여전히 계속되는 DataBase 포스팅 속
생각보다.. 아니 하나의 분야라고 일컫어지는 시스템은 정말 방대한 양이 있구나라고 느꼈다. 물론 내가 꽤 깊고 자세하게 그리고 어느정도 쓸데 없는 곳까지 파서 포스팅하고 있기는 하지만 벌써 6번째인데도 끝이 보이지 않는다. 이번에는 끝 없는 DataBase의 Data 속 신입 개발자의 면접 질문으로도 등장하는 이상현상과 정규화에 대해 쓰려고 한다.
이상현상(Anomly)
보통 정규화를 거치지 않은 데이터베이스에서 발생하는 현상으로 정규화가 수행되지 않으면 데이터의 중복이 발생하고 전체적인 무결성이 저하된다. 그로인해 릴레이션 조작에 예기치 못한 문제 발생할 수 있고 애트리뷰트들의 종속관계를 하나의 릴레이션에 표현하기 때문에 발생할 수 있다.
이상현상 세 가지
1. 삽입 이상(Insertion Anomaly)
특정 데이터가 존재하지 않아 중요한 데이터를 데이터베이스에 삽입할 수 없을 때 발생한다.
특정 속성에 해당하는 값이 없으면 의도와 다른 값 NULL을 입력해야 하는 상황이 생긴다.
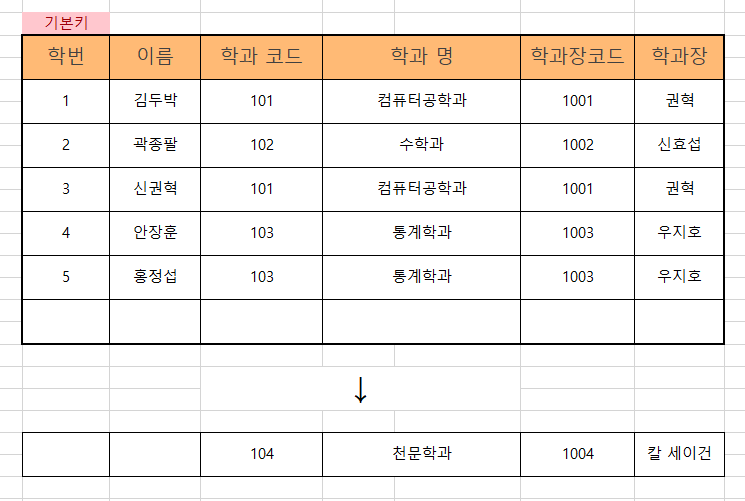
ㅇㅇ대학 테이블에서 학생 없이 학과만 신설된 경우 기본키인 학번이 없어서 추가할 수 없다.
2. 삭제 이상(Delete Anomaly)
특정 정보를 삭제하면, 원치 않는 정보도 삭제되는 현상이다. 튜플을 삭제할 때 저장되어있는 다른 정보도 삭제되어 연쇄 삭제(Triggered Deletion)의 문제가 발생하는 경우를 의미한다.
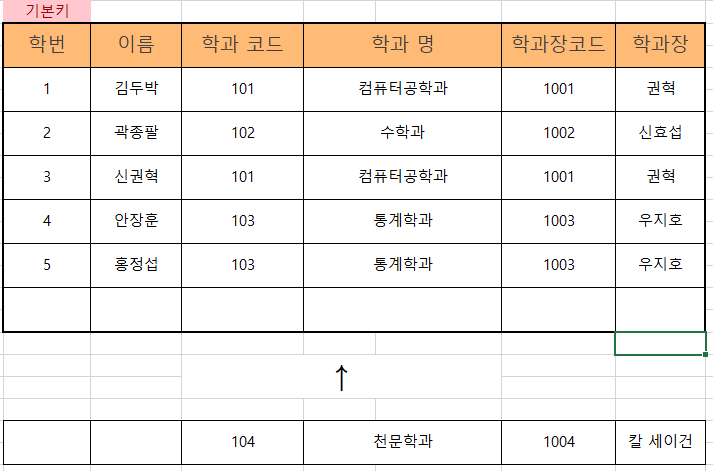
학번 2의 학생이 자퇴하여 대학교 테이블에서 데이터를 지우려 했으나 정규화 되지 않은 '학과의 데이터'도 함께 삭제된다.
3. 업데이트 이상(Update anomaly)
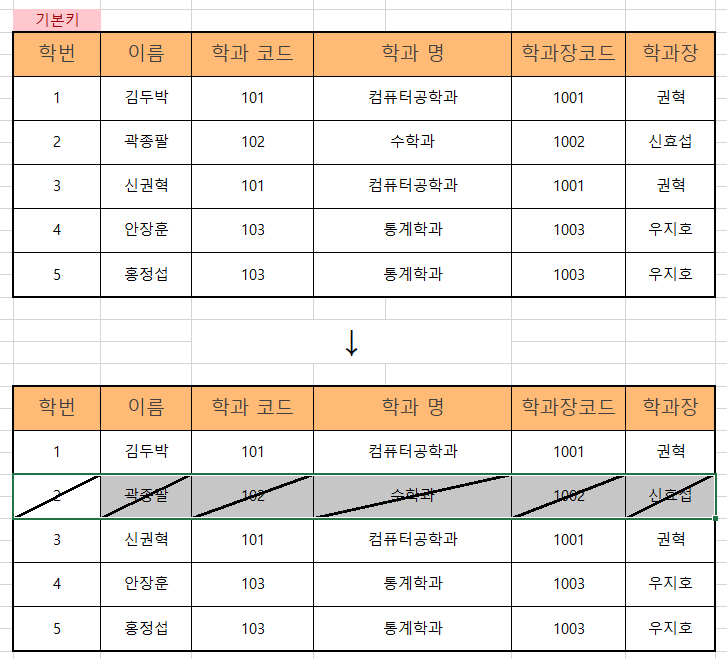
특정 데이터를 업데이트했는데, 정상적으로 변경되지 않은 경우 그리고 너무 많은 행을 업데이트하는 것이다. 만약 한 과에 천 명이 있는 학과 테이블에서 학과장이 변경되었을 때 천 명의 데이터를 모두 바꿀 수 없다. 만약 노가다로 바꾼다 하더라도 에러가 생길 수 있다.
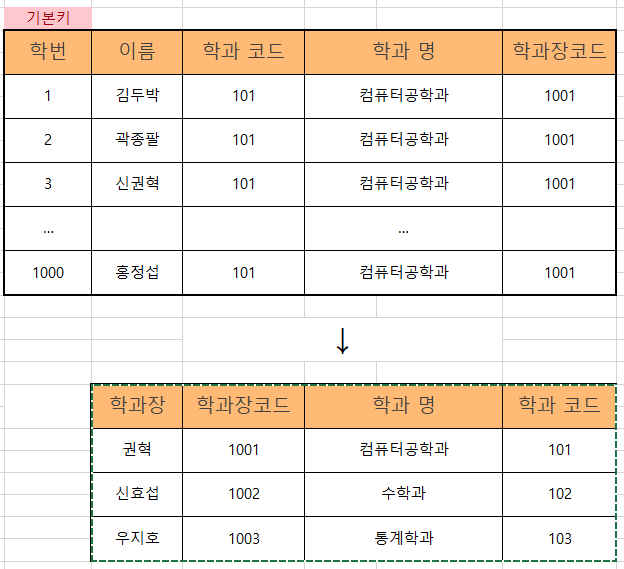
데이터를 모두 바꿀 수 없기때문에 테이블을 분리해 간단한 수정만 거칠 수 있도록 한다.
데이터 베이스에는 항상 이 세 가지 이상이 생길 수 있기 때문에 정규화를 필요로 한다.
하지만 정규화 설명에 들어가기 이전, 함수적 종속(Functional Dependency)을 미리 알아두는게 정규화를 이해하기에 좀 더 편하다고 생각이 들어 함수적 종속에 대하여 미리 설명하려고 한다.
함수적 종속(Functional Dependency)
DB에서 속성(Attribute)들 간의 종속 관계를 말한다. 두 개의 속성 값을 각각 X, Y라고 칭할 때, X의 값을 알면 Y의 값을 바로 식별할 수 있고, X의 값에 Y의 값이 달라질 때, Y는 X에 함수적 종속이라고 한다. 이 경우 X를 결정자, Y를 종속자라고 일컫는다. 이런 함수적 종속관계에는 완전 함수적 종속과 부분 함수적 종속 및 이행적 함수 종속이 있다.
완전 함수적 종속(Full Functional Dependency)
종속자가 기본키에만 종속되며, 기본키가 여러 속성으로 구성되어 있을경우 기본키를 구성하는 모든 속성이 포함된 기본키의 부분집합에 종속된 경우이다.
부분 함수적 종속(Partial Functional Dependency)
릴레이션에서 종속자가 기본키가 아닌 다른 속성에 종속되거나, 기본키가 여러 속성으로 구성되어 있을 경우 기본키를 구성하는 속성 중 일부만 종속되는 경우이다.
이행적 함수 종속(Transitive Functional Dependecy)
함수 종속 설명과 같이 세 개의 속성 값을 각각 X, Y, Z라고 칭할 때 X→Y, Y→Z 이란 종속 관계가 있을 경우, X→Z가 성립될 때 이행적 함수 종속이라고 한다.
정규화(Normalization)가 무엇이오?
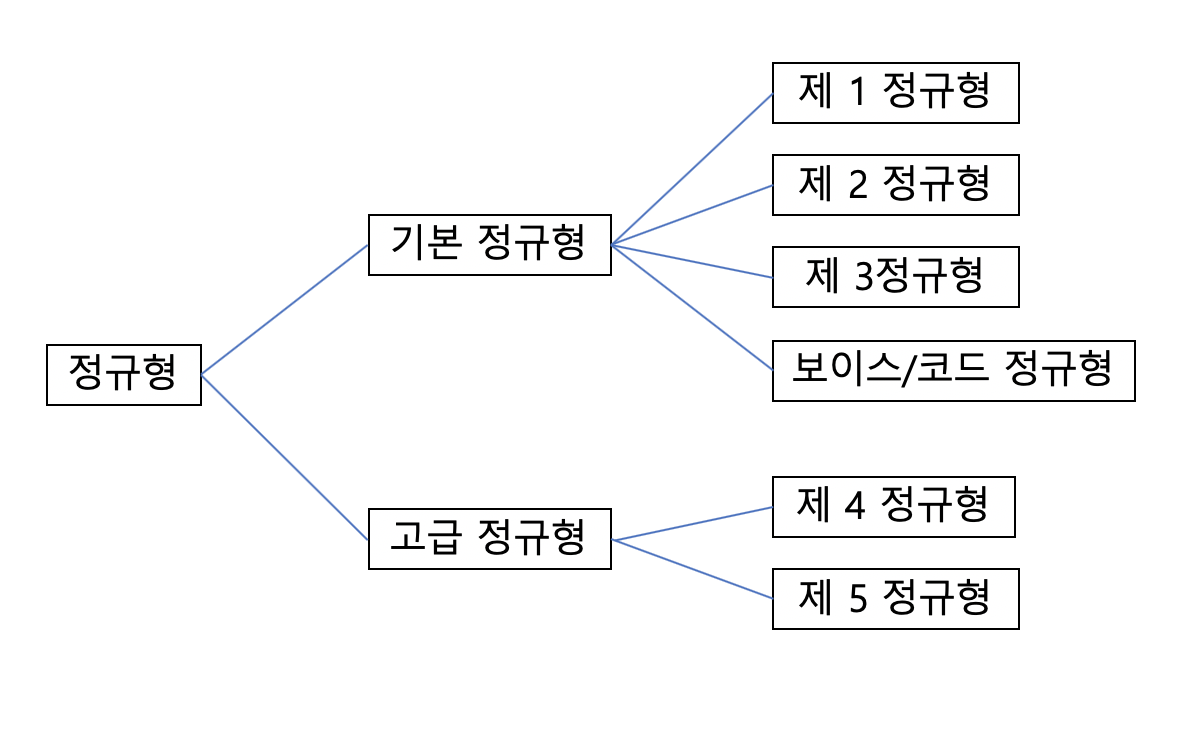
정규화는 관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화하는 프로세스이다. 기본 목표는 테이블 간에 중복된 데이타를 허용하지 않는다는 것이며 그로써 무결성(Integrity)를 유지하고 DB의 저장 용량 역시 줄일 수 있다.
정규화 과정에는 1NF, 2NF, 3NF, BCNF, 4NF, 5NF가 있으며 보통 BCNF 이상으로 정규화를 하면 연산시간이 길어진다는 단점이 나타나기 때문에 잘 하지 않는 편이다.
정규화의 순서

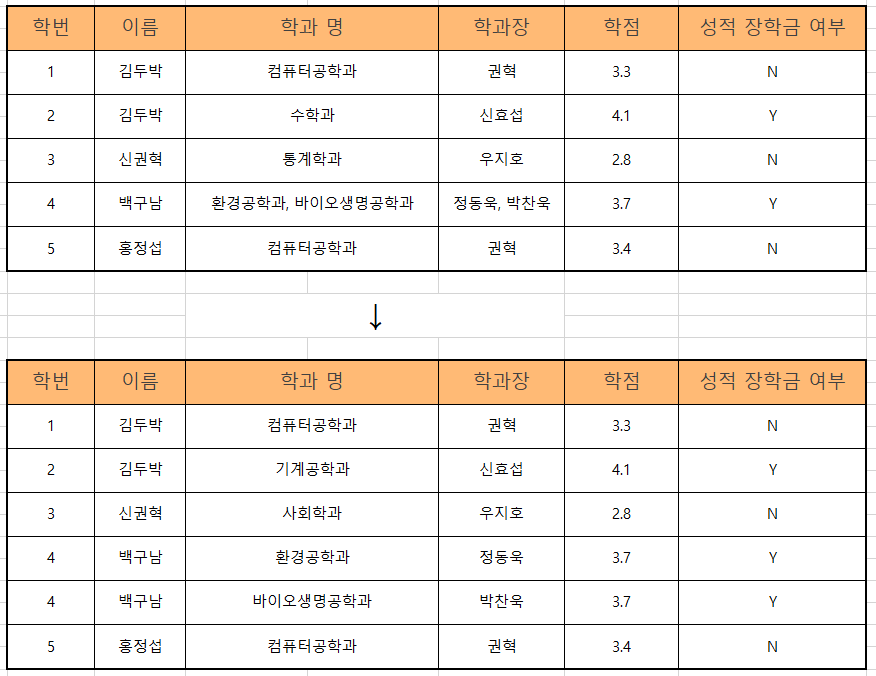
1NF(1차 정규화)
1차 정규화는 테이블의 컬럼이 원자값(Atomic Value, 하나의 값)을 갖도록 테이블을 분해하는 것이다.
아래의 이미지는 성적 장학금 여부를 기록한 테이블이다. 1차 정규화 이전 테이블에서 '백구남' 학생은 복수 전공 중이여서 한 칼럼 안에 두 개의 값이 존재한다.
1차 정규화에서는 이 값을 하나만 가질 수 있도록 분해한다.
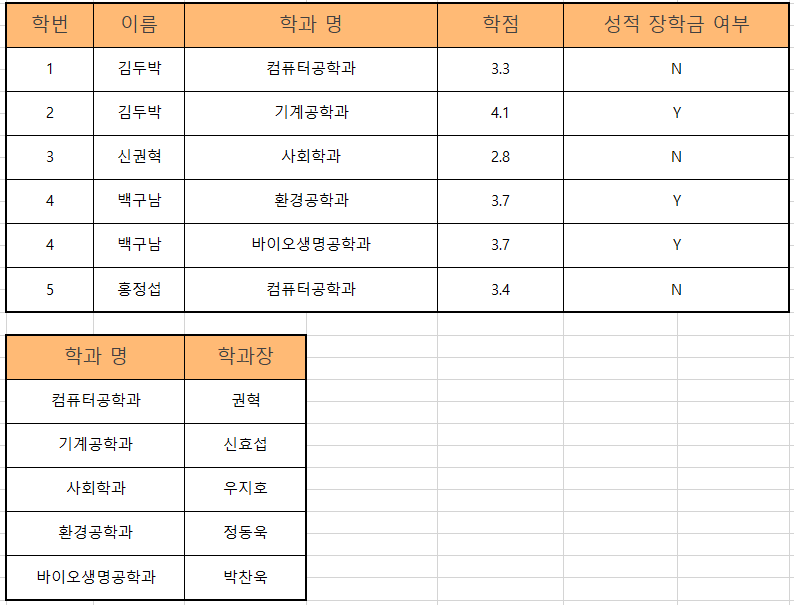
2NF(2차 정규화)
2차 정규화는 1차 정규화가 진행된 테이블에서 부분 함수 종속을 제거하고 모든 속성이 기본키에 완전 함수 종속되도록 릴레이션을 분해하는 것이다.
위의 이미지에서 1차 정규화가 끝난 테이블을 보면 기본키로 설정할 수 있는 것은 학번과 학과 명이 있다. 2차 정규화에서는 기본키를 제외한 이름, 학과장, 학점, 장학금 여부의 칼럼은 기본키에 종속이 되어야 한다. 분석해보면 이름과 학점, 장학금 여부는 학번에 종속되고 학과장은 학과 명에 종속된다. 그래서 아래의 이미지처럼 테이블을 분해해준다.
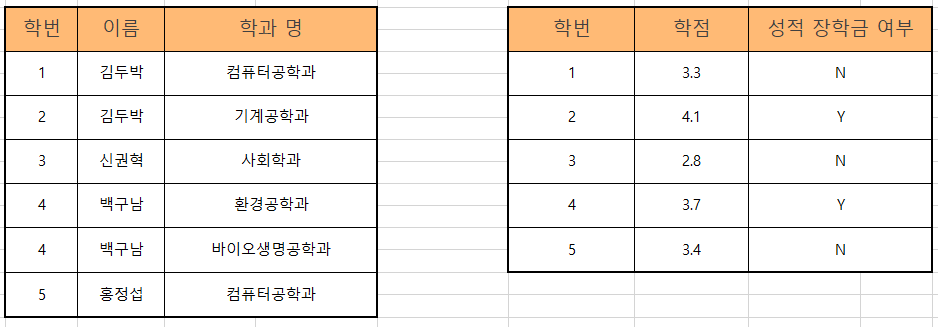
3NF(3차 정규화)
3차 정규화는 2차 정규화를 만족하면서 종속관계가 아닌 칼럼 간에 이행적 함수 종속이 있는 경우 그렇게 되지 않도록 릴레이션을 분해하는 것이다.
2차 정규화가 끝난 테이블을 기준으로 X-Y-Z를 대입해보면 학번(X)을 통해 이름(Y)이나 학과 명(Y)을 알 수 있고 동명이인이 존재하기때문에 학번과 이름, 혹은 이름과 학과명을 통해 학점(Z)이나 장학금 여부(Z)를 알 수 있다. 제대로된 이행적 함수 종속이 이루어지지 않기때문에 이름과 학과 명을 학번과 합쳐 아래처럼 테이블을 분리해준다.
BCNF(Boyce and Codd Normal Form)
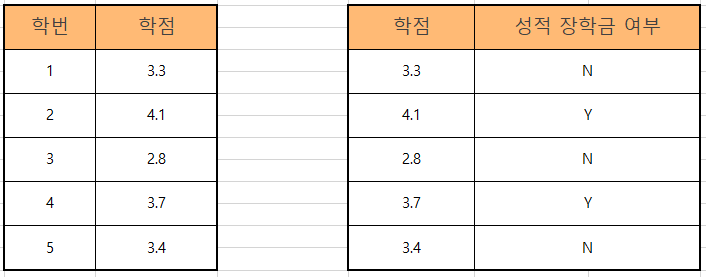
BCNF는 3차 정규화를 진행한 테이블에 대해 모든 결정자가 후보키가 되도록 테이블을 분해하는 것이다. 3차 정규화가 끝난 테이블에서 기본키와 후보키는 학번과 학점이다. 하지만 학번이 장학금 여부를 결정하는 것이 아닌 학점이 학점을 결정하고 학점이 성적 장학금 여부를 결정하기 때문에 두 테이블을 아래 이미지처럼 나누어 주어야 한다.
생각보다 정규화 테이블 예시 생성이 힘들었다..
사람들이 의외로 정규화를 그냥 복붙하는 느낌이 많았고 예시도 어디서 긁어온 것들이 많았다. 특히 3차 정규화의 설명도 그랬는데 내가 이해할 때에는 이행적 함수 종속이 제대로 이루어 지지 않는 테이블을 분해한다고 생각했는데 그냥 이행적 함수 종속이 있는 테이블이 3차 정규화 대상이라는 글이 많았다.
많이 참조하기는 했으나 사람들의 예시에서 오류가 너무 많아서 이게 왜 그런건지 이해하는데 생각보다 시간을 많이 잡아먹었다.. 그냥 거의 서로 배끼고 배끼다보니 제대로 이해 안 하고 쓰는가보다 싶을정도로..ㅜㅜㅜ 물론 나도 이상한 부분이 많다고 생각하나 적어도 테이블 분해하면서 칼럼 하나를 날려버린다거나 이런건 없기때문에 그나마 낫지 않을까 하하
여튼 현타가 조금 오는 정규화 정리였다.
