인덱스의 필요성을 알고싶어
대부분의 포스팅에서 Index란 데이터베이스 테이블에 대한 검색 성능의 속도를 높여주는 자료 구조라고 한다. 하지만 과연 어떠한 방식으로 검색의 성능을 높여주는지 어째서 성능이 높아지는지 그것을 알아야 Index에 대한 내용이 좀 더 쉽게 머릿 속에 들어오지 않을까.. 그런 생각이 들어 코딩장이님의 블로그를 참조하여 필요성을 서술하려고 한다.
우리가 📙책을 읽을 때..
백과사전이나 논문과 같은 글을 참조할 때 우리는 책장 맨 앞에 있는 목차를 통해서 빠르게 그 페이지로 넘어가 거기서부터 원하는 내용을 찾는다. DataBase에서 말하는 Index란 바로 그 목차와 비슷한 기능을 한다고 생각하면 될 것 같다. 더 명확하게 말하면 책 뒷 쪽에 있는 색인 그 자체이다.
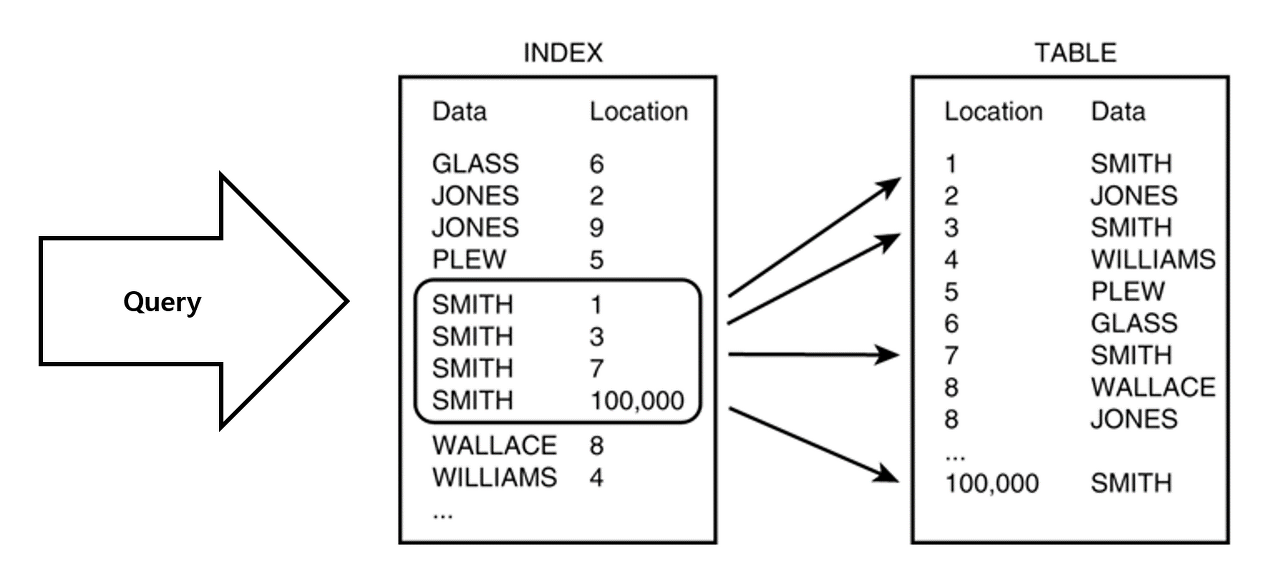
우리가 원하는 데이터를 찾기 위해 주로 사용하는 Select 기능은 색인을 이용하지 않는 사람처럼 내용을 처음부터 끝까지 찾아본다. 심지어 데이터를 찾은 이후에도 마지막까지 검색하는 full scan 성질을 가지고있다.
그렇기에 Index를 사용하여 성능의 낭비를 줄일 필요가 있는 것이다.
Index는 하나의 테이블과 비슷한 개념으로
CREATE INDEX INDEX_NAME ON TABLE_NAME(COLUMN_NAME);라는 쿼리문을 이용해 해당 Column의 데이터를 정렬해 Index를 생성한다.
Index의 구현에 사용되는 자료구조는 B+Tree🎄!!
B+Tree는 Binary Tree(이진 탐색 트리)의 문제점을 보완한 B-Tree에서 순차탐색을 효율적으로 하기위해 한 번 더 발전한 형태이다. B-Tree의 특징을 가지며 노드를 찾아 이동해야 하는 단점을 보완하기 위해 모든 키 값들이 leaf node에 정렬되어있다.
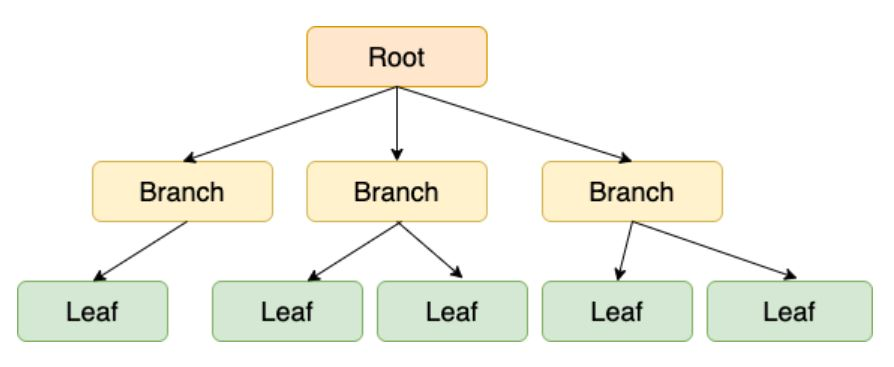
Index를 통한 탐색 시에 LinkedList된 노드를 따라 Root -> Branch -> Leaf로 내려가서 Leaf node에 저장된 rowid를 이용해 검색하기 때문에 불필요한 탐색을 줄일 수 있다. 하지만 무조건 Leaf node까지 가야하기 때문에 적은 규모의 테이블의 경우 그냥 Select를 사용하는 것이 더 높은 성능을 낼 수 있다.
장/단점을 이야기하자면❗
인덱스의 장점은 단 하나로 아주 분명하다. 테이블을 검색하는 속도와 성능이 향상된다는 것이다. 겨우 하나라고 말할 수 있지만 이 때문에 인덱스를 사용할 수 밖에 없는 상황이 있다.
하지만 인덱스를 효율적으로 사용하기 위해서는 아래의 특정 조건들이 필요하다.
- 규모가 큰 테이블
- 삽입(INSERT), 수정(UPDATE), 삭제(DELETE) 작업이 자주 발생하지 않는 컬럼
- WHERE나 ORDER BY, JOIN 등이 자주 사용되는 컬럼
- 데이터의 중복도가 낮은 컬럼
일정 수 이 하의 테이블이 존재할 때는 오히려 인덱스를 사용하는 것이 더 느릴 때가 있다. 그리고 DML(Data Manipulation Language)이 자주 발생하지 않는 조건이 붙는데 어째서 이러지 않는 것이 효율적인지는 아래의 단점에서 설명이 된다.
인덱스의 단점은 오히려 장점으로인한 것이 크다. 항상 정렬된 상태이기 때문에 그걸 유지해야할 필요가 있기때문이다.
단점은 크게 네가지로 말할 수 있다.
- 인덱스를 관리하기 위해 추가 저장 공간 필요하다.
- 인덱스를 관리하기 위한 추가 작업이 필요하다.
- 잘못 사용하는 경우 오히려 검색 성능 저하된다.
- 인덱스 테이블의 유지, 관리 비용이 든다.
단점에 대한 '추가 설명'
Index는 위에서 이야기 한 균형 이진 트리를 구성하는데, INSERT, UPDATE, DELETE를 하면 트리 균형을 위해 트리 구조를 재구성 하는 비용이 발생한다. 게다가 이진 탐색 트리의 업데이트는 삭제와 삽입 과정이 함께 발생하므로 2배의 비용이 발생한다.
DBMS는 이 트리 재구성 비용을 아끼기 위해서 노드 삭제를 진행하지 않고 '사용하지 않음'으로 처리하고 남겨두기 때문에 수정 작업이 많은 경우 실제 데이터에 비해 인덱스가 과도하게 커지는 문제점이 발생할 수 있다.
이렇게 인덱스 테이블이 거대해짐에 따라, 트리의 높이가 깊어지는 문제가 발생하게 된다.
이는 DBMS의 성능을 점진적으로 내린다. 결국 미사용 노드를 트리에서 제거함으로써 높이 최적화가 필요하다.
그 외에도 여러 사용자(여러 응용프로그램)에서 한 페이지를 동시에 수정할 때 병행성이 떨어진다는 단점도 존재한다.
그렇다면 인덱스는 안 쓰는게 좋은걸까?
장점이 단 하나고 단점이 많다고 해서 안 쓰는게 좋다라고 딱 잘라 말할 수 없다. 실제 신입 개발자들의 면접에도 자주 나오는 질문이기도 하고 OLTP라고 하는 소프트웨어 업무의 90%가 데이터 조회이기때문이다.
그리고 검색을 해본 결과 현업에 들어가면 생각보다 인덱스를 쓰는 것 같았다. 중첩해서 쓰거나 크게 나누어서 쓴다는 이야기들이 있었다.
💫짜투리! OLTP는 조금 생소합니다
OLTP(Online Transaction Processing)는 온라인 트랜잭션 처리를 말한다. 네트워크상의 여러 이용자가 실시간으로 데이터베이스의 데이터를 갱신하거나 조회하는 등의 단위 작업을 처리하는 방식이다. 다수의 이용자가 거의 동시에 이용할 수 있도록 송수신 자료를 트랜잭션 단위로 압축하고 비어 있는 공간을 다른 사용자들이 함께 쓸 수 있도록 한다.
흔히 트랜잭션이라 부르는 용어의 의미 자체가 OLTP의 의미를 포함하고 있다고 할 수 있다.
일반적으로 은행이나, 항공사, 우편주문, 수퍼마켓, 제조업체 등을 포함한 많은 산업체에서 데이터 입력이나 거래조회 등을 위해 사용된다.
참조 Blog
https://itholic.github.io/database-index/ (Index)
https://rebro.kr/167 (Index 장 단점)
https://mommoo.tistory.com/109(Index의 비용 문제)
https://ssocoit.tistory.com/217 (B Tree)
http://ko.infomngproeng.wikidok.net/wp-d/60a1e50990b350fb11df6fa4/View (B Tree)
https://jins-dev.tistory.com/entry/%EA%B0%84%EB%9E%B5%ED%95%98%EA%B2%8C-%EC%A0%95%EB%A6%AC%ED%95%B4%EB%B3%B4%EB%8A%94-OLTP-OLAP-%EC%9D%98-%EA%B0%9C%EB%85%90(OLTP)
