
GPT 파인튜닝 시리지의 마지막으로 파인튜닝 된 모델을 추론하고 API로 배포하는 방법을 정리한다.
context에 사용할 농산물 정보 데이터 저장

질문을 생성할 문맥이 필요하기 때문에 미리 농산물 관련 데이터를 수집해 MySQL에 저장해뒀다. 데이터는 여기에서 수집했다.
Library Install
pip install fastapi
pip install pymysql
pip install 'uvicorn[standard]'MySQL에서 데이터 가져오기
전편에서 쓴 것 처럼 숨겨야할 DB 관련 정보들을 .env파일에 추가한다.
DB_URL = ${YOUR_URL}
DB_PORT = ${YOUR_PORT}
DB_USER = ${YOUR_USER_NAME}
DB_PASSWORD = ${YOUR_PW}
DB_NAME = ${YOUR_DB_NAME}main.py에서 Setting을 수정한다
class Settings(BaseSettings):
openai_api_key: str
ai_model_name : str
db_url : str
db_port : int
db_user : str
db_password : str
db_name : str
class Config:
env_file = ".env"
env_file_encoding = "utf-8"DB Connection을 생성한다
conn = pymysql.connect(host= settings.db_url, port=settings.db_port, user=settings.db_user, password=settings.db_password, db=settings.db_name, charset='utf8')DB에서 랜덤한 데이터 하나를 가져온다
def get_content() -> str:
cur = conn.cursor()
cur.execute("SELECT context FROM quiz_context_tb ORDER BY RAND() LIMIT 1")
return cur.fetchone()[0]질문 생성(추론) 하기
def make_question() -> str:
messages = [{"role": "system", "content": "You are the best quiz generator."}]
context = get_content()
context += '<sep>generate question with context'
message = {"role": "user", "content": context}
messages.append(message)
gpt_response = client.chat.completions.create(
model=settings.ai_model_name,
messages=messages,
temperature=0.3,
max_tokens=300
)
print(gpt_response)
return gpt_response.choices[0].message.content.split(', ')앞의 글에서 model의 역할을 부여한 것과 같이 "You are the best quiz generator."와 같이 역할을 부여한다.
이후 사용자의 입력으로 문맥<sep>generate question with context의 형태로 파인튜닝을 진행했으니 같은 형태로 만들어준다.
gpt_response = client.chat.completions.create(
model=settings.ai_model_name,
messages=messages,
temperature=0.3,
max_tokens=300
)학습이 완료된 모델의 이름을 입력한다. 모델 이름 또한 .env 파일에 저장해 settings.ai_model_name으로 접근한다.
messages에는 위에서 작성한 prompt를 넣어준다.
temperature는 GPT 가 생성하는 문장의 다양성이다. 값이 낮을 수록 일관적이고 안정적인 답변을 하고, 값이 높아질 수록 창의적(?)인 답변을 한다.
max_tokens는 생성할 답변의 최대 토큰을 지정한다.
이외에도 hyperparameters를 조정할 수도 있다.
자세한 내용은 공식문서에서 찾을 수 있다.
print의 결과는 다음과 같다
ChatCompletion(id='chatcmpl-99SIuPzsbuRzKh1srSMLzHMr3CrTA', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='question : 호박의 토양 산도는 얼마인가?, answer : pH 6.0∼6.5, wrong: pH 5.5∼6.0<sep>pH 6.5∼7.0<sep>pH 7.0 이상', role='assistant', function_call=None, tool_calls=None))], created=171*****0, model='ft:gpt-3.5-turbo-0125:personal::9****IA', object='chat.completion', system_fingerprint='fp_3******e1', usage=CompletionUsage(completion_tokens=71, prompt_tokens=166, total_tokens=237))즉 내가 필요한 데이터는 choices[0]의 message의 content 인 것을 알 수 있다.
이 데이터를 질문, 정답, 오답으로 구분하기 위해 ', '를 기준으로 split 하여 return 했다.
API 서버 개발
API 서버 개발을 위한 python 백엔드 프레임워크에는 django, Flask, fast api 등이 있고 나는 API 하나만 만들면 됐기 때문에 가장 빠르고 간편하게 사용할 수 있는 fast api를 통해 개발했다.
main.py
app = FastAPI()
@app.get("/quiz")
async def generate_quiz():
try:
question_data = await make_question_with_retry(max_retries=5)
return question_data
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
async def make_question_with_retry(max_retries: int) -> dict:
retry_count = 0
while retry_count < max_retries:
try:
gpt_response = make_question()
response = {
"question": gpt_response[0].split(' : ')[1],
"answer": gpt_response[1].split(' : ')[1],
"wrong": gpt_response[2].split(': ')[1].split('<sep>')
}
return response
except Exception as e:
print(f"Error: {e}, retrying... ({retry_count+1}/{max_retries})")
retry_count += 1
raise Exception("Failed to make a question after several retries.")genarate_quiz
@app.get("/quiz")를 통해BASE_URL/quiz로 요청이 들어왔을 때 함수가 실행된다.
make_question_with_retry함수를 통해 얻은 값을 사용자에게 반환한다.
make_question_with_retry
위의make_question를 통해 생성된 퀴즈, 정답, 오답을 반환한다.
이 과정에서 문제가 발생하는 것에 대비해 Exeption 발생시 해당 과정을 다시 반복하고 매개 변수인max_question만큼 반복했다면 Exception을 발생시킨다.
배포
main:app --reload를 통해 서버를 실행시킨다.
터미널에 표시되는 주소에 접속하면 api가 요청되고 잘 반환이 된다.
물론 이 방법은 Local 환경에서만 돌아간다.
나는 fast api 서버를 aws ec2에서 docker 환경에서 실행시켰다.
결과
다음은 실제 프로젝트에서 사용된 결과 화면이다.
어쩌다보니 화면도 React를 사용해서 내가 만들었는데 퀴즈 기능을 백엔드, 인프라, 프론트엔드까지 모두 하게 되어서 하나의 기능에 대한 개발 프로세스를 전부 경험해볼 수 있어 좋았다.
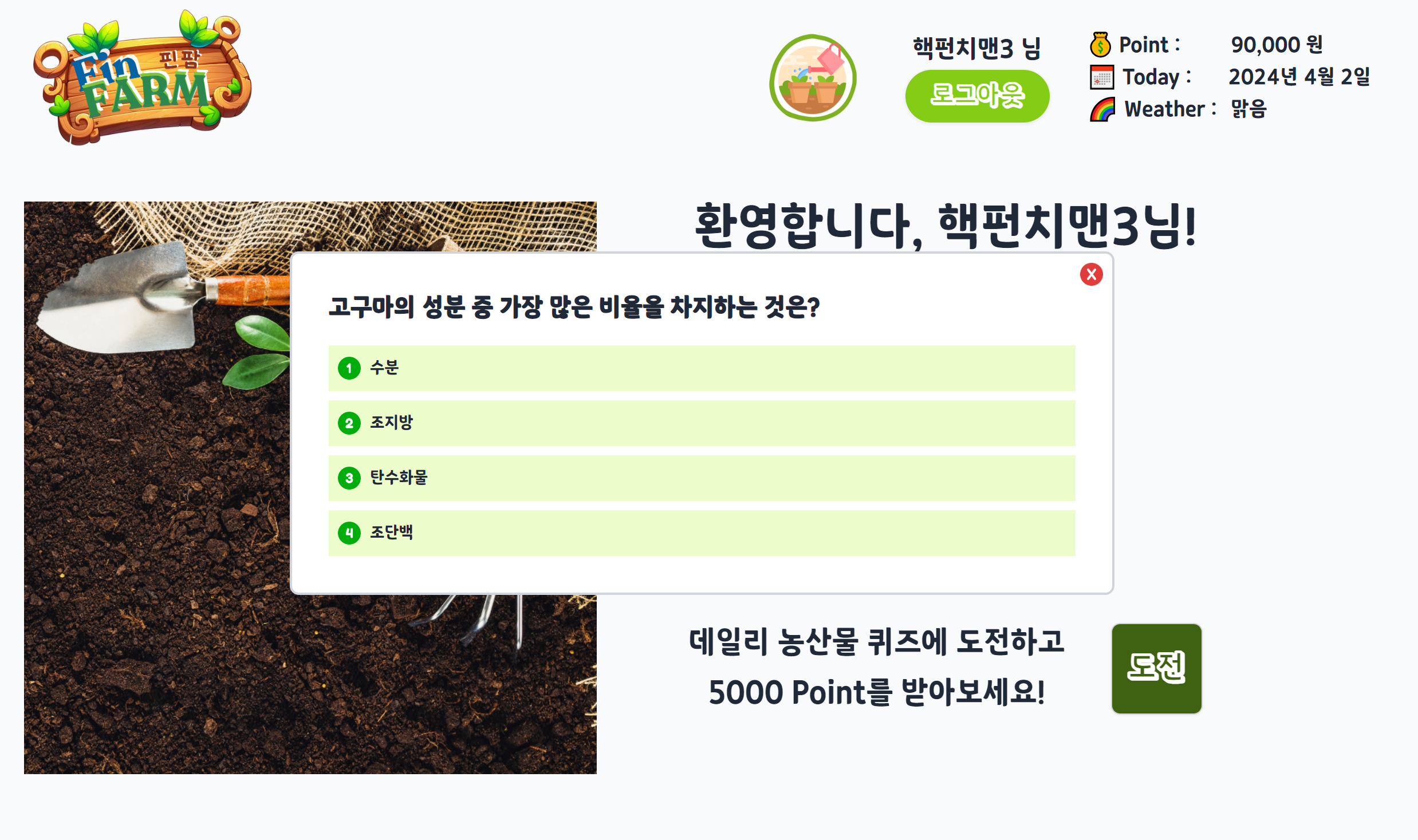
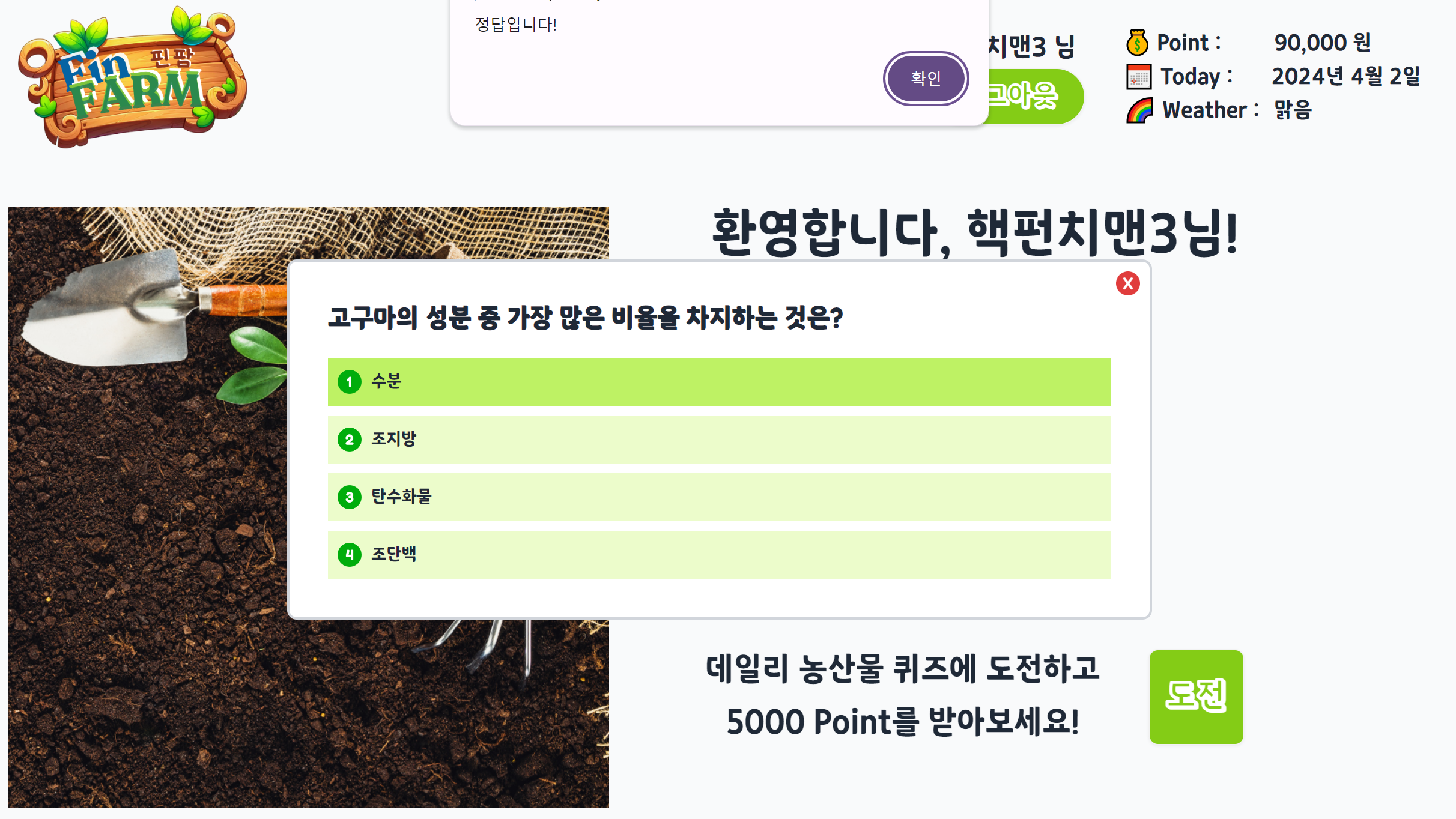
회고
AI에 대한 깊은 지식 없이 LLM 파인튜닝을 시도해봤다. 벽을 느꼈지만 오히려 좋아, 더 공부해서 좋은 결과물을 내보고 싶다는 계기가 되었고 핸즈온 머신러닝책으로 공부를 시작했다.
플랜 B 느낌으로 GPT라도 파인튜닝 해보자였지만 생각보다 까다로운 부분도 많았고, 배운 것도 많다.
요즘 바빠서 공부를 못하고 있지만 이번 프로젝트가 끝나면 다시 공부를 시작해야겠다.
