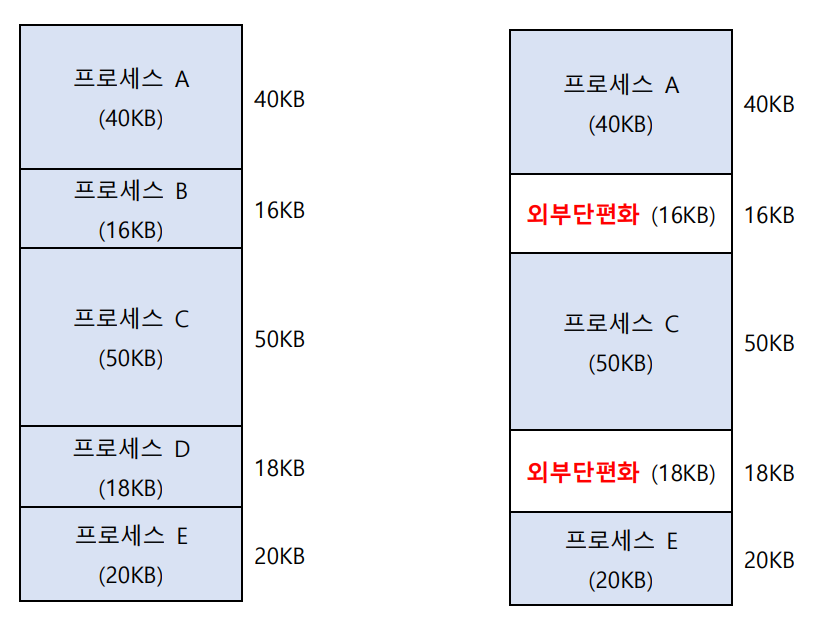
메모리 단편화
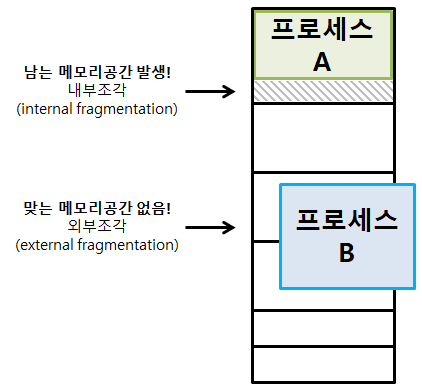
메모리 할당 정책
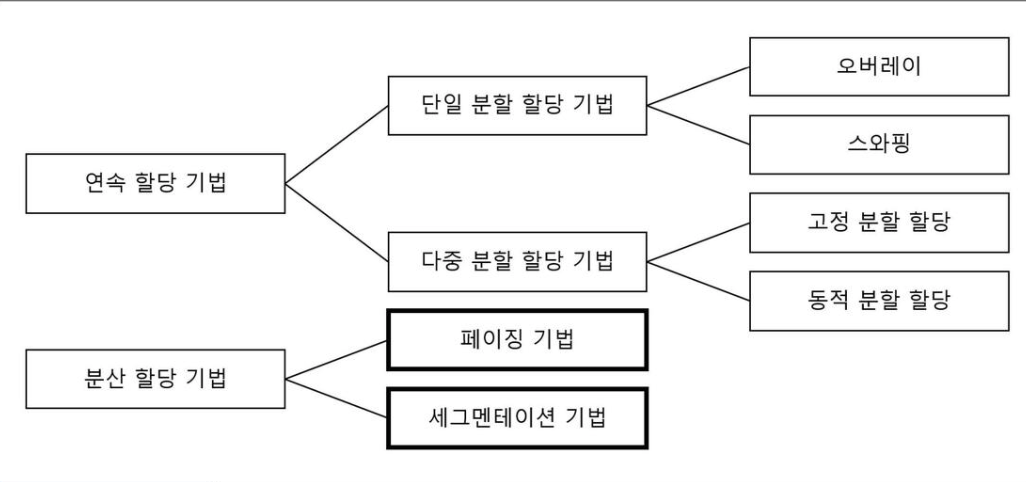
연속 할당(Contiguous Memory Allocation)
주소 변환이 매우 간단하지만 단편화 문제가 많이 발생
1. 고정된 크기로 분할 - 연속 할당 기법에 해당
구현은 간단하지만 메모리 공간의 낭비라는 큰 단점을 가지고 있어 단편화가 발생한다.
2. 가변 분할(동적 분할) - 연속 할당 기법에 해당
메모리에 적재되는 프로그램의 크기에 따라 분할의 크기, 개수가 동적으로 변하는 방식이다.
프로세스에 딱 맞게 메모리 공간을 사용하기에 내부 단편화 문제는 생기지 않는다.
그렇지만, 사용중인 프로세스가 종료되어 메모리에 새로운 프로세스를 올릴 공간이 충분하지 않을 경우가 있을 수 있다.(외부 단편화)
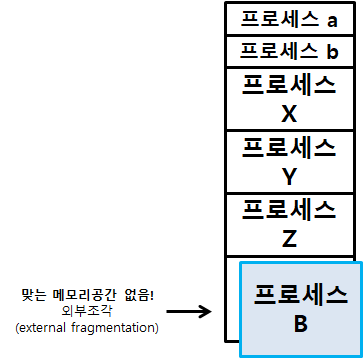
가변 분할 4가지 방식
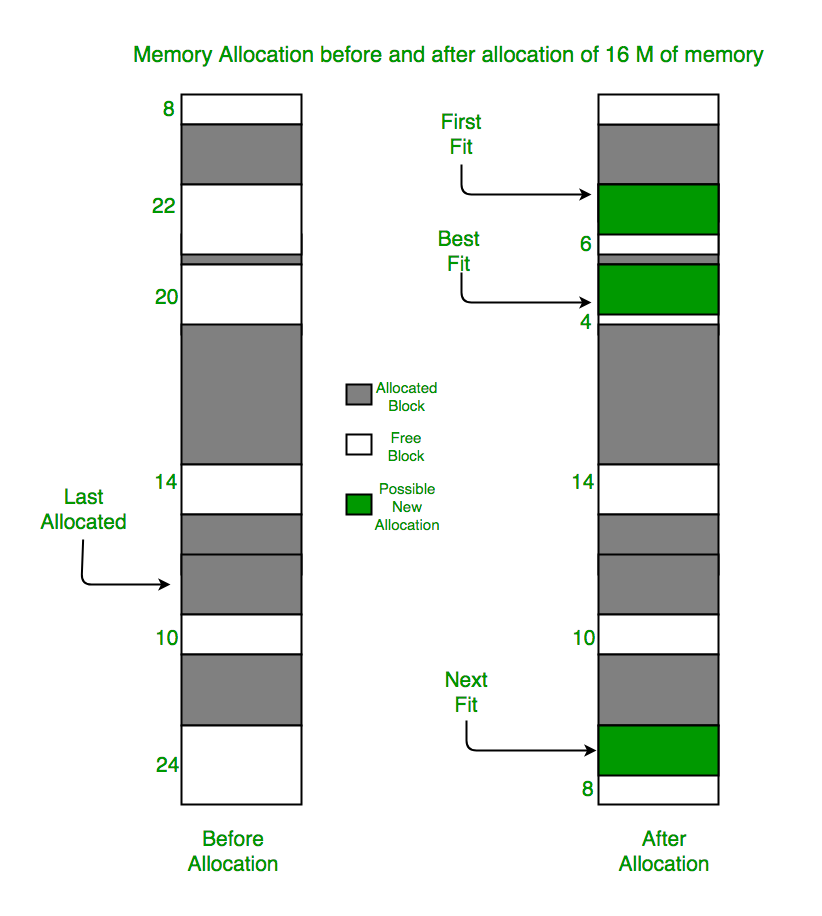
1. first fit
위쪽이나 아래쪽부터 시작해서 홀을 찾으면 바로 할당. 빈 공간을 찾아다닐 필요 없다.
static void *first_fit(size_t asize) {
for (unsigned char *cur = heap_listp; GET_SIZE(HDRP(cur)) > 0; cur = NEXT_BLKP(cur)) {
if (!GET_ALLOC(HDRP(cur)) && (asize <= GET_SIZE(HDRP(cur)))) {
return cur;
}
}
return NULL;
}2. next fit
static void *next_fit(size_t asize) {
for (unsigned char *cur = next_fit_ptr; GET_SIZE(HDRP(cur)) > 0; cur = NEXT_BLKP(cur)) {
if (!GET_ALLOC(HDRP(cur)) && (asize <= GET_SIZE(HDRP(cur)))) {
set_next_fit_ptr(cur);
return cur;
}
}
// 적합한 블록이 없다면 'first fit'처럼 동작합니다.
for (unsigned char *cur = heap_listp; cur < next_fit_ptr; cur = NEXT_BLKP(cur)) {
if (!GET_ALLOC(HDRP(cur)) && (asize <= GET_SIZE(HDRP(cur)))) {
set_next_fit_ptr(cur);
return cur;
}
}
set_next_fit_ptr(heap_listp);
return NULL;
}3. best fit
프로세스의 크기 이상인 공간 중 가장 작은 홀에 할당. 빈 공간을 확인하는 부가적인 작업이 있지만, 딱 맞는 공간을 찾을 경우 단편화가 일어나지 않는다.
static void *best_fit(size_t asize) {
void *bestfit = NULL;
size_t diff = 0;
for (unsigned char *cur = heap_listp; GET_SIZE(HDRP(cur)) > 0; cur = NEXT_BLKP(cur)) {
if (!GET_ALLOC(HDRP(cur)) && (asize <= GET_SIZE(HDRP(cur)))) {
if (bestfit == NULL) {
bestfit = cur;
diff = GET_SIZE(HDRP(cur)) - asize;
continue;
}
if (diff > GET_SIZE(HDRP(cur)) - asize) {
bestfit = cur;
diff = GET_SIZE(HDRP(cur)) - asize;
}
}
}
return bestfit;
}4. worst fit
프로세스의 크기와 가장 많이 차이가 나는 홀에 할당. 프로세스를 배치하고 남은 공간이 크기 때문에 쓸모가 있다. 빈 공간의 크기가 클 때는 효과적이지만 빈 공간의 크기가 점점 줄어들면 최적적합처럼 작은 조각을 만들어낸다.
불연속 할당
메모리를 연속적으로 할당하지 않는 방식. 현대 운영체제 쓰는 방법이다.연속 할당에 비해 단편화 문제는 적지만 주소변환이 복잡
페이징 -> 고정분할 방식
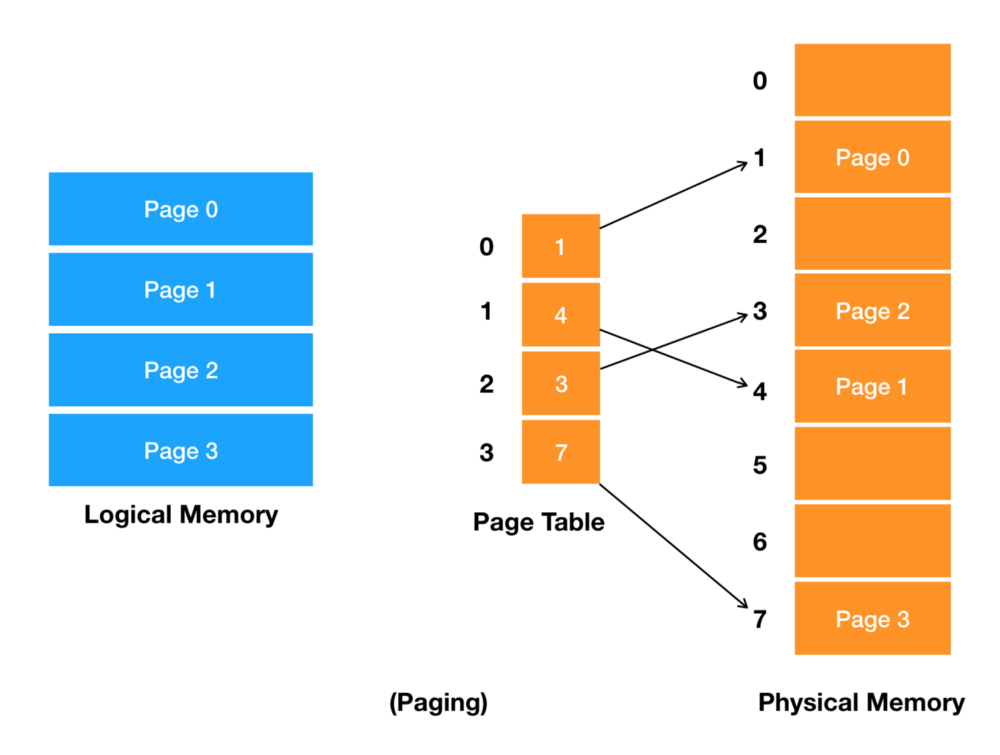
프로세스가 사용하는 주소 공간을 여러 개로 분할하여 비연속적인 물리 메모리 공간에 할당, 가상 메모리를 모두 같은 크기의 블록으로 나눔
다른말로,
논리 주소의 전체 범위를 페이지라고 불리는 인접하는 블록들로 분할하고,
페이지를 가리키는 논리 주소에서 프레임을 가리키는 물리주소로 변환하고,
MMU가 논리주소를 물리주소로 변환하고 이를 캐시와 물리 메모리에 공급한다.
단어 정의
- 프레임 : 물리 메모리에 할당 된 실제 메모리 공간
- 페이지 : 가상 메모리의 블록들 (프로세스의 메모리 공간)
(프레임 사이즈 = 페이지 사이즈)(논리적 의미와 관계없이 크기 모두 동일)- 페이지 테이블 : 피지컬 메모리와 로지컬 메모리가(virtual memory) 매핑될 때 참조하는 테이블
페이징의 문제
- 데이터가 물리 메모리에 위치하지 않는다면 페이지 부재(page fault) 발생
* 위 문제를 해결할 때, 페이지 테이블을 재설정 해야해서 문맥교환(context switching)이 발생- 매번 PTE먼저 읽어야 해서 메모리 접근 시간이 두배-> 캐싱을 사용하여 해결
page hit & falut
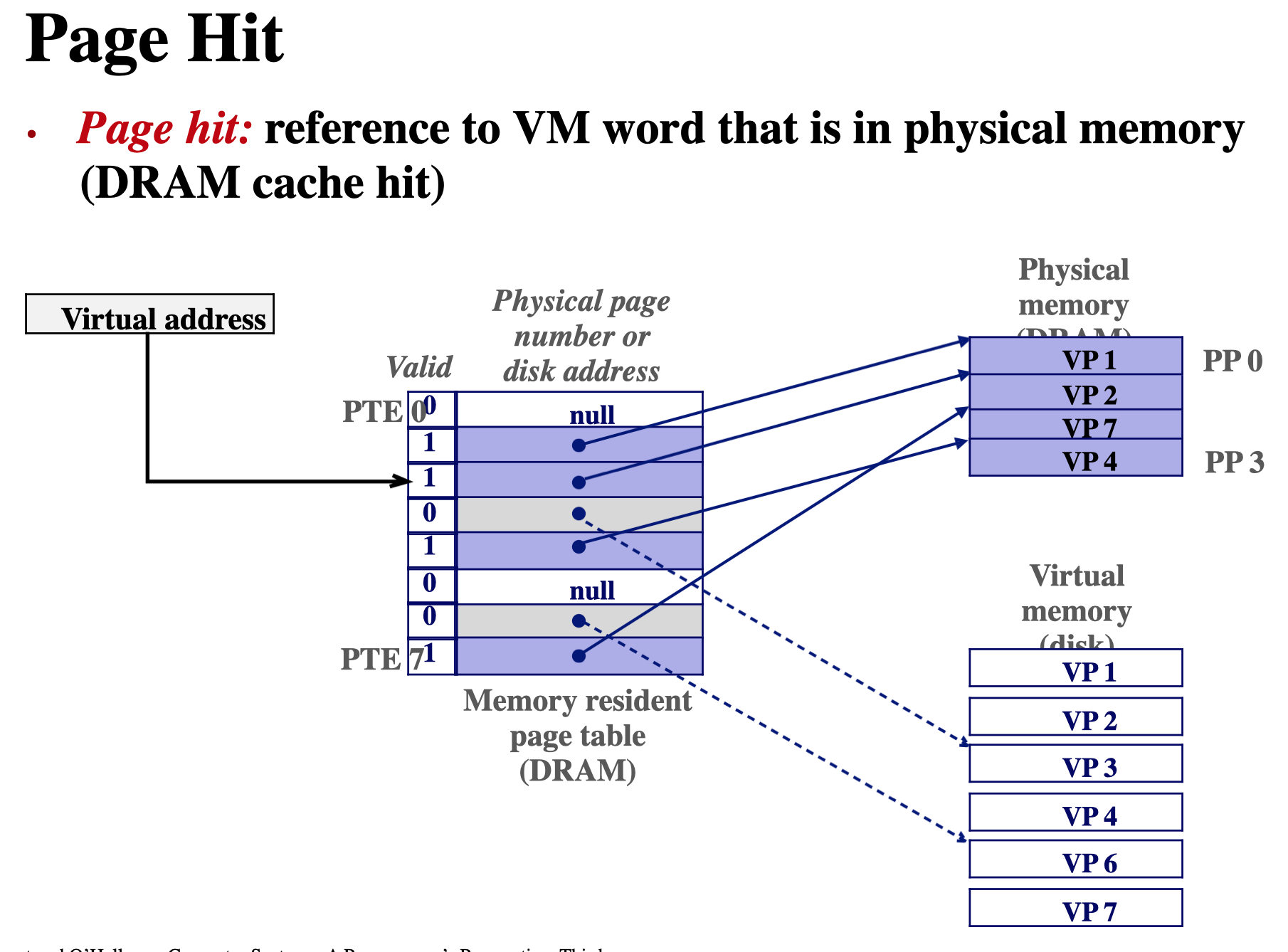
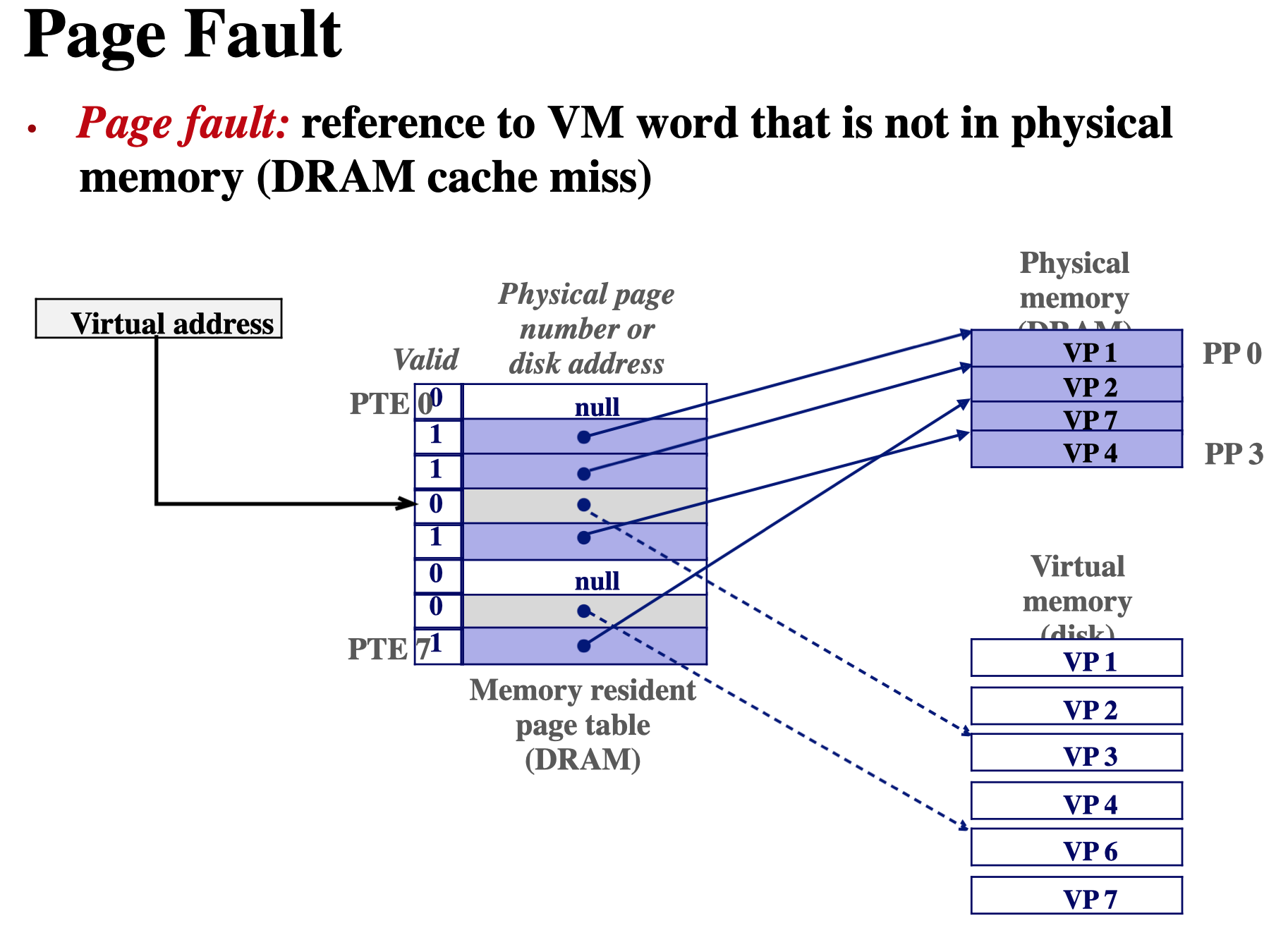
페이지 폴트란 프로그램이 자신의 주소 공간에는 존재하지만 시스템의 RAM에는 현재 없는 데이터에 접근을 시도하였을 경우에 발생하는 현상.
페이지 폴트를 핸들하는 방법
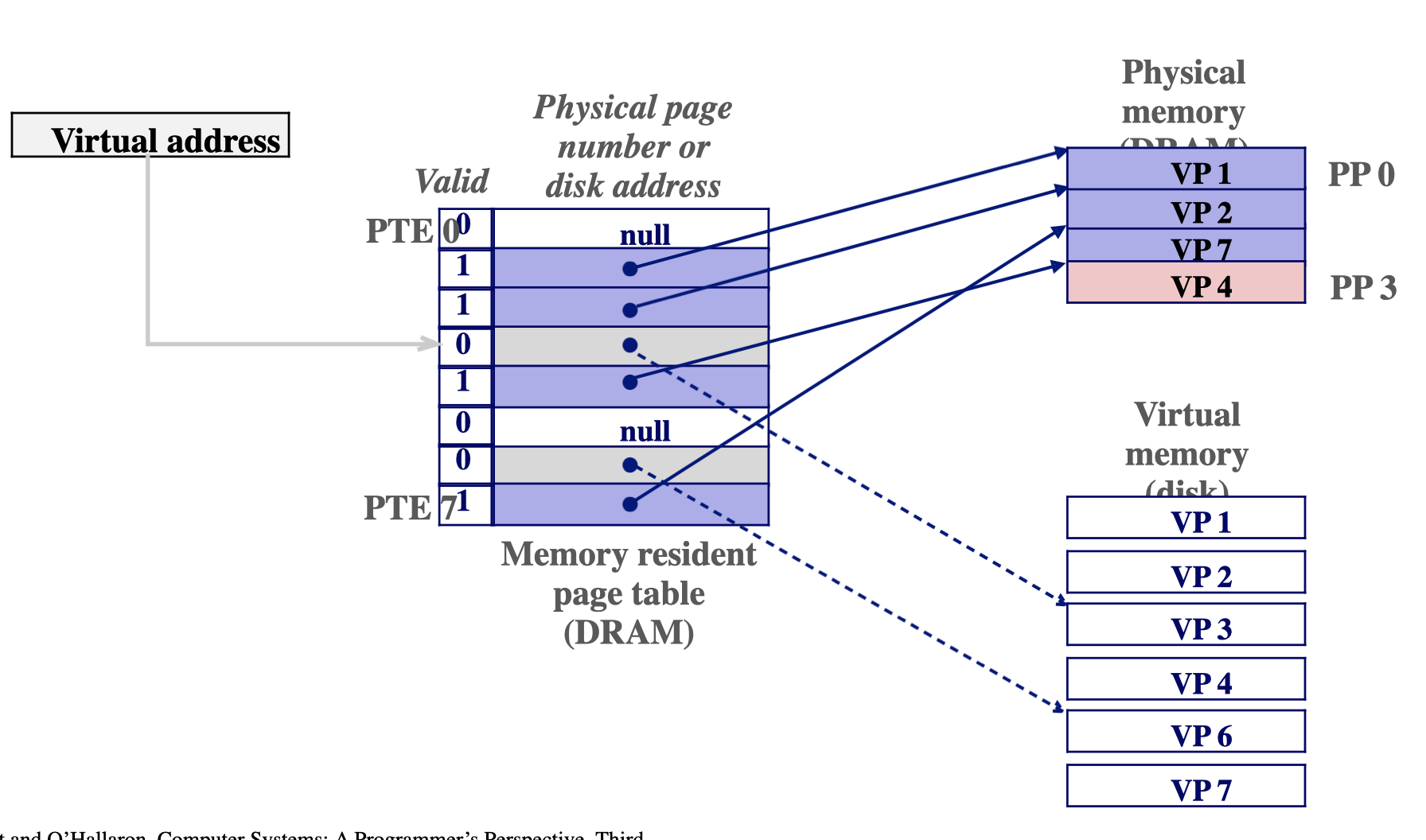
Key point: Waiting until the miss to copy the page to DRAM is known as demand paging
디멘드 페이징 : 하드디스크에 스왑영역에 있는걸 물리메모리로 가져오는 행위를 말하는 것
접근비트
변경비트
유효비트
유효비트 1 : 스왑영역에 페이지 존재
유효비트 0 : 물리영역에 페 이지 존재
읽기 쓰실
프레임
1) 스왑이 필요 없는 경우
2) 스왑이 필요한 경우
3) 물리메모리가 꽉 찼을 때 스왑 영역에 있는 경우
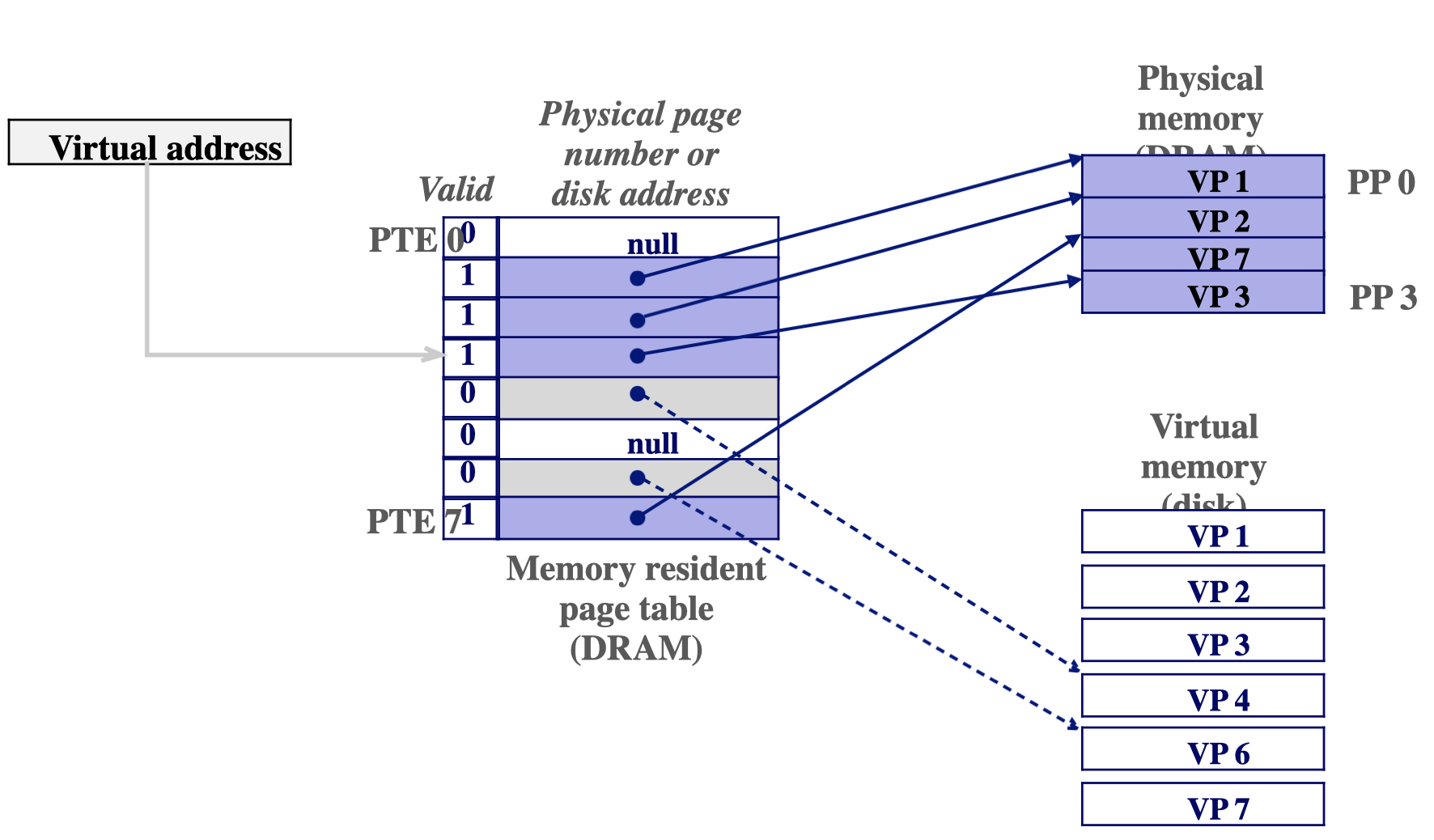
- page fault handler 가 physical memory에서 퇴출할 victim을 선택한다.
물리 메모리를 스왑에 남는곳으로 - virtual address가 가르키는 페이지 테이블을 새로 넣은 페이지를 가르키게 한다.(퇴거 앤 입주)
- victim을 가르키던 페이지 테이블은 Virtual memory의 퇴거한 페이지를 가르키게 한다.
- page fault가 났던 instruction을 재시작한다(page hit!)
세그멘테이션 -> 가변분할 방식
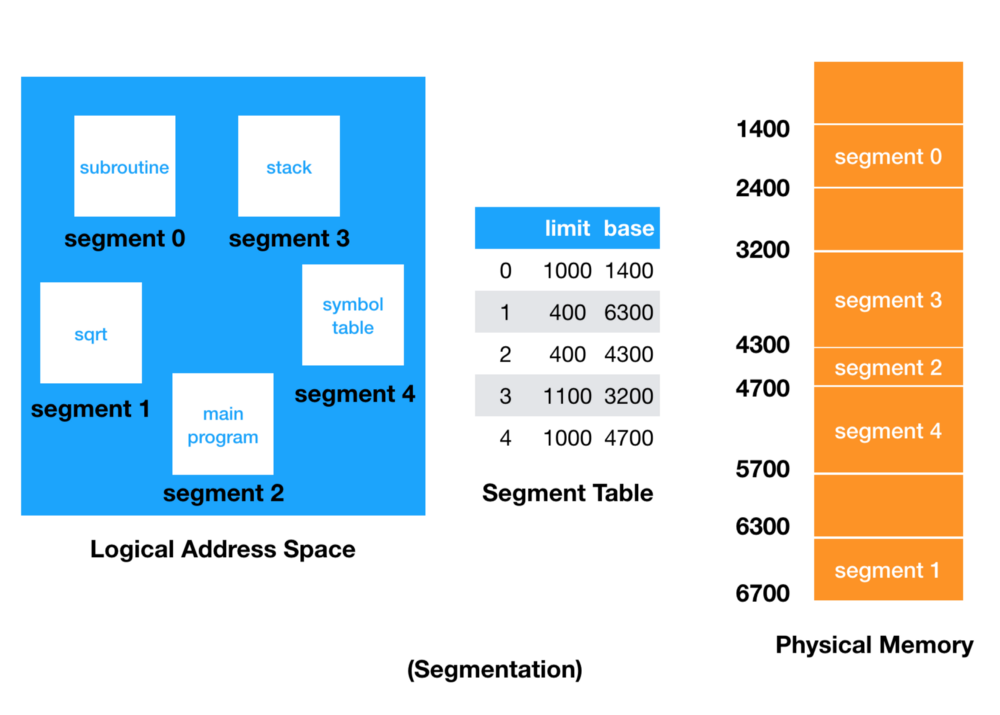
페이지 단위가 아닌 segment(서로 다른 크기)로 비연속적인 물리 메모리 공간에 나누는 방식.
크기가 다 다르기 때문에 미리 분할해 두지 않고 메모리에 적재될 때 빈 공간을 찾아 할당한다.
물리주소 = BASE address + Bound address
세그먼트 테이블에서는
Base(세그먼트 시작 주소) + Limit(세그먼트 길이)
그래서 만약에 1000 Out of Bounds
paging VS segment 장단점
추가로 알아가자 paged segmentation
공유나 보안을 의미 단위의 세그먼트로 나누고, 물리적 메모리는 페이지로 나눈다.
implicit free list
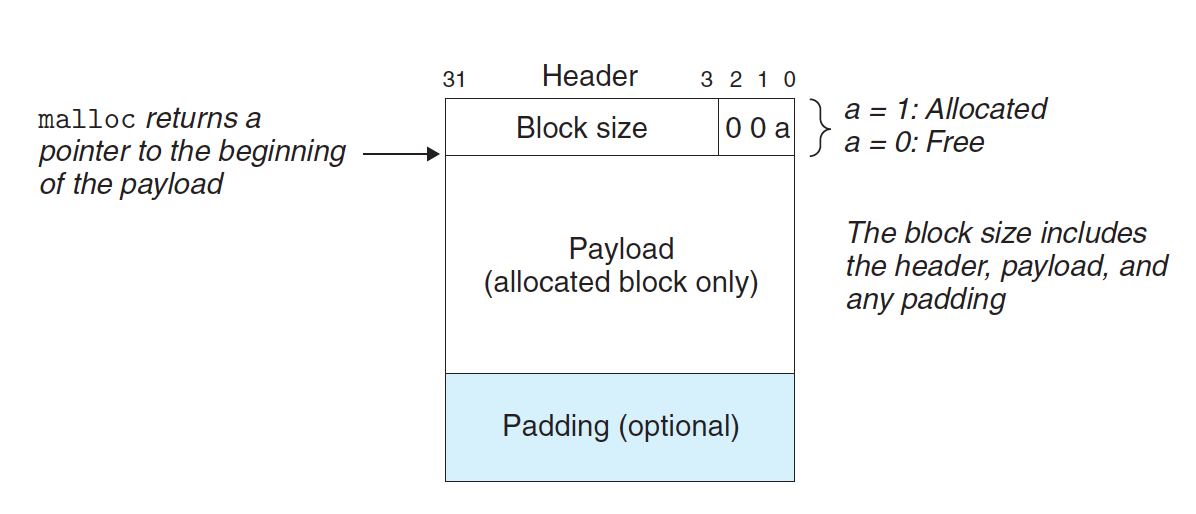
explicit free list
Basic Concept
Explicit Free List는 '현재 Block의 Size' 뿐만 아니라 'Next Free Block의 주소값'도 저장하는 방식이다.
즉, 'Block Size'와 'Next Free Block Pointer'를 같이 저장하는 방식이다. (2Words)
당연히 공간적인 관점에서는 Implicit Free List가 더 유리하다.
Implicit Free List에선 Boundary Tags 방법을 사용하지 않는다고 보았을 때 Extra Space가 1Word면 충분하다.
반면, Explicit Free List에선 2Words가 필요한 것이다.
아래 그림을 보면, Implicit Free List에선 5Words Size의 Block에 4Words의 Payload가 저장될 수 있는 반면, Explicit Free List에선 똑같은 5Words Size Block에 3Words Size의 Payload를 저장할 수 있다.
Implicit Free List는 4/5, 즉, Payload가 80%를 차지한다.
Explicit Free List는 3/5, 즉, Payload가 60%만 차지한다.
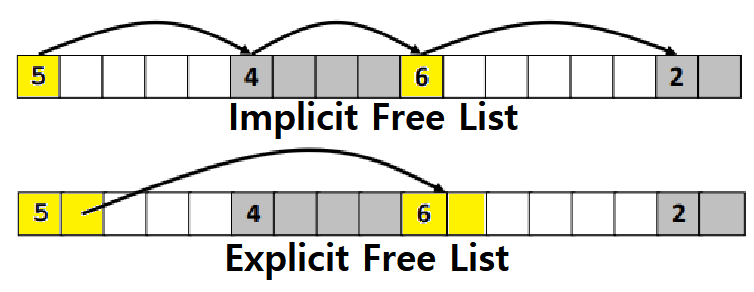
- 두 방식 모두 Free Block Search 시에 Linear Traversal을 사용한다. 하지만 Implicit은 State와 상관없이 모든 Block을 순회하는 반면, Explicit은 Free Block만 순회한다.
- 따라서, Explicit이 순회 횟수가 훨씬 적으며, 나아가 수행 속도도 더 우수하다.
segregated free list
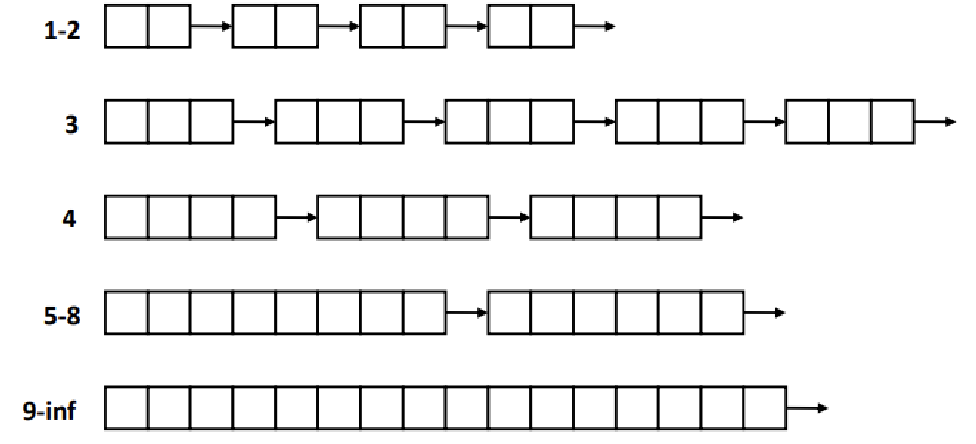
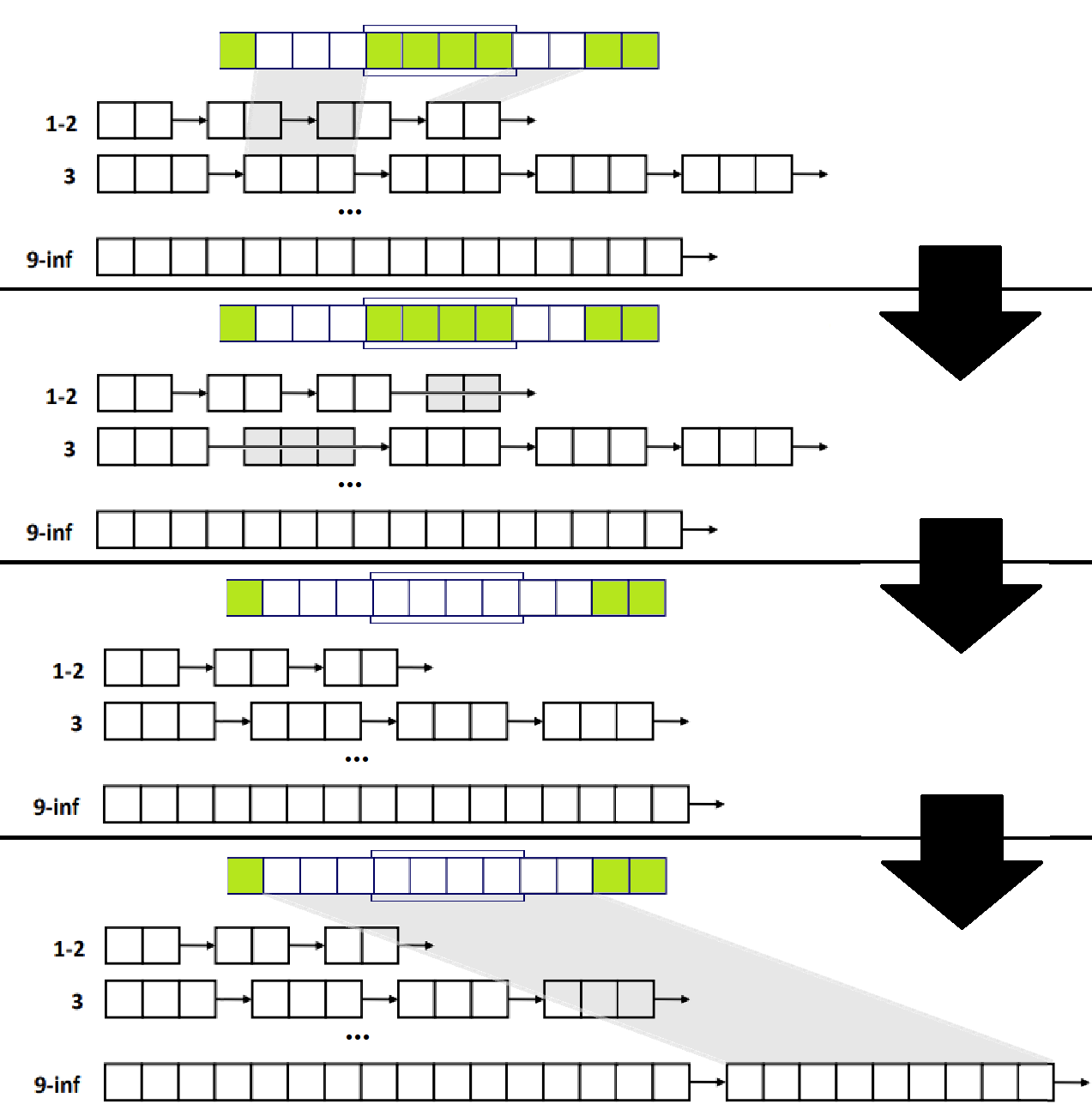
빈구멍이용
페이지 테이블 구성
1. 프레임 번호(Frame Number)
2. 유효 비트(valid bit) - 유효비트가 0이면 페이지 부재를 뜻함
3. 기타 제어비트(Accessed, Dirty 등)
-
페이지 테이블 접근
-
Frame, page
출처
https://charstring.tistory.com/919
https://hapen385.tistory.com/49
https://velog.io/@junttang/SP-6.3-Explicit-Segregated-Free-List
