3D shape representation [EECS 498-007 / 598-005]
[EECS 498-007 / 598-005: Deep Learning for Computer Vision] 23강을 요약했습니다.
3D vision tasks

이 강의에서는 두 가지 task에 대해 배울 것이다.
1. 2d image에 대한 3d shape prediction
2. 3d shape input에 대한 classification/segmentation 등
모두 fully supervised한 과정을 다룬다.
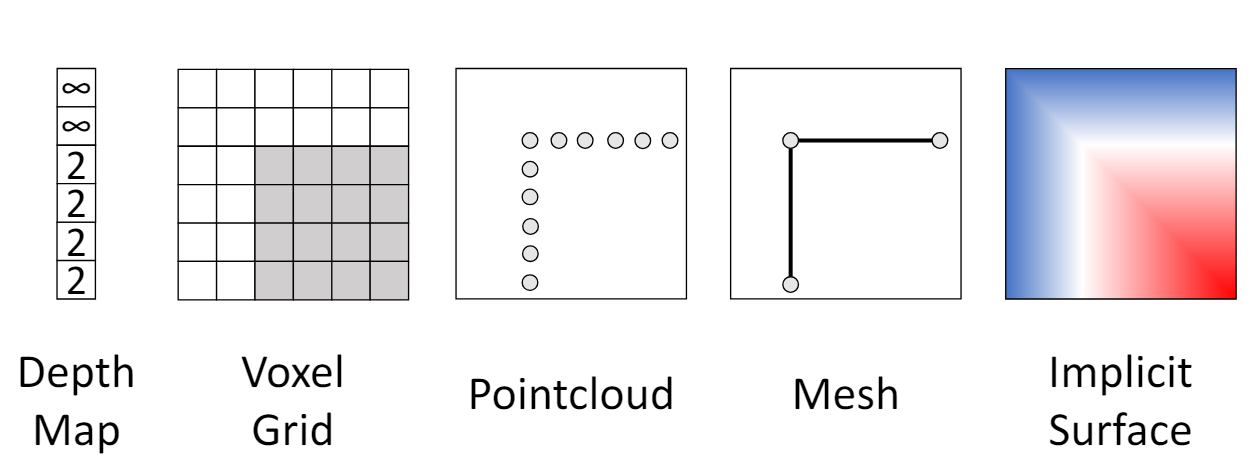
3D shape representations
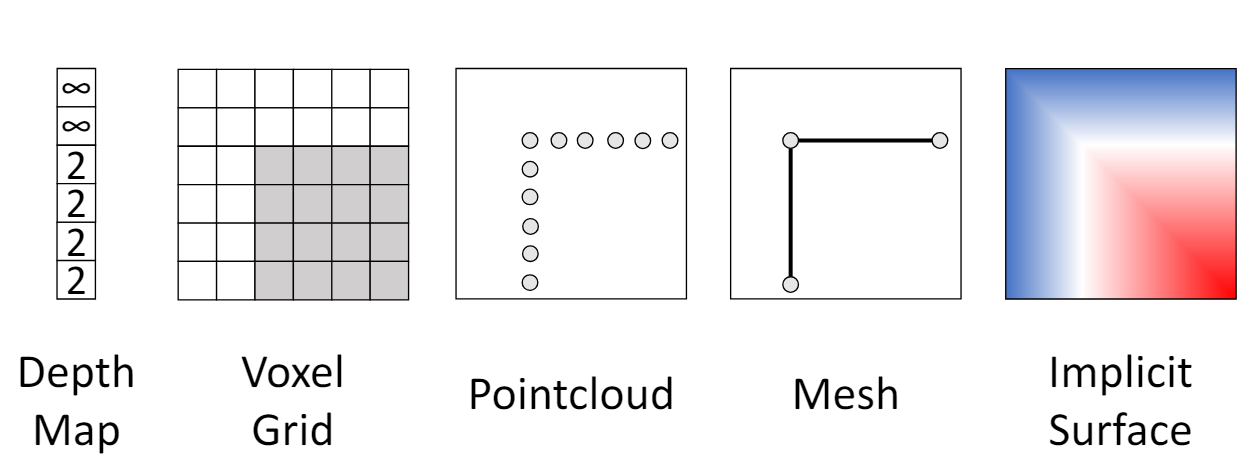
1. Depth map

pixel과 camera의 거리를 depth map으로 정의한다. RGB 이미지에 4번째 channel인 depth map을 추가하는 것이다.
- 단점
다만 occluded object에 대한 정보를 얻을 수 없다. 예를 들어, 소파에 가려진 부분의 책장은 실제로는 존재하지만 이미지로는 정보를 얻을 수 없다. 이 때문에 RGBD 이미지를 3d가 아닌 2.5d 이미지라고 부르기도 한다.
Depth Map Network
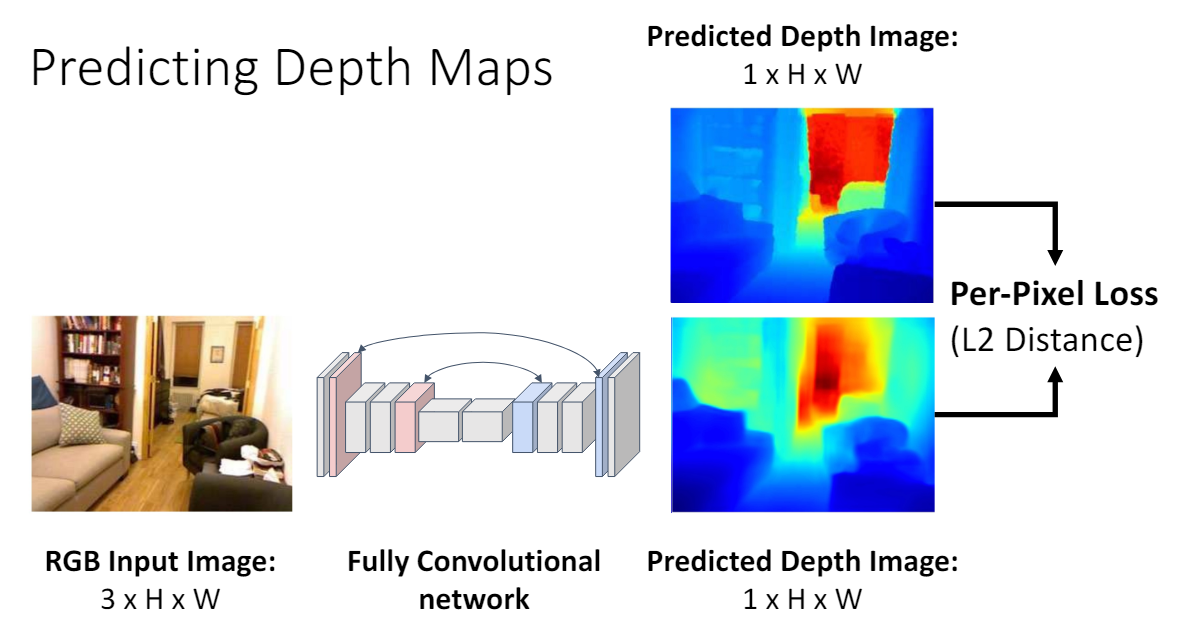
Fully Convolutional Networks for Semantic Segmentation
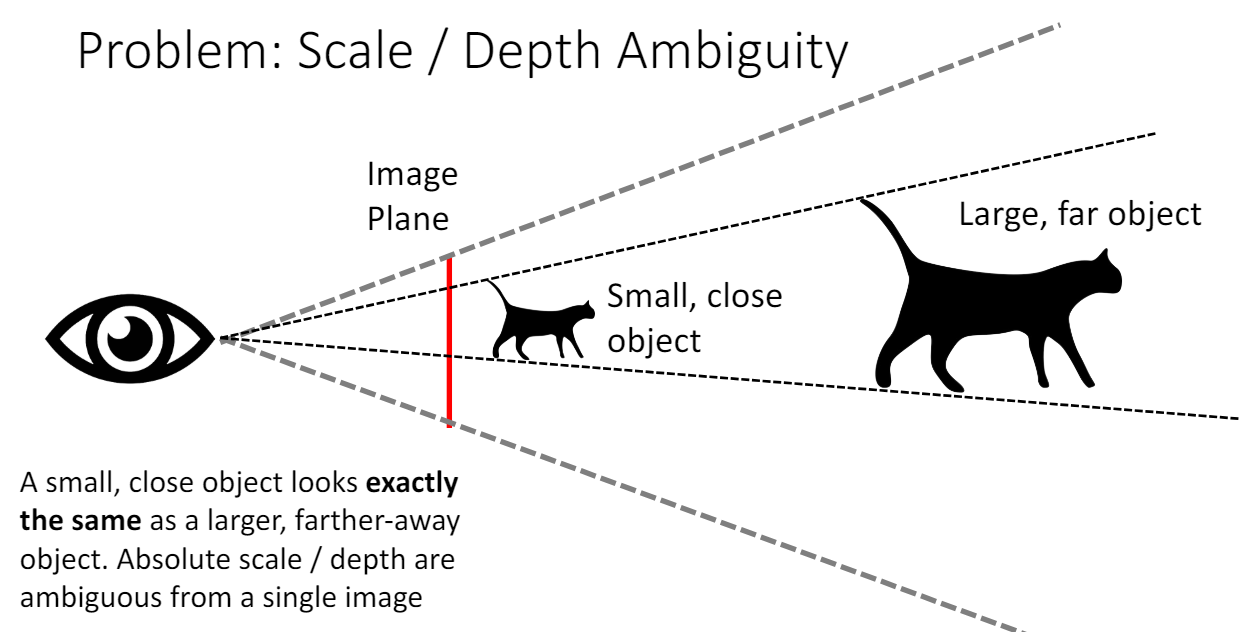
- Scale
Depth가 1인 작은 고양이와 depth가 2인 2배 크기의 고양이를 이미지 한장으로는 구분할 수 없다는 문제점이 있다.
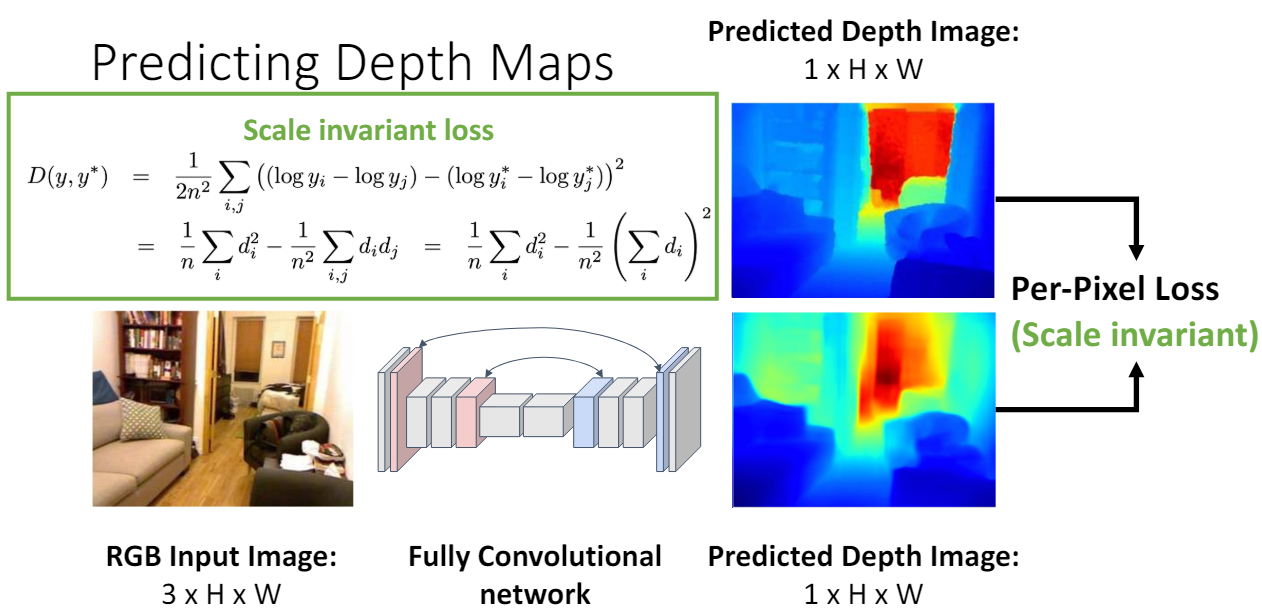
그래서 scale invariant한 loss를 사용한다. 이 loss를 사용하면 이미지에 있는 모든 물체의 depth를 2배, 크기를 2배로 예측했어도 loss가 0이 된다.
자세한 정보는 “Depth Map Prediction from a Single Image using a Multi-Scale Deep Network”, NeurIPS 2014
Surface Normal
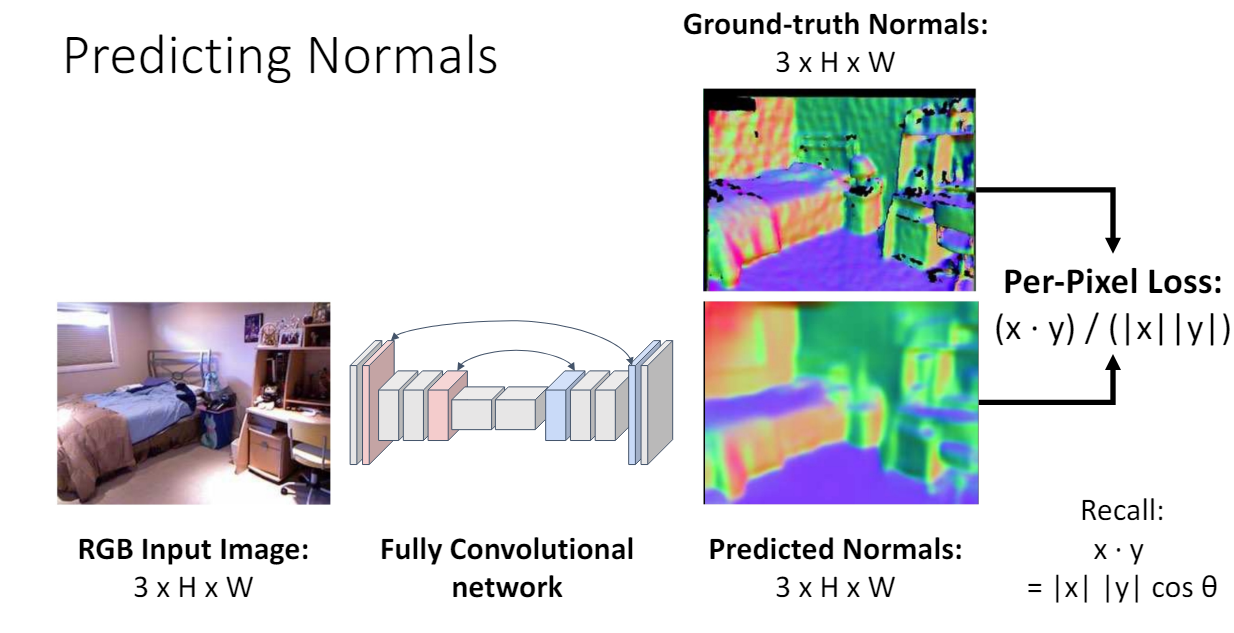
depth 외에도 추가적으로 surface normal 정보를 얻을 수도 있다. 각 pixel이 실제 물체의 3차원 normal vector 정보를 가지고 있다.
(오른쪽 그림은 blue: up, red: right, green: left로 visualization 한 것이다. )
- Loss
Loss를 구할 때는 각 pixel의 3차원 vector에 대한 각도 차이를 본다.
2. Voxel Grid
세상을 마인크래프트로 바꾼다고 생각하면 된다..ㅎㅎ
3d grid에서 물체가 존재하는 위치의 블록은 on시키는 것이다.
- 단점
다만 디테일한 structure를 모두 얻으려면 high spatial resolution(촘촘한 grid)이 필요하고 high resolution이 되도록 scale하는 것은 쉽지 않다.
또한 high resolution voxel grid는 memeory usage가 엄청나다. 1024^3 voxel grid는 4GB memory가 필요하다.

3D voxel to Classification
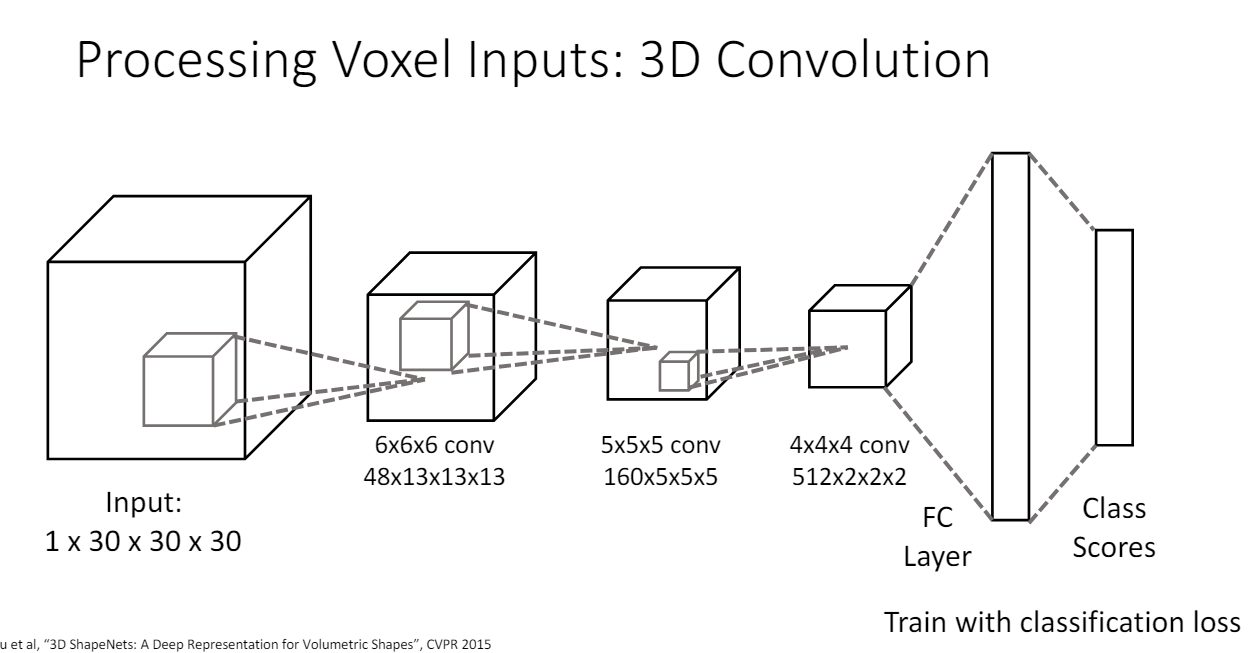
3d voxel이 주어졌을 때 voxel이 의자인지를 classification하는 것은 3d convolution을 사용하면 된다.
- 4d input
30x30x30 공간, 공간이 채워졌는지를 나타내는 binary channel
3d convolution 이후에는 각 pixel에 48dim feature vector
Image to Voxel
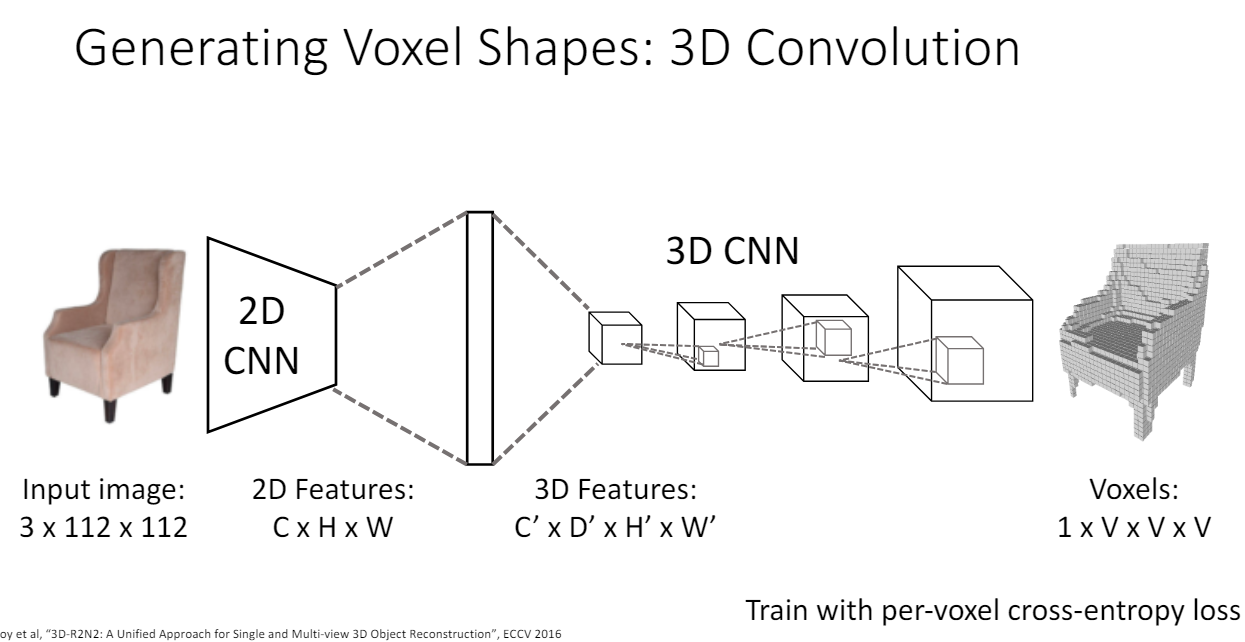
2D CNN ouput(CHW)에서 flatten을 한 뒤에 fully connected layer를 거친다. 그리고 4d tensor(CDH*W)로 reshape한다. 이 과정은 spatial dimension을 추가하기 위해서 거치는 과정이다.
하지만 3d convolution의 computational cost는 무려 cubic하게 증가한다.
그래서 2d convolution만을 활용하는 방법이 있다.
Voxel Tubes
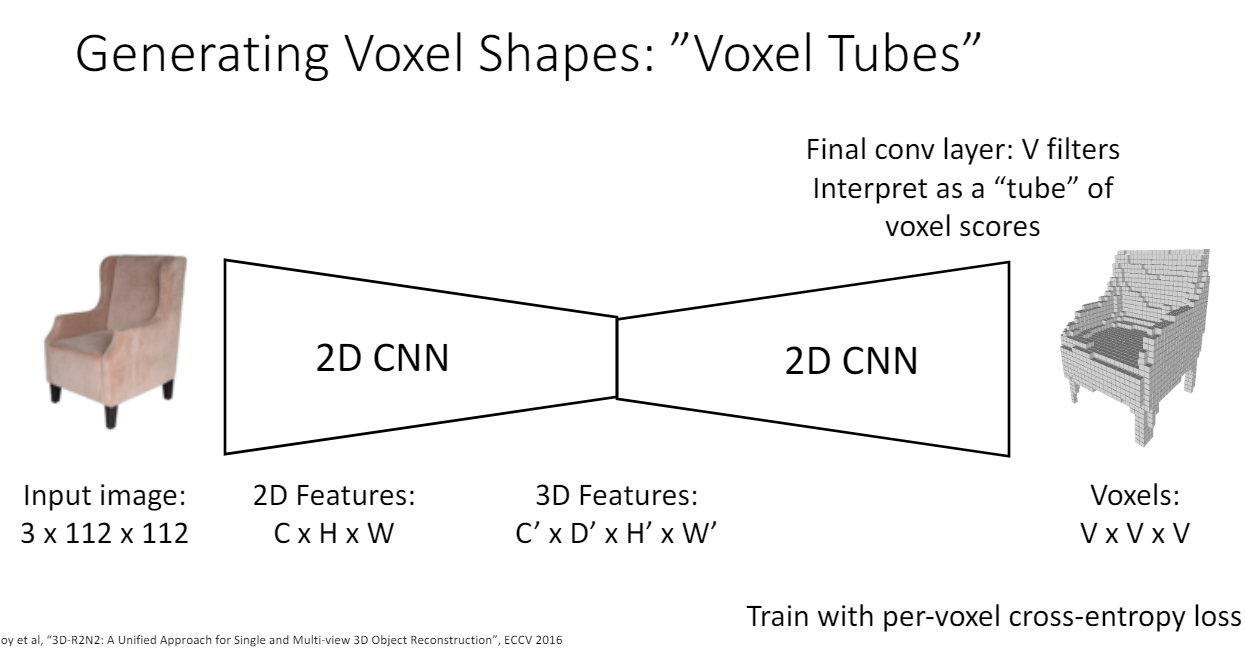
마지막 output이 V channels V V가 되도록 하여 4d voxel tensor(1VV*V)를 예측하도록 한다. (V channel(tube)에서 score이 1에 가까우면 해당 위치에 voxel이 존재하는 방식?)
- 단점
다만 3d가 아닌 2d convolution을 사용하면 z축 방향의 invariance 성질을 잃게 된다. xy방향으로는 2d convolution filter가 이동하면서 invariance 성질을 유지한다.
Oct-Tree
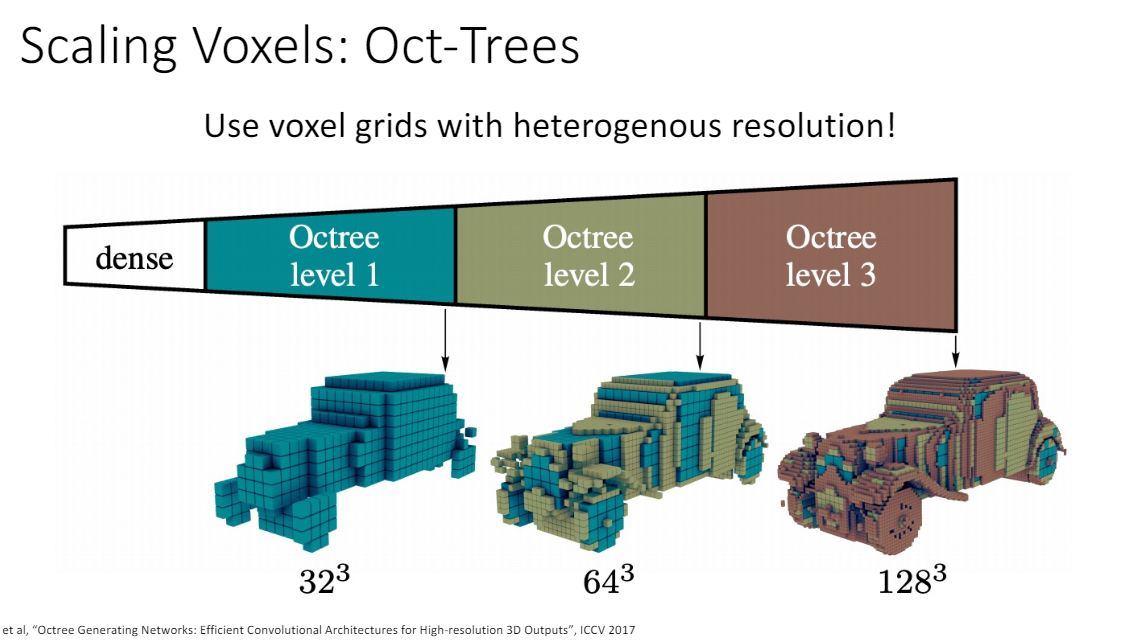
low resolution에서 형체를 만들고 세부적인 디테일을 채워나가는 방식
3. Pointcloud
물체를 3d 공간에 있는 P개의 point로 나타낸다.
fine detail이 필요한 부분에 point 개수를 더 많이 줘서 디테일하게 표현할 수 있다는 장점이 있다.
마찬가지로 pointcloud 결과에 대해 3d explicit shape을 얻으려면 post processing이 필요하다.
Point cloud to Classification
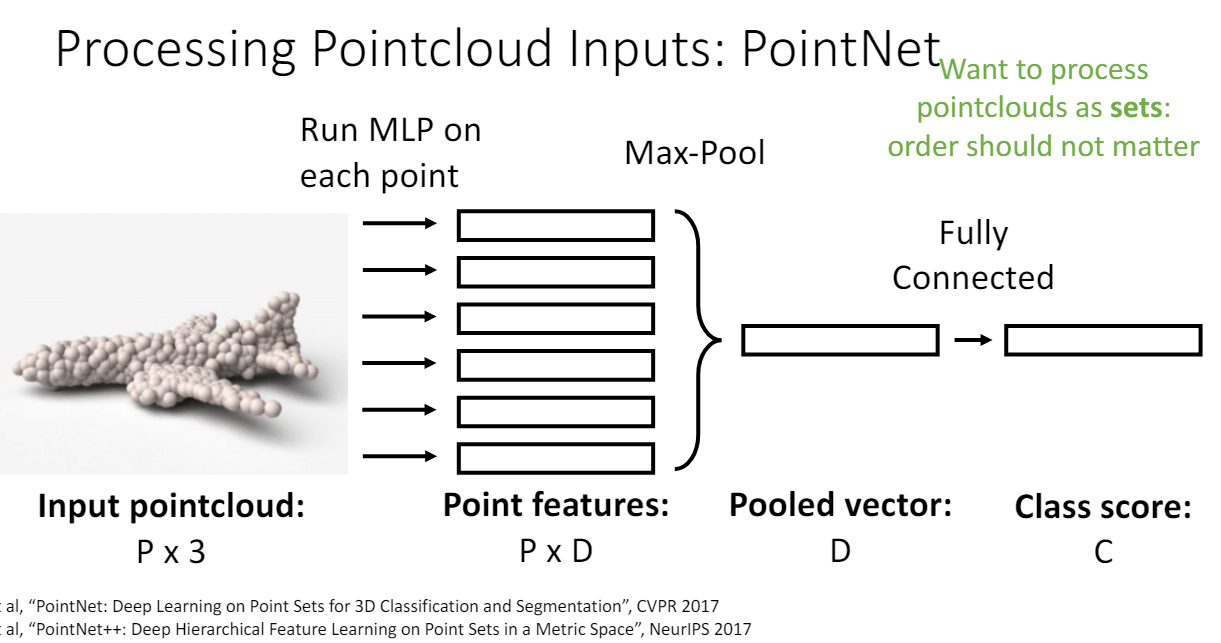
point의 순서가 영향을 주면 안되므로 output이 각 point의 순서와 invariant하게 학습해야 한다.
- 각 point의 3d 좌표를 여러 fully connected layer에 독립적으로 통과시킨다.
- 모든 feature vector를 max pooling하여 하나의 vector을 얻는다. 이때 max pooling은 순서와 무관하다.
Image to Pointcloud
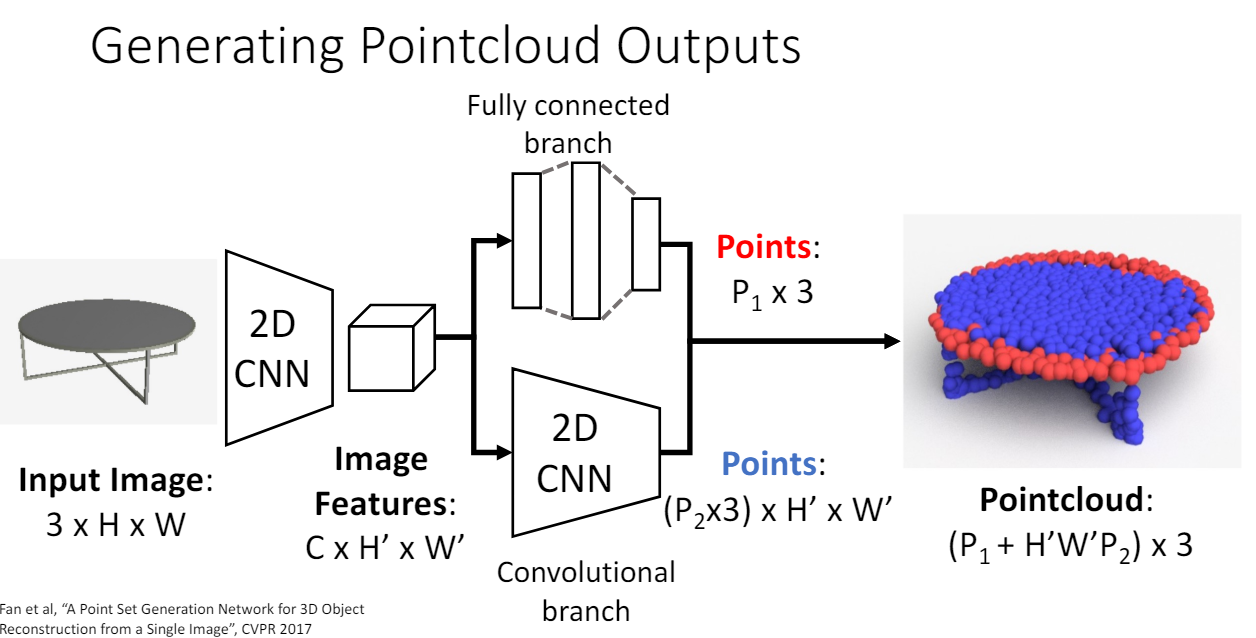
- Pointcloud loss 구하기 - 두 개의 pointcloud set이 얼마나 다른가?
Chamfer distance

⇒ 파란색 점들의 집합 과 주황색 점들의 집합 사이의 거리를 구해보자.
1st term : 각 파란색 점에 대해 가장 가까운 주황색 점과의 L2 distance

2nd term: 각 주황색 점에 대해 가장 가까운 파란색 점과의 L2 distance
Loss도 point cloud에 대해 order invariant하다.
4. Mesh
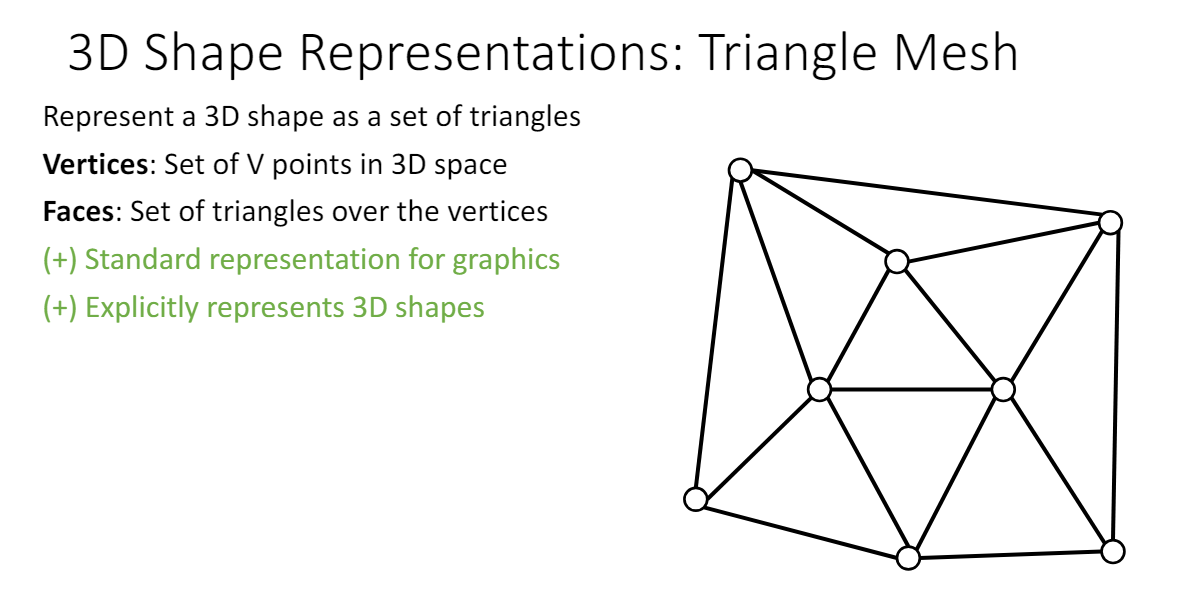
Triangle mesh: 3D shape을 Vertex(점)과 Face(삼각형)을 사용하여 나타낸다.
평평한 면을 face로 효과적으로 나타낼 수 있고, fine area는 face를 많이 위치시키면 된다. 또한 vertex에 feature 정보가 포함되어 있는 경우(RGB color, texture coordinates, normal vector 등), coordinate interpolation으로 중간 값의 정보를 faces에 넣어줄 수 있다는 장점이 있다.
그러나 neural net으로 학습하기는 쉽지 않다.
추가) Ray tracing & Nerual rendering
모든 물체는 polygon mesh(다각형들의 집합)으로 표현할 수 있다. 물체를 구성하는 모든 polygon에 반사되는 빛을 추적하고, 추적한 빛들을 종합해 물체의 2D이미지를 생성하는 방법이다.
딥러닝 = 미분가능한 함수를 학습
nerual rendering = 미분가능한 rendering function을 학습, 이를 통해 2D 이미지 생성
다각형으로 쪼갤 필요가 없어 계산량 감소
Pixel2Mesh
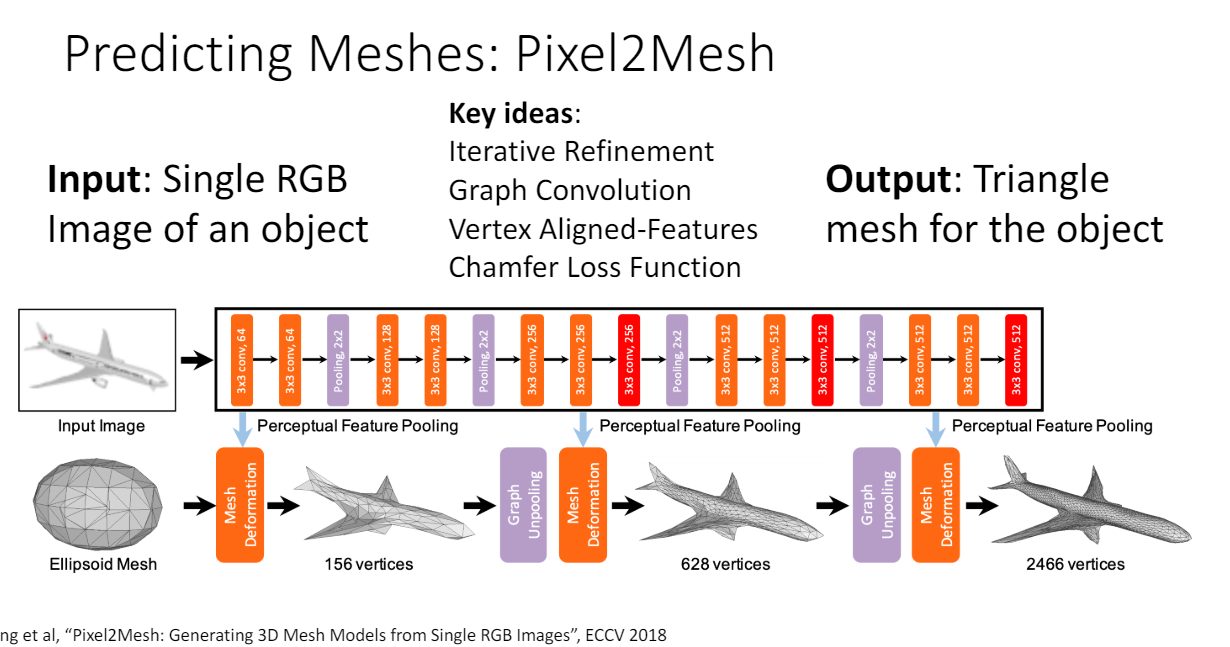
< Key Ideas >
- Iterative Refinement
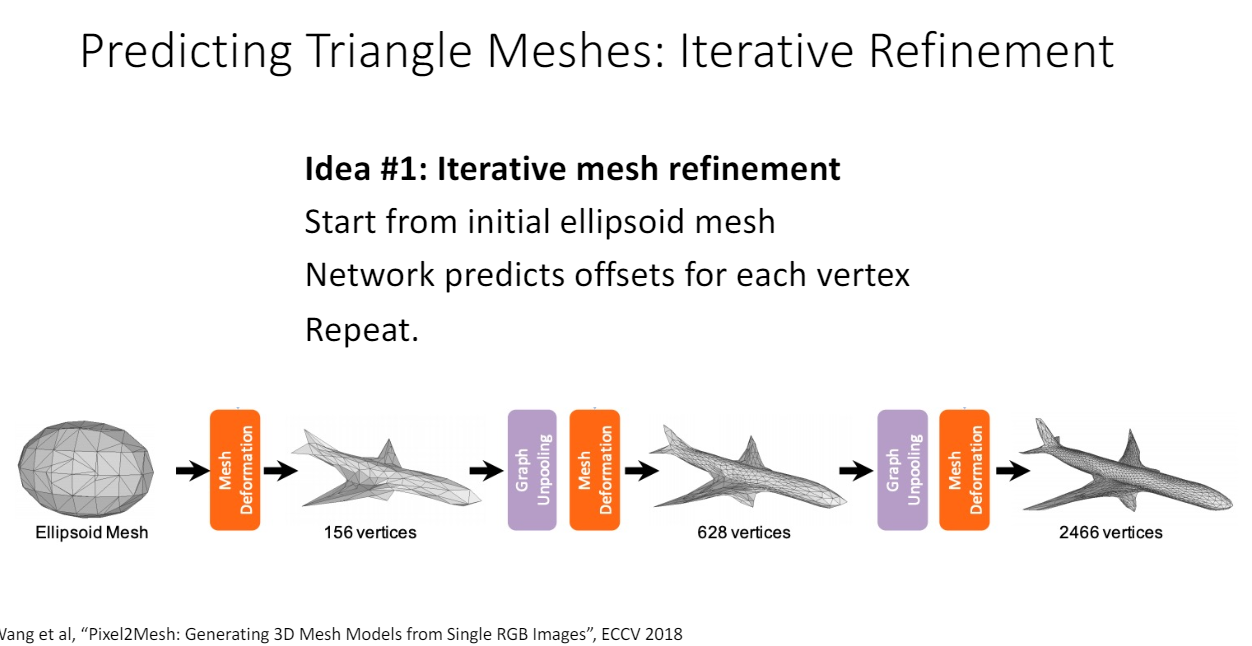
scratch에서 시작하지 않고 ellipsoid mesh에서 시작해서 offset을 예측한다.
- Graph Convolution
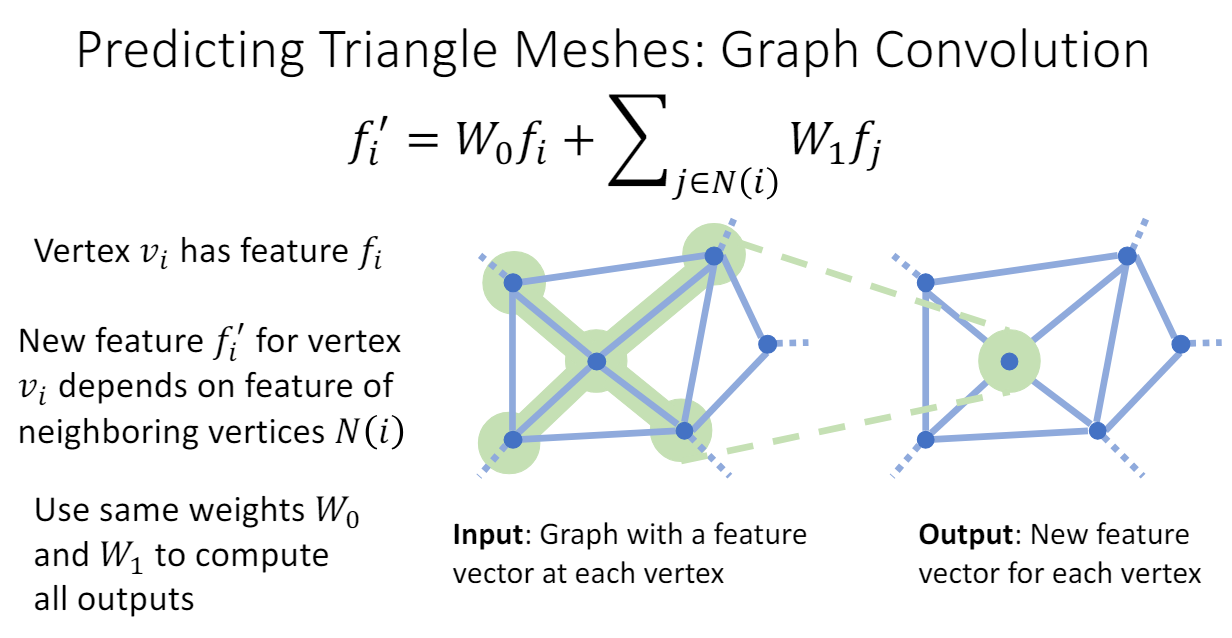
Graph convolution 을 통해 각 vertex의 feature vector를 구한다.
⇒ f_i’ = + 이웃한 vertex의
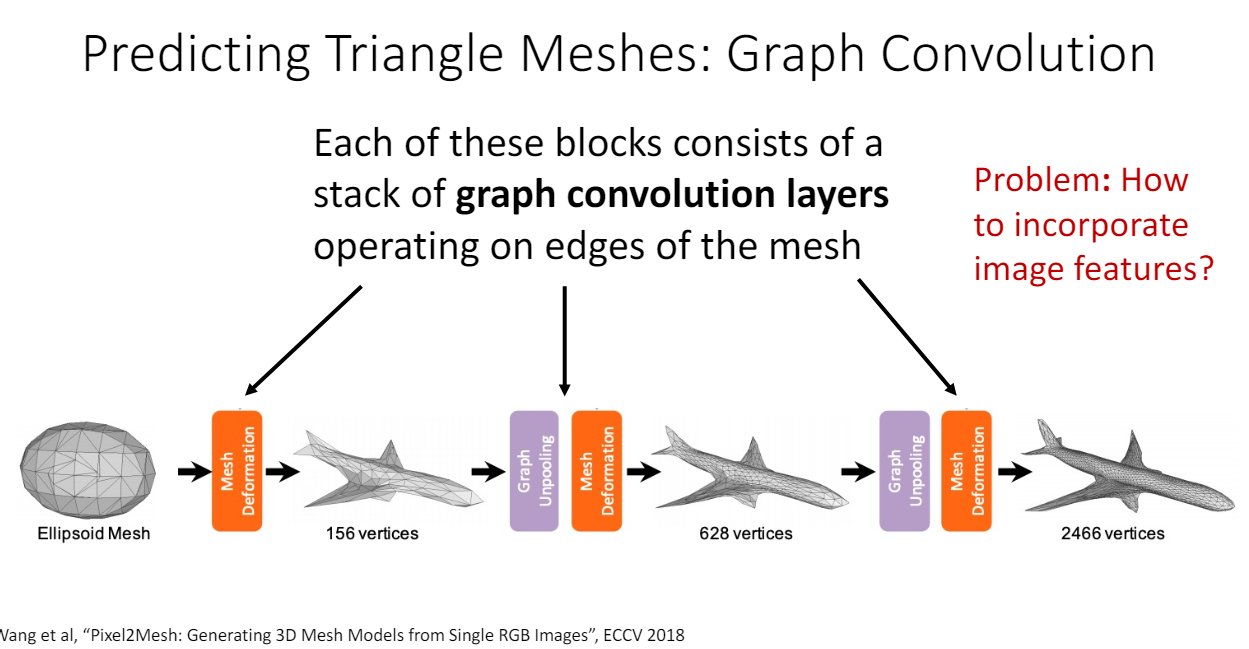
mesh deformation block마다 graph convolution이 포함되어 있어서 이 feature vector 정보로 offset을 예측하게 된다.
그렇다면 image에서 어떻게 feature를 각 vertex으로 가져올까?
- Vertex-Aligned Features

- image에서 CNN을 통해 feature vector을 얻는다.
- GT 3d mesh에서 projection을 한다.
- 각 vertex의 projection 점의 위치에 대해
bilinear interpolation을 통해 정확한 위치에서 대응하는 feature vector 값을 가져온다.
- Loss
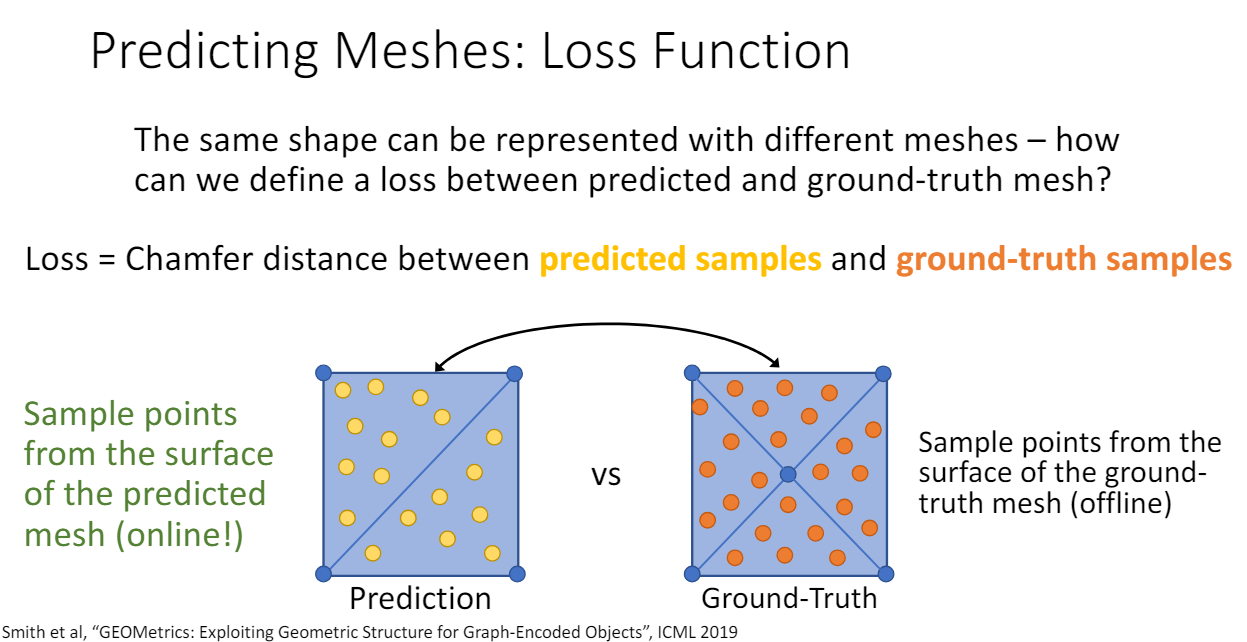
같은 모양이 여러 가지 mesh로 표현될 수 있는데 loss를 모두 같게 하려면 어떻게 해야 할까?
GT mesh에서 sampling한 pointcloud와 prediction mesh에서 sampling pointcloud에 대해 chamfer distance로 loss를 계산한다.
5. Implicit Surface
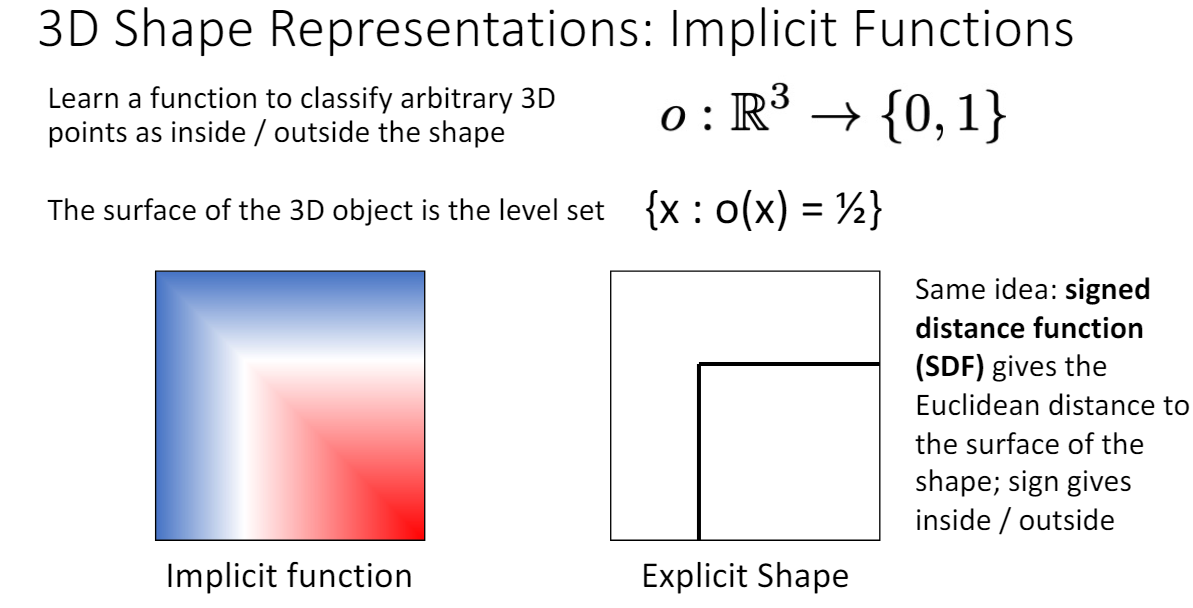
주어진 위치가 shape의 내부에 있는지 외부에 있는지를 판단하는 함수를 학습(implicit function)
o(x)=1/2인 지점이 경계, 1에 가까울수록 경계 바깥(파란색), 0에 가까울수록 경계 내부(빨간색)에 있는 위치이다.
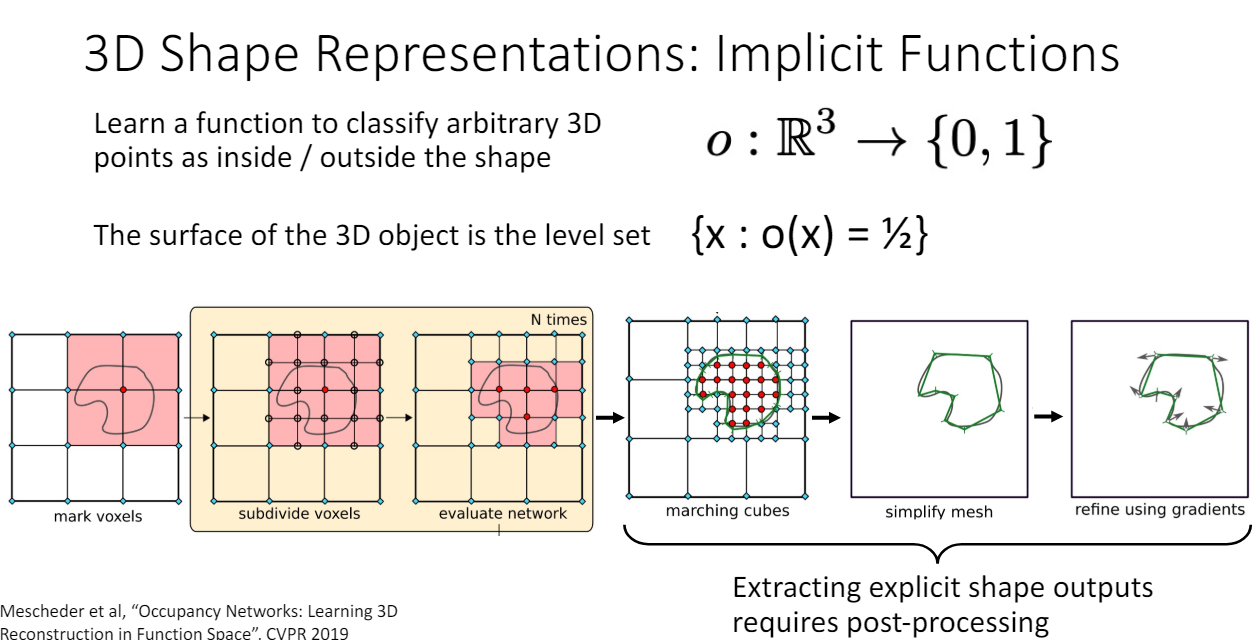
이 함수 학습을 완료하면 voxel space의 여러 점을 함수에 넣어서 경계를 찾는다. 이때 sampling하는 공간을 점점 세밀하게 subdivide하는 방식을 사용하므로 oct-tree처럼 multiscale output이 가능하다. 또한 implicit function에 대해 3d explicit shape을 얻으려면 sampling을 한 뒤에도 위와 같은 post processing 과정이 필요하다.
이 representation을 사용하는 방법 중에서 유명한 것으로 NeRF(2020)가 있다. NeRF에 관한 내용은 다음 포스트에서 따로 요약하였다. NeRF 논문리뷰
3D shape comparison metrics
F1 scoreis the best!
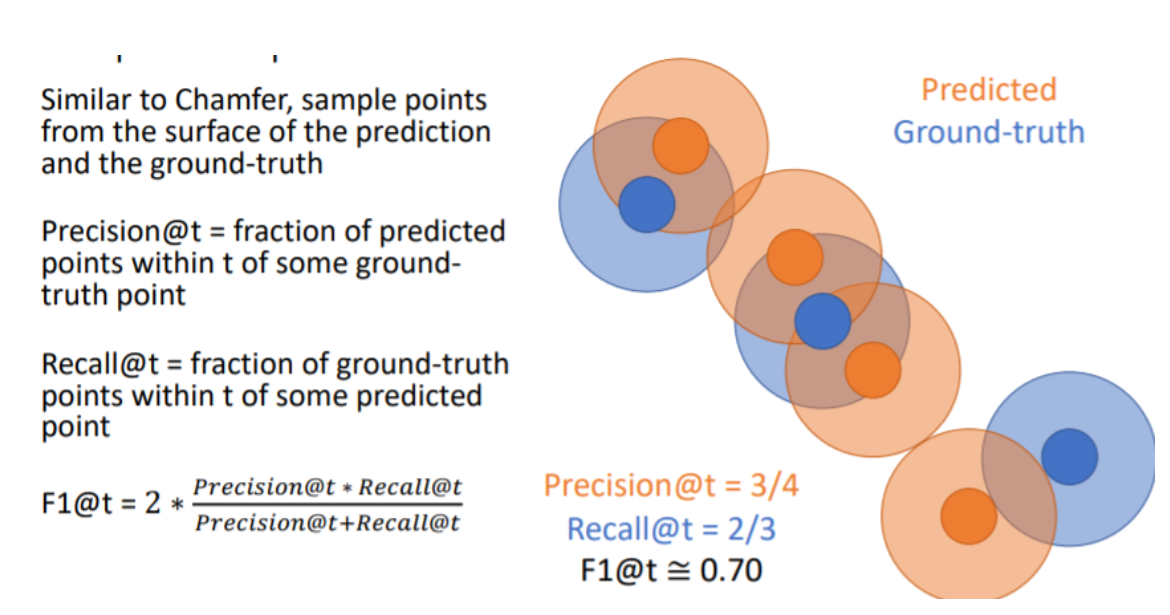
precision과 recall의 조화평균인 F1 score이 outlier에 robust해서 가장 좋다.
Mesh RCNN
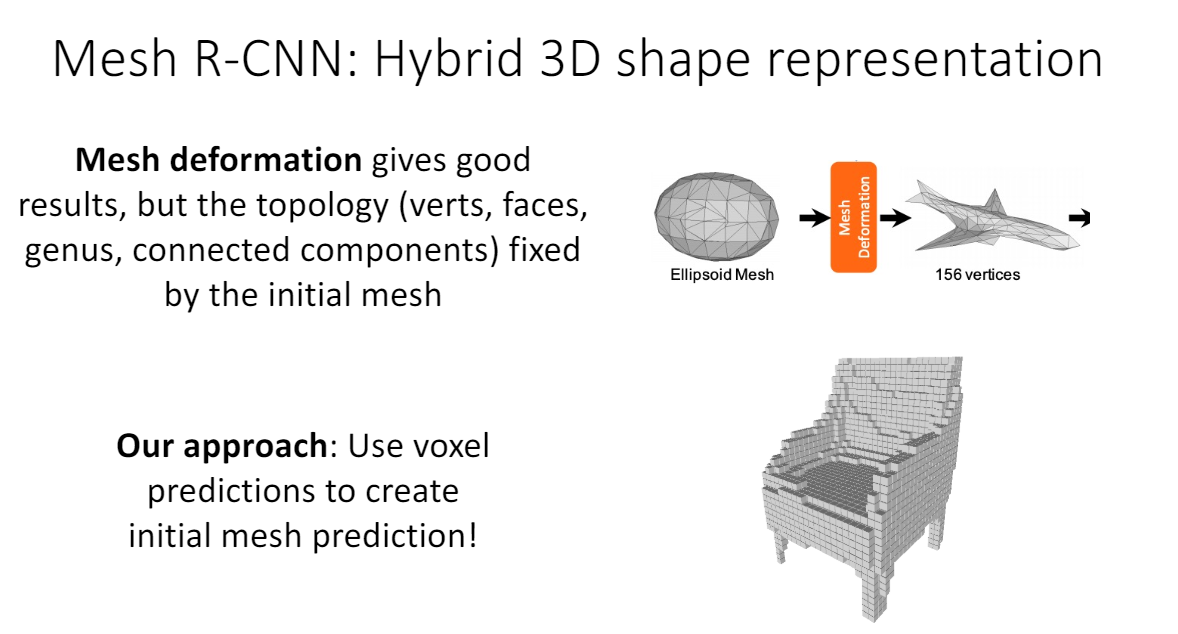
pixel2mesh에서는 initial mesh에 따라 만들 수 있는 모양이 제한된다. 예를 들어, Topology에 의해 sphere에서 절대 donut이 될 수 없다. 그래서 mesh RCNN에서는 mask rcnn 결과에 먼저 voxel prediction으로 ellipsoid mesh를 만들고 나서 mesh를 만든다.
