개념
판다스에서는 두 가지 핵심 데이터 구조(data structure)을 사용한다.
(데이터 구조 : 다양한 종류의 데이터 형식(Data type)이 모여 있는 객체이다.)
- Serise 여러 개의 레이블과 그 값을 들고 있는 일차원 배열
- DataFrame 데이터 테이블. 여러 개의 컬럼을 갖고 있으며 각각의 컬럼은 다른 데이터 형식의 값들을 담고 있을 수 있다. 행과 열이 있고, Serise 모음이다.
판다스 데이터 구조(data structure)
시리즈 Serise
- 판다스에서 시리즈는 여러개의 레이블이 있는 값을 들고 있는 일차원 배열이다. 판다스 시리즈에서 데이터 레이블은 인덱스라고도 불린다
import pandas as pd #판다스는 주로 pd라는 이름으로 불러온다.
obj = pd.Series([4, 7, -5, 3])
obj
Serise를 출력하면 왼쪽에 인덱스, 오른쪽에 값이 표시된다. 위 예시에서는 레이블을 입력하지 않았기 때문에 디폴트 0부터 시작하는 숫자가 레이블 된다.
- 값을 보고자 한다면 .values 속성을 사용하면 된다.
obj.values
→ 판다스가 내부적으로 값을 저장할 때 numpy array를 쓰는 것을 알 수있다.
- .index 속성은 RangeIndex를 보여준다.
obj.index
→ [ 0부터, 4까지, 1씩 증가 ]하는 정보를 반환한다.
- 레이블(index)을 지정해서 시리즈를 만들 수 있다.
obj2 = pd.Series([4, 7, -5, 3], index=['d', 'b', 'a', 'c'])
obj2
여기서 인덱스(레이블)와 값의 개수는 동일해야 한다. 개수가 다르다면 에러 난다.
- 딕셔너리처럼 시리즈도 인덱싱할 수 있다. 이 때, 레이블(인덱스)가 ‘키’ 역할을 한다.
obj2['a'] -> -5따라서 딕셔너리로 시리즈를 만들 수 있다.
sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
obj3 = pd.Series(sdata)
obj3
- 딕셔너리에서 특정 쌍만 시리즈로 만들고 싶다면 인덱스(레이블)를 지정할 수 있다.
states = ['California', 'Ohio', 'Oregon', 'Texas']
obj4 = pd.Series(sdata, index=states)
obj4
값과 인덱스의 길이는 같지만, California 인덱스에 해당하는 값은 없기 때문에 NaN(Not a Number) 발생한다. 이는 결측치(missing data)를 나타내기 위해 pandas에서 가장 자주 쓰이는 방식이다.
- 판다스는 결측치를 검사하는 방법도 제공한다.
pd.notnull(obj4)
obj4.notnull()
pd.isnull(obj4)
obj4.isnull()
- 시리즈끼리 더하거나 빼는 등의 연산을 할 수 있다. 같은 레이블(인덱스)에 해당하는 값끼리 연산 가능.
- 시리즈와 그 인덱스에 이름을 붙일 수도 있다.
obj4.name = 'population'
obj4.index.name = 'state'
obj4데이터프레임(DataFrame)
데이터프레임(DataFrame)은 직사각형 모양의 데이터 테이블을 나타내고 컬럼으로 이루어져 있다. 데이터프레임은 시리즈의 모음으로 생각할 수 있다.
데이터프레임은 데이터 분석에서 가장 자주 쓰이는 데이터 구조이다.
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002, 2003],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]}
frame = pd.DataFrame(data)
frame
- 데이터프레임이 너무 클 때는, 데이터의 일부분만 보는 것이 좋을 때도 있다. 이때, 데이터프레임의 앞의 일부만 보기 위해 head라는 메서드를 쓸 수 있다. head에 숫자를 안주면 5개만 보여준다.
frame.head(3) # 앞 부분의 3개만 보여준다.
frame.tail(3) # 뒤에서 3개만 보여준다.- 데이터프레임에서 사용할 컬럼과 그 순서를 지정할 수 있다.
pd.DataFrame(data, columns=['year', 'state', 'pop'])
- 컬럼 뿐 아니라 사용할 인덱스까지 지정할 수 있다. 해당하는 인덱스가 없다면 NaN이 된다.
frame2 = pd.DataFrame(data, columns=['year', 'state', 'pop', 'debt'],
index=['one', 'two', 'three', 'four', 'five', 'six'])
frame2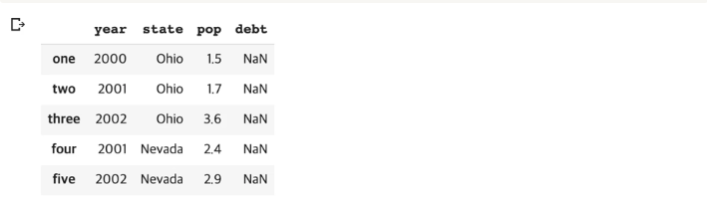
- 데이터프레임에서 컬럼은 다음과 같은 방식으로 접근 가능하다. 데이터프레임의 컬럼은 시리즈 데이터 구조이다.
frame2['state']
frame2.state #둘 다 동일한 방법이나, 컬럼이름에 띄어쓰기가 있다면 위의 방법으로만 컬럼을 가져올 수 있다. 
- 데이터프레임의 행은 loc이라는 메서드로 접근할 수 있다. 아래같이 행(row)을 시리즈로 보여준다.
frame2.loc['three']
- 컬럼에 새로운 값을 집어넣어 변경할 수 있다.
frame2['debt'] = 16.5
frame2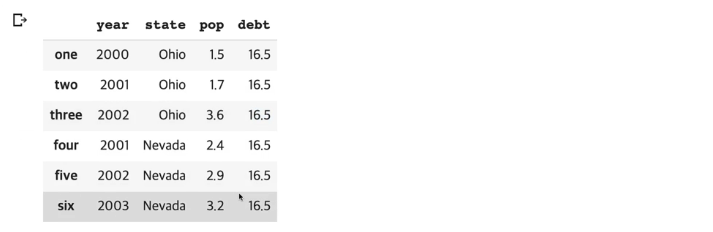
- 이렇게 전체 같은 값을 줄 수도 있지만, 특정 컬럼에만 값을 줄 수 있다.
val = pd.Series([-1.2, -1.5, -1.7], index=['two', 'four', 'five'])
frame2['debt'] = val
frame2
- 존재하지 않는 컬럼에 할당(assign)해서 새로운 컬럼을 만들 수 있다.
frame2.state == 'Ohio' # 먼저 값이 Ohio만 True가 나오게 한다.
frame2['eastern'] = frame2.state == 'Ohio'
frame2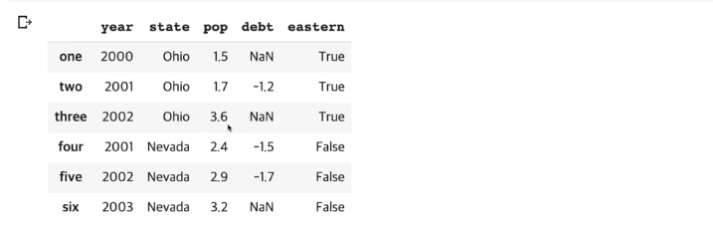

날마다 꾸준히 성장하는 Software Engineer