해당 시리즈는 LG에서 지원하는 LG Aimers의 교육 내용을 정리한 것으로, 모든 출처는 https://www.lgaimers.ai/ 입니다.
오늘부터는 새로운 주제인, 설명가능한 AI, XAI에 대해 알아본다.
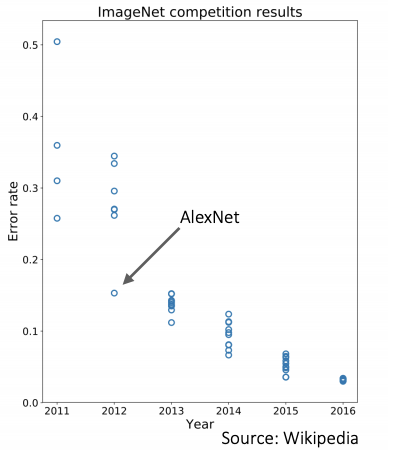
최근, 인공지능의 성능이 대단히 발전함에 따라 매년 에러가 절반씩 줄어드는 형상을 확인할 수 있다.
하지만 deep learning 모델이 대용량 학습 데이터로부터 학습하는 모델구조로 인해 점점 복잡해지고, 이해하기 어려운 모델이 만들어지고 있다.
단순신경망, ResNet, DenseNet, transformer 등 시간이 지남에 따라 매우 복잡해지고 있는 모습이다.
결론적으로, 우리는 이러한 모델이 어떻게 잘 동작하는지 잘 알지못하고, 입력을 넣으면 출력이 튀어나오는 마치 하나의 블랙박스처럼 동작하게끔한다. 이런 점은, 모델의 예측결과가 사람에게 직접 영향을 미칠 수 있는 경우 문제가 생길 수 있다.

- 이미지 인식 기반 자율주행자동차가 사고를 냈을 때
- 의료영상 기반 질병진단
- 인공지능 기반 인터뷰
이러한 문제점을 해결하기 위해, 단순히 인공지능의 예측결과만 사용하지 않고, 왜 모델이 이러한 예측과 결정을 내렸는지를 설명할 수 있어야 한다. 만약 설명하지 못한다면, 해당 모델을 적용하는 데 법적, 사회적 제약이 생길 수 있다.
인공지능 모델은 이미지 인식이나 이미지 라벨링에 있어 특정 성별이나 인종에 편항적인 결과를 내놓을 때가 있다.

위 그림처럼 인공지능 모델이 사람을 고릴라라고 판단하거나, 아래 그림처럼 눈 뜨고 있는 동양인의 얼굴을 눈 감고 있는 것으로 인식하는 것처럼 인종이나 성별과 관련하여 잘못된 예측을 내놓는 경우가 많다.

편향된 bias를 고치기 위해서 어떻게 해야 할지 등을 알아내기 위해 모델의 결과를 설명할 수 있는 XAI가 필요하다.
Example of Explainable AI
Pascal VOC는 이미지 분류 연구를 위해 벤치마크로 널리 쓰인 데이터셋이다. 아래 그림은 독일의 한 연구진이 XAI 기법을 Pascal VOC 데이터 셋으로 훈련된 classifier에 적용해본 결과다.
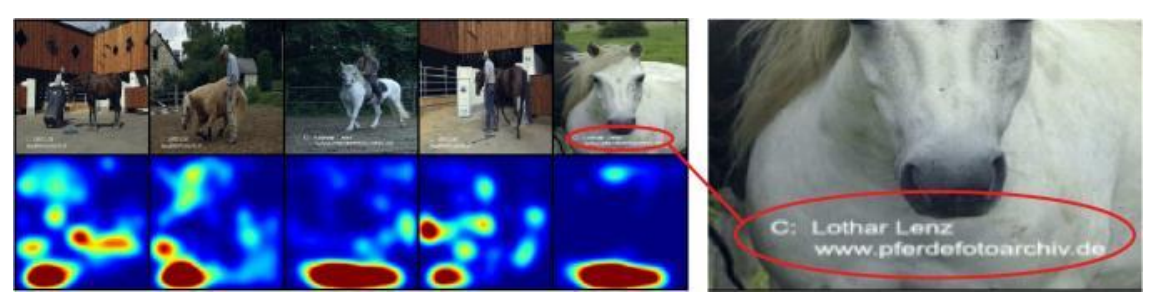
XAI 기법은 과연 이 모델이 이미지의 어느 부분을 보고 해당 사진을 말이라고 판단했는지 빨간색 하이라이트로 표현해주는 방식인데, 결과를 보면 말에 해당하는 부분이 아니라 아래쪽 부분으로 판단했음을 알 수 있다.
결론적으로, 데이터셋에 있는 모든 말 사진에는 text watermark가 있었고, 해당 데이터를 학습한 모델은 실제 말 사진이 아닌, text watermark에 기반하여 말이라고 분류했다.
XAI 기법을 사용할 경우 위 처럼 모델이나 데이터셋의 오류를 색출할 수 있고, 모델이 얼마나 편향되었는지를 확인할 수 있다.
COMPAS는 미국 교도소에 수감되어 있는 사람 중, 어떤 사람을 집행유예로 풀어줬을 때 다시 범죄를 저질러서 교도소에 돌아올 확률이 있는지를 예측하는 시스템이다.
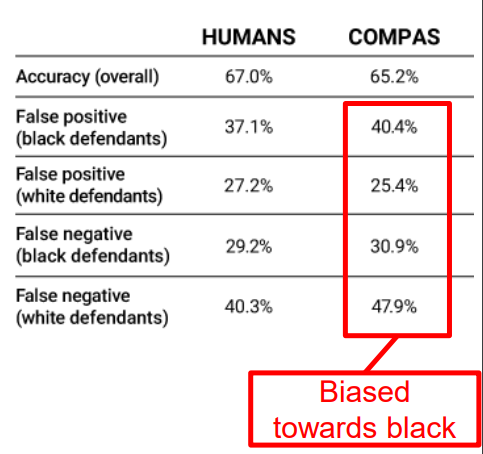
위 그림은 인간과 COMPAS 시스템을 정확도 측면에서 비교한 것인데, 전체 평균의 관점에서 보면, 비슷해보일 수 있지만 실제로 세부사항을 따져 들어가보면
- 흑인이 범죄를 저지르지 않았지만 저질렀다고 판단하는
FP - 백인이 범죄를 저질렀지만 저지르지 않았다고 판단하는
FN
위 두 값이 인간과는 달리 흑인이 불리하게 편향되어 있음을 알 수 있다.

자율주행자동차와 관련해서도, 만약 자율주행차가 사고를 냈을 때, 어떤 근거로 내린 어떤 판단이 사고를 유발했는지 추적하는 과정은 매우 중요하다.
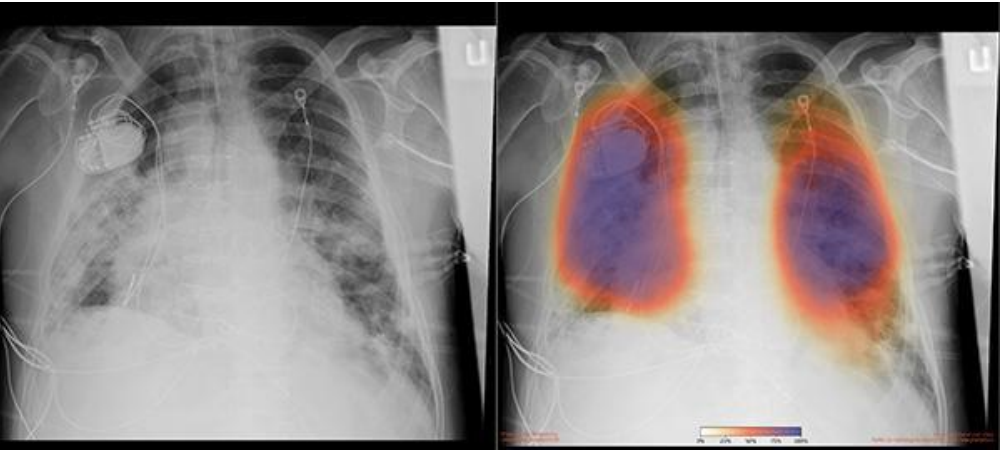
위 그림처럼 X-RAY를 이용해 질병을 분류하는 모델에서 왜 알고리즘이 이런 예측 결과를 냈는지 설명을 보고, 알고리즘을 신뢰할 것인지에 대한 여부를 결정해야 한다.
Explainability / Interpretability
설명에 대해서도 많은 정의가 존재한다.
- 사람이 그 이유를 이해할 수 있게 해주는 것
- 모델의 결과를 예측할 수 있게 해주는 것
- 이유를 설명할 수 있게 해주는 것
하지만, 인공지능 모델과 관련하여 정확이 어떻게 하는 것이, 설명가능성을 높이는 것인지에 대한 구체적인 답을 알기는 어렵다.
XAI는 다음과 같이 정의한다.
사람이 모델을 사용할 때, 그 동작을 이해하고 신뢰할 수 있게 해주는 기계학습기술
이런 XAI는 주로 시각화를 통해 모델의 예측 결과에 중요한 영향을 미친 특징이나 데이터를 하이라이트해서 보여준다.
XAI는 몇 가지 세부 속성이 존재한다.
LocalvsGlobal
Local: 주어진 특정 데이터에 대한 예측결과를 개별적으로 설명하려는 방법Global: 개별 데이터에 대한 결과를 따로따로 설명하지 않고, 전체 데이터셋에서 모델의 전반적인 행동을 설명하고자 하는 방법
White-boxvsBlack-box
White-box: 모델의 내부 구조를 정확하게 알고 있는 상황에서 설명을 시도하는 방법Black-box: 모델의 내부 구조를 전혀 모르는 상태에서 단순히 모델의 입력과 출력을 가지고 설명을 시도
IntrinsicvsPost-hoc
Intrinsic: 모델의 복잡도를 훈련하기 이전부터 설명하기 용이하도록 제안한 뒤, 학습을 진행하여 학습된 모델을 통해 설명하는 방법Post-hoc: 모델의 학습이 끝난 후, 이 방법을 적용해서 모델의 행동을 설명하는 방법
Model-specificvsModel-agnostic
Model-specific: 특정 모델 구조에만 적용 가능Model-agnostic: 모델의 구조와 관계없이 어느 모델에도 항상 적용
Linear model, Simple Decision Tree
Global,White-box,Intrinsic,Model-sperific
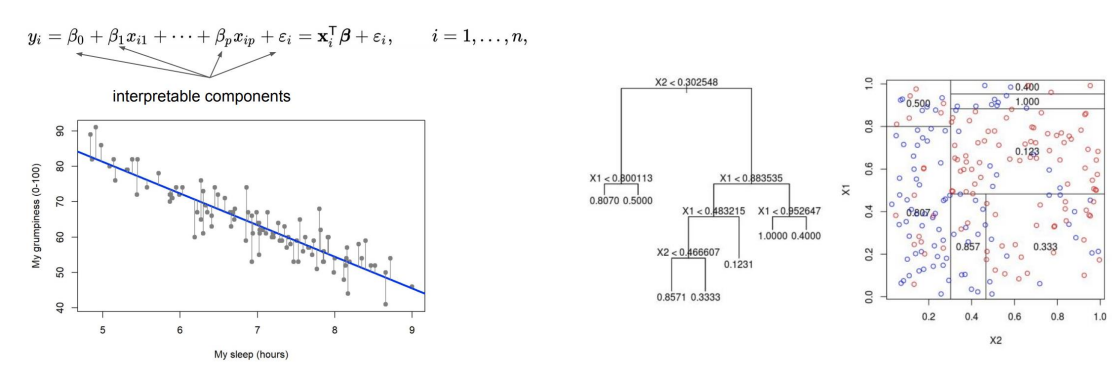
- 주어진 데이터에 대한 설명이 아니라, 데이터 전체로부터 학습된 모델을 설명하는 것으로
Global - 모델의 정확한 구조를 알아야하기 때문에
white-box - 학습되는 모델 자체가 간단하고 직접적인 설명을 만들어내는 모델이라서
intrinsic - 특정 모델 구조에만 적용할 수 있기에
Model-specific
linear의 예로, 학습하고 난 뒤 얻어지는 선형계수가 모델의 설명으로 직접 작용한다. 각 X들이 선형적으로 조합되어 예측 값 Y를 나타내는데, 선형계수가 클수록 특징들이 예측에 작용하는 정도가 크다고 볼 수 있다.
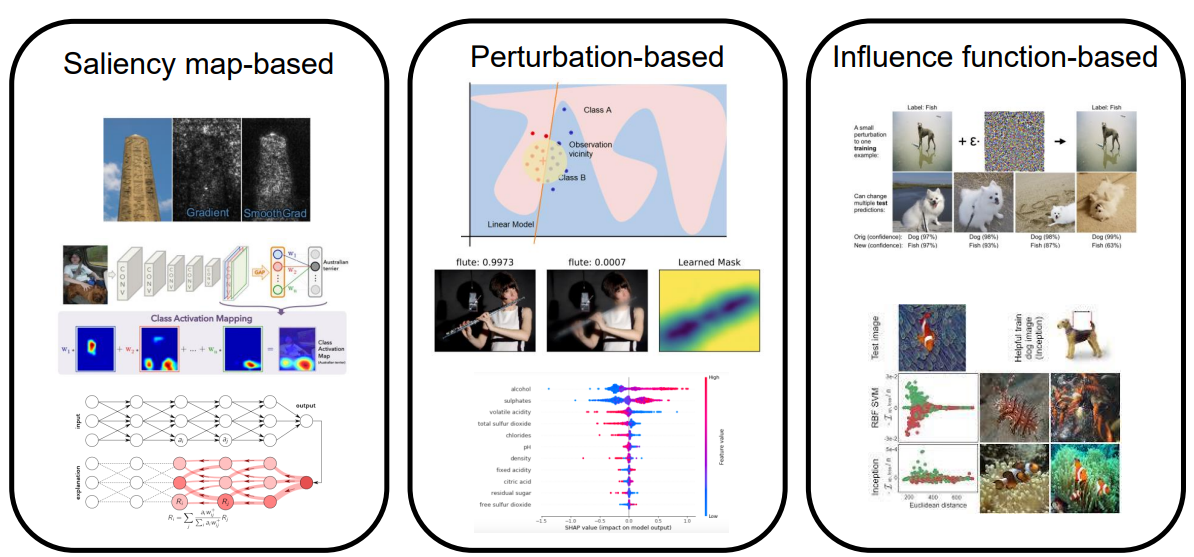
Grad-CAM
Local,White-box,Post-hoc,Model-agnostic

- 주어진 개별이미지마다 예측 결과를 설명할 수 있기에
Local - 모델의 정확한 구조와 계수들을 모두 알아야 구할 수 있는 설명이기에
White-box - 모델이 학습이 끝난 후 적용해서 설명하는
Post-hoc - 딥러닝 모델의 구조와 상관없이 항상 적용할 수 있는 문제이기 때문에
Model-agnostic
아래 기법들은 하나의 이미지 샘플이 모델의 입력으로 들어가게 되면 샘플에 대한 예측결과의 설명을 히트맵과 같이 이미지 중에서 중요하게 작용한 부분을 하이라이트해서 보여줌으로써 설명을 제공하는 방법들이다.
입력에 대한 모델의 gradient로 설명을 제공한다.
Simple Gradient Method
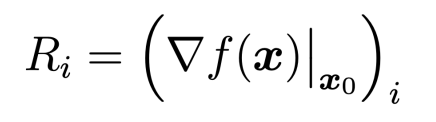
위 수식에서 X0라는 이미지가 f()라는 함수로 들어가서 출력이 계산되었을 때, 출력 값의 입력 이미지의 각 픽셀에 대한 gradient를 구해서 그 값을 각 픽셀의 중요도로 해석한다.
gradinet는 pixel의 값이 조금 바뀌었을 때 이 함수의 출력 값이 얼마나 빨리 변하는지를 구하는 값이기 때문에, gradient가 크다면 해당 픽셀이 출력 값에 영향을 많이 미치는 것이므로 중요하다고 할 수 있다.
back-propagation 방식으로 효율적이고 쉽게 계산할 수 있기 때문에, 구현상으로도 간단하다.

위 그림에서 세 이미지에 대해 모델은 정확히 예측했고, 그에 대한 설명을 보면 정답 클래스에 해당하는 객체들을 잘 구분해내고 있다.
간단한 gradient에 기반한 설명 방법은 계산하기가 아주 쉬운 장점을 가지며, 어느정도 정확한 설명을 만들어낼 수 있음을 보여준다. 하지만, 이렇게 구한 설명들이 매우 Noisy할 수 있다.
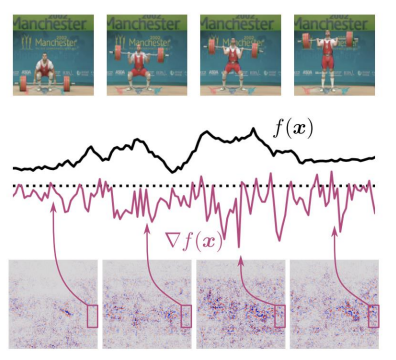
동일한 예측 결과를 가지고 있지만 조금씩 변경된 이미지에서, 각 이미지에 대한 설명은 gradient가 높아져 많이 다르게 나타남을 알 수 있다.
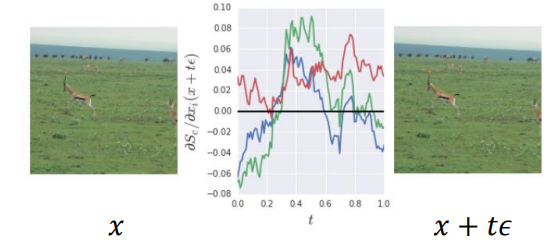
위 그림에서도, 이미지 X에 아주 작은 noise를 섞었을 때 입력 gradient가 매우 요동침을 알 수 있다.
SmoothGrad
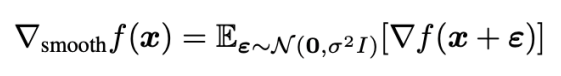
smoothgrad는 X라는 이미지가 주어졌을 때 작은 독립적인 Gaussian Noise Epsilon을 섞어준 뒤, noise가 섞인 이미지의 입력 gradient를 구하는 과정 여러번 수행하여 얻은 gradient의 평균으로 설명을 제시한다.
위 과정을 대략 50번정도 반복하여 추출했으며, noisy한 gradient를 많이 제거하고 평균 gradient만을 남겨 더 깨끗한 설명을 제공할 수 있도록 한다.
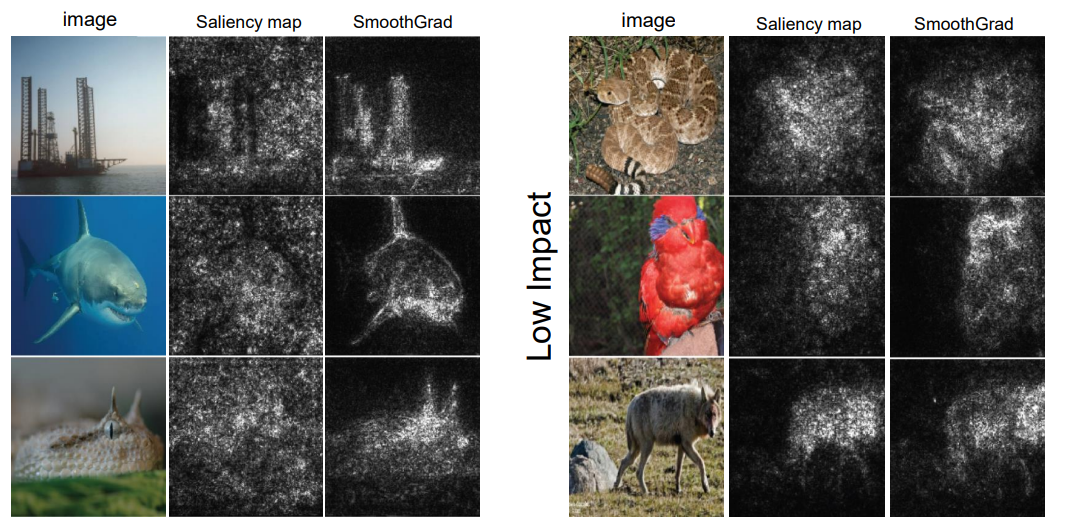
매우 좋은 성능을 보임을 알 수 있고, 배경이 균일한 경우에 더 깨끗하게 smoothgrad가 더 잘 설명한다.
smoothgrad는 간단한 평균을 구하는 과정을 통해 깨끗한 설명을 생성해낼 수 있는 장점이 있고, 간단한 gradient 방법만이 아닌, 대부분의 saliency-map 기반 방법들도 동일하게 적용이 가능하다.
하지만, nosie를 섞어주고 얻는 gradient를 평균내는 과정에서 noise를 섞어주는 횟수만큼 모델의
forward-backward propagation을 진행해야 하기에 매우 높은 계산 복잡도를 갖는 단점이 있다.
