안녕하세요! 이번에는 SELECT으로 데이터베이스에서 조회를 실행할 때 *이 아닌 필요한 컬럼만 설정하는 것이 왜 필요한지에 대해서 적어보겠습니다. 이 방법은 쿼리의 성능을 최적화 할 때 가장 먼저 고려해보는 부분입니다. 데이터베이스(MySQL)의 동작 원리에 대해서 알아보고 왜 필요한 컬럼만 조회하는 것이 성능 향상에 영향을 주는지 알아보겠습니다. 다른 의견이나 잘못된 내용이 있다면 알려주세요 :)
데이터베이스는 MySQL 5.7을 사용했습니다.
인덱스와 정렬
데이터를 조회하는 쿼리를 작성할 때 일반적으로 인덱스를 이용하도록 쿼리를 작성하고 SELECT 쿼리에 정렬은 필수적으로 작성한다고 합니다.
테이블에 인덱스를 적용하고 인덱스로 설정된 컬럼이 포함되도록 쿼리를 작성하게 되면 조회 성능이 증가합니다. 개발자가 설정한 인덱스를 더 효율적으로 사용하기 위한 SELECT절 튜닝에 대해 알아보겠습니다. 또한 MySQL에서 쿼리에 정렬 조건이 포함되었을 때 정렬 작업의 동작 원리에 대해 살펴보고 효율적인 쿼리를 작성하는 방법에 대해서 알아보겠습니다.
Using Index(커버링 인덱스)
먼저 인덱스를 사용할 때 커버링 인덱스가 되도록 쿼리문을 작성하면 더 빠르게 데이터를 조회할 수 있습니다. 커버링 인덱스가 무엇인지, 어떻게 쿼리를 작성해야 하는지에 대해서 알아보겠습니다.
커버링 인덱스
커버링 인덱스란 데이터 파일을 전혀 읽지 않고 인덱스만 읽어서 쿼리를 처리할 수 있는 것입니다. MySQL의 인덱스의 종류에는 클러스터드 인덱스, 논클러스터드 인덱스가 있는데 이 인덱스들을 적절히 이용하도록 쿼리문을 작성하면 더 빠른 효율을 얻을 수 있습니다. 예시 테이블은 아래와 같고 데이터는 약 30만건으로 쿼리문을 수행했습니다.
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` enum('M','F') NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`),
KEY `ix_firstname` (`first_name`),
KEY `ix_hiredate` (`hire_date`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8emp_no 컬럼은 클러스터드 인덱스(pk), first_name, hire_date 컬럼은 논클러스터드 인덱스로 등록해 주었습니다. SELECT절에서 지정한 컬럼이 다른 몇가지 쿼리문의 실행 계획과 실제 수행 시간을 비교해보면서 차이점을 알아보겠습니다.
먼저 논클러스터드 인덱스로 등록한 컬럼만 포함한 경우입니다.
SELECT first_name FROM employees
WHERE first_name BETWEEN 'Babette' AND 'Gad';위 쿼리의 실행 계획에서 Extra 컬럼을 보면 Using Index라고 표시되어 있습니다.

쿼리의 실행 계획에서 Extra 컬럼이 나타내는 값은 작성한 쿼리문의 테이블 스캔 방식, 정렬 방식 등의 중요한 정보가 담겨있습니다. Filtered 컬럼은 데이터가 인덱스에 의해 필터링된 비율을 나타냅니다.
수행시간은 대략 162ms 정도 걸렸습니다. 이 경우 WHERE 절에서 인덱스로 등록된 first_name 컬럼만 비교하고 있으므로 커버링 인덱스로 검색한 것입니다.
다음으로 인덱스로 등록하지 않은 컬럼을 포함한 경우입니다.
SELECT first_name , birth_date -- birth_date 추가
FROM employees WHERE first_name BETWEEN 'Babette' AND 'Gad';SELECT절에 birth_date라는 인덱스로 등록하지 않은 컬럼을 추가했습니다. first_name 컬럼만 인덱스가 걸려있어서 먼저 first_name으로 값을 찾고, 그 값에 해당하는 birth_date를 테이블 스캔으로 가져와야 하는 쿼리입니다. 따라서 인덱스만으로는 처리가 안되서 성능에 차이가 발생합니다. 쿼리의 실행 계획을 보면
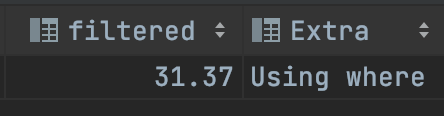
위와 같이 Using Index가 포함되지 않고 필터링된 값의 비율도 줄어들었습니다. 실행 속도 또한 629ms 정도로 늘어났습니다.
마지막으로 논클러스터드 인덱스 + 클러스터드 인덱스로 등록한 컬럼으로만 조회한 경우입니다.
SELECT first_name , emp_no -- pk 추가
FROM employees WHERE first_name BETWEEN 'Babette' AND 'Gad';
커버링 인덱스를 이용하여 검색이 수행되었고 실행 시간도 111ms 정도로 단축되었습니다.
성능 차이가 발생한 이유는 인덱스로 등록하지 않은 컬럼이 추가됨으로써 메모리에 있는 인덱스 정보만으로 쿼리 결과를 만들지 못해서 디스크로의 추가적인 I/O 작업이 발생했기 때문입니다. 만약 SELECT 절에 *로 쿼리를 작성해 인덱스에 포함되지 않은 수 많은 컬럼들을 한번에 조회하게 된다면 더 큰 성능 차이가 발생할 것입니다. 따라서 우리는 필요한 컬럼값만 SELECT 절에 포함시켜야 하고 그 값들이 빈번하게 조회가 된다면 인덱스로 등록하는 것을 고려해 봐야 합니다 :)
Filesort
정렬 기준이 포함된 쿼리를 수행할 때 MySQL의 동작 원리에 대해 알아보고 왜 SELECT 절에 필요한 컬럼만 지정하는 것이 효율적인지 알아보겠습니다.
MySQL은 정렬을 수행할 때 별도의 메모리 공간인 소트 버퍼(Sort buffer)를 할당 받아서 정렬을 수행합니다. 소트 버퍼로 디스크에서 데이터를 읽어온 후 정렬을 수행하고 만약 레코드의 건수가 소트 버퍼의 크기보다 크다면 레코드를 여러 조각으로 나눠서 처리합니다. 이때 소트 버퍼에서 수행하는 두 가지 정렬 알고리즘에 대해서 살펴보고 효율적인 쿼리 작성 방법에 대해 알아보겠습니다. 알고리즘 지칭 용어는 Real MySQL에서 나오는 용어로 설명하겠습니다. 이 용어는 공식적인 명칭은 아니라고 합니다 :)
테이블 구조는 커버링 인덱스에서 사용한 테이블이고 수행하는 쿼리문은 아래와 같습니다.
SELECT emp_no, first_name, last_name
FROM employees
ORDER BY first_name;Single pass algorithm
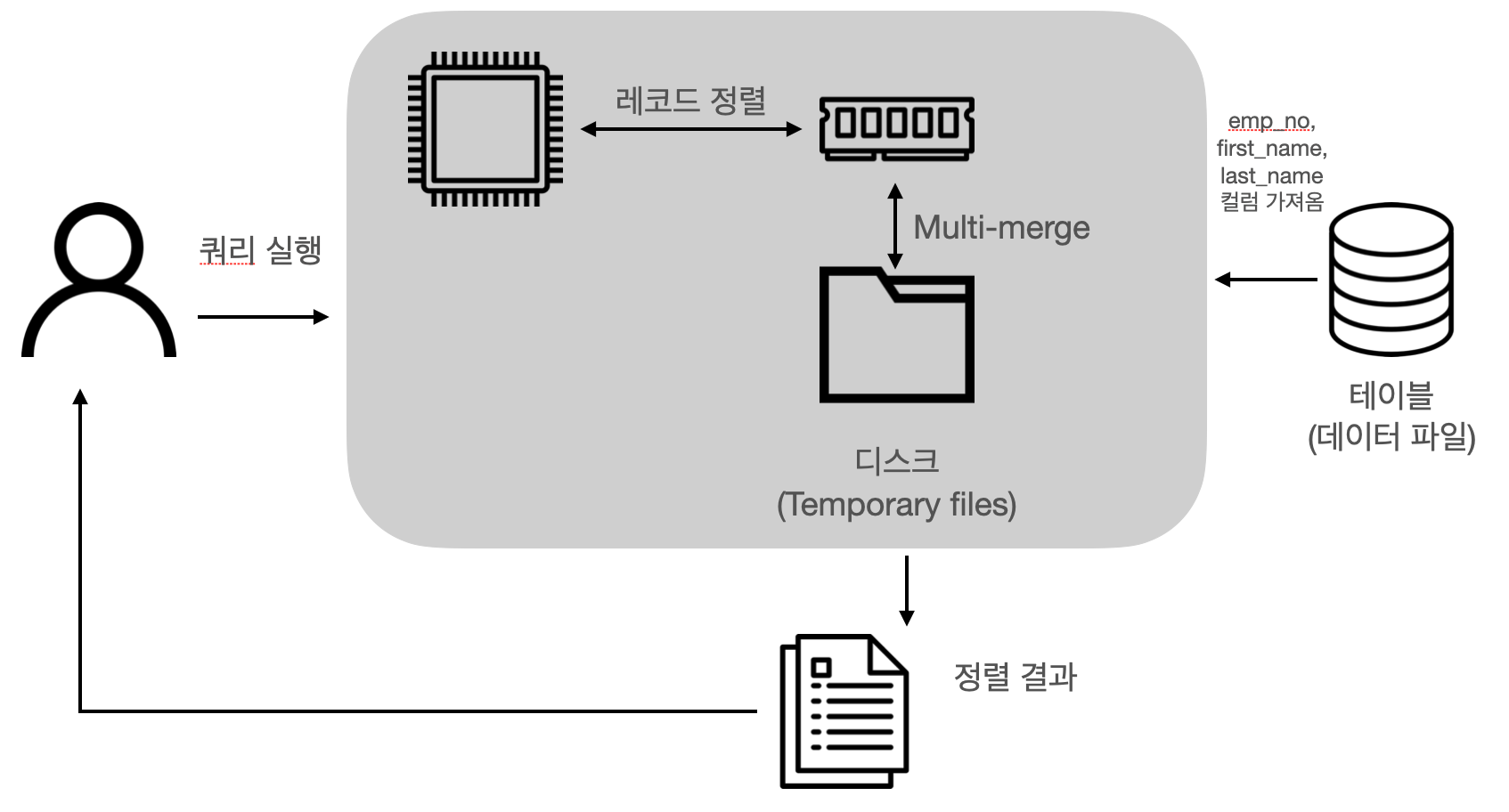
소트 버퍼에 정렬 기준 컬럼을 포함해 SELECT 되는 컬럼 전부를 담아서 정렬을 수행하는 방법입니다. 처음 employees 테이블을 읽어올 때 정렬에 필요하지 않은 last_name 컬럼까지 전부 읽어서 소트 버퍼에 담고 정렬을 수행합니다. 정렬이 완료되면 정렬 버퍼의 내용을 그대로 클라이언트로 넘겨주게 됩니다. 레코드의 크기나 건수가 적은 경우 빠른 성능을 보입니다.
Two pass algorithm
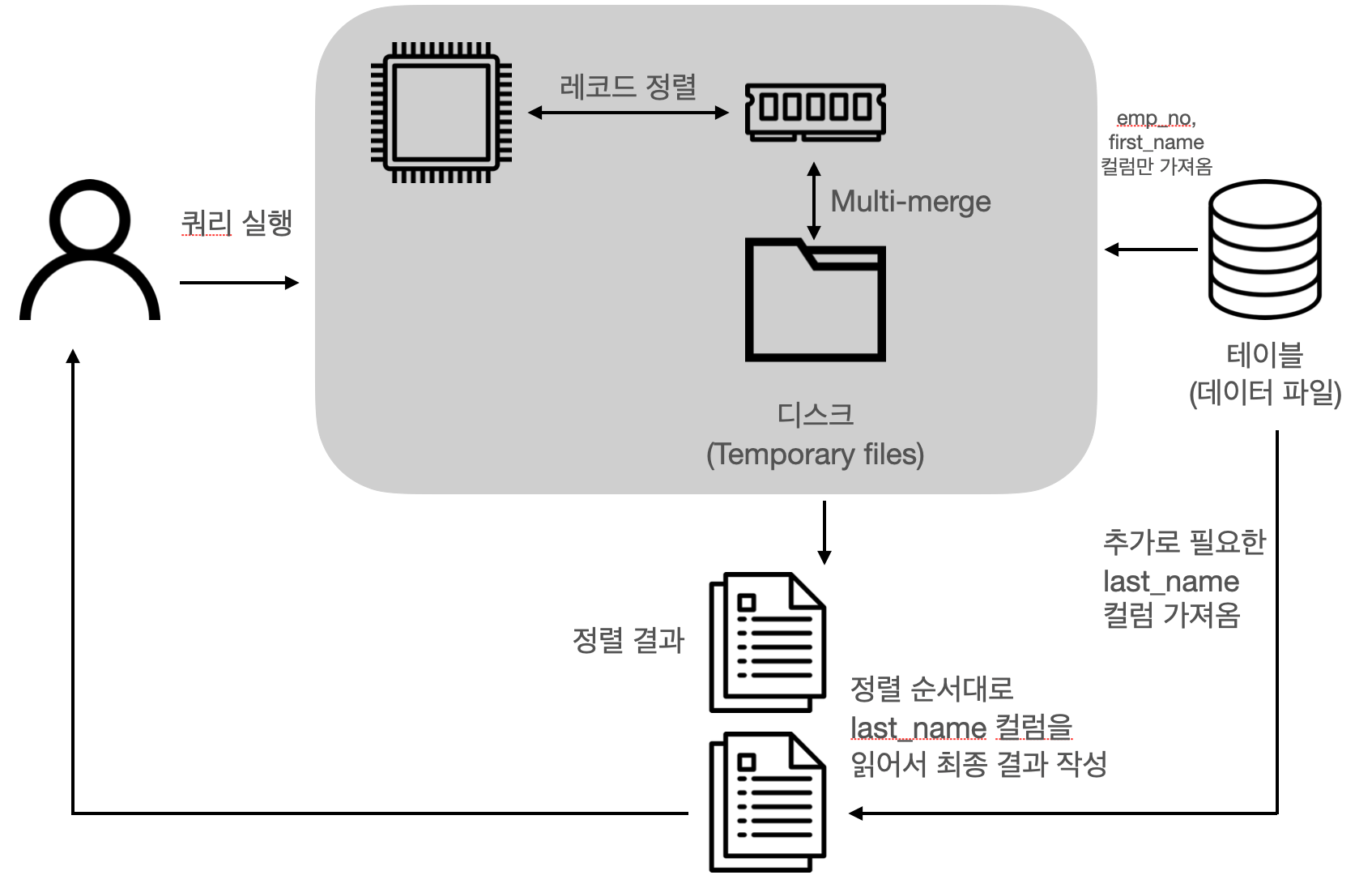
정렬 대상 컬럼과 프라이머리 키값만을 소트 버퍼에 담아서 정렬을 수행하고 정렬된 순서대로 다시 프라이머리 키로 테이블을 읽어서 SELECT 할 컬럼을 가져오는 알고리즘입니다. 테이블에서 같은 레코드를 두 번 읽어야 하기 때문에 불합리한 부분이 있습니다. 하지만 싱글 패스 알고리즘보다 소트 버퍼에 담는 컬럼의 수가 적습니다. 레코드의 크기나 건수가 많은 경우 효율적입니다.
위의 정렬 방식들 때문에 정렬이 필요한 SELECT 쿼리에서 꼭 필요한 컬럼만 작성하는 것이 메모리 효율적으로 더 좋은 쿼리라고 할 수 있습니다. *을 이용해 모든 컬럼을 포함한다면 소트 버퍼에 더 많은 공간이 필요하게 되고 조회해야 하는 레코드 건수가 많아지면 디스크와의 I/O 작업이 늘어날 것입니다.

인라인뷰나 서브쿼리에서 *을 자주사용하곤했었는데, 이 부분도 필요한 컬럼만 가져오는게 좋을까요?