
전 글에 이어서 python에서 OpenAI Library를 활용하는 환경 구축과 파인튜닝에 대해 정리하겠다.
OpenAI Key 발급
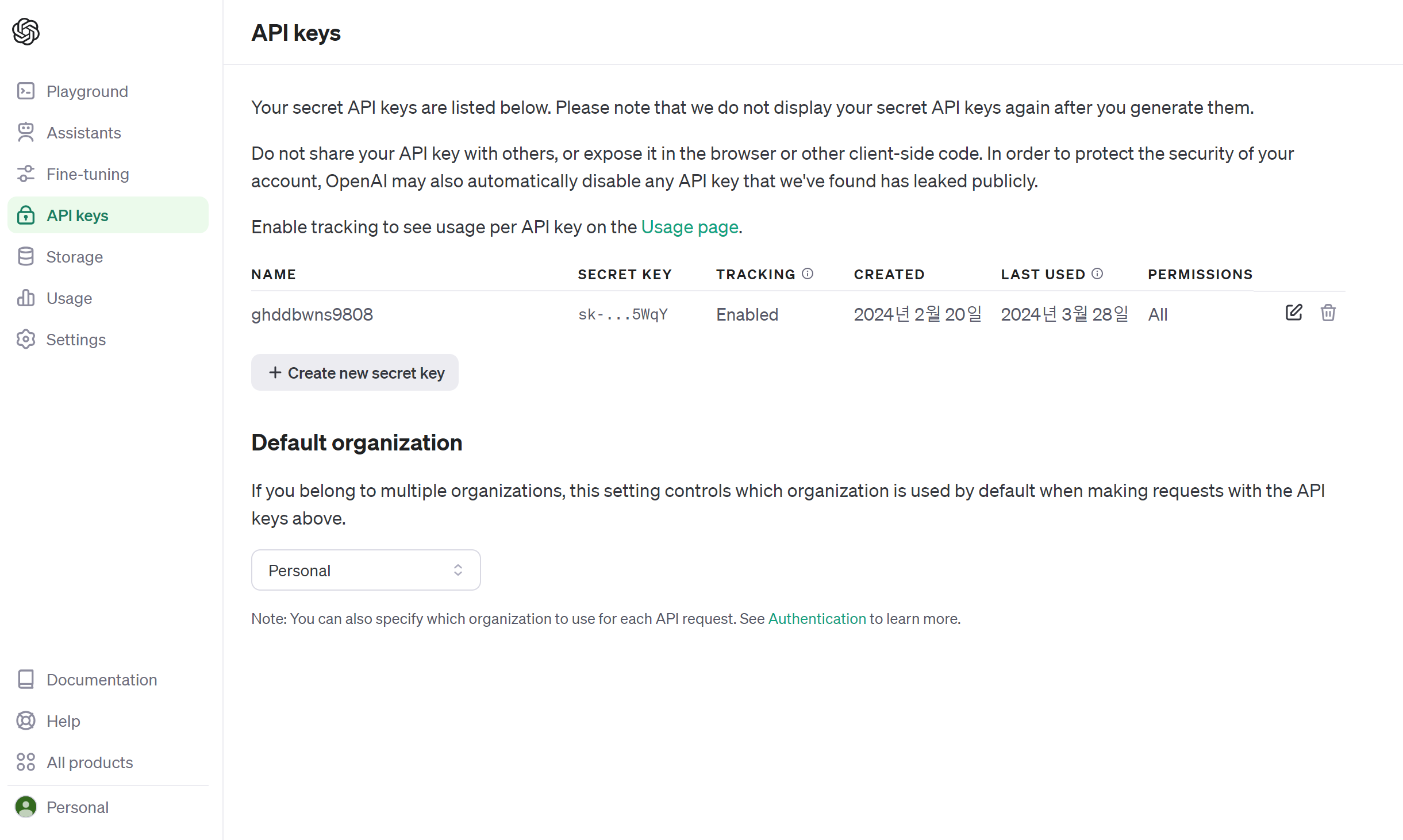
+ Create new secret key를 통해 api key를 발급 받는다.
이때 발급된 key는 다시 안 알려주니 꼭 어딘가에 저장하자.
Library Install
- pip install openai
- pip install pathlib
- pip install pydantic-settings
파인튜닝
튜토리얼이 잘 나와있다.
- 튜토리얼 코드
from openai import OpenAI
client = OpenAI()
file = client.files.create(
file=open("marv.jsonl", "rb"),
purpose="fine-tune"
)
client.fine_tuning.jobs.create(
training_file=file.id,
model="gpt-3.5-turbo"
)- 내 코드
데이터 로드
train_data와 validation_data를 각각 만들어준다.
업로드에 성공하면 .id로 파일의 id를 얻을 수 있다.
client = OpenAI(
api_key="OPENAI_API_KEY"
)
train_data_file = client.files.create(
file=Path("train_data.jsonl"),
purpose="fine-tune",
)
validation_data_file = client.files.create(
file=Path("validation_data.jsonl"),
purpose="fine-tune",
)파인튜닝
try, exeption으로 OpenAI API에서 발생할 수 있는 Exception을 핸들링 했다.
def fine_tune(train_file_id, validation_file_id):
try:
# 파인 튜닝 작업을 생성하고 결과를 저장합니다.
fine_tune_job = client.fine_tuning.jobs.create(
model="gpt-3.5-turbo",
training_file=train_file_id,
validation_file = validation_file_id
)
# 생성된 파인 튜닝 작업의 ID를 사용하여 상태를 검색합니다.
job_id = fine_tune_job.id # 작업 ID를 얻습니다.
print(f"Fine-tune job ID: {job_id}") # 작업 ID를 출력합니다.
# 작업 ID를 사용하여 파인 튜닝 작업의 상태를 검색합니다.
job_status = client.fine_tuning.jobs.retrieve(job_id)
print(job_status) # 작업 상태를 출력합니다.
except openai.APIConnectionError as e:
print("The server could not be reached")
print(e.__cause__)
except openai.RateLimitError as e:
print("A 429 status code was received; we should back off a bit.")
except openai.APIStatusError as e:
print("Another non-200-range status code was received")
print(e.status_code)
print(e.response)KEY 안전하게 보관하기
위의 코드처럼 OPENAI_API_KEY를 하드코딩하면 보안상의 위험이 있다. 특히 요청 token수로 과금을 하는 OpenAI에서 Key가 탈취 당한다면... 아주 슬퍼질 수 있다.
Key를 안전하게 관리하기 위해 pydantic-settings를 사용한다.
우선 .env 파일을 만든다.
OPENAI_API_KEY = "여기에 Key를 입력하세요"이후 main.py 파일에서 다음과 같은 코드를 추가한다.
from pydantic_settings import BaseSettings
class Settings(BaseSettings):
openai_api_key: str
class Config:
env_file = ".env"
env_file_encoding = "utf-8"
settings = Settings()이후 settings.openai_api_key의 형태로 코드에서 사용할 수 있습니다.
전체 코드
import os
from openai import OpenAI
from pathlib import Path
import openai
from pydantic_settings import BaseSettings
class Settings(BaseSettings):
openai_api_key: str
class Config:
env_file = ".env"
env_file_encoding = "utf-8"
settings = Settings()
def fine_tune(train_file_id, validation_file_id):
try:
# 파인 튜닝 작업을 생성하고 결과를 저장합니다.
fine_tune_job = client.fine_tuning.jobs.create(
model="gpt-3.5-turbo",
training_file=train_file_id,
validation_file = validation_file_id
)
# 생성된 파인 튜닝 작업의 ID를 사용하여 상태를 검색합니다.
job_id = fine_tune_job.id # 작업 ID를 얻습니다.
print(f"Fine-tune job ID: {job_id}") # 작업 ID를 출력합니다.
# 작업 ID를 사용하여 파인 튜닝 작업의 상태를 검색합니다.
job_status = client.fine_tuning.jobs.retrieve(job_id)
print(job_status) # 작업 상태를 출력합니다.
except openai.APIConnectionError as e:
print("The server could not be reached")
print(e.__cause__)
except openai.RateLimitError as e:
print("A 429 status code was received; we should back off a bit.")
except openai.APIStatusError as e:
print("Another non-200-range status code was received")
print(e.status_code)
print(e.response)
client = OpenAI(
api_key = settings.openai_api_key,
)
train_data_file = client.files.create(
file=Path("train_data.jsonl"),
purpose="fine-tune",
)
validation_data_file = client.files.create(
file=Path("validation_data.jsonl"),
purpose="fine-tune",
)
print(f"File ID: {train_data_file.id}")
print(f"File ID: {validation_data_file.id}")
fine_tune(train_data_file.id, validation_data_file.id)
실행 결과
File ID: file-u...v
File ID: file-0...h
Fine-tune job ID: ftjob-yV...YO
FineTuningJob(id='ftjob-yV...YO', created_at=1..2, error=Error(code=None, message=None, param=None, error=None), fine_tuned_model=None, finished_at=None, hyperparameters=Hyperparameters(n_epochs='auto', batch_size='auto', learning_rate_multiplier='auto'), model='gpt-3.5-turbo-0125', object='fine_tuning.job', organization_id='org-xs...aV', result_files=[], status='validating_files', trained_tokens=None, training_file='file-u...v', validation_file='file-0...h', user_provided_suffix=None)1번 2번줄에는 업로드된 train_data_file과 validation_data_file의 id가 출력된다.
3번 줄에는 생성된 fine_tune_job의 id가 출력된다.
4번 줄에는 3번줄의 작업 id로 검색한 작업의 현재 상태가 출력된다.
status=validating_files를 보면 현재 데이터셋의 유효성을 검사하고 있음을 알 수 있다.
또한 hyperparameters=Hyperparameters(n_epochs='auto', batch_size='auto', learning_rate_multiplier='auto')을 통해 epoch, batch_size, learing_rate를 조정할 수 있다는 것을 알 수 있다. 자세한 사용법은 공식문서 에서 확인하자
이것을 OpenAI 사이트에서 GUI 환경에서 확인할 수 있다.

이 작업은 테스트용으로 10개의 데이터만 사용해서 돌려본 결과 화면이다.
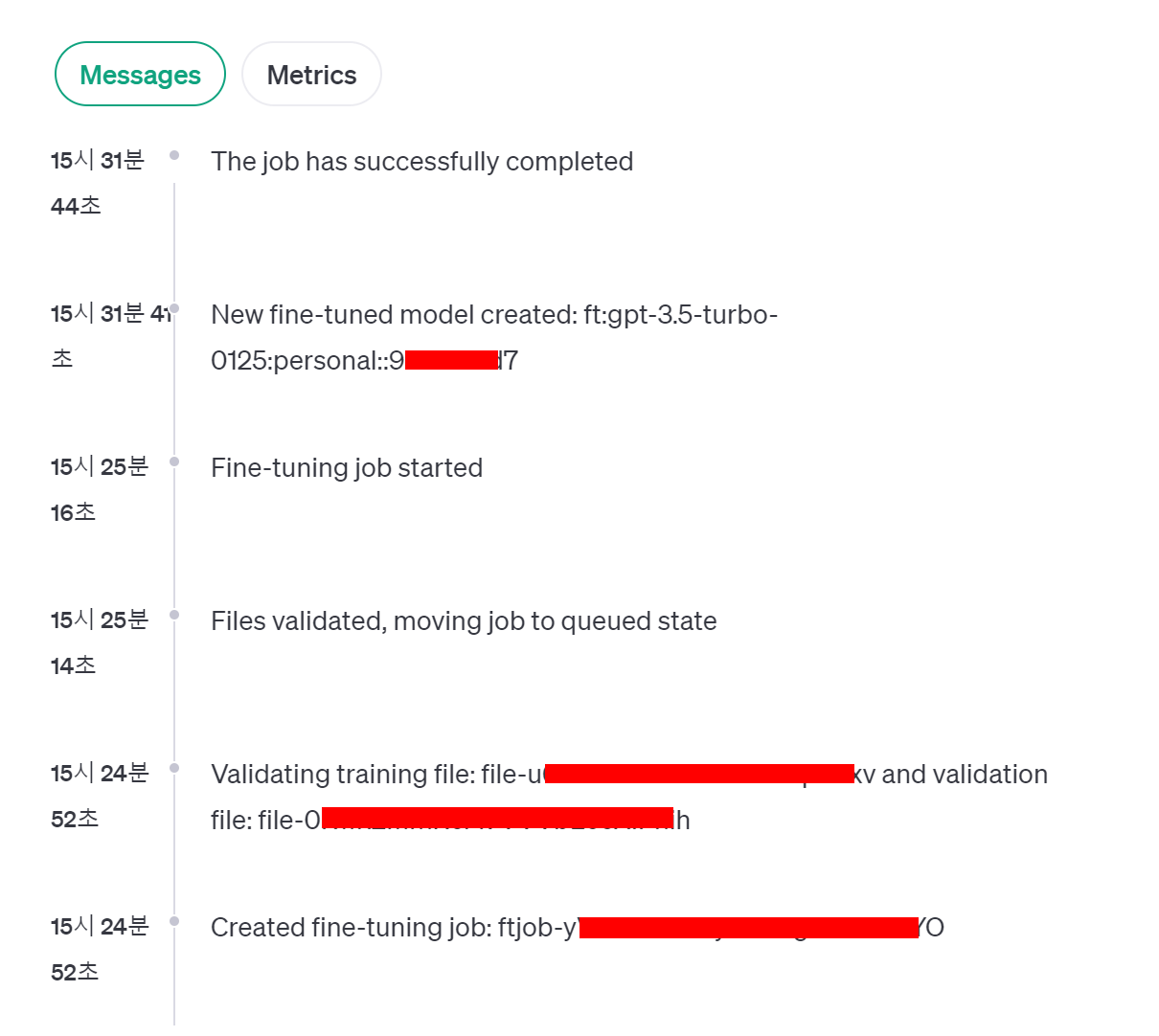
작업 생성 ➡ 파일 검증 ➡ 작업 queue로 이동 ➡ 작업 시작 ➡ 모델 생성 ➡ 작업 완료
의 순서로 파인튜닝이 완료된다.
학습 결과
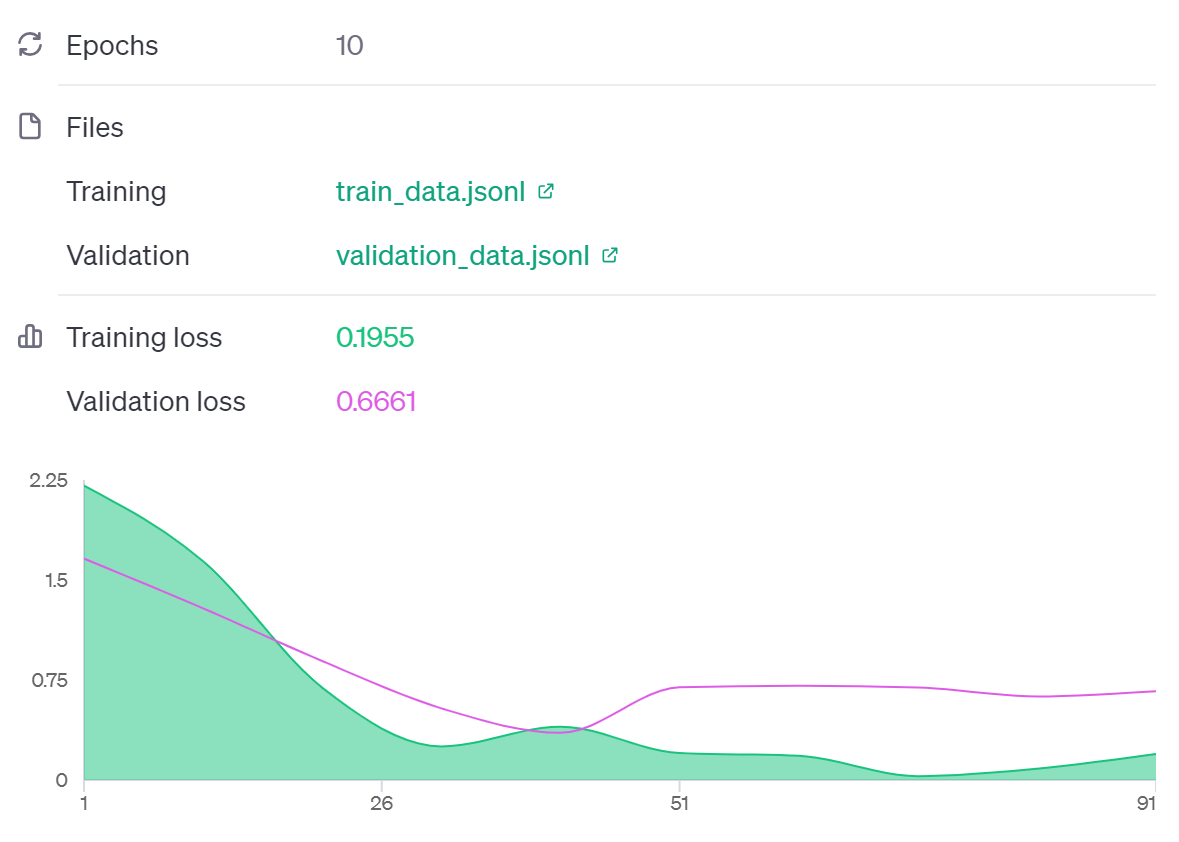
블로그용으로 train_data를 10개만 사용했더니 데이터가 적어서 epoch가 10으로 잡힌 것 같다. 역시 Training loss는 0.1955까지 떨어지지만 Validation loss는 41 step에서 저점을 찍고 다시 올라 0.666으로 마무리 된다.

이건 실제 학습했던 모델이다. 500개의 train_data, 100개의 validatoin_data로 파인튜닝한 결과다. 데이터 양이 많다보니 epochs는 3으로 잡혔다. loss 그래프가 마음에 들지 않지만 요금의 문제도 있고, 결과물을 생각보다 잘 찍어서 추가 학습을 하진 않았다.
요금
데이터도 6만개가 있었고, learning_rate 같은 하이퍼파라미터를 조정해가며 여러 차례 학습을 하고 싶지만 돈이 문제다 😂
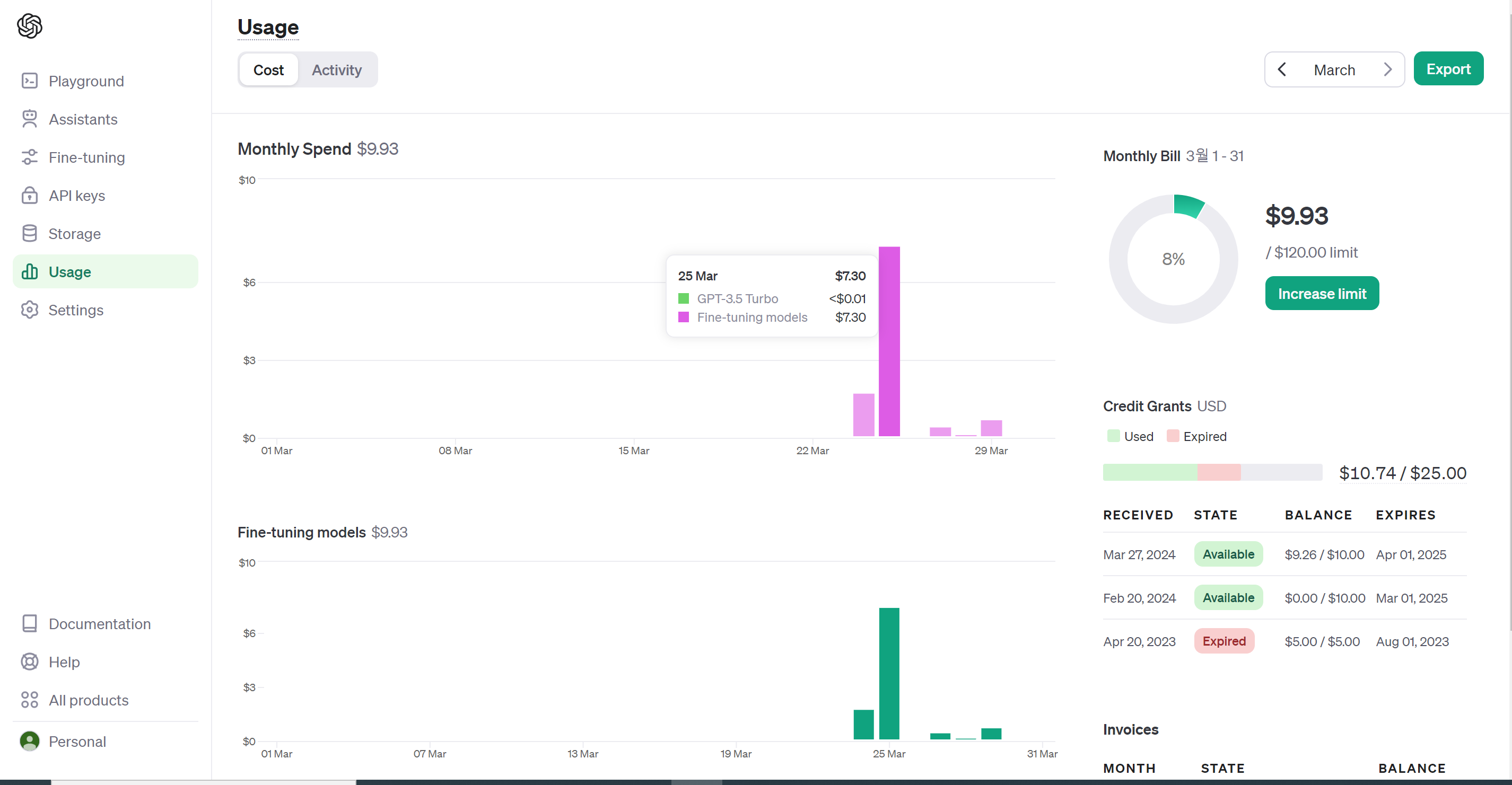
500개 train_data, 100개 validation_data로 학습을 돌렸을 때 약 한시간 십분 정도 소요됐고, 904,755개의 토큰을 사용한 결과 7.3$(9,837원)이 부과 되었다.
미리 충전해두고 차감되는 형태인데 최소 충전 금액이 11$이니 대충 얼마 정도 충전하면 될지 계산할 수 있을 것이다.
👍 마무리
Key를 발급받고, 개발환경 설정, 파인튜닝, 결과 확인 까지 알아보았다. 다음 글에서는 추론, 추론 api 개발 및 배포까지 알아보며 시리즈가 마무리 될 것 같다.
