
ABSTRACT
현재 NLE모델들은 VISION또는 VISION-LANGUAGE모델(예를들어 VQA)의 DECISION MAKING 과정을 LANGUAGE 모델(GPT같은)을 이용하여 설명한다. 이 경우 TASK 모델에 추가적인 메모리 자원과 추론시간이 필요하다. TASK모델과 설명 모델이 독립적이기 때문에 정답예측의 REASONING 과정과 설명이 일치하지 않을 가능성도 있다.
저자는 동시에 정답과 설명을 동시에 예측하는 COMPACT하고 신뢰성 높은 언어 모델인 NLX-GPT를 제안하였다. 우선 이미지의 GENERAL한 이해를 위해 대규모의 IMAGE-CAPTION쌍 데이터를 PRE-TRAIN하였고 그 다음 TEXT형식의 정답과 설명 예측을 생성하였다.
NLX-GPT는 적은 파라미터 수로 현재 SOA 모델보다 15배 빠른 결과를 도출한다. 논문 끝에는 EXPLAIN-PREDICT과 RETRIEVAL-BASED ATTACK라는 2가지 평과 방법을 제안한다.
1.INTRODUCTION
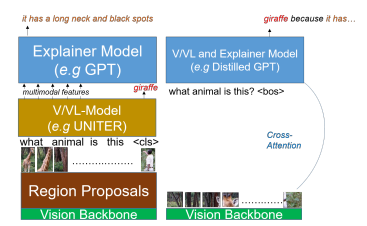
기존 NLE모델은 VL모델을 활용해 TASK의 정답을 얻어낸다(예를 들어 VQA). VL모델의 OUTPUT은 언어 모델(예를 들어 LSTM, TRANSFORMER)로 들어가서 정답에 대한 설명을 얻는다.
TRAINING에서 언어 모델은 NLE DATASET으로 설명 생성을 TRAIN한다. TEST에서는 VL모델의 OUTPUT은 언어 모델(예를 들어 LSTM, TRANSFORMER)로 들어가서 정답에 대한 설명을 얻는다.
이러한 모델은 2가지 단점이 존재한다.
TASK모델의 추가는 메모리 단점이 존재한다. 일반적으로 작은 모델은 80M, 큰 모델은 300M의 파라미터를 필요로 한다.또 다른 단점으로는 VL모델과 언어 모델이 서로 정답으로 설명을 생성하는 과정이 단절되어있다. 때문에 설명 생성에서 CORRECTNESS, REASONING, SEMANTIC MEANING을 반영하지 못한다.
2.RELATED WORK
DATASET
ACT-X:ACTIVITY RECOGNIZATION 모델의 결정을 설명하는데 사용된다.
VQA-X:VQA모델의 결정을 설명하는데 사용된다.
..
3.NLX-GPT

Mt:TASK MODEL Me: explanation model
NLX-GPT는 Mt를 제거하고 Me가 정답을 내고 설명까지 도출하는 작업을 한다.
NLX-GPT에서 Mt를 distilled version의 GPT-2 LANGUAGE MODEL을 선정하였다. NLX-GPT는 인코더-디코더 구조이다. 인코더는 VISUAL BACKBONE으로 이미지를 인코딩하고 디코더는 DISTILLED GPT-2이다.
질문/가설, 정답, 설명을 하나의 SEQUENCE로 Me입력하고 CROSS-ENTROPY로 SEQUENCE를 생성한다. 해당 SEQUENCE는 정답과 설명을 동시에 포함하고 SEQUENCE W는 w = w1, w2, . . . , wT of T words임.
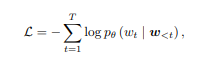
W<t는 t번째 단어 이전까지의 단어들을 뜻한다.
배경지식
Bottom-Up and Top-Down Attention for Image Captioning and VQA
이미지를 이해하는 2가지 방식
Top-down 방식: 이미지 전체를 보고 그 이미지에서 Task에 걸맞는 특징을 찾는 방법
Bottom-up방식: 이미지의 픽셀 단위부터 조금씩 파악하여 특징을 찾는 방식
https://woosikyang.github.io/Bottom-Up-and-Top-Down-Attention-for-Image-Captioning-and-VQA.html
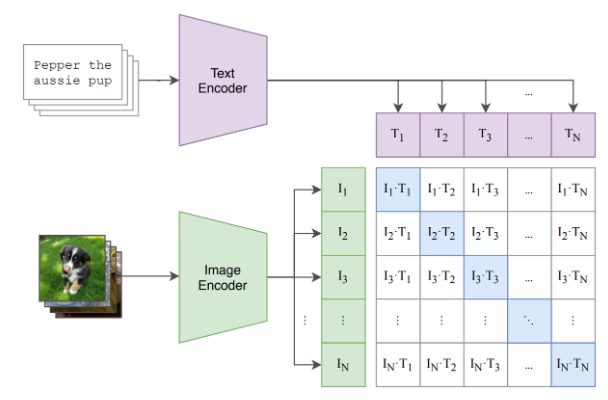
특정 작업(예를 들어 이미지 분류)에 편향된 인코더와 time-expensive한 bottum-up feature에서 벗어나고자 CLIP vision encoder를 활용한다. CLIP의 contrastive learning으로 VISUAL FEATURE이 (1)non-bias하고 일반적인, (2)GPT-2의 LANGUAGE EMBEDDING SPACE와 가까워짐. 이로 시각과 언어 정보가 잘 융합된다고 본다.
zero-shot
모델이 학습 과정에서 배우지 않은 작업을 수행하는 것, 예를들어 셰익스피어처럼 글을 쓰도록 학습한 자연어 생성 모델이 마크 트웨인의 스타일로 글을 쓰는 것
clip
https://simonezz.tistory.com/88
이제까지의 SOTA의 Computer vision 시스템들은 미리 정의된 카테고리의 데이터셋에 대해서 예측하도록 훈련되어 왔다.
이런 supervision방식은 generality와 usability를 한정짓게 된다. 다른 visual concept을 특정화지으려면 추가적인 라벨링된 데이터가 필요하기 때문이다.
이에 대한 대안으로는 Raw text로부터 바로 이미지에 대해 러닝하는 것이 있다.
실제 쌍의 이미지 임베딩과 텍스트 임베딩의 코사인 유사도를 최대화하고 나머지는 작게되도록 이미지 인코더와 텍스트 인코더를 같이 학습한다.
resion proposal과 vl-model이 없어 빠르고 메모리 효율적이 되었다.
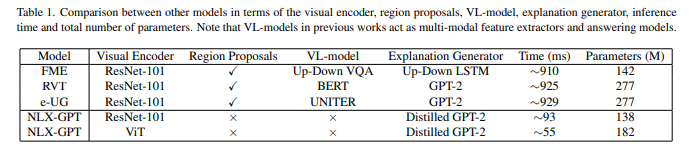
bottum up feature없이도 이전 모델보다 성능이 뛰어났고 bottum up feature을 사용하면 추가적인 bert-based multimodal feature extractor(UNITER같은)없이도 SOA모델보다 성능이 뛰어났음.
앞으로 2단계인 PRETRAINING과 FINETUNING으로 MODEL에 대해 설명을 한다. VISUAL ENCODER는 PRETRAINING과 FINETUNING에서 고정되어 FINE-TUNE되지않는다.
3.1 PRETRAINING
Distilled GPT-2를image-caption쌍으로 pre-train하고 NLE 데이터셋으로 FINETUNE
ABOUT GPT-2: https://amber-chaeeunk.tistory.com/98
NLE모델이 오버피팅 되지않고 정답에 대한 설명을 적절히 수행하기위해서는 우선 이미지에 대한 이해가 필수적으로 요구된다. vision-language pretraining의 트렌드에 따라 NLX-GPT도 large-scale의 image-caption쌍으로 Distilled GPT-2를 pre-train함. image caption을 pre-train task로 선정한 이유는 (1)downstream task of text generation와 일치하고 (2) image caption이 이미지 속 물체간 속성과 관계에 대한 이해를 제공하기 때문이다. COCO caption, Flickr30k, visual genome (VG), image paragraph captioning의 데이터를 사용하였음. model이 이미지 I를 설명하는 caption C를 생성하는것을 train하는데 아래 cross-entropy 목적함수를 사용하였다.
APPENDIX
3.2 concept detection
e-SNLI-VE데이터 셋에서는 pre-training이 도움이 되지않는걸 발견하고 이미지 이해를 돕기위해서 visual encoder의 상단에 mlp를 추가하였고 denome데이터셋으로 학습함.오차함수로 binary cross-entropy를 사용하였다.
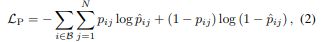
N은 concept vocabulary이다.pij는 b배치에서 i번째 데이터포인트의 j번째 타겟이다. concept을 GPT-2의 인풋으로 집어넣음.
vision transfomer개념 필요, https://wikidocs.net/137253
appendix:H, W, P, Y가 높이, 너비, patch size, 이미지의 전체 patch
3.3 FINETUNING
pretrain이후 NLX-GPT를 nle task에 대해서 finetune한다. VQA-X, e-SNLI-VE, VCR, ACT-X의 데이터를 이용함(각 데이터마다 DOWNSTEAM TASK가 명확히 존재,SECTION 4에서 각 데이터셋에대한 설명함
input sequence는 question, answer, explanation이고 각 token은 embedding layer로 들어간다.
3.4 evalution measures
1.natural language generation(nlg) metric
2.human evalution
논문에서 2개의 새로운 automatic evalution measures를 제안함
1.explain predict
설명이 정답을 얼마나 정당화하는지를 측정한다.language representation 모델에 질문을 인풋으로 넣고 설명을 생성하고 정답을 예측하도록 한다. 해당 측정은 정답과 설명의 연관성을 측정이 가능하다. 여기서는 DistilBERT를 language representation 모델로 선정함
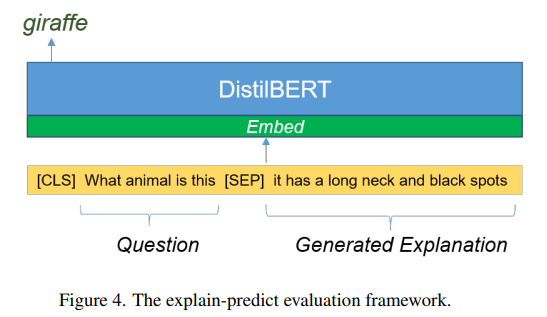
cls토큰의 출력인 sep를 classification layer의 input으로 취한다. 그림4의 예시를 보면 질문인 cls토큰과 질문에 대한 설명인 sep토큰을 DistilBERT의 input으로 집어넣었더니 설명을 적절히 정당화하는 정답 'giraffe'가 나옴을 볼 수 있다.
2.retrieval-based attack
모델이 얼마나 데이터셋에 얼마나 연관되고 편향되있는 정도를 비슷한 input으로 attack하여 측정한다.
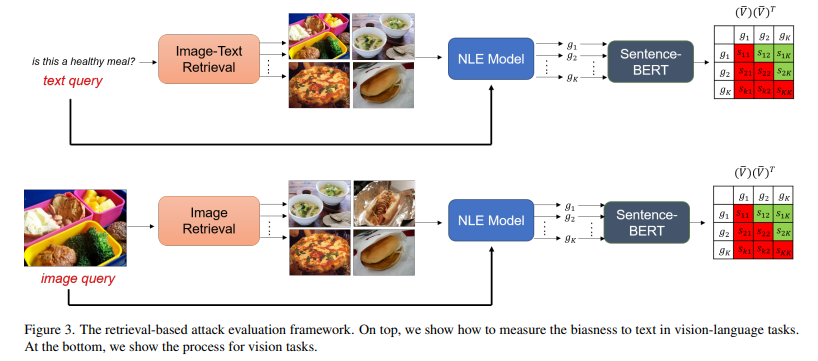
text를 query로 설정하고 해당 text query에 가까운 유사한 k개 이미지들을 검색한다. 이때 이미지들에 같은 질문을 했을때 같은 설명을 생성해낸다면, 그것은 같은 reasoning에 의한것이 아닌 데이터에 대한 correlation과 bias에 의한것으로 생각해볼 수 있다.
NLX-GPT에 질문은 고정하고 k개의 이미지에 대한 설명을 생성한다. G = {g1 . . . gK}는 설명들이고 이를 language representation model에 넣어 x V ∈ R
K×d, encoded vector representation을 얻는다. d는 encoded representation의 차원이다. 각 샘플간 average cosine distance를 위한 연산으로 v¯k = vk/kvkk2, ∀k = 1, . . . , K L2 norm을 하고 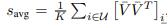
다음 식을 통해 average cosine distance를 얻음(그림에서 초록부분). distance가 낮다면 bias또한 낮게된다. 논문에서는 BERT mode을 대조적인 setence쌍으로 fine-tune한 Sentence-BERT를 language representation model로 선정하였다. retrieval model로는 CLIP을 선정하였다. 이 evaluation framework는 ground-truth labels이 필요없다(장점).
vision tasks에서는 image-retrieval model을 이용해 유사한 이미지를 검색하고 나머지 과정은 앞과 동일하게 진행한다.
4.experiments and result
데이터셋 설명
e-SNLI-VE: SNLI는 visual-textual entailment(VTE)의 데이터셋이다. e-SNLI-VE는 SNLI-VE-2.0에서 e-SNLI의 HUMAN-WRRITEN EXPLANATION을 합친 버전이다. LABEL에 ENTAILMENT,CONTRADICT, NEUTRAL 3가지가 있다. 이미지는 Flickr30k로부터 얻음
https://arxiv.org/abs/2004.03744

VQA-X: VQA-X의 설명은 질문과 정답에 초점을 맞춤
ACT-X: activity에대한 데이터, “I can tell the person is doing (action) because..”로 설명을 한다.

evaluate NLE with automatic NLG metrics
1.데이터셋에 대한 설명을 예측된 정답이 참/거짓인지 상관없이 평가하기. 저자는 이를 'unfiltered'된 variant라한다.
2. 예측된 정답이 참인것에 대해서만 설명을 살펴보기. 이는 정답이 거짓이면 설명또한 거짓이라 추정하는것. 저자는 이를 'filtered'된 variant라한다.
두가지 방법을 모두 이용하여 평가를 진행한다.
4.1 Quantitative Analysis
기존의 평가 방식에 의한 성능비교
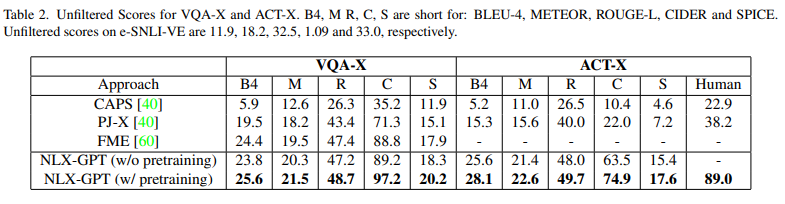
table2: VQA-X and ACT-X 데이터셋에서 NLX-GPT가 뛰어난 성능을 보임
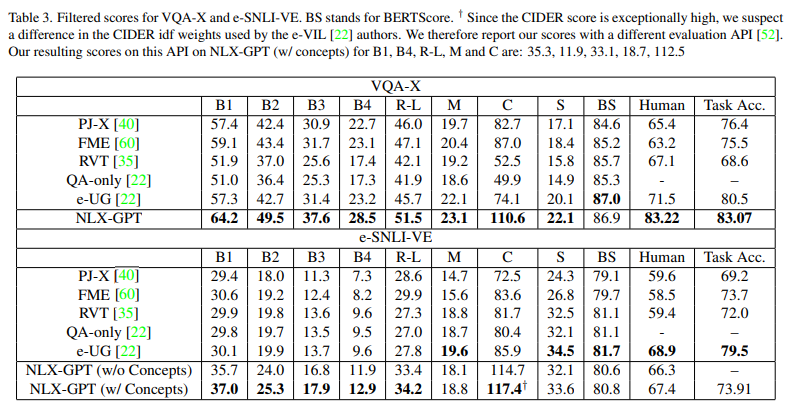
table3: 결과적으로 메모리 효율적이고 빠르고 성능또한 우수하다.
task accuracy가 추가되었는데 모든 가능한 ground-truth answers set에 answer가 포함되어있으면 corrcet하다고 판단함.
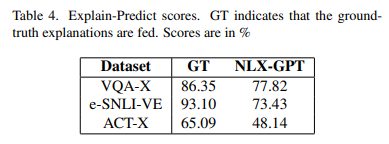
table4: 논문에서 제안한 Explain-Predict 방법에 따른 score. GT는 ground-truth explanation을 집어넣었을때의 score이고 이를 통해 top-performing score를 보여줌.
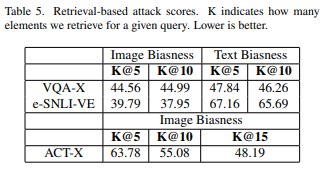
table5: retrieval-based attack의 결과를 보여준다.모든 test dataset에서 intra-distances scores를 평균내서 게산을 하였고 k는 retrieve한 수를 의미한다.
4.2 qualitative analysis

예측한 정답 attention map을 시각화한것.

그림6을 통해 pretrain하고 안하고의 차이를 확인할 수 있음. pretrain한 경우 정확한 정답과 그에 대한 설명을 위해 어떤 조건을 봐야하는지를 안한 경우보다 더 잘 본다.

NLX-GPT의 qualitative results
appendix
4.3 ablation studies
-
pretrainingr(VQA-X와 ACT-X)또는 concept detection(e-SNLI-VE)이 성능에 얼마나 영향을 주는지는 table2,3에서 확인함
-
서로다른 image encoders들을 사용했다. table6는 이에 대한 성능 차이를 보여준다.
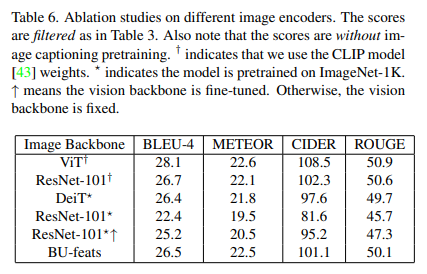
CLIP vision transformer에서 가장 좋은 성능을 보였다. table6의 score는 image-caption pretraining없이 도출된것이다.
5.limitaions
e-SNLI-VE task에서 automatic NLG metrics인 METEOR, SPICE and BERTScore에서는 score가 낮게 나왔다. NLX-GPT가 e-SNLI-VE에서 N-gram(BLEU, ROUGE)와 human consensus(CIDER)에 대해 다른 metric보다 더 큰 비중을 둔다. 다른 NLE models에서는 e-SNLI-VE task에서 둘중 하나에만 더 큰 비중을 두지만 NLX-GPT의 경우는 둘 다에 비중을 둔다.]
6.future direction
distillation, NLP tasks를 목적으로 하는 g NLE datasets활용하기(더 큰 규모)로 더 좋은 성능의 language understanding models을 만들고자함
