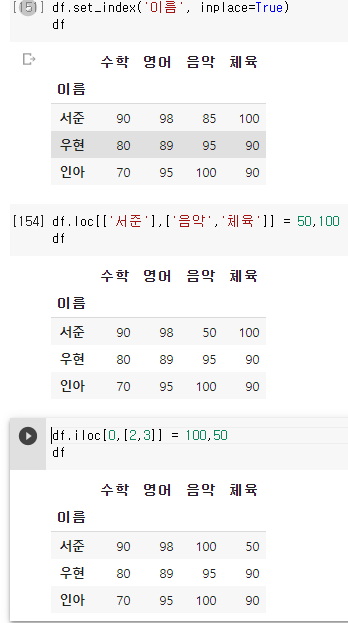
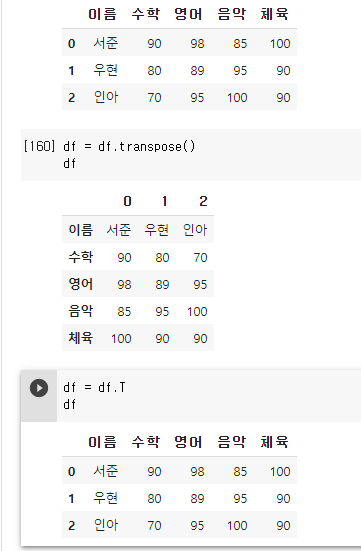
8. 행,열의 위치 바꾸기 .transpose()
: 데이터프레임의 행과 열을 서로 맞바꾸는 방법이다. 선형대수학의 전치행렬과 같은 개념이다. 전치의 결과로 새로운 객체를 반환하므로, 기존 객체를 변경하기 위해서는 df=df.transpose() (메소드)또는 df=df.T(클래스 속성)와 같이 기존 객체에 새로운 객체를 할당해준다.
행,열 바꾸기 : DataFrame 객체.transpose() 또는 DataFrame 객체.T
< 인덱스 활용 >
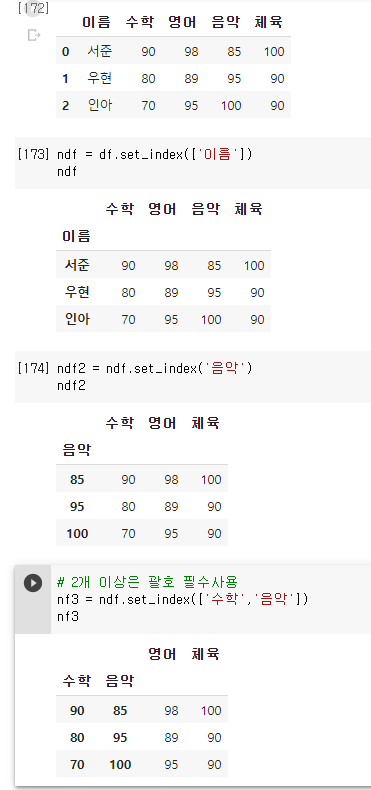
1. 특정 열을 행 인덱스로 설정 .set_index(' ')
: set_index() 메소드를 사용해 데이터프레임의 특정 열을 행 인덱스로 설정한다. 단, 원본 데이터프레임을 바꾸지 않고 새로운 데이터프레임 객체를 반환하는 점에 유의한다.
특정 열을 행 인덱스로 설정 : DataFrame 객체.set_index( ['열 이름' ] 또는 '열 이름')
2. 행 인덱스 재배열 .reindex()
: reindex() 메소드를 사용하면 데이터프레임의 행 인덱스를 새로운 배열로 재지정 할 수 있다. 기존 객체를 변경하지 않고 새로운 데이터프레임 객체를 반환한다.
새로운 배열로 행 인덱스를 재지정 : DataFrame 객체.reindex(새로운 인덱스 배열)


3. 행 인덱스 초기화 .reset_index()
: reset_index() 메소드를 활용해 행 인덱스를 정수형 위치 인덱스로 초기화한다. 이때 기존 행 인덱스는 열로 이동한다. 다른 경우와 마찬가지로 새로운 데이터프레임 객체를 반환한다.
정수형 위치 인데그로 초기화 : DateFrame 객체.reset_index()

4. 행 인덱스를 기준으로 데이터프레임 정렬 .sort_index()
: sort_index() 메소드를 활용해 행 인덱스를 기준으로 데이터프레임의 값을 정렬한다.
ascending=True or False 옵션을 사용해 오름차순 또는 내림차순을 설정한다. 새롭게 정렬된 데이터프레임을 반환한다.
행 인덱스 기준 정렬 : DataFrame 객체.sort_index()

- 특정 열의 데이터 값을 기준으로 정렬하기
열 기준 정렬 : DataFrame 객체.sort_values()

