[Paper Review] Bag of Tricks for Image Classification with Convolutional Neural Networks review
본 포스팅은 https://arxiv.org/pdf/1812.01187.pdf 를 참고했다.
[Abstract]
image classificaion에서 data augmentation이나 optimization을 변경해가면서 학습 방법을 개선하는 방식을 통해 좋은 성능을 낼 수 있지만, 논문들에서는 이 점에 대해 간단하게 서술하거나 코드에서만 볼 수 있다.
=> 이 논문에서는 이러한 개선점들을 조사하고, ablation study를 통해 최종 모델의 정확도에 미치는 영향을 평가할 것이다.
(ex, ResNet-50의 top-1 error의 정확도를 75.3%-> 79.29%로 증가)
또한 image classification의 정확도를 높이는 것이 다른 도메인인 Object detection과 Semantic segmentation에서도 좋은 결과로 이어졌다.
(왜일까 ?
image classification : image 안의 객체의 종류를 구분하는 행위
+localization : image 안의 object가 이미지 안의 어느 위치에 있는지 위치 정보를 출력해주는 것
Object detection : 보편적으로 Classification + Localization
Semantic Segmentation : Object segmentation을 하는데, 같은 class인 object들은 같은 영역 혹은 색으로 분할 하는 것
=> 기본적으로 image classification이 기초가 되기 때문에)
[Introduction]
많은 모델들이 나왔는데, 이는 단순히 Architecture 개선 뿐 아니라, loss function, data preprocessing, optimization을 포함한 training 절차 개선도 큰 역할을 했다. 하지만 이 점은 잠깐 소개되거나, 코드에서만 확인할 수 있어 상대적으로 적은 관심을 받았다.
이 논문에서는 계산 복잡도는 변경하지 않고, Architecture나 training procedure개선을 살펴볼 것이며 이 중에는 stride size를 변경하거나, learning rate를 조절하는 것도 포함이 된다.
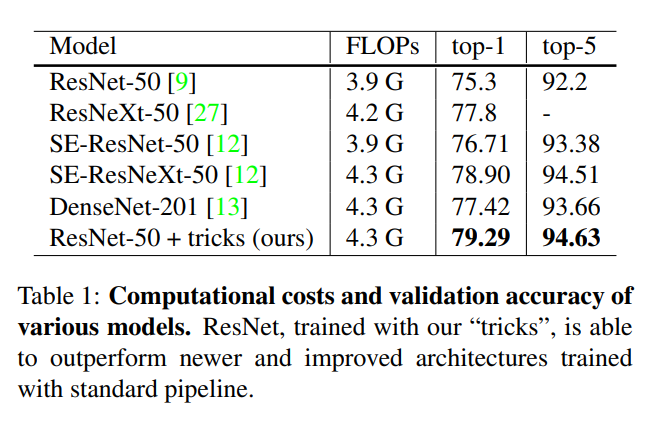
실제로 다른 모델보다도 ResNet50에 tricks를 적용했을 때 top-1 error가 향상됐다.
[Training Procedures]

학습 절차는 SGD가 적용된 일반적인 CNN 모델의 학습 기법과 같다.
각 iteration 마다 b이미지를 랜덤하게 샘플링하고, gradient를 계산한 다음 parameter를 update한다. 알고리즘이 K번이 지난 다음 종료 되고, 모든 함수 및 하이퍼파라미터는 조정할 수 있다.
[baseline]

1. 랜덤 샘플링을 통해서 [0,255]에서 FP32로 decoding
2. 랜덤 샘플링된 직사각형 영역을 임의로 crop한 다음 자를 영역의 크기를 224x224로 조정한다.
3. 수평으로 뒤집고 (좌우회전 50%확률로)
4. 밝기, 색조 등을 조정한다. (아마 bn?)
5. PCA noise를 추가한다.
validation에서는 aspect ratio를 유지하면서 짧은 축이 256이 되게끔 사이즈 조절하고 224x224로 center crop, RGB 채널에 Normalization해주고, random augmentation을 하지 않는다.
convolution layer와 fc layer에서 xavier algorithm을 사용하여 초기화한다.
(xavier algorithm : 입력값과 출력값 사이의 난수를 선택해서 입력값의 제곱근으로 나눈다.)
실행 시 : Optimizer NAG, 120 epoch, Nvidia V100 GPU 8개, batch size 256, learning rate : 0.1 , 30, 60, 90 epoch마다 10으로 나눈다.
[Experiment Result]
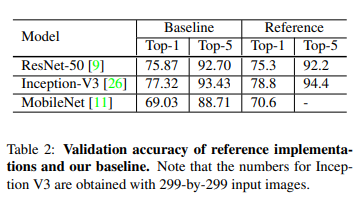
ResNet-50, Inception-V3, MobileNet으로 실험했다.(Inception-V3에서는 input size를 299x299로 resize)
Dataset : ISLVRC2012 (1.3 million, 1000class)
[Efficient Training]
최근 GPU가 발전해왔기에 더 낮은 numerical precision 및 large batch size를 training 단계에서 사용하더라도 trade-off 문제는 많이 줄었다.
[large-batch training]
Mini-batch SGD => 병렬화를 증가시키고, 연산 비용을 감소시킨다.
(전체 dataset에서 뽑은 mini batch안의 데이터 m개에 대해서 각 데이터에 기울기를 m개 구한 뒤, 그것의 평균 기울기를 통해 모델을 업데이트 하는 방법)
large batch 는 훈련 속도를 늦추는데 convex problem에서는 배치크기가 커질 수록 수렴 속도가 감소.
(convex problem => convex optimization이란 완전한 optimum을 찾는 경우)
동일한 epoch에서 더 큰 배치를 사용하는 경우가 더 작은 배치를 사용할 때보다 validation 정확도가 떨어진다. (왜,,?)
그래서 해결하기 위한 방법
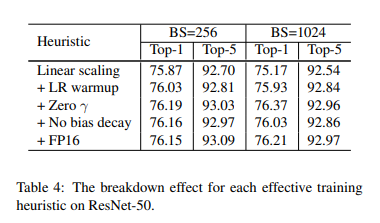
[Linear scaling learning rate]
mini-batch SGD에서 각 배치마다 example들이 랜덤하게 선택되므로, gradient descending이 랜덤하게 진행된다.
batch size를 증가시키는 것은 영향이 약하지만, 분산을 줄여주면 된다.
다시 말하자면, large batch size는 gradient의 noise를 줄여주니까, 우리는 learning rate를 증가시키면 된다.
batch size가 256일때, 초기 learning rate를 0.1로 맞춰주고, batch size를 b로 변경하면 초기 learning rate를 0.1*b/256으로 설정한다.
[Leaning rate warmup]
학습 초반에는 모든 parameter들이 랜덤하게 초기화된다. => 최종값과는 차이가 있다.
너무 큰 learning rate를 사용하게 되면 수치적으로 불안정 => warmup 기법을 사용해야한다.
(Learning rate scheduler는 미리 Lr schedule를 정해둔 뒤 warmup이라는 파라미터를 설정하고 현재 step이 warmup보다 낮을 경우에는 linear하게 증가시키고, warmup 후에는 각 Lr scheduler에서 정한 방법대로 update한다.)
m번째 batch까지 warmup을 수행하고, 초기 learning rate를 η라고 한다면, i배치에서의 learning rate는 iη/m이 된다.
[Zero γ]
Zero γ는 모든 BN layer에 대해 γ를 0으로 설정하여, residual block들이 skip-connection 결과만 보낸다. (즉, 모든 입력값을 그대로 반환한다.) 따라서 초기에 망이 짧아겨서 학습이 빨라지는 현상이 발생한다.
[No bias decay]
L2 regularization과 같다. => 보통 weight와 bias를 포함한 모든 학습 가능한 파라미터에 적용한다. weight decay를 오버피팅을 방지하기 위해 weight에만 적용하는 것을 추천한다.
[Low precision training]
보통의 train은 FP32로 연산이 되는데, 하드웨어의 향상으로 더 작은 크기의 데이터 타입에서도 더 빠른 연산을 지원한다.
(ex, V100에서 FP 32에선 14TELOPS, FP16에선 100TELOPS)
but, FP16은 표현범위가 작아져서 Train을 방해하는 부분이 있어서 모든 parameter&activation은 FP16으로 구현하고, FP32로 복사한 뒤 parameter update시 loss 계산하는 mixed precision training 방법이 있다.
[Experiment Results]
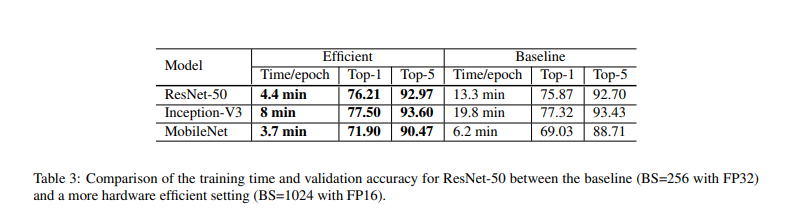
ResNet-50에서 1024 batch 사이즈와 FP 16을 사용했을 때 1epoch당 13.3 min -> 4.4로 학습시간 줄인 결과를 냈다.
또한 다음 baseline과 efficient를 낸 결과는 다음 사진과 같다.
[Model Tweaks]
conv layer의 stride을 바꾸는 것과 같은 개선이다.
연산 복잡성에선 미미한 영향, 모델의 정확도 개선에는 효과가 크다.
(ResNet 모델을 이용한다.)
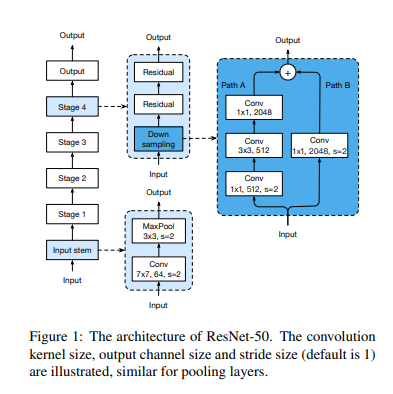
input stem=> conv 7x7, stride=2 (64 channel 출력을 하는)
그 뒤에 3x3 maxpooling layer (stride 2), 이때 input stem은 input의 w와 h를 4배만큼 줄이고 channel size를 64로 늘린다.
stage 2부터 downsampling과 residual block로 구성되고, down sampling path에는 파란색 상자 안의 PATH A와 PATH B가 있다.
[ResNet Tweaks]
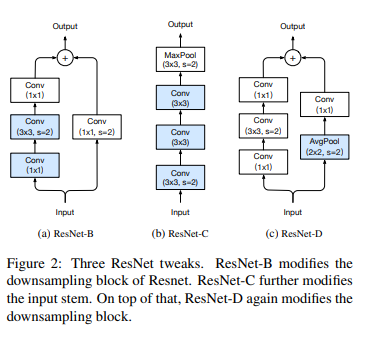
ResNet-B => downsampling block를 변경한 것이다. (기존 모델 -> stride가 2라서 feature map의 3/4를 날린다. But B는 아님)
ResNet-C => Inception-V2에서 제안된 방법을 적용, Input stem 부분을 수정하여, 연산량의 증가를 줄여준다.
ResNet-D => 정보의 손실을 막기 위해 stride가 2인 average pooling layer를 추가했으며, 원래의 conv의 stride를 1로 변경
[Experiment Results]
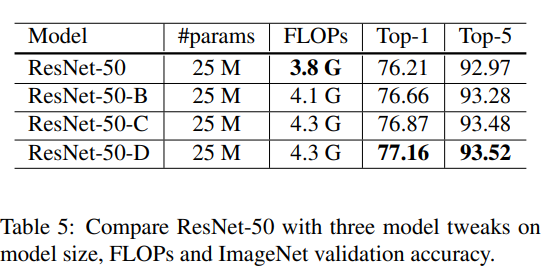
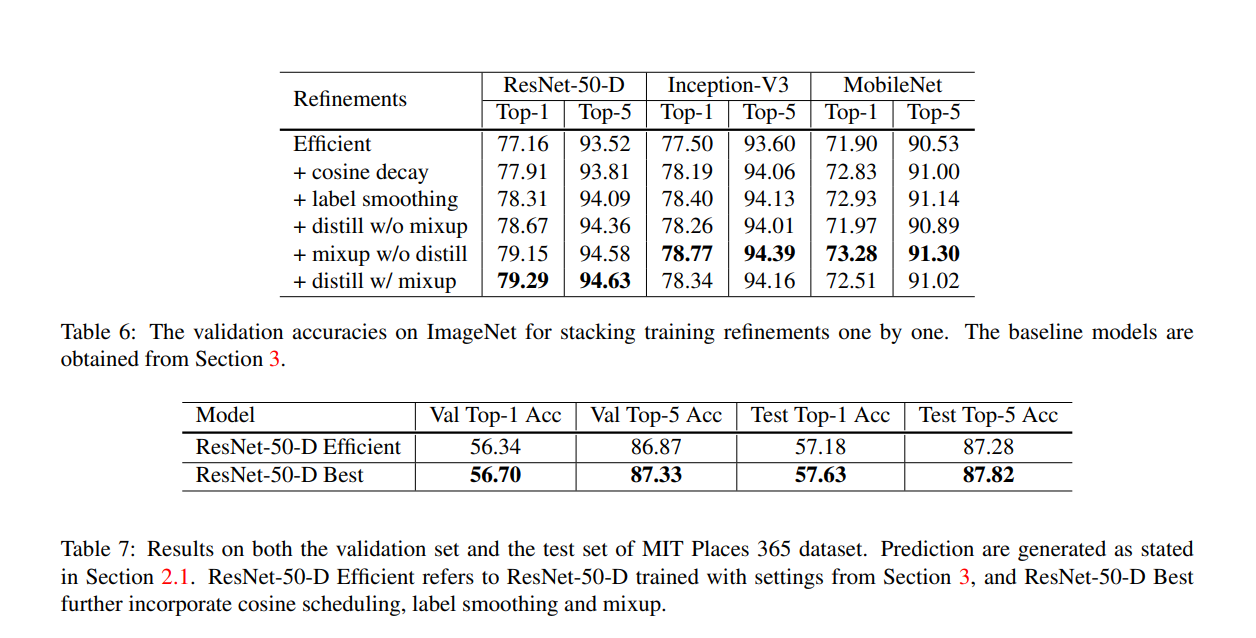
변경된 결과의 값은 위의 표와 같다. ResNet-D의 경우 연산량이 많아지지만, ResNet-50보다는 약 15%정도이며, 속도는 3%정도 느리다.
[Training Refinements]
[Cosine Learning rate decay]
learning rate decay 방법 중 가장 널리 사용되는 것은 exponentially decay이다.
Step decay는 30 epoch 마다 0.1을 감소시키는 것
Cosine decay는 천천히 감소하다가 선형의 모양으로 감소하다가 다시 천천히 감소하는 특징이 있다.
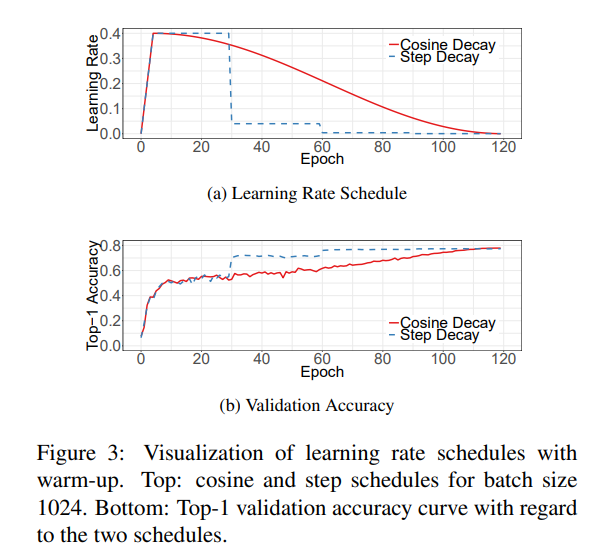
(Cosine decay는 끊김없이 loss가 감소하고 Step Decay보다 하이퍼 파라미터를 덜 생각할 수 있게 된다. [step decay보다]
참고 블로그 : https://velog.io/@good159897/Learning-rate-Decay%EC%9D%98-%EC%A2%85%EB%A5%98)
[Label Smoothing]
classification 학습할 떄, 정답은 1 나머지는 0인 one-hot vector를 label로 사용하는데, 0 대신 작은 값을 갖는 방식을 의미한다. (왜 사용할까 ? 기존의 방식은 오버피팅이 발생할 수 있다.)
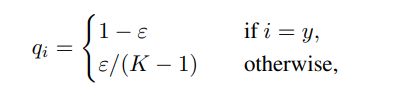
(ϵ값으로는 0.1을 사용했으며, K의 값은 class의 개수이다.)
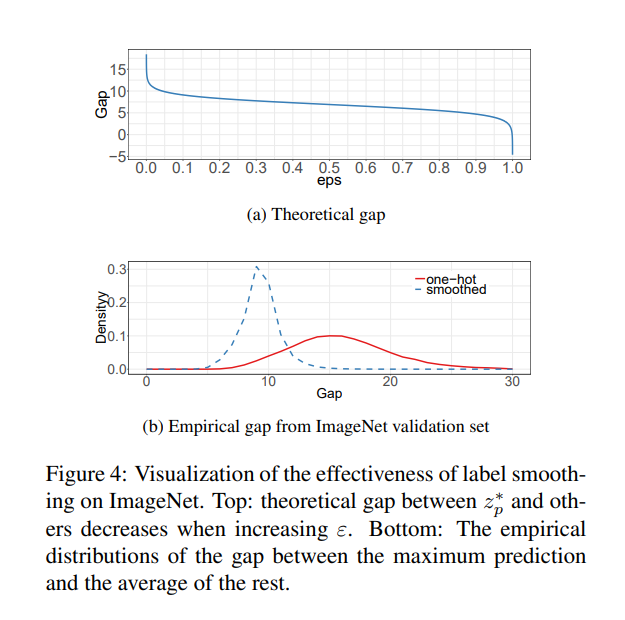
이를 사용함으로써 gap이 9.1에 수렴하는 것을 볼 수 있다.
[Knowledge Distillation]
성능이 좋은 teacher model(pre-trained)를 이용하여 student model이 적은 연산 복잡도를 가지면서 teacher model의 정확도를 따라가도록 학습시키는 방법이다.
(ex, ResNet-152로 pre-trained model로 사용하여, ResNet-50을 학습시키는 것)
학습시 Teacher model과 student model간의 softmax output의 차이를 줄이기 위해 distillation loss를 더해준다.
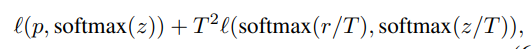
(여기서 T는 하이퍼 파라미터이다. r은 teacher의 출력값 z는 student의 출력값이다.)
[Mixup Training]
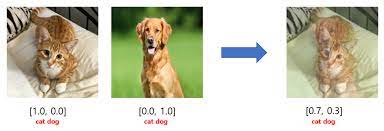
mixup은 augmentation기법 중 하나로, 두개의 이미지가 있을 때 이 이미지들로 새로운 이미지를 만들어내는 것이다. (두 이미지에 weighted linear interpolation을 적용하여)
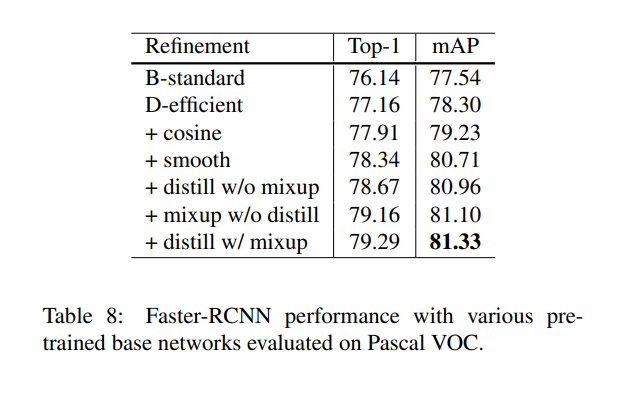
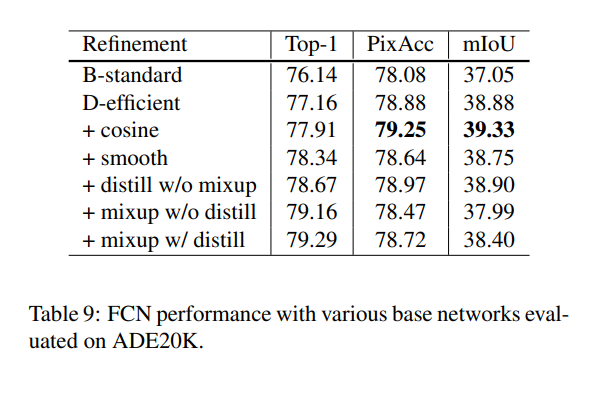
[Experiment Results]
label smoothing => ε값을 0.1
model distillation에서 T=20, Teacher model로 label smoothing이 적용된 ResNet-152-D model(cosine decay기법을 적용)
epoch => 120->200으로 증가.
[Object detection]
classification에 적용한 것을 object detection에 적용했을 때에도 효과가 좋아지는가?
=> dataset : PASCAL VOC를 사용하였고, VGG-19를 base로 하는 Faster-RCNN에 대해 실험하였고, Semantic Segmentation은 FCN으로 실험하였다.