[Paper Review] Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks("DCGAN")
[Abstract]
Computer Vision 분야에서 CNN을 이용한 지도학습 방법은 많이 채택되어왔다.
이 논문에서는 지도학습과 비지도 학습간의 격차를 줄이기 위해 사용(?
CNN을 비지도학습에 적용하는 Deep Convolutional Generative Adversarial Networks를 소개하고 있다.
[Introduction]
GAN을 학습시켜 좋은 이미지의 결과를 얻는 것이 목적이지만, 종종 불완전한 결과물이 나오기도 한다. 또한 지금까지 연구는 GAN의 학습과정을 시각화한 연구가 매우 제한적이어서, 이 논문은 아래와 같이 기여(? 했다고 한다.
- Convolution을 GAN에 결합한 구조로 이를 DCGAN이라고 명명했다.
- 다른 비지도 학습 알고리즘과 비교하기 위해서 이미지 분류 과제에 학습되었던 Discriminator을 사용했고, 이렇게 학습된 Discriminator가 다른 학습 알고리즘과 비교하여 비등한 이미지 분류 성능을 보여준다.
- GAN의 학습 과정에서 필터들을 시각화할 것이고, 특정 filter들이 이미지의 특정 물체를 학습했다는 것을 보여준다.
- generator가 벡터 산술 연산이 가능한 성질을 갖고 이것을 semantic 수준에서의 sample generation을 해볼 수 있다.
[Related Work]
비지도 학습의 예는 다음과 같다.
- Clustering (ex, K-means)
- Auto-encoder
- Ladder structure
이미지 생성 모델은 두가지 범주로 구분되는데, Parametric 과 Non-Parametric이다.
(간단하게 정리한 Parametric& Non Parametric : https://velog.io/@ghgh5317/ParametricNon-Parametric-Model)
[Non-parametric]
다음과 같은 기술에 사용된다.
- Texture Synthesis
- Super Resolution
- In Painting
[Parametric]
이미지 생성을 위한 Parametric 모델들은 광범위한 분야에 대해 연구되었다. 하지만 아직까지 현실의 자연스러운 이미지를 생성해내는 것은 최근까지도 성공적이지 못하다.(2015년 기준)
GAN에 의해 생성된 이미지는 노이즈와 이해 불가한 문제에 대한 단점이 있다.
모델에서 fully connected layers를 제거하고, Global average pooling을 사용했다.
⇒ But 실험 결과 모델의 안정성은 증가했는데, 수렴 속도는 저하됐다.
[Approach And Model Architecture]
이 모델은 LAPGAN을 motivated했으며, CNN 구조를 활용했다.

-
max pooling과 같이 미분이 되지 않는 부분을 convolution으로 대체하여 all convolutional net을 사용했다.
-
Fully connected layer들을 제거했다. ⇒ FC layer를 사용하게 되면 parameter가 늘어나니까 속도에 영향을 주기 때문에?
global average pooling을 사용했는데 모델의 안정성은 증가했으나 수렴속도는 저하됐다.
-
generator와 discriminator에 BN을 사용했다. 단 모든 layer에 BN을 추가하면 문제가 발생하여, Generator의 output layer와 discriminator의 input layer에는 BN을 넣지 않는다.
⇒ BN 사용을 하게 되면 하나의 동일한 이미지로 만들어지는 mode collapsing문제를 예방하는데 도움이 된다. But 모든 layer에 사용하면 sample oscillation과 model instability 문제가 발생한다(무슨 문제,,,지?
-
ReLU를 사용했는데, generator에는 ReLU를 사용하는데 output에서만 Tanh을 사용했다.
discriminator에서는 **leakyReLU**를 사용하였다.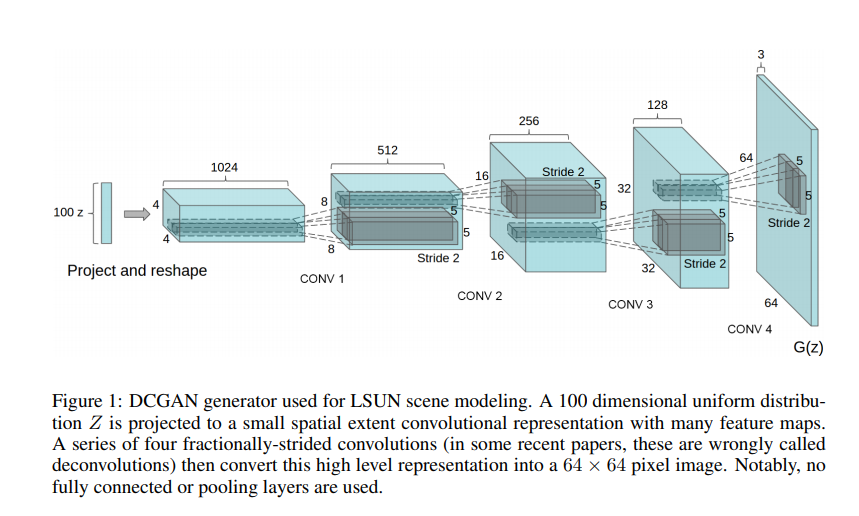
DCGAN generator Architecture
[Details of Adversarial Training]
Dataset은 3개 사용했다.
- LSUN (Large Scale Sence Understanding)
- FACES
- IMAGENET-1k
이미지에 대해서는 별도의 전처리를 하지 않았다.
- Mini batch SGD (batch size 128)
- 정규 분포(평균 0, 표준편차 0.02)로 가중치 초기화
- AdamOptimizer (lr=0.001 → 0.0002로 내리고, momentum=0.9 → 0.5 (학습안정화))
[LSUN]
침대 사진들이 모여있는 dataset이다. 그림에 나와있는 Generator 구조를 사용했으며, fully connected나 pooling layer는 사용하지 않았다.
중복된 그림 275000장을 제외하면 꽤 성능적으로는 괜찮다고 생각한다고 한다.

LSUN epoch 1

LSUN epoch 5
[FACES]
web에서 random image들을 받아와서 근대에 태어난 사람 얼굴을 모은 dataset이다.
만명의 사람들의 얼굴로 총 3백만장으로 구성되어있다.
[IMAGENET-1k]
DCGAN으로 학습시킨 후 discriminator의 feature를 가져다가 K-means classification을 하니 state-of-art의 결과와 비등한 정도의 정확도를 보인다.
[Empirical Validation of DCGANs Capabilities]
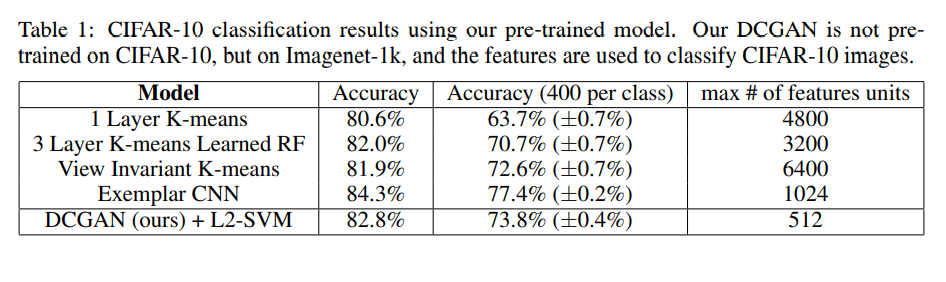
DCGAN은 CIFAR-10 기반이 아닌 ImageNet-1k로 fine-tuned 됐다.
아직 표를 보면 CNN에 미치지는 못한다.
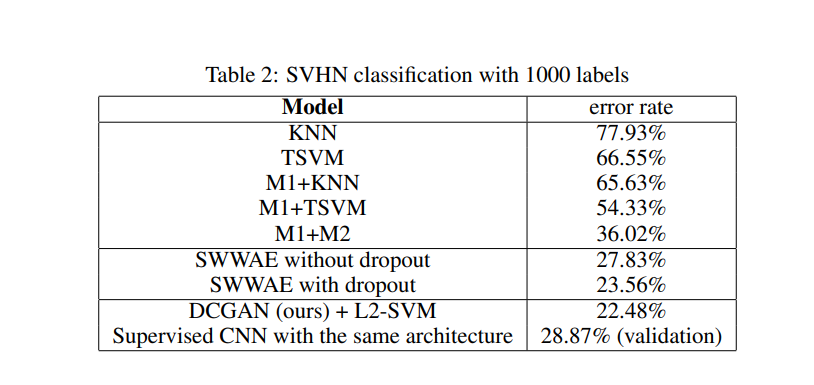
또한 SVHN Dataset을 사용하여 다른 모델과 비교했을 때 DCGAN의 에러율이 제일 낮았다.
[Investigating and Visualizing The Internals of The Networks]
학습된 generator 와 discriminator를 Visualizing 해준다.

학습된 Generator의 input값인 z값을 조금씩 바꿔가면서 생성되는 output이미지가 어떻게 바뀌는지를 확인한 그림이다.
이미지의 변화가 확 바뀌게 되면 training sample을 학습했다기보단 기억하고 있는 것으로 볼 수 있는데, 변화가 부드럽게 일어나게 된다면 이미지 생성에 있어서 객체를 추가하거나 제거하는 변화를 줄 수도 있다.
따라서 위의 사진을 보면 벽에서 창문으로 서서히 변해가거나, TV가 창문으로 변해다는 것으로 학습하고 있다는 것을 확인할 수 있다.

CNN이 black box model이라고 하여 안이 어떻게 돌아가는지 지적을 받고 있었는데 DCGAN은 네트워크의 내부가 어떻게 실행되는지를 보여줍니다.
Backpropagation을 사용해서 discriminator에 의해서 학습된 feature가 침대나 창문과 같은 침실의 특정한 부분에서 활성화가 되는 것을 보여준다.
또한 generator에서 창문을 완전히 제거하려고 실험을 해보았고(150개 sample data에 52개의 창문에 bounding box를 그렸고, 창문이 있는지 없는지 예측하기 위해 fitting되었다.)
실험을 해보았을때 네트워크는 실제로 창문을 만들어내지 않고 다른 것으로 대체했다.

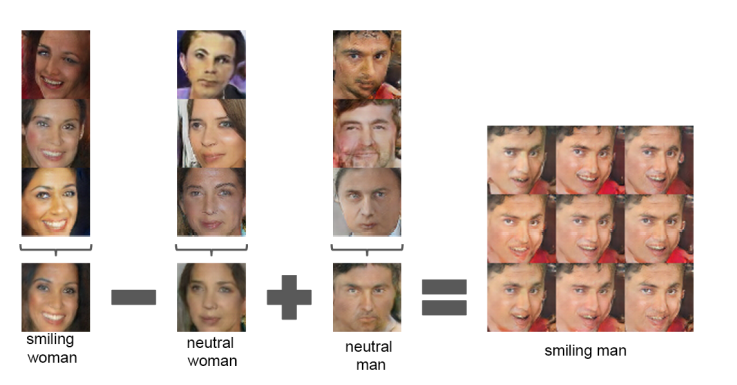
[Vector arithmetic on face samples]
word embedding에서 King-man+woman을 하면 "queen"이 나오는 것처럼 이미지에서도 벡터 연산이 가능하다는 것을 보여줬다.
z를 이용하여 연산이 의미적으로 작용하는 것을 보여준다.
또한 보간을 사용하여 왼쪽 방향을 보고 있는 얼굴에서 오른쪽을 보고 있는 얼굴로 바꿀 수 있다.
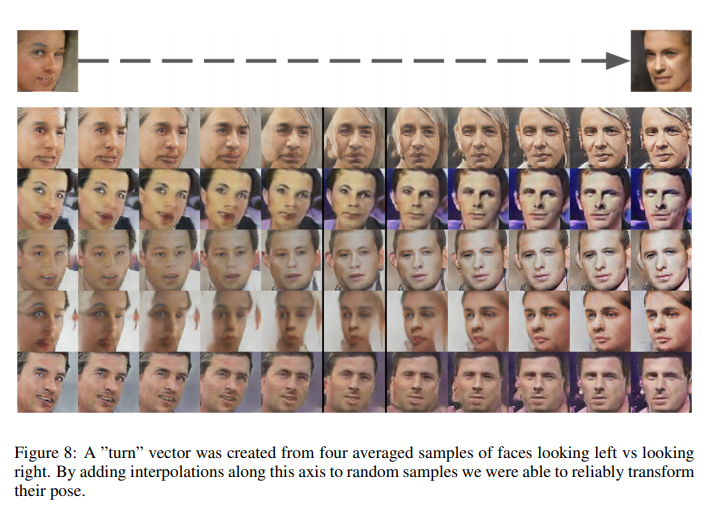
이는 왼쪽 얼굴을 만들어내는 input 값의 z평균값과 오른쪽 얼굴에 대응하는 z의 평균값을 계산하고 두 벡터 사이를 잇는 축을 interpolating 하여 Generator에 넣었더니 회전하는 얼굴이 나오는 것을 확인할 수 있다.
이를 통해 네트워크가 scale, rotation, position 등에 대해 이해하고 있는 것을 확인할 수 있다.
