Expectation-Maximization algorithm(EM)은 latent variable이 존재할 때, 만일 latent variable을 알 수 있다면 쉽게 풀리는 문제에 공통적으로 적용할 수 있는 범용적인 알고리즘입니디. EM은 latent variable을 통계적으로 할당하는 과정(E-step)과 할당한 결과를 바탕으로 parameter를 재산정하는 과정(M-step)을 반복합니다.
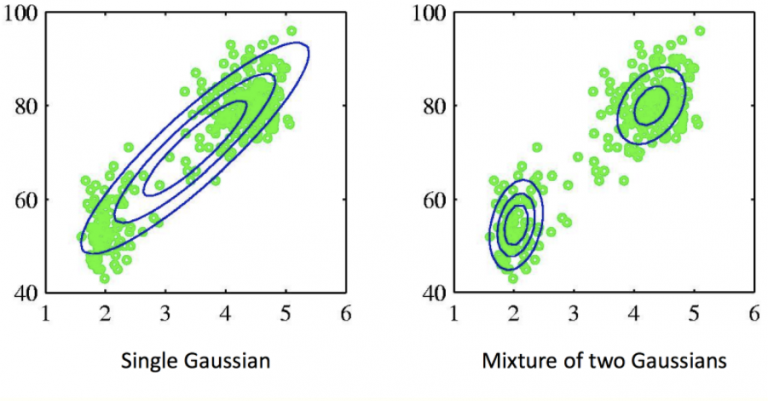
위 이미지는 Gaussian Mixture Model(GMM)의 parameter를 EM을 통해 근사하는 과정을 보여줍니다. GMM은 분포의 확률밀도함수를 Gaussian 분포의 가중 합으로 표현하는데, 점차 그럴듯한 분포로 수렴해나가는 모습을 볼 수 있습니다. 이후 섹션에서는 GMM을 소개하고, EM의 예시로 GMM을 사용하겠습니다.
Gaussian Mixture Model
GMM의 분포는 K 개의 서로 다른 Gaussian의 합으로 이루어져 있으며 다음과 같이 주어집니다. GMM의 parameter는 {pi_k, mu_k, Sigma_k} (k in [1, K]) 이고, pi_k는 임의의 샘플이 k번째 cluster에 속할 확률입니다.
직접 계산을 시도해보시기 바랍니다. 결과는 다음과 같습니다. (1.01962)
잘 알고 있는 함수(Gaussian)라도 그 합의 최댓값을 찾기는 어렵다는 결과를 얻었습니다. 즉, GMM의 분포에 직접적으로 MLE를 적용하기 어렵습니다.
이제 EM이 등장할 차례입니다. EM은 다음의 생각에서 출발합니다.
likelihood를 최대화하는 parameter(param_MLE)를 계산하기 어려운 상황에서, 만약 likelihood를 "잘 아는 함수의 성질"을 활용할 수 있도록 정의된 parameter의 함수 Q로 근사한다면, Q를 최대화하는 parameter (param_EM)를 MLE 방식에 비해 더 간단히 얻을 수 있고, Q가 likelihood를 잘 근사할수록 param_EM은 param_MLE와 가까워진다.
이 때, 반복을 통해 Q가 likelihood를 점점 더 잘 근사하도록 할 수 있다.
본격적으로 EM에 대해 설명하겠습니다.
Notation
EM의 표기법부터 시작하겠습니다. EM에서는 관측한 데이터를 O, 숨겨진 데이터를 H로 표기합니다. Parameter는 Theta입니다. GMM의 경우 다음과 같습니다.
O={X}H={zi}i=1nΘ={πk,μk.Σk}
z는 앞에서 정의한 적이 없는 latent variable로 데이터가 어떤 클러스터에 속하는지 표현합니다. x^1이 2번째 클러스터에 속한다면 z^1 = 2로 주어집니다.
p(zi=k)=πk
z가 hidden인 이유는 명확합니다. 실제로 관측한 데이터에는 클러스터 정보가 주어지지 않기 때문입니다. 이처럼 hidden을 모르는 경우 정보가 불충분하고 incomplete라고 표기합니다. 반대로 hidden을 아는 경우 complete라고 표기합니다. 두 경우의 likelihood도 구분할 수 있습니다.
Marginal likelihood: O만 관측 가능한 경우로, 실제로 최대화하고 싶은 함수입니다. (b: 어렵다)
p(O∣Θ)
Complete likelihood: O뿐 아니라 H 역시 관측 가능한 경우입니다. H를 알 경우, 간단한 형태가 됩니다. GMM의 경우 단일 Gaussian이 됩니다. (a, c: 쉽다)
p(O,H∣Θ)
Likelihood 사이의 관계: Marginalize rule에 의해 다음이 성립합니다.
p(O∣Θ)=H∑p(O,H∣Θ)
EM Bound
실제로 최대화하고 싶은 함수는 marginal likelihood로, complete likelihood의 합으로 표현할 수 있습니다. GMM의 예시에서 보았듯이 marginal likelihood를 그대로 최적화하기 어렵지만, 다음의 근사를 활용하면 complete likelihood를 통해 잘 아는 함수의 성질을 활용할 수 있어, 더욱 간단히 최적화 할 수 있습니다.
logp(O∣Θ)=log[H∑p(O,H∣Θ)]≈H∑αHlogp(O,H∣Θ)
alpha_H는 데이터가 H에 할당될 확률입니다. 확률의 정의를 만족하는 임의의 조합 alpha_H에 대해 다음이 성립한다고 알려져 있습니다. 이 식을 통해 marginal log likelihood의 lower bound를 얻었습니다. Complete likelihood는 parameter(Theta)에 의존하므로, lower bound 는 Theta, alpha_H의 함수입니다.
M-step(재산정): alpha_H를 고정한 채로, lower bound가 최대가 되도록 Theta를 업데이트합니다.
αHt=p(H∣O,Θt)Θt+1∈ΘargmaxH∑αHtlogp(O,H∣Θ)
정리하면 위와 같습니다. E-step에서 alpha_H를 업데이트하면 alpha_H, Theta의 함수인 lower bound가 업데이트됩니다. M-step에서는 업데이트된 lower_bound를 최대화 하는 parameter(Theta)를 찾아 다음 스텝의 Theta, 즉 Theta^(t+1)로 사용합니다. Lower bound의 두번째 항은 Theta에 대해 상수입니다.
GMM에서 E-step은 할당 과정이라 볼 수 있습니다. 데이터와 Parameter가 주어졌을 때, 데이터 포인트가 각각의 클러스터에 속할 사후확률을 계산하기 때문입니다.
H, O, Theta를 원래의 변수로 바꾸어 계산하면 다음과 같습니다. 이때, pi_{k,t}는 t번째 업데이트 과정에서 k번째 클러스터의 등장 확률이고 mu_{k,t}, Sigma_{k,t}는 그 클러스터의 평균, 공분산행렬입니다. pi, mu, sigma는 M-step에서 얻어집니다.
또한 p(H|O, Theta)의 분모에 Gaussian의 합처럼 보이는 항이 존재하나 분포의 합이 아닌 함숫값의 합입니다.
GMM을 다루는 많은 자료들이 E-step의 결과로 얻어지는 i번째 데이터 포인트가 k번째 클러스터에 속할 사후확률을 responsibility(r)로 정의하고 i번째 데이터 포인트는 k번째 클러스터에 soft-assigned되었다고 표현합니다. r을 사용하면 Q를 간단히 표현할 수 있습니다.
위 결과를 통해 x=0.5는 클러스터 1에 0.45, 클러스터 2에 0.55의 비율로 나뉘어 할당되었음을 알 수 있습니다.
M-step
Maximization step은 E-step에서 얻은 Theta에 대한 함수 Q를 mu, pi, Sigma에 대해 미분하여 Q를 최대로 만드는 parameter를 구하는 재산정 과정입니다. Gaussian의 성질을 활용하고, 선형대수의 도움을 받는다면 업데이트 공식을 다음과 같이 정리할 수 있습니다. (GMM에서 Gaussian의 성질을 활용할 수 있는 이유는 likelihood를 complete likelihood의 weighted average로 근사했기 때문입니다 - EM bound 단락 참고)





잘 보았습니다. GMM에서 K 는 임의로 지정해주어야하나요? 예컨데, 총 몇개의 가우시안이 섞인것인지 모를 때는 어떻게 해야하나요?