[Paper Review] Enhanced Deep Residual Networks for Single Image Super-Resolution ("EDSR")
[Abstract]
- SR관련 연구들은 DCNN의 발전과 함께 진행되었는데, 이중 residual learning 기술이 성능 향상에 도움이 됐다.
- EDSR는 더 향상된 deep sr network로 SOTA 성능을 넘는 네트워크를 제시했다.
- Training 절차를 안정화시키는 동안 모델의 크기를 확장시킴으로써 성능이 향상된다(?
- 또한 단일 모델에서 여러 배율의 upscaling이 적용가능한 MDSR을 제시한다.
[Introduction]
deep neural network가 PSNR 기준으로 좋은 성능을 보였지만, 구조에 대해서는 한계가 있다.
⇒ 1. 네트워크의 성능의 재현에 있어서 구조의 미세한 변화에 민감하다. 같은 모델이라도 initialization이나 training technique을 다르게 한다면 성능이 달라진다.
- 대부분의 알고리즘들은 다른 배수들의 연관성을 생각하기보다는 독립적인 각각의 문제로 본다. 즉, 대부분의 존재하는 SR 알고리즘은 모델에 한가지의 배율만 적용할 수 있다는 것이다.
예외적으로 VDSR이 있는데, VDSR은 단일 네트워크에서 여러 scale의 SR을 공동으로 처리할 수 있다. VDSR을 여러 scale로 train시키면 성능이 크게 향상되지만, 입력으로 bicubic interpolation된 이미지가 input으로 들어가고 scale별로 upsampling 하는 방법과 비교했을 때는 더 많은 계산시간과 메모리를 사용한다.
이러한 시간과 메모리 문제를 해결한 모델이 SRResNet이다. 기존의 ResNet 구조를 사용하여 좋은 성능을 내는데 성공했지만, original resnet구조는 image classification and detection문제에서 적합하기는 하지만, SR에 사용하기에는 최선책이 아닐 수도 있다.(저자 피셜
이 한계점을 해결하기 위해서 SRResNet을 기반으로 하여 모델에서 필요없는 부분을 제거하고, 3, 4배율을 학습하는데에 pre-train된 2배율 학습 모델을 사용하여 한번에 여러 배율이 확대가 가능한 모델을 만들었다.
[Related Works]
- SR 문제를 해결하는데 interpolation을 사용했는데 realistic texture과 같은 디테일한 부분들을 예측하는데에 한계를 보였다. (⇒ realistic texture 실제와 비슷한 느낌 재현에 있어서 떨어지는 성능이 있다?)
- DNN을 SR에 적용하여 성능이 크게 향상되었고 더 깊은 네트워크를 학습시키기 위해서 residual 구조를 적용하였다 또한 skip-connection과 encoder-decoder 구조를 사용했을 때 빠르고 향상된 수렴을 보였다.
- 많은 딥러닝 기반의 SR에서 입력 이미지는 bicubic interpolation을 이용하여 upsampling하거나, SRGAN 처럼 모델의 끝에서 upsampling을 학습할 수도 있다.
- 하지만 이러한 방법은 VDSR처럼 하나의 모델에서 여러가지 scale을 처리할 수는 없다.
⇒ 따라서 이 논문에서는 각 scale에 대해서 학습된 모델을 잘 활용하고, 여러 scale에 대한 HR 이미지를 효율적으로 만드는 MDSR을 제안한다.
또한 다른 연구들은 model 학습을 잘할 수 있도록 loss function에 집중하기도 하는데 MSE나 L2 loss function이 가장 흔히 이용되는 함수지만, Zhao에 의하면 L1 loss function의 성능이 더 좋다라고 제시한다.
[Proposed Methods]
[Residual blocks]
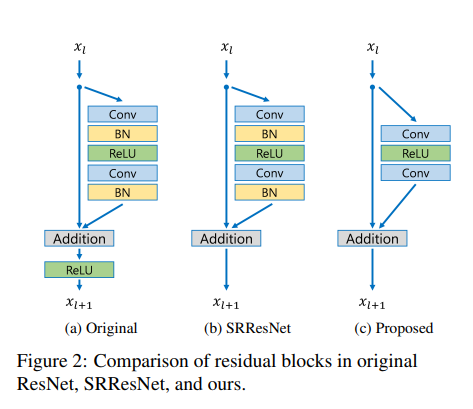
a : 원래의 ResNet
b : SRResNet
c : EDSR
그림에서 보는 것과 같이 original resnet에서 ReLU와 BN이 빠진 것을 확인할 수 있다.
BN layer를 사용하지 않은 이유 2가지
- BN layer는 feature들을 normalize하기 때문에 blur가 되어버린다.
- BN layer는 메모리를 많이 차지하기 때문에 이를 제거하여 GPU 사용량을 40% 감소시켰다.
[Single-scale model]
네트워크 모델의 성능을 향상시키는 가장 간단한 방법은 파라미터의 수를 증가시키는 것이다.
B depth(layer의 수)와 F width(feature channel의 개수)라고 할때, 일반적인 CNN 구조의 네트워크는 O(BF)의 메모리 공간을 O(BF^2)개의 파라미터로 채운다.
But 이렇게 feature의 수가 증가하더라도, 일정수준 이상으로 feature를 증가시키는 것은 학습 과정을 더 불안정하게 만들 수 있다.
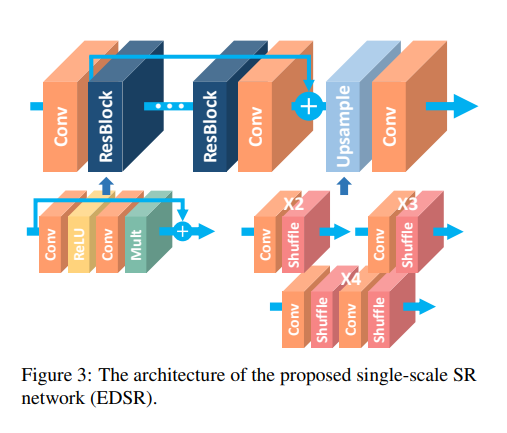
이를 해결하기 위해 논문에서는 residual scaling factor를 0.1로 적용하고, constant scaling layer를 residual block의 마지막 convolution layer 뒤에 배치한다.
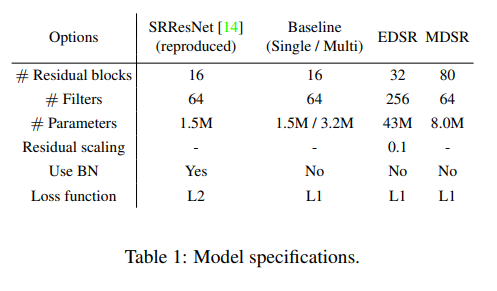
논문에서는 baseline 모델을 위의 그림과 같은 구조를 이용했으며, scaling layer를 넣지 않았다.(이유 :: 각각의 convolution layer에 대해서 64개의 많지 않은 feature map을 사용했기 때문)
논문의 최종 EDSR에서는 B=32, F=256으로 scaling factor를 0.1로 사용했다.
x3, x4 scale 모델을 학습할 경우에는 x2의 사전 학습된 모델의 파라미터로 초기화하여 학습했다.
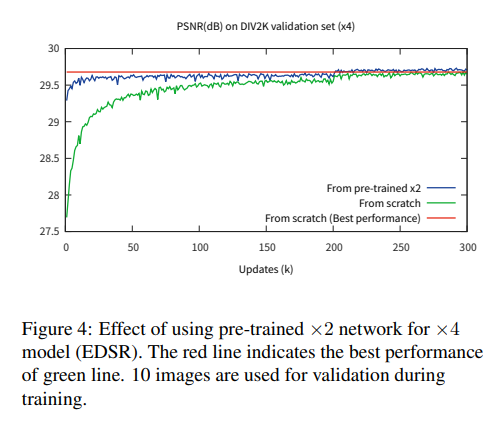
[Multi scale model]
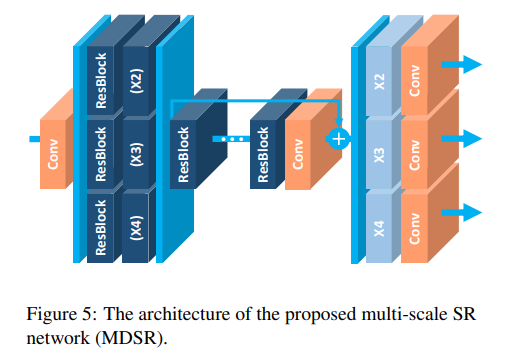
VDSR과 같은 multi scale 구조를 만들고자 하고, 다른 scale의 parameter들을 공유하는 구조를 만들었다.
B=16인 residual block들로 single main branch를 만들어, 다른 배수의 모델들이 서로 파라미터를 공유할 수 있도록 baseline 모델을 설계했다.
SR의 multiple scale을 다루기 위한 scale-specific processing 모듈을 추가했다.
다른 크기의 input image의 다양성을 줄이기 위해 네트워크 앞단에 pre-processing 모듈을 넣었다.
전처리 모듈은 5x5 커널의 residual block 2개로 이루어져있다.
모델의 끝에는 특정 upsampling 모듈을 multi scale 재구성을 위해서 전처리 모듈과 마찬가지로 병렬적으로 배치한다.
결과적으로 B=80, F=64의 MDSR 모델을 구성한다. 단일 scale 변환이 가능한 경우에는 모델당 약 1.5M개의 매개변수가 필요하므로 총 4.5개의 변수를 지니게 되는데, baseline multi scale 모델의 경우에는 3.2M개의 매개변수만을 필요로 하여 시간은 단축시키고, 성능은 단일 모델과 유사하다.
[Experiments]
[Datasets]
DIV2K dataset을 사용하였고, 8:1:1=Train : validation : Test로 구성되어있다.
학습을 위해 LR image에서 48X48 크기의 RGM 입력 패치를 해당 HR 패치와 함께 사용하는데, 이는 2K 이미지를 그대로 넣으면 모델의 크기가 버티지 못하기 때문이다.
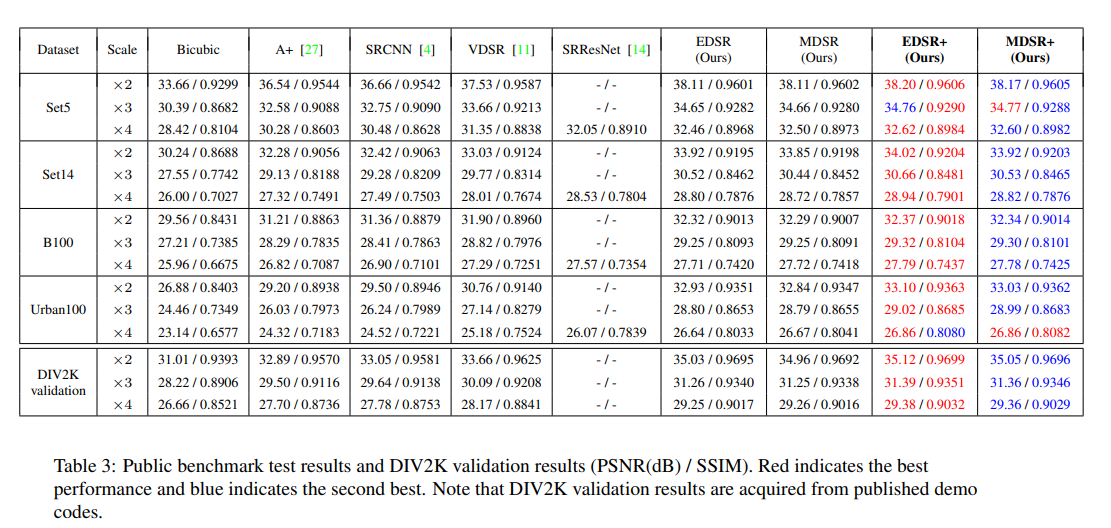
또한 성능을 비교하기 위해 4가지의 표준 benchmark dataset도 사용했다. (Set5, Set14, B100, Urban100)
[Training Details]
input patch : 48 X 48 patch
Augmentation : 영상을 좌우반전, 90도 단위로 회전시켜 사용
Optimizer : Adam
loss function : L1 loss
mini batch size : 16
learning rate : 처음에는 0.0001로 하면서 2x10^5 배치 업데이트때마다 절반으로 감소합니다.
[Geometric self-ensemble]
model의 성능을 높이기 위해 self-ensemble 기법을 사용하였다. (self-ensemble?)
test 할 때 input image를 flip and rotate하여 각 sample별로 7 augmented input을 만들어서 사용하였다.
이런 기법을 토대로 만들어진 모델을 EDSR+ / MDSR+로 이름을 붙였다.
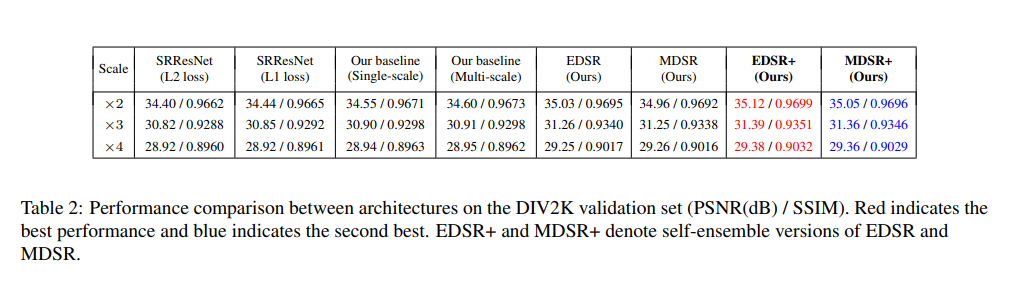
[Evaluation on DIV2K Dataset]