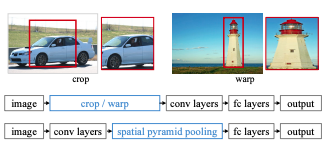
- 기존 R-CNN의 문제점
- 기존의 CNN 아키텍쳐들은 모두 입력 이미지가 특정 사이즈로 고정되어, 통과 시킬 이미지 warp(resize)해야 했습니다. 그 과정에서 물체의 일부분이 잘리거나 본래의 생김새와 달라진다는 문제가 있었습니다. SPP Network는 이런한 단점을 보완하기 위해서 탄생했습니다.
- 기존의 CNN 아키텍쳐들은 모두 입력 이미지가 특정 사이즈로 고정되어, 통과 시킬 이미지 warp(resize)해야 했습니다. 그 과정에서 물체의 일부분이 잘리거나 본래의 생김새와 달라진다는 문제가 있었습니다. SPP Network는 이런한 단점을 보완하기 위해서 탄생했습니다.
- SPP Network 동작 방식
- Pre-trained된 CNN에 전체 이미지를 통과시켜 feature map을 얻습니다.
- 추출된 feature map에서 selective search를 통해 2000개의 rol을 찾습니다.
- 2000개의 rol에 SPP를 적용해서 고정된 크기의 feature 얻어냅니다.
- 얻어낸 feature를 fc layer를 통과 시켜 feature vector를 얻습니다.
- 얻어낸 feature vector를 바탕으로 각 클래스 별로 binary SVM classifier를 학습시킵니다.
- 얻어낸 feature vector를 바탕으로 bbox regressor를 학습시킵니다.
- SPP를 적용하는 방법?
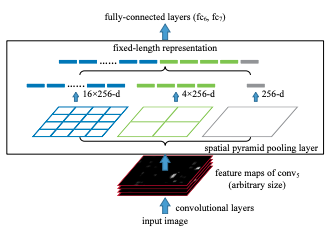
- Conv layer를 거쳐서 추출된 feature map을 input으로 받고, 미리 정해진 영역으로 나눈다. 위의 사진에는 4x4, 2x2, 1x1 세가지 영역이 있고, 각각을 하나의 피라미드라고 부른다. 또한 피라미드의 한칸을 bin이라고 한다. 예를 들어 64x64x256 크기의 feature map이 들어온다고 가정할 때, 4x4피라미드의 bin은 16x16이 된다.
- 각 bin에서는 가장 큰 값만 추출하는 max-pooling을 수행하고, 그 결과를 쭉 이어 붙입니다. 위의 예시라면, 최종 output은 kM 차원의 vector입니다. k =256, M = (16 + 4 + 1) = 21이 됩니다. 결론적으로 이미지의 크기와 상관없이 미리 설정한 bin의 개수와 CNN채널 값으로 SPP의 출력이 결정되므로, 항상 동일한 크기를 return한다.
- R-CNN vs SPP Network in Object Detection

- R-CNN은 Selective Search로 찾아 2천개의 물체 영역을 모두 고정 크기로 조절한 다음, 미리 학습된 CNN 모델을 통과시켜 feature를 추출하기 때문에 속도가 느릴 수 밖에 없습니다.
- SPP Network는 입력 이미지를 그대로 CNN에 통과시키고 feature map을 얻어, 그 feature map에서 2000개의 rols를 찾아 SPP를 적용하여 고정된 크기의 feature를 얻어냅니다. 그리고 이를 FC layer와 SVM classifier에 통과시킵니다.
- SPP의 한계
- end-to-end 방식이 아니므로, 학습을 할 때 여러 단계를 요구한다.
- fine-tuning
- SVM training
- Bouding Box Regression
- R-CNN과 같이 classification task에서는 binary SVM, Region Proposal은 selective search를 사용한다.
- fine tuning시에 SPP를 거치기 이전의 Conv 레이어들을 학습 시키지 못한다.
- end-to-end 방식이 아니므로, 학습을 할 때 여러 단계를 요구한다.


하얀 도화지 김태영입니다.