ClassSR: A General Framework to Accelerate Super-Resolution Networks by Data Characteristic
https://arxiv.org/pdf/2103.04039.pdf 글 참조
[Abstract]
이 논문의 목표는 SR network를 진행하는데 2K-8K정도의 큰 이미지의 SR을 목표로 한다.
일반적으로 큰 크기의 영상들은 실제로 작은 sub-image로 분해되어 사용된다.
=> 이미지를 영역별로 SR을 할 수 있고, SR하는 부분에 처리하는 용량의 어려움에 따라 수용할 수 있는 크기가 다른 네트워크에서 처리할 수 있다.
그래서 나온 모델이 ClassSR이며, 이는 두가지 방법이 합쳐진 새로운 solution pipeline이다.
ClassSR은 간단하게 표현하자면 classification + SR이 합쳐졌다고 생각하면 될듯.
먼저 Class-Module을 통해서 restoration difficulty에 따라 Sub-image를 분류한다.
다음으로 SR module을 통해서 서로 다른 class에 대해서 SR을 수행한다.
(이때, class module은 일반적인 classification network이고, sr module은 가속화시킬 SR network와 조금더 단순화된 버전으로 구성된 network이다.)
classification method로 2가지의 loss를 도입했는데, 이는 Class Loss와 Average Loss이다.
Train 후 sub-image의 대다수가 (중요 정보가 많이 없는 sub-image) 작은 용량을 처리할 수 있는 network를 통과하게 된다. => 중요하게 보지 않는 정보는 SR을 집중적으로 하지 않기 때문에 가벼운 network를 돌린다.
이렇게 SR을 돌릴 때 class를 돌리게 되면 computational cost를 줄일 수 있고, 실험 결과 FSRCNN, CARN, SRResNet, RCAN에 대해 더 좋은 성능을 낼 수 있다.
[Introduction]
요즘은 Smartphone이나 TV에서도 최소 4K 혹은 더 나아가 8K의 이미지들을 사용한다. 그렇기에 2K이상의 큰 이미지도 빠르게 처리할 수 있는 SR algorithm이 필요하다.
최근의 SR 연구는 초기의 FSRCNN이나 CARN처럼 경량화된 network 구조들을 제안했지만, 더 빠른 Network를 설계하는 것이 아니라 대부분의 SR method를 가속화할 수 있는 새로운 pipeline을 본 논문은 제시한다.
본 논문은 서로 다른 이미지 영역에서 다른 네트워크의 복잡성이 요구된다는 것을 확인했다.
(ex. 하늘이나 땅 같은 flat area에서보다 머리카락이나 깃털과 같이 texture area가 더 정교한 작업이 필요하기 때문에)
통계에 따르면 약 60%의 sub-images(32X32)는 DIV8K dataset의 smooth region이지만, DIV2K의 경우에는 30%정도입니다. 즉, 이미지의 크기가 커질 수록 LR Sub-image가 차지하는 부분이 많아지기 때문에 SR하는데 있어 가속도가 더 높아진다.
[Methods]
DIV2K의 validation set에서 나온 32X32의 sub-image를 사용하는데, 이때, 모든 sub-image에 대하여 MSRResNet을 거쳐 PSNR을 뽑고 순위를 낸다.
여기부터 설명
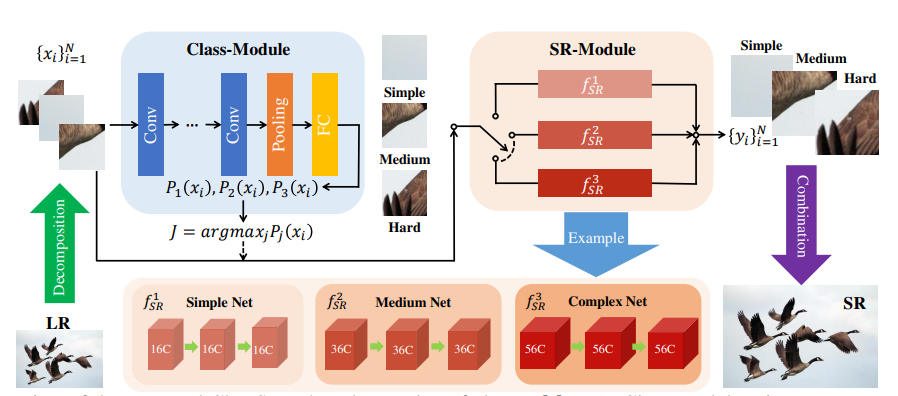
대략적인 Class SR의 흐름 => 먼저 큰 LR img를 분해시킨다.
다음으로 sub-image들을 class module로 보낸 뒤 확률 벡터를 생성한다.
그런 다음 maximum probability 값에 따라 사용할 SR Network를 결정한다.
SR Module를 통해 나온 output subimage를 합쳐서 final large SR image를 만든다.
[class module]
class module의 목표는 input subimage가 SR하는 과정에 있어 smooth한 이미지인지 아닌지를 파악하게 된다.
Class Module은 단순한 분류기 모양이다.
5개의 convolution layer와 average pooling layer, 그리고 fully connected layer로 구성이 되어있다.
매우 가벼운 모델로 구성되어있지만, 간단한 구조에서 괜찮은 분류 결과를 얻을 수 있게 됐고, 이를 통해 어떤 SR Network를 사용하게 될지를 정해준다.
[SR module]
SR module은 여러개의 independent한 branch들로 구성이 되어있습니다.
-> 본 논문의 목표는 기존 SR 방법을 가속화하는 것이기 때문에, hard class에 대한 것을 FmSR branch라고 한다.
다른 F1, F2 branch는 network complexity를 줄여서 사용합니다.
다시 말해, 각 convolution layer의 channel 수를 통해 제어를 하게 되는데, 본래의 모델과 비슷한 성능을 내도록 맞춰야한다.
예로 FSRCNN을 들어본다면
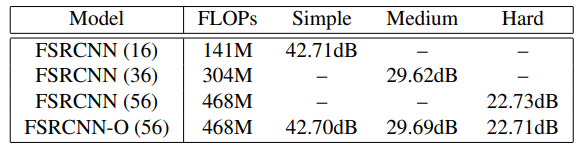
사진과 같이 FSRCNN-O는 채널수가 56개인 original 모델이다.
이와 비슷한 성능을 내게 해주는 채널 수를 찾으면 되는데, 그게 simple에는 16, medium에는 36, hard에는 56이다.
[classification method]
Training 중에 class module은 미리 지정된 label이 아니라 특정한 branch의 restoration에 따라 sub-image들을 분류하게 되기 때문에 Train시에는 sub-image들이 모든 SR branch들을 통과해야한다.
그리고 class module에서 SR로 만든 결과와 classification probability들을 곱해 최종 SR에 대한 output y를 만든다.
[Loss function]
여기서 사용되는 loss는 총 3가지로, L1 loss와 본 논문에서 제안하는 loss 2개가 있다. (class loss, average loss)
먼저 class loss는 다른 module보다 maximum probability를 가지고 더 높은 신뢰도를 가지고 있는 것이 좋다. 예를 들어 90%,5%,5%가 34%,33%,33%보다 random select를 하는 것처럼 보이기 떄문에 전자가 더 괜찮은 경우이다.
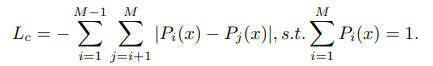
여기서 M은 class의 수이고, Lc는 동일한 sub image에 대한 각 class probability 사이의 거리 합계에 음수값을 취한 것이다.
이렇게 된다면 서로 다른 classification의 결과 사이에서 확률 차이를 크게 낼 수 있기 때문에 최대 확률 값이 1에 가까울 수 있게 됩니다.
(...?
다음은 Average loss이다.
image loss와 class loss만 사용하게 된다면 sub image들이 hard class에 분류되는 경우가 많아지기 때문에 이를 방지하기 위한 것이 average loss이다.
각 classification에 제하을 두기 위해 이 loss를 사용하고, 수식은 다음과 같다.
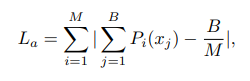
여기서 B는 batch size이고, La는 batch 내 class의 average number(B/M)와 sub image 수 사이의 거리 합이다.
이 loss로 training 중 각 SR branch를 통과하는 sub-image의 수는 거의 동일하게 된다.
[Training Strategy]
3가지의 순서로 Class SR를 Train시킨다.
1. SR module를 pre-train하고, 2. 3개의 loss를 사용하여 3. class module을 고정시키고, 마지막으로 모든 network를 finetune시킨다.
(class module과 sr module를 처음부터 train 하면 성능이 매우 불안정해지고, classification하는데 있어 안좋은 영향을 받는다)
SR module을 pre trian할 때 PSNR 값으로 분류되어있는 data를 사용한다.
특히 모든 sub-image들은 train된 MSRResNet을 통해 전달된다.
그런 후 sub image의 rank가 psnr값에 따라 정해지게 된다.
그 뒤, class module를 추가하고 sr module의 parameter를 수정합니다.
joint training할 동안 class module은 최종적인 SR image로 확률 벡터를 조정하고, SR Module은 새로운 classification 결과에 따라 update된다.
[Experiments]
[Training data]
=> DIV2K dataset을 사용한다.
Training data를 준비하기 위해 scaling factor(0.6, 0.7, 0.8, 0.9)를 사용해서 원본 image를 downsampling하여 HR 영상을 생성한다.
그 뒤 LR을 위해 4번더 downsampling한뒤 32x32로 image를 자르게 됩니다. 그 후 동일한 비율로 classification된다.
또한 flip & rotation을 진행한다.
사용된 Detail
=>
mini batch size = 16
optimizer = adam
learning rate = 초기에 10-3, 최소는 10-7
learning rate scheduler = cosine annealing
[Result]
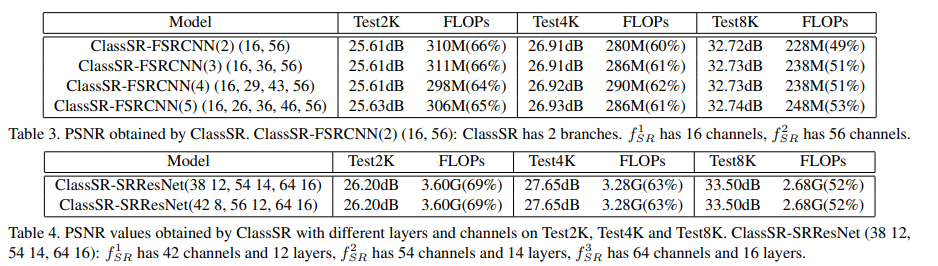
FSRCNN을 예로 든다면 60%정도가 simple, 23% medium, 16%가 hard로가서 FLOPs를 468M에서 236M정도 줄이는 효과를 내었다.
