[Paper Review] Photo-Realistic Single Image Super Resolution Using a Generative Adversarial Network
SRGAN 논문 리뷰
https://arxiv.org/pdf/1609.04802.pdf
[Abstract]
SR task에서 정확도와 속도 면에서는 개선이 이루어졌지만, 한가지 해결되지 않은 것이 있다.
(=large upscaling factor에서 SR할 때, 더 미세한 texture detail을 어떻게 복구할 것인가?)
최근 연구는 목적 함수에 초점을 두는데, MSE loss를 최소화하는 것에 집중한다.
결과로 PSNR은 높게 나오지만 detail를 살리지 못하여 지각적으로 만족스럽지 못하다.
(=PSNR로 metric은 높게 나오지만, 세부적인 detail를 잘 살리지 못해 보기에 별로 성능이 좋아보이지 않는다?)
MSE를 사용하는건 간단하고 편리하지만, 이미지의 세밀한 texture를 볼 때 지각척인 차이를 잡아내는데 한계가 존재한다.
Why> mse는 서로 다른 image 간의 pixel wise 차이들의 평균값을 계산하는 것이기 때문에 서로 다른 pixel간의 정보를 담는건 불가능하기 때문이다.
SRGAN은 4배 upscaling factor에 대한 현실적인 이미지를 추론할 수 있는 최초의
프레임워크이다.
본 논문에서는 perceptual loss를 제안하는데, 이것은 adversarial loss와 content loss로 구성되어있다. (뒤에 나옴)
사용된 deep residual network는 심하게 downsampled된 이미지의 texture를 복구할 수 있다.
[Introduction]
supervised SR 알고리즘의 최적화 목표는 HR이미지와 GT이미지의 MSE를 최적화하는 것이다. (=> MSE를 최소화하면 PSNR이 최대화가 되기 때문에)
PSNR이 pixel-wise 기반이라서 perceptually relevant 표현을 잘 하지 못하는 한계를 가지고 있다.
따라서 PSNR이 높다고 해서 반드시 SR결과가 좋은 것은 아니다.

위의 사진과 같이, SRResNet이 PSNR이 높음에도 불구하고 SRGAN이 선명도가 높은 것을 확인할 수 있다.
이전 연구와 다른 점은 VGG net의 high-level feature map을 이용한 독보적인 perceptual loss를 제시하고 이를 기반으로 만들어진 예시 결과가 위의 사진이다.
[Related work]
[Design of convolutional neural networks]
Deep Network는 학습에 어려움이 있다는 문제가 있어서 이를 해결하기 위해서 SRGAN에서는 batch normalization과 skip connection을 사용했다.
Batch Normalization은 Internal Covariate Shift를 막아주고, Upscaling Filter는 정확도와 속도 관점에서 유용하다.
[Loss Function]
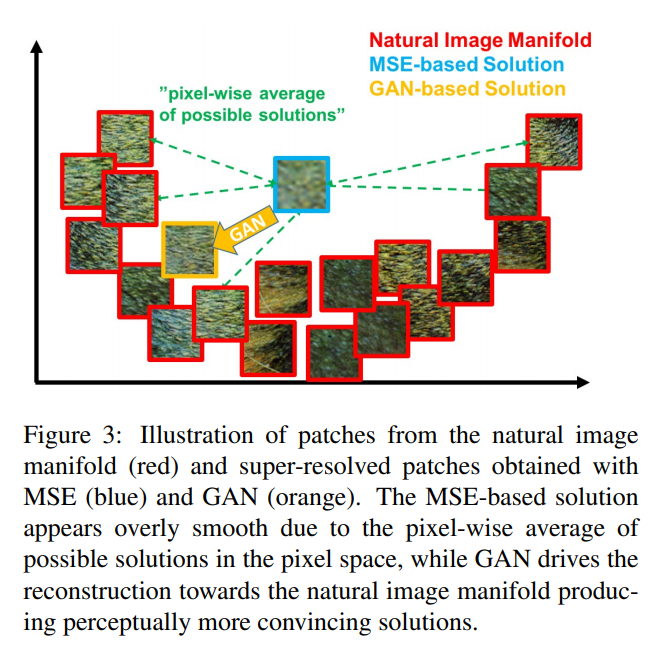
기존의 MSE loss function은 pixel wise 차이의 평균값이다.
즉, smooth reconstruction을 위해서 high texture detail이 살아있는 multiple potential solution을 평균을 내기 때문에 과하게 smooth해지는 경향이 있고, 이로 인해 lost high frequncy detail를 복구하는데 어려움이 있다.
하지만, GAN은 natural image manifold로 매핑하는 것을 학습하기 때문에 더 적당한 solution이라고 볼 수 있다.
[VGG19로 부터 추출한 feature map들 간의 Euclidean Distance를 기반으로 한 loss function으로 구성했다. (pixel space 변화에 더 변하지 않는 loss)=> SR 및 artistic style-transfer에 대해 지각적으로 더 설득력있는 결과를 냈다.]
[Contribution]
MSE에 최적화된 16 block deep ResNet으로 PSNR과 SSIM으로 측정되는 high upscaling factor를 가진 SR에 대한 새로운 최첨단 기술을 설정했다.
새로운 perceptual loss를 제안했으며, 새로운 Benchmark로 제안하는 MOS test를 기반으로 한다.
[Method]
목표는 LR input으로 부터 HR image를 생성하는 Generating Function G를 훈련시키는 것이다.
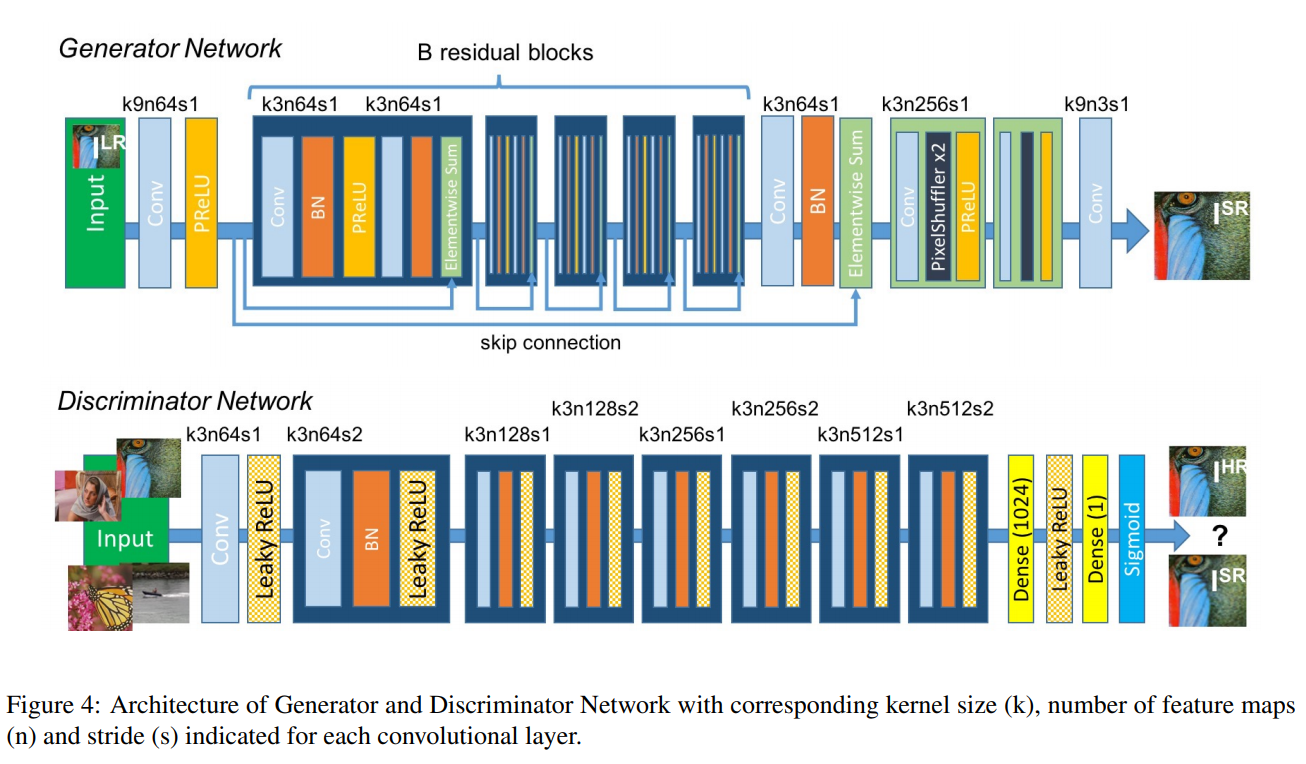
그림에서 K=kernel size, n=feature maps(channel) s=stride이다.
Generator를 먼저 본다면, LR input image를 그에 상응하는 HR image짝을 생성하도록 학습시킨다.
▶ 3x3 kernels
▶ 64 feature maps
▶ BN 적용
▶ parametricReLU (PReLU)
▶ two trained sub-pixel convolution layers를 사용 => 이미지의 해상도를 높여준다.
(CNN filter를 거치면 image dimension은 줄거나 동일한데, 여기서 pixel 수를 늘려주는 역할을 하는것이 sub-pixel인 방법이다)
![]()
[이미지 출처 : https://mathematica.stackexchange.com/questions/223504/how-to-efficiently-implement-a-sub-pixel-convolution-layer-in-a-cnn-for-image-su]
Discriminator 부분은 생성된 SR Sample과 GT를 구별하도록 학습시킨다.
▶ maxpooling을 피하기 위해서 activation function으로 LeakyReLU 사용(α=0.2)
▶ convolution layer 8개고, 3X3 filter 수가 증가하도록 설계
=> output feature map이 증가하면 잘 뽑아냈다는건가?
▶ VGG처럼 64-> 512 kernel로 2배 증가한다.
▶ feature 수가 2배 증가할 때마다 이미지 해상도를 줄이기 위해 strided convolution을 사용한다.
▶ resulting 512 feature map의 뒤에 2 dense layer와 sigmoid를 넣었다.
(sigmoid activation function을 사용하여 sample classification의 확률을 얻는다.)
[perceptual loss function]
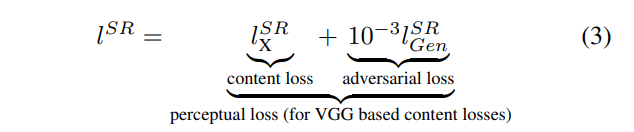
perceptual loss는 content loss와 adversarial loss를 합친 것이다.
[content loss]
pixel-wise MSE loss는 high PSNR을 얻을 수 있지만, 너무 smooth하게 되기 때문에 VGG loss를 사용한다.
=> VGG 19 model을 사용하여, SR image와 HR image의 VGG 모델 내의 feature map의 차이를 loss로 이용한다.
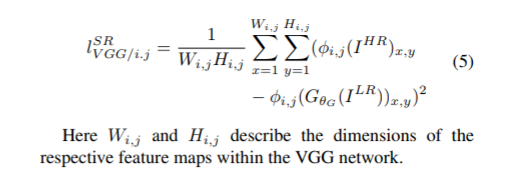
(즉, 논문에서는 pretrain된 VGG19의 ReLU를 기반으로 feature map에서 LR 이미지와 HR간의 Euclidean Distance를 구함으로써 content loss를 구성한다.)
[Adversarial loss]
GAN의 generative componenet를 추가했다.
Adversarial loss는 Discriminator가 low resolution에서 생성된 이미지를 Natural High Resolution image라고 구별할 확률을 기반으로 정의한다.
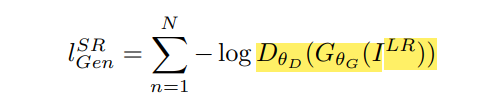
노란색으로 색칠된 부분이 G가 만들어낸 이미지가 natural HR image일 확률이며,
더 나는 gradient를 위해서 -log~부분를 minimize하여 사용한다.
(=기본적으로 log(1-x)는 초기 gradient가 flat한 경향이 있어서 역으로 바꾼 -log x를 사용하는데, 이렇게 되면 gradient 초기값이 크게 되어 학습이 더 잘된다.)
[Experiments]
dataset : Set5, Set14, BSD100 (testing set : BSD300)
train dataset : ImageNet에서 350000개로 random 추출
4 scale factor로 했으며, PSNR, SSIM의 공평한 측정을 하기 위해 중앙 crop
optimizer : Adam (β=0.9)
learning rate : 0.0001 => 0.00001로 update
Generator : 16개의 동일한 Residual block으로 구성
test : BN off
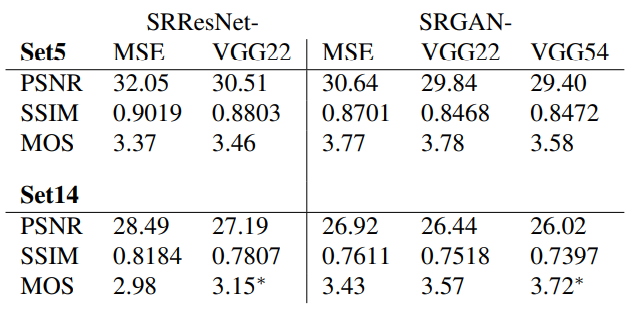
PSNR, SSIM은 SRResNet에 비하면 낮은 편이지만 MOS 평가에서 높은 점수를 받은 것을 확인할 수 있다.
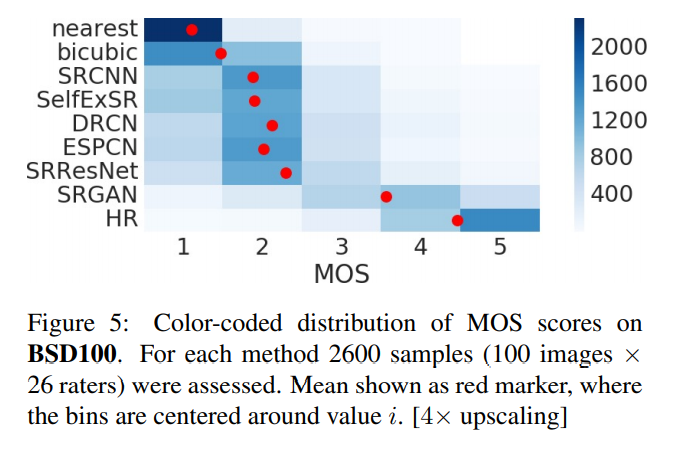
MOS 결과를 봤을 때 SRGAN이 HR을 가장 잘 구현했다고 할 수 있다.

