해당 시리즈는 LG에서 지원하는 LG Aimers의 교육 내용을 정리한 것으로, 모든 출처는 https://www.lgaimers.ai/ 입니다.
Class Activation Map (CAM)
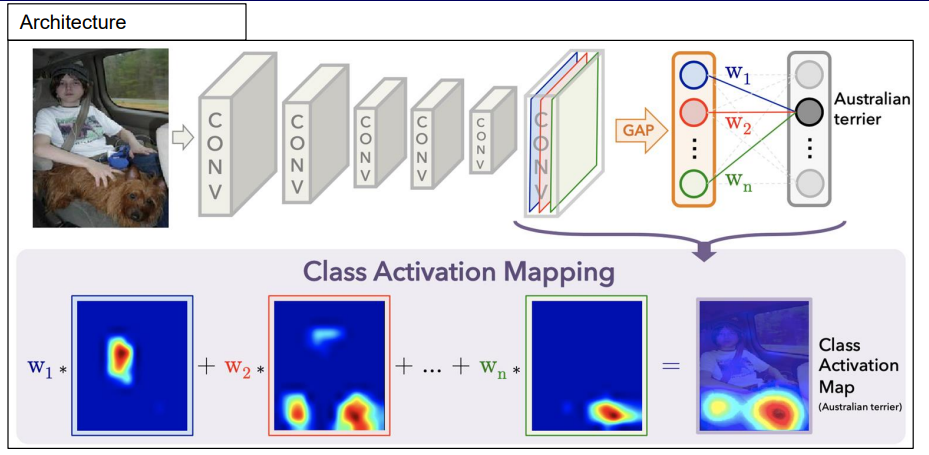
CAM은 saliency map 기반의 설명 방법으로, 그림과 같이 CNN기반의 분류기가 있다고 가정하고, 최종 layer에서 n개의 activation map이 나왔다고할 때 각 map은 색으로 구분하며, 각 activation map의 모든 activation을 평균내는 연산인 GAP layer를 통해 확률을 구한다.
계산된 activation map 별 평균 activation에 최종 softmax output layer를 붙혀 각 클래스마다 평균낸 activation 들을 선형적으로 결합해서 class별 확률을 계산하는 output classifier를 만들어 학습한다.
학습을 진행하면 위 그림에서와 같이 각 클래스에 대한 activation을 결합하여 score를 계산하는 선형계수 W_1 ~ W_N을 얻는다.

이미지가 CNN의 입력으로 들어오면, 이미지에 해당하는 activation들이 최종 activation map으로 나타난다. 이때, 어떤 activation map에 activation이 크게 된다는 것은 map이 주어진 입력과 관련이 많다는 뜻이고, 그것을 결합하는 W가 크다는 것도 최종 분류에 영향을 주는 activation이라는 뜻이므로 그것을 결합하면 입력에 대한 예측을 잘 설명하는 방식이 된다.
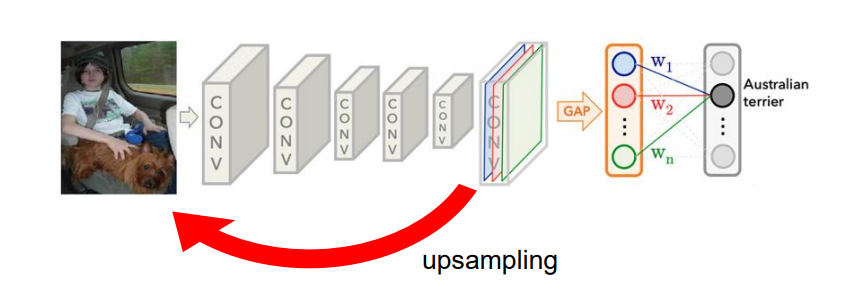
원래 이미지의 해상도에 미치지 못하기 때문에, upsampling을 통해 해상도를 올린다.
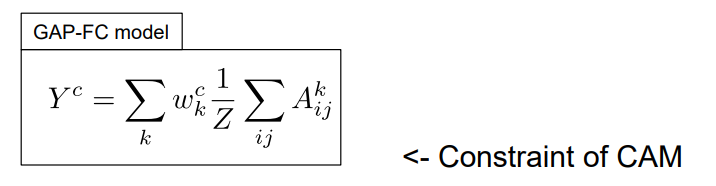
수식에서 A는 activation map을 뜻한다. 각 픽셀 i, j에 대해 모든 activation을 더하고 activation 크기로 나누면 global average pooling을 하는 것이고, 클래스 c에 대한 w들이 각 activation k마다 있어서, global average pooling을 한 activation을 다시 결합하여 최종 점수 y를 계산한다. y^c는 클래스 c에 대한 output score를 뜻한다.
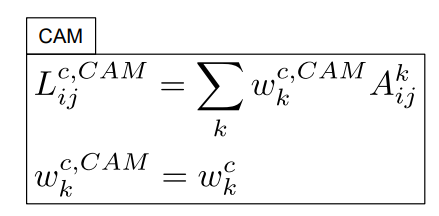
activation map의 CAM 값들의 평균을 내면 특정 클래스에 대한 분류 점수가 된다.
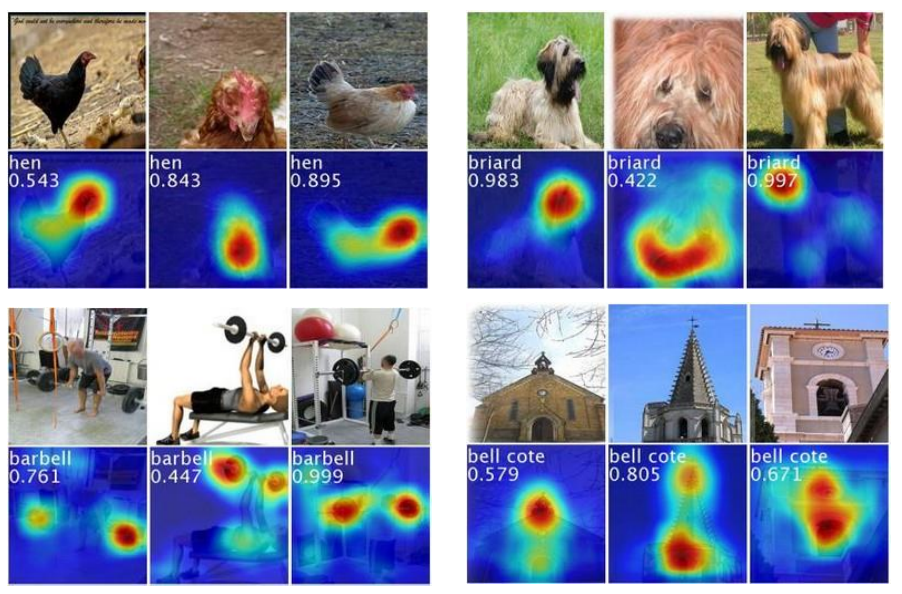
클래스가 같더라도, 매우 다른 입력들이 주어졌을 때 classifier는 제대로 정답을 예측한다. 예측에 대한 설명도 그림 내에서 정답에 해당하는 객체들을 잘 찾아내 보여주고 있다.

CAM은 Object detection이나 semantic segmentation에도 사용하며 weakly supervised learning이다.
CAM은 이미지에서 중요하게 보고있는 object를 정확하게 잡아내는 장점이 있지만, model-specific한 기법이고 global average pooling layer가 달려있는 모델에만 적용가능하다.
하지만 대부분의 모델에는 global average pooling layer가 존재하지 않다. 또한, CAM의 설명은 CNN의 마지막 activation에서만 얻을 수 있어 visualization의 해상도가 떨어진다.
Grad-CAM
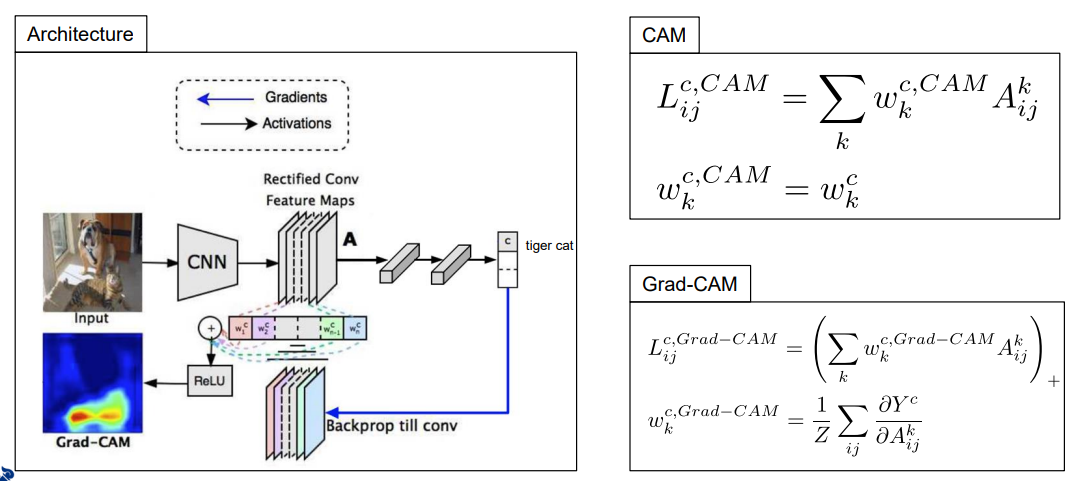
grad-cam은 gradient 정보를 활용해 cam을 확장한 설명방법으로, global average pooling layer가 없어도 적용가능하다.
해당 activation들에서 구한 gradinet를 global average pooling 과정을 거쳐 W 값으로 사용한다.
즉, 어떤 W가 특정모델구조를 가지고 학습된 W를 사용하는 것이 아니라, 어느 activation map의 gradient를 구한 후, 그것의 global average pooling 값으로 W를 적용하는 것이다.
활용하고자 하는 layer의 activation map까지 backpropagation을 진행하여 gradinet를 구하고, gradient를 pooling해서 해당 activation map을 결합하는 W로 사용하여 최종 설명을 구한다.
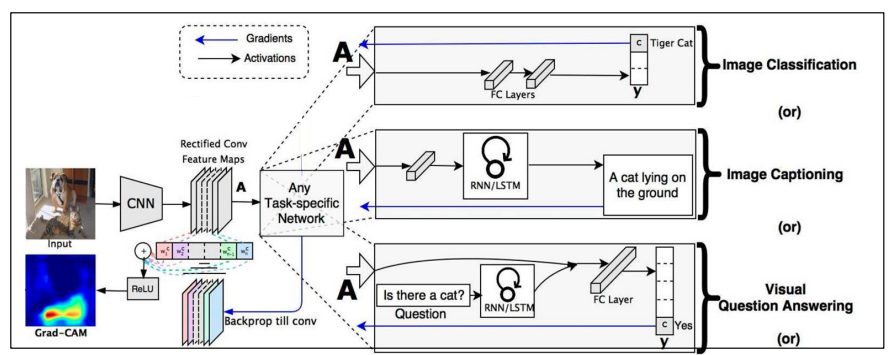
grad-cam은 CAM과 달리 model-agnostci 하여 모델 구조와 관계없이 사용할 수 있는 장점을 가진다.
하지만, activation을 결합하는 w로 평균 gradinet를 사용하는데, 정확하지 않은 경우가 존재하며 gradient가 크다는 것이 해당 activation에 대한 출력 값의 민감도가 크다는 말이지만 그것이 최종결과를 계산하는 데 있어 중요하게 정확히 반영되지 않는 단점이 있다.

좋은 결과를 내는 grad-cam의 예시다.

grad-cam을 이용하면 학습된 모델이 제대로 예측하고 있는지, 모델의 예측에 편향성이 존재하지 않는지를 알 수 있다.
위 그림처럼, 입력사진을 간호사라고 분류했을 때, 만약 그 모델의 예측 출력에 대한 grad-cam을 구해봣을 때 가운데 이미지처럼 여성 및 얼굴이 중요하다고 나올 경우 모델은 성별에 대해 편향되었음을 알 수 있다.
정상적인 예측은 오른쪽 그림과 같이 청진기와 같은 의료도구에 집중되어있어야 한다.
Perturbation-based
perturbation-based 설명 방식은 모델의 정확한 구조나 계수를 모르는 상태에서 모델에 대한 입출력 정보만 가지고 있는 경우에 사용하며 입력데이터를 조금씩 바꾸면서 그에 대한 출력을 보고, 변화에 기반해서 설명한다.
LIME : Local Interpretable Model-agnostic Explanations
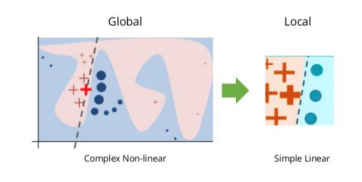
lime은 어떤 classifier가 딥러닝 모델처럼 매우 복잡한 비선형적 특징을 가지고 있더라도 주어진 데이터 포인터들이 local하게는 다 선형적인 모델로 근사화가 가능하다라는 아이디어에서 출발해 주어진 데이터를 조금씩 교란해 가면서, 교란된 입력 데이터를 모델에 여러번 통과시켜 나오는 출력을 보고 입출력 쌍들을 간단한 선형모델로 근사함으로써 설명을 얻어내는 방법이다.
그림과 같이 복잡한 decision boundary를 가진 모델이더라도 해당 포인트 근처에서는 선형 모델로 근사할 수 있고, 이를 이용해 설명한다.

lime의 예로, 개구리 이미지가 있을 때 이미지를 super pixel로 segmetation 해주고 오른쪽과 같은 interpretable component를 얻는다.
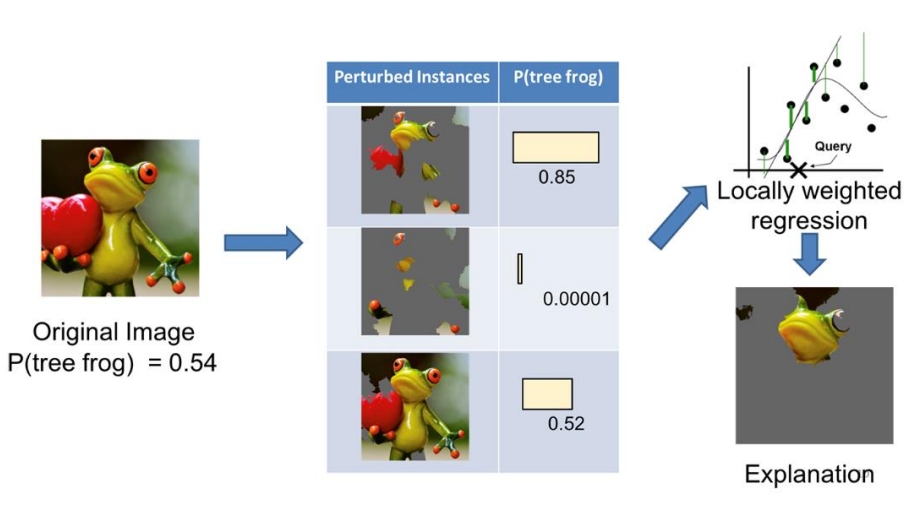
perturb된 이미지와 출력 확률의 쌍을 이용하여 각 super pixel들을 잘 결합하는 선형계수들을 잘 학습할 수 있고, 계수를 이용해서 super pixel을 다시 결합했을 때 나오는 이미지가 최종 설명이 된다.
lime은 블랙박스 설명 방법이므로, 딥러닝 모델을 포함하여 주어진 입력과 그에 대한 출력을 얻을 수 있는 모델에 대해서는 모두 적용가능한 장점이 있다.
하지만, 주어진 모델을 여러번 evaluation 해야하므로, 딥러닝의 경우 forward-propagation을 많이 수행하며 계산복잡도가 매우 복잡해지는 문제가 발생한다. 이는 모델의 구조를 알지 못하는 black-box 방법의 한계점이다.

또한, 실제 모델이 local하게도 비선형적인 특징을 가지고 있고, 선형함수로 근사화가 안되는 경우에 설명이 잘 되지 않는 단점이 존재하며 이미지 속 객체가 아닌 전체의 분류를 하는 경우에도 lime은 잘 동작하지 못한다.
RISE : Randomized Input Sampling for Explanation
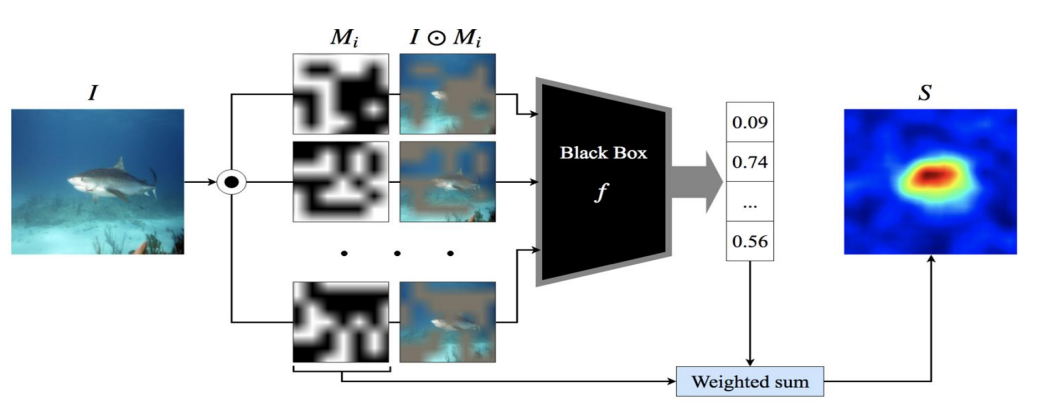
rise는 lime과 비슷하게 입력을 여러번 perturb해서 설명을 구하는 방법이다.
이는 random mask를 만들어서 mask를 씌운 입력이 모델을 통과했을 때 해당 클래스에 대한 예측 확률이 얼마나 떨어지는지를 보고 설명하는 방식으로, 여러 개의 random masking이 되어있는 입력에 대한 출력 값을 구하고, 이를 이용해서 mask에 가중치를 부여한 뒤, 평균을 내어 설명을 구한다.
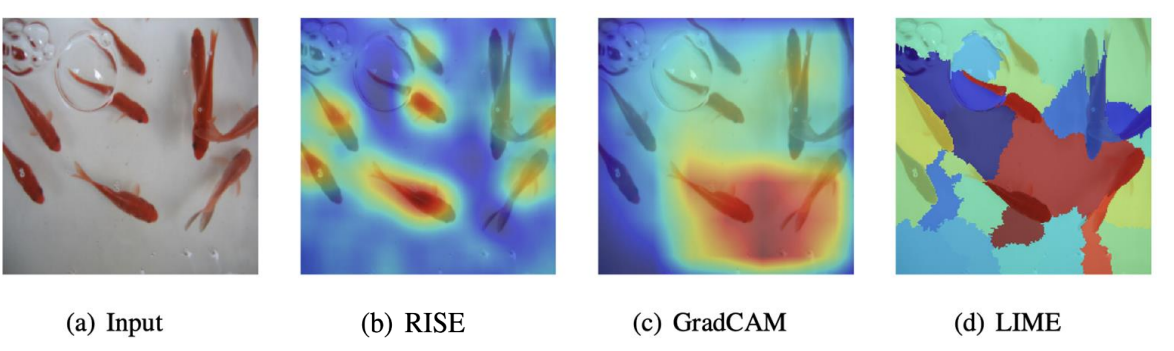
이는 때로 white-box보다 좋은 성능을 내는 장점이 있지만, lime 보다도 매우 높은 계산 복잡도를 요구하는 점과 random mask 생성 횟수에 따라 설명이 달라지는 noise가 존재하는 단점이 있다.
Influence function-based
influence function-based 설명 방법은 주어진 test img에 대해 모델이 이미지를 분류하고 분류 결과에 대한 설명을 해당 test img에서 highlight 하는 방식이다.
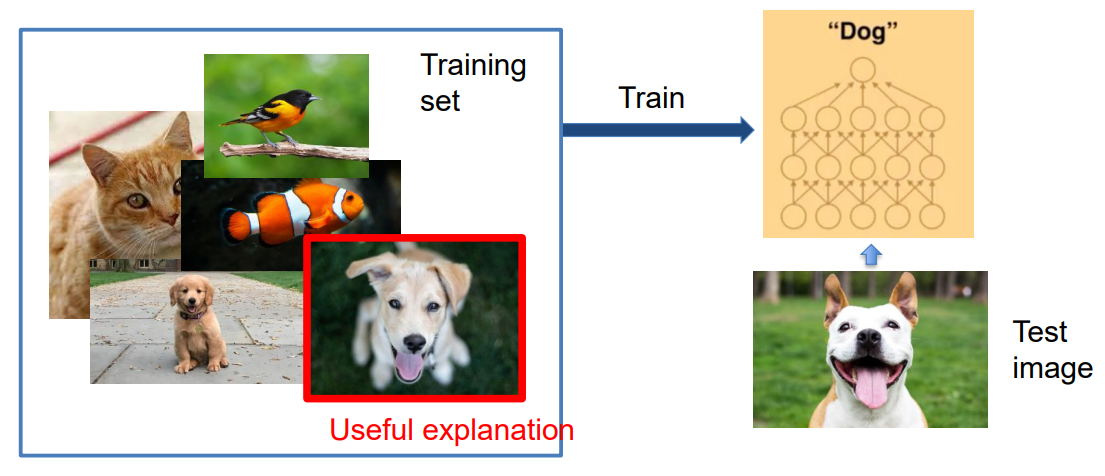
이는 주어진 모델이 어떤 학습 데이터셋으로부터 학습한 것이므로 데이터셋에 있는 학습 이미지들의 함수라고 볼 수 있고, 각 테스트 이미지를 분류하는데 가장 큰 영향을 미친 트레이닝 이미지가 해당 분류에 대한 설명이라고 생각한다.
위 그림 속 오른쪽에 나와있는 테스트 이미지를 "DOG" 라고 분류하는 데 가장 큰 영향을 준 학습 이미지는 왼쪽 빨간색 박스의 강아지 그림이다.
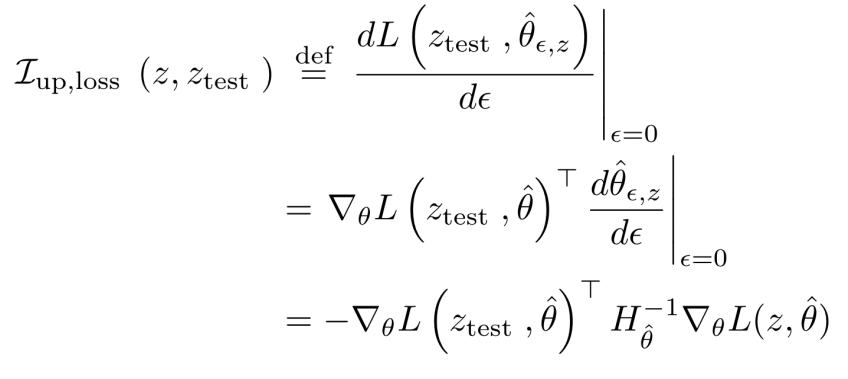
위 수식은 학습 이미지 없이 모델을 학습시켰을 때 해당 테스트 이미지의 분류 값이 얼만큼 변할 것인지를 근사하는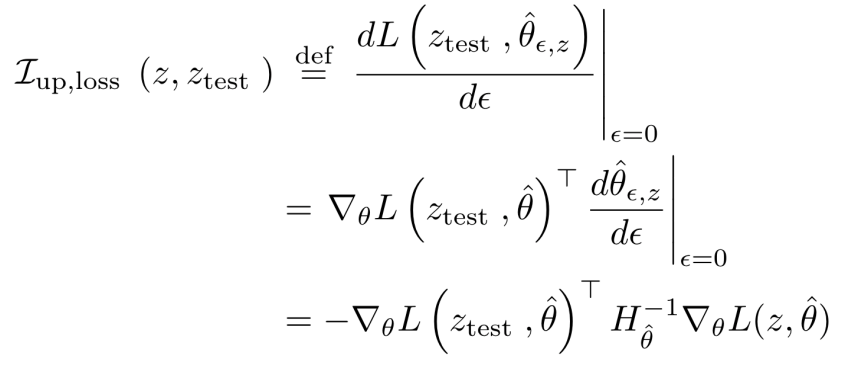
함수를 나타낸다. 함수 값을 가지고 각 학습 이미지마다 영향력을 계산하여 영향력이 가장 큰 이미지를 설명으로 제공하는 방식이다.
