
- 이 글은 ShapeVAE (3Dshape2vecset, michelangelo) 와 SOTA 3D Latent Diffusion 인 Trellis, Hunyuan3D 에 대한 상세한 Review 가 포함되어 있습니다.
들어가며
Diffusion. Imagen과 DALL·E를 거쳐 Stable Diffusion 과 Midjourney 에 이르기까지, Diffusion 은 GAN 을 압도하며 현대적인 2D 생성 모델의 표준이 되었다. 특히, Latent Diffusion 의 등장은
- "Latent 공간에서 Diffusion을 적용 → 연산량 절감 + 고해상도 이미지 생성 가능"
이란 기치 아래, 성능과 효율성을 동시에 갖춘 2D 생성 모델을 제시하며 실제 서비스에 적용 가능한 속도와 품질을 구현하는 데 성공했다.
생성 모델의 확장은 2D를 넘어 Video 와 3D 분야로 이어지고 있다. 2024년에는 Sora, DreamMachine (Ray), Veo 등의 비디오 생성 모델이 등장하며 모달리티 확장의 가능성을 보여주었고, 이제는 비디오를 넘어 3D domain 에서도 latent diffusion 기반 모델들이 그 가능성을 증명해 나가고 있다.
이번 글에서는 3D Latent Diffusion 의 개념과 그 핵심이 되는 ShapeVAE 를 분석하고, 기존의 Score Distillation Sampling (SDS) 이나 NeRF 기반 Large Reconstruction Model (LRM) 의 한계를 어떻게 극복하는지를 살펴본다. 또한, SOTA 3D 생성 모델인 Trellis와 Hunyuan3D 를 비교 분석하며, 최신 3D 생성 모델들의 설계 차이와 특장점을 깊이 있게 탐구해보자.
Preliminary: What is Latent?
| RBF Network | Gaussian Mixture Model | 3D Gaussian Splatting |
|---|---|---|
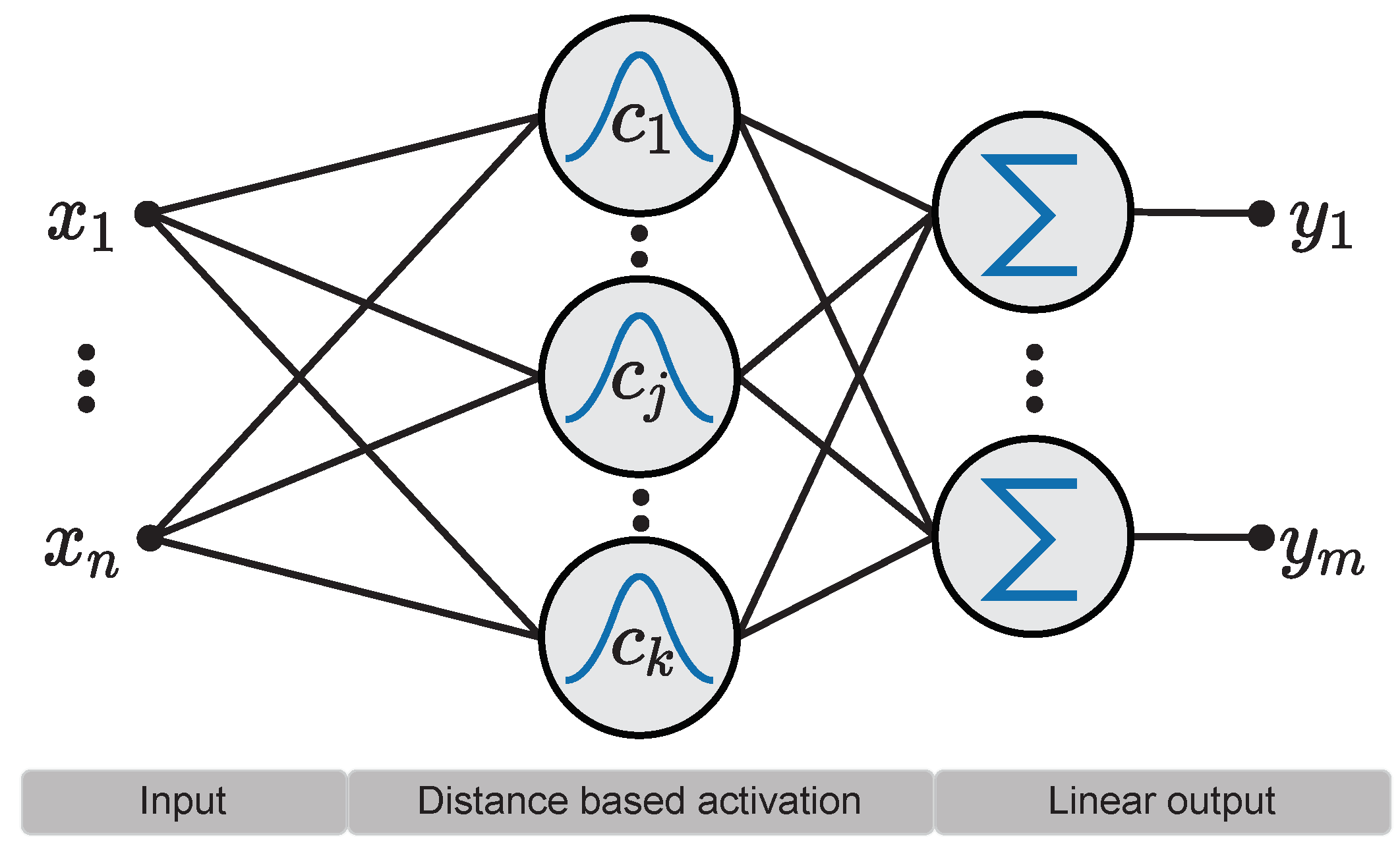 | 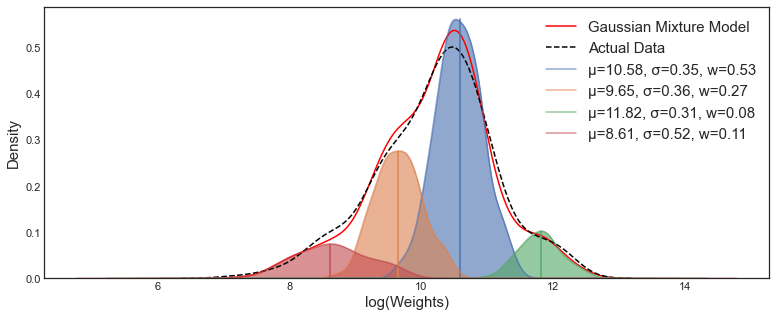 |  |
고전 Machine Learning 에서의 RBF neural network, Gaussian Mixture Model (GMM) 을 떠올려보자. 둘 모두 핵심은 결국,
-
여러 개의 basis 와
-
각 basis 의 weight
를 결합하여 어떠한 데이터 (확률 분포) 를 근사하는 것이다.
Equation: Radial Basis Function (RBF)비슷한 관점으로 3D Gaussian Splatting 도 해석해볼 수 있는데,
-
여러 basis (3D gaussian primitives)
-
각 basis 의 weight (각 gaussian 의 opacity)
의 결합으로 어떠한 데이터 (3D scene 에 대한 multi view observations) 을 근사하는 것으로 볼 수 있다.
Equation: 3D Gaussian Splatting여기서 RBF, Gaussian primitives 는 각각 learnable paramter (e.g., mean, variance) 를 가지며, 학습 과정에서 최적화하게 된다.
관점을 조금 바꿔서 생각해보면, 이러한 basis (primitive) 들은 data distribution 의 의미를 축약하는 일종의 ‘latent vector' 로, 전체는 ‘latent vector set’ 으로 해석할 수 있을 것이다.
RBF, 3D GS 등은 basis representation 을 human crafted 로 정의하고 있는 것인데, 알고 싶은 data distribution 에 대해서 learnable 하게 basis 를 학습하면 그것이 곧 Deeplearning 에서의 Representation Learning 을 대변한다.
1. ShapeVAE: Representation Learning for 3D Shape
Goal: Representation Learning for 3D Shape
ShapeVAE 란 3D shapes data 에 대해 정의된 AutoEncoder (VAE) 이다. 여타 모든 ShapeVAE 들의 목적은 다른 domain 의 LDM 에서의 AutoEncoder (VAE) 와 그 역할이 같다.
'Input Data 에 대해 semantically meaningful 한 learnable representation 을 확보'
하는 것.
대표적으로 다음과 같은 연구들이 있으며,
모두 비슷한 형태의 pipeline design 을 갖는다. 사실 특별할 것도 없는 AutoEncoder 구조이며, 다음과 같은 특징이 있다.
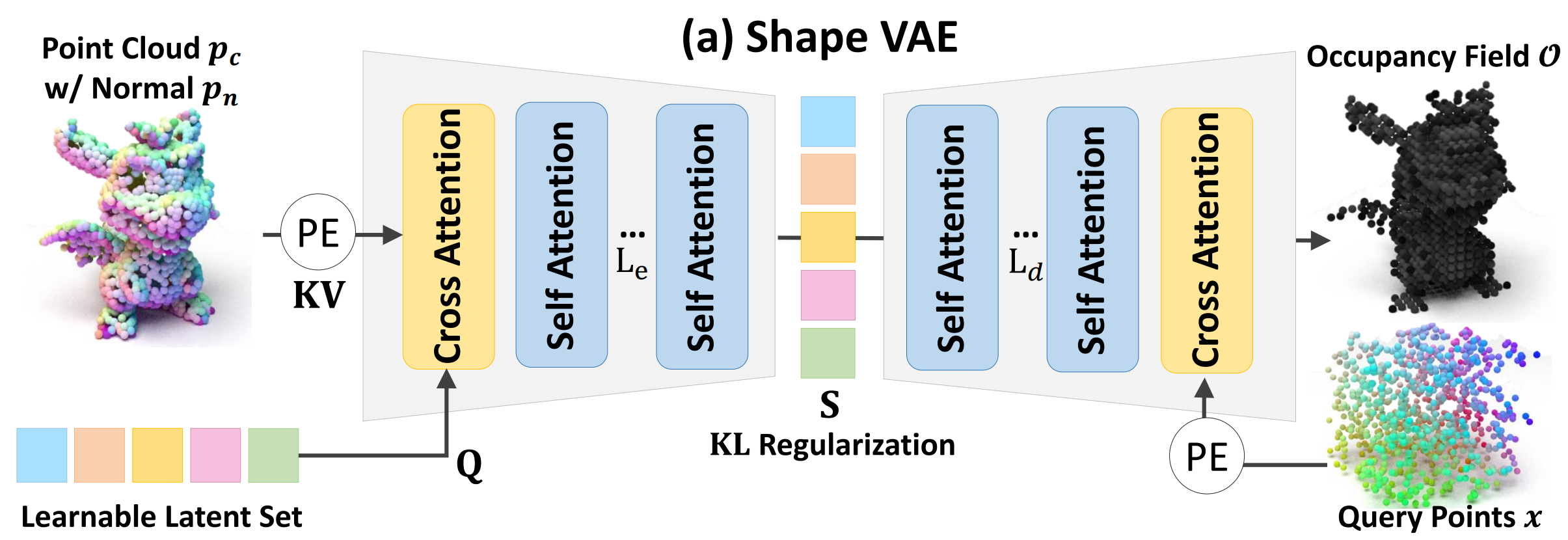
- Figure: ShapeVAE pipeline (from CraftsMan)
- Input: point clouds (보통 training set 의 GT mesh 에서 sampling)
- What to Learn?
a. Learnable query (latent vector set)
b. AutoEncoder (각 self/cross attn. block 의 linear projection layer weight) - Output: 3D shape, typically occupancy fields (binary voxel grid)
여기서 learnable query 는 data distribution (3D shape) 에 대해서 semantically meaningfull, compressed 된 공간에서의 (latent space) 일종의 basis 로써, 즉 preliminaries 에서 살펴본 kernel basis 과 같은 역할을 한다. 아래 그림에서 서로 다른 basis 가 data point 에 대해 embedding 을 어떻게 적용하는지 볼 수 있다.

ShapeVAE 에서는 위 그림에서의 (e) 처럼, query point 에 대해 learnable query (latent space 의 basis) 의 similarity 를 반영한 후,
- where Z: normalizing factor (즉 v 를 제외하고 보면 softmax)
이 embedding 을 decoding 하여 GT shape 을 reconstruction 하는 구조로 latent space 를 학습한다.
ShapeVAE 를 처음 제시한 Shape2vecset 저자들은, 이 설계 자체를 RBF 에서 착안하여 제시했다고 한다. 는 input embedding 이기 때문에 여기서 learnable parameters 은 latent vectors 와 corresponding weight 이며, 이는 곧 RBF 에서 query point 와 kernel basis 간의 weighted similarity 로 RBF 값을 근사하고, 이를 이용해 basis function 을 optimize 하는 것과 같은 형태임을 알 수 있다.
또한 이 식을 Transformer 의 QKV cross-attention 의 형태로도 해석할 수 있다. 실제로 저자들은 DETR, Perceiver 에서 착안해 다음과 같은 형태로 learnable latent 를 정의한다.
정리하자면 ShapeVAE AutoEncoder 는 basis (latent query, L) 를 이용해서, 각 data instance (X) 에 대해 basis 와 data 간의 관계를 encoding ↔︎ decoding 하는 구조를 학습한다. Shape 에 대한 representation 을 가장 잘 표현하는 latent space 와, 그 latent space 에 대한 정보를 가장 잘 담고 있는 basis (learnable query) 를 배우게 되는 것.
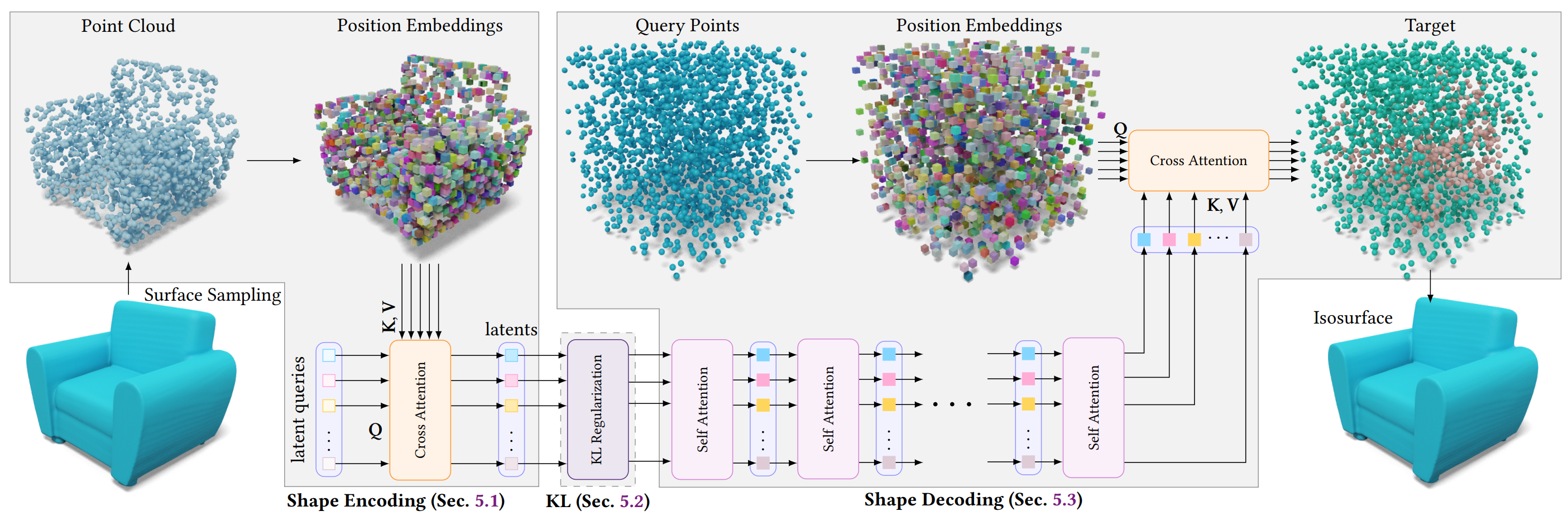
- Figure: ShapeVAE pipeline (from 3DShape2vecset)
Pipeline 에서 각 요소는 다음과 같은 세부사항을 갖는다.
-
Positional Encoding: fourier featuring 으로 NeRF / Transformer 에서 쓰이는 sinusodal encoding 의 그것. PE 는 Cartessian Coordinates 를 high-dimensional, frequency domain 으로 mapping 시켜줄 뿐만 아니라 kernel regression 을 학습할 때 coordinates 간의 stationary 성질을 더해준다.
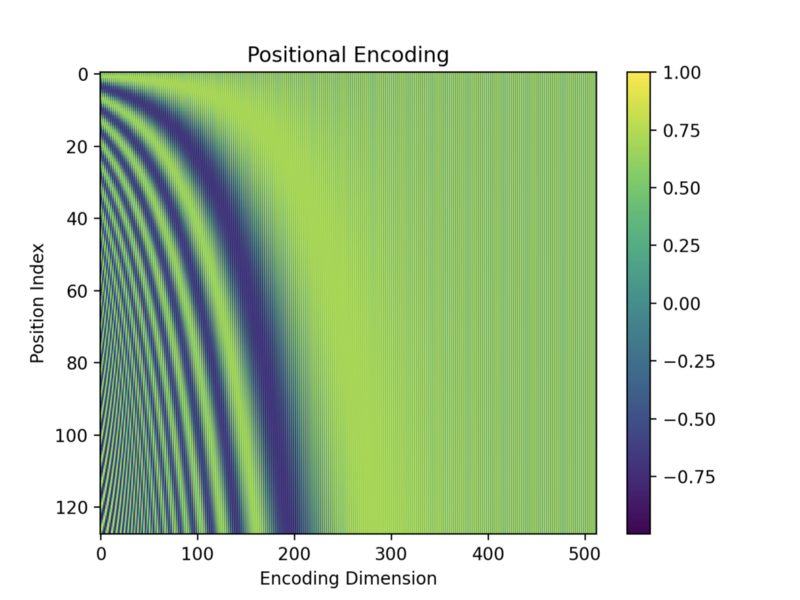
-
KL reg term: Encoder가 생성하는 latent distribution 이 prior distribution (일반적으로 standard Gaussian distribution, ) 에 가깝도록 유도한다. 이는 다음과 같은 장점들이 있다.
- Continuous latent space: 정규 분포를 따르는 latent space는 연속적이고 부드러운 공간이 되며, latent space 상에서 interpolation 이나 sampling 이 쉬워진다.
- latent space 상에서 벡터 연산 (interpolation, extrapolation 등) 을 통해 shape variation 을 자연스럽게 제어할 수 있다.
- Prevent Overfitting: latent space를 prior distribution에 가깝게 제약함으로써, encoder가 학습 데이터의 분포를 더 일반적인 형태로 학습하도록 유도한다.
- Sampling Ease: 단순히 standard Gaussian distribution에서 랜덤 샘플링한 후 decoder에 입력하면 새로운 데이터를 생성할 수 있다.
- Continuous latent space: 정규 분포를 따르는 latent space는 연속적이고 부드러운 공간이 되며, latent space 상에서 interpolation 이나 sampling 이 쉬워진다.
Q. Why learnable query?
DETR / Perceiver 는 기본적으로 detection 이나 classification 등 generation 이 아닌 분야를 위해 설계된 모델이다. 생성이 아닌 분야에서는 learnable query 가 종종 쓰이지만, 2D LDM 에서는 잘 쓰이는 방법이 아니다. 하지만 ShapeVAE 에서 latent query 를 도입한 이유에 대해서 몇 가지 유추해보자면,
- Hierarchy
명확한 Part-based 구조: 3D shape 은 의미 있는 부분 (part) 들로 구성되는 경우가 많다. 이러한 부분들은 spatial relation 을 가지며 전체 shape 을 구성한다- Sparsity & Geometry
sparse 한 특징을 가지고, 3D shape 자체는 ‘2D image’ 의 texture, style, background 보다 훨씬 sparse 한 geometry 자체가 핵심 정보이기 때문에 latent query 방식으로 compress 하기 좋다
Enc/Dec 에 어떤 구조를 사용하느냐 (Perceiver ↔︎ Diffusion Transformer) / latent space 에 multi-modality 에 대한 alignment 를 위한 loss 등을 추가적으로 설계하느냐 (CraftsMan) 등의 차이는 있지만, 기본적으로 ShapeVAE 가 하는 역할은 위와 일맥상통하다.
풍부한 데이터로부터 잘 학습된 latent space 가 있다면, 우리는 Latent Diffusion Model 의 힘을 빌려 3D shape 에 대해서도 생성 모델 (3D Latent Diffusion Model) 이 학습 가능할 것을 예상할 수 있다.
Challenges for ShapeVAE
하지만 최근까지도 3D 생성 분야는 2D / 비디오 생성만큼의 놀라운 결과를 보여주지는 못하고 있었다. 이러한 더딘 발전의 원인들은 다음과 같은데,
-
Versatility & Diversity of Data: 데이터 양이 2D 에 비해 극심히 적다. 그나마 Objaverse 란 데이터셋이 8M 정도이며, 그 데이터셋의 확장인 XL 버젼도 100M 정도로 2D 데이터셋들에 비해 극도로 적다 (LAION 5B...). 특히 고퀄리티의 데이터셋은 더더욱.
-
Curse of Dimensionality: 3차원인만큼 high-resolution 생성이 2D 에 비해 cost 가 높다.
-
What is the ‘BEST’ representation?
‘3D’ 에 대해 적절한 representation 이 무엇인지는, 답이 없는 open-problem 이다. neural fields 를 제외하고서라도, voxel, occupancy grid, SDF… 등 수많은 representation 이 있는데, 이는 각 장단이 있기 때문에 쉽사리 어느 하나를 고를 수 없다.
또한 NeRF 의 대유행으로 3D 생성에서도 2D Diffusion + NeRF 를 결합한 방법인 SDS 가 주류를 이루었으나, 태생적인 한계 (extremly slow generation time / Janus problem) 을 극복하기가 매우 힘들었다. cf: 3D 생성에서 NeRF 와 SDS 는 도태될 수밖에 없는가?
ShapeVAE 의 성능은 이 중에서도 1) 데이터의 양과 다양성 문제와 그 성능이 직결되었다. 초기 ShapeVAE 는 3D 생성 보다는 surface recosntruction 분야를 generative 하게 접근하는 쪽에 더 가까웠기 때문에 ShapeNet 등 제한적인 데이터셋에서만 학습되었으며, 데이터의 양을 늘려 학습한 경우에도 input image 나 text 를 충실하게 재현하지 못하는 성능을 보였다.
또 한가지 ShapeVAE 의 문제점은 feature aggregation 을 ‘spatial location 에만 dependent 하게 추출' 한다는 점이다. 기본적으로 ShapeVAE 에서 point feature 는 ‘Positional Encoding’ 으로 들어가는데, Positional Encoding 만으로는 공간 상의 local structure (curvature, surface normal) 나 global shape context (connection relation between vertices & faces) 와 같은 중요한 3D 정보를 충분히 포착하기 어렵다.
이러한 ShapeVAE 를 Geometry Generation 단계에서 적극 활용해 Model / Data capacity 를 크게 늘리고 shape generation 과 texture generation 을 분리한 2-stage pipeline 을 처음 제시한게 바로 CLAY-Rodin 이다.

- Figure: Rodin (paper: CLAY)
Rodin 은 large DiT model (1.5B) 를 이용해 ShapeVAE 와 그 latent space 에서의 shape generation 성능을 크게 올리고, 생성된 shape (mesh) 위에 geometry-guided multi-view generation 을 이용한 texture synthesis 의 2-stage 를 사용하여 그전까지의 3D 생성 퀄리티를 압도하는 결과를 보여주었다.
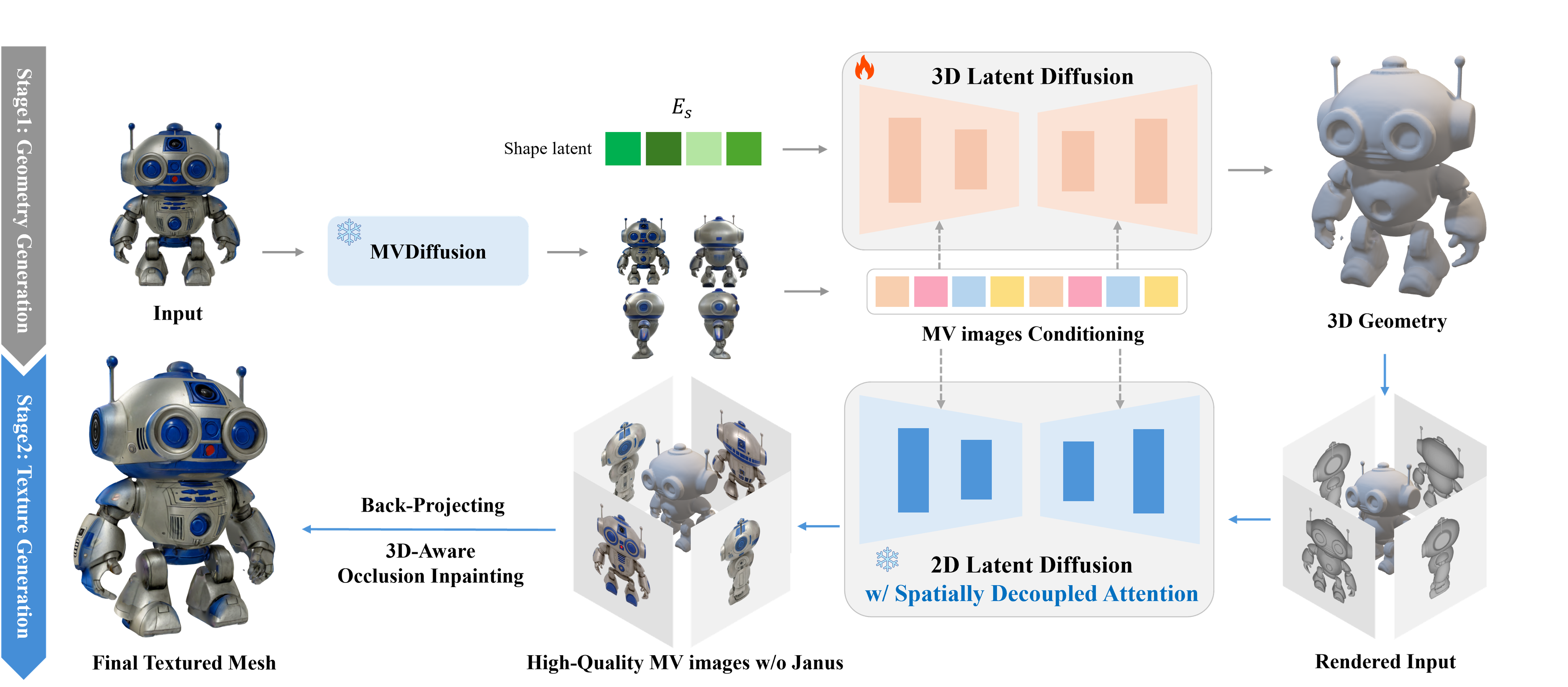
- Clay 와 유사한 pipeline 을 가진 CaPa. 3D LDM 으로 mesh 를 생성한 이후 high-quality texture 를 만들어 backprojecting 한다.
이 연구를 필두로 2024년에 점차 3D Latent Diffusion 자체를 제시하는 연구들이 증대되었다. 하지만 상기했던 문제들,
- Low Quality
- Not faithfully follow the guidance (input image or text)
를 해결하기 어려웠는데...
2. Trellis
Paper: Trellis: Structured 3D Latents for Scalable and Versatile 3D Generation
Trellis 는 2024년 말 Microsoft 에서 발표한 SOTA 3D Latent Diffusion 모델이다. 안정성과 fidelity 측면에서 이전 ShapeVAE 기반 접근법들을 크게 상회하는 결과를 보여주었고, end2end 로 shape 뿐만 아니라 texture 를 같이 생성할 수 있다는 장점이 있다. 어떠한 설계를 통해 SOTA quality 를 달성했는지 분석해보자.
2.1. Structured Latent Representation
Trellis 는 ShapeVAE 의 단점 중 ‘PE only input feature encoding' 의 한계로부터 나오는 한계를 well-trained 2D feature extractor (DINOv2) 를 사용해 극복한 연구이다.
저자들은 SLAT (Structured Latent Representation) 이라는 representation 을 제안하는데,
여기서 는 voxel index, 는 latent vector 이다. 즉 voxel grid 마다 latent vector 가 하나씩 할당되어 있는 구조이고, latent vector set 이 그 자체로 structured (voxelized) 되어 있기 때문에 SLAT 이라고 명명한 듯 하다.
3D data의 sparsity 으로 인해, activated grid 의 개수는 3D grid 의 총 사이즈보다 매우 작고 , 이는 상대적으로 높은 해상도로 생성될 수 있음을 의미한다. Instant-NGP 등 voxel-grid NeRF 와도 비슷한 접근인데, ShapeVAE 를 이용해 featured grid 를 예측하는 설계인 셈.
정의 자체는 ShapeVAE 에서 사용하는 learnable query 를 voxel grid 에 mapping 한 것에 불과할 수 있으나, SLAT 의 핵심은 이 SLAT encoding 을 배우는 과정에서 DINOv2 feature extractor 를 적극 이용한다는 것이다.
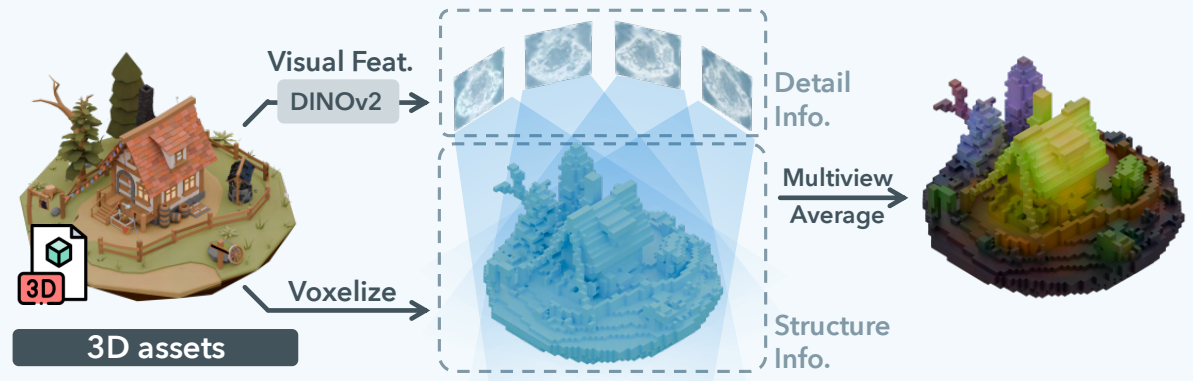
위 그림과 같이, SLAT 은 VAE 를 학습하는 과정에서 3D assets 에 대한 encoding 을
-
Multi-View Rendering
-
Featurizing: 각 view rendering 에 대해서 DINOv2 로 feature extracting
-
Averaging
하여 계산한다.
이는 Trellis 가 end2end 3D generation 을 표방하기 때문에 채택한 방법으로 보이는데, 단순 PE 만으로는 표현하기 힘든 color, texture 등 3D Assets 에 대한 정보를 pre-trained DINOv2 를 이용해 versatile 한 feature 를 얻은 것 이라고 생각한다.
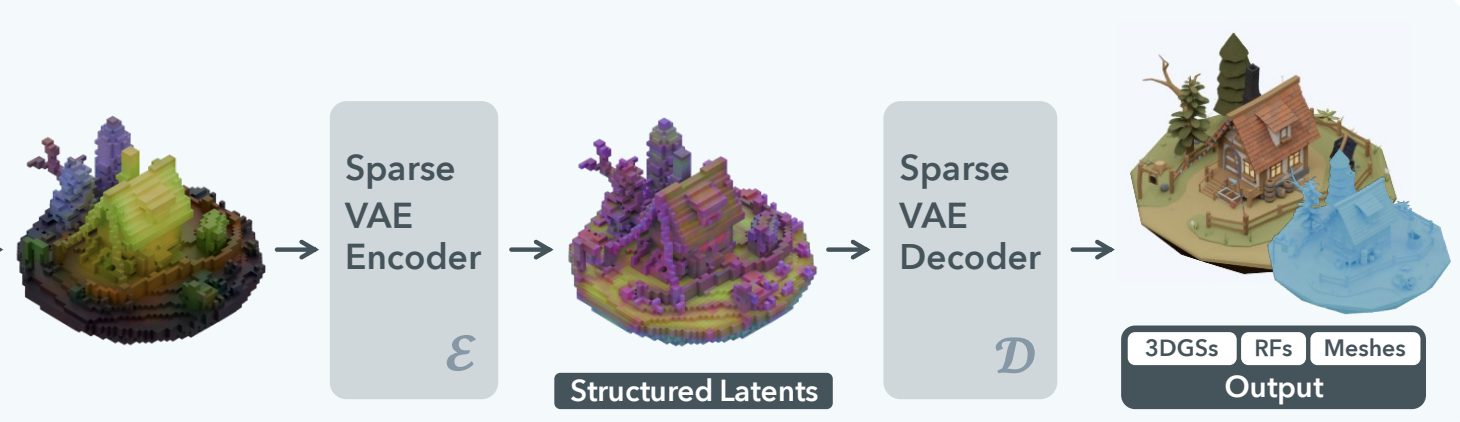
- figure: SLAT representation learning
VAE 구조 자체는 original ShapeVAE 와 동일하며, latent space 가 잘 정의되어 있다면 Decoder 를 바꿔서 3D GS / Radiance Fields / Mesh 의 output 을 생성하도록 finetune 할 수 있기 때문에, Trellis 는 output 에 GSs, NeRF, Mesh 등 format-agnostic 하게 결과를 예측할 수 있다. (실제 inference branch 에서는 GS 와 Mesh branch 두 개를 사용함)
2.2. SLAT Generation
Q. 그럼 3D Generation 자체도, ShapeVAE 에서처럼 latent space 에서 Standard Gaussian Distribution 의 random sample 을 넣으면 새로운 asset 이 생성되는가?
아쉽게도 그렇지 않은데, 우선 SLAT 은 ‘structure’ (position index) 자체도 의미가 있기 때문에 structure, 즉 어떤 voxel 이 비었는지, 비지 않았는지부터 생성할 필요가 있다.
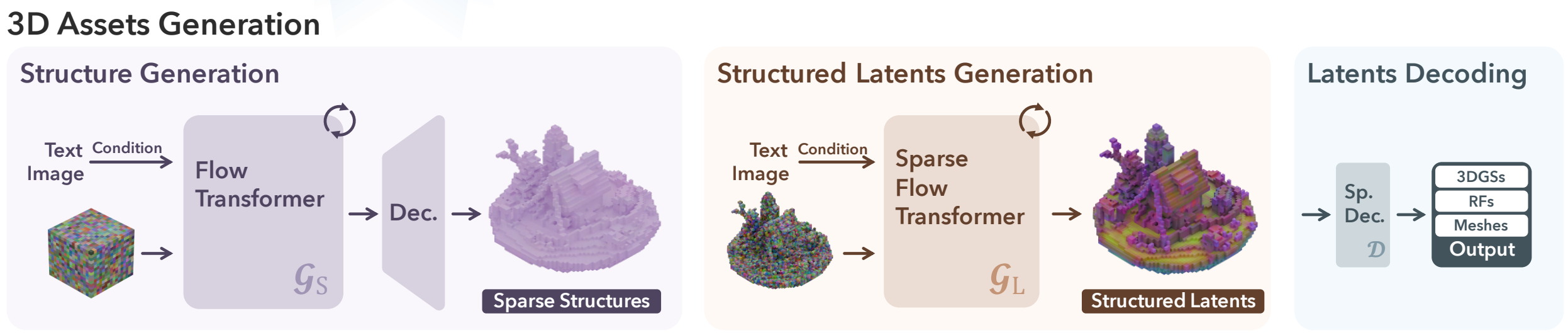
이를 위해 Trellis 는 3D Generation 에서 2-stage 의 접근을 사용한다.
- Conditional Flow Matching 을 통해 Sparse Structure 생성: rectified flow model 을 이용. (model 1)
- 생성된 Sparse Structure 를 input 으로 하여 DiT 와 비슷한 구조의 Transformer 로 최종 SLAT 생성한다. (model 2)
첫 단계에서 structure 를 dense grid 로 바로 생성하는 것은 computation cost 가 크기 때문에, Trellis 는 Structure Gen Stage 에서도 Decoder 를 도입하여 low-resolution feature grid 를 생성 후 Decoder 로 scale up 하는 방식을 채택한다.
구체적으로는 GT dense binary grid 를 3D convolution 을 이용해 low-resolution feature grid 으로 압축하여, 이를 예측하는 Flow Transformer 를 먼저 학습한다. 가 coarse 한 형상이기 때문에 3D conv 를 이용한 압축 과정에서 손실이 거의 없고, NN 학습의 효율성을 향상시키는 장점도 있다. 또한, 의 binary grid 를 continuous value 로 변환하여 Rectified Flow 학습에 적합하게 만든다.
Rectified flow 모델은 diffusion process 에서 data → noise 로 경로를 linear interpolation (input → output) 의 직선 경로를 forward process 로 사용하는 모델이다. 일반적인 Neural ODE solver 의 step 이 비효율적인데 비해 Rectified Flow 는 data → noise 의 linear 한 vector field 를 modeling 하기 때문에 훨씬 빠르고 정확하게 생성이 가능하다.
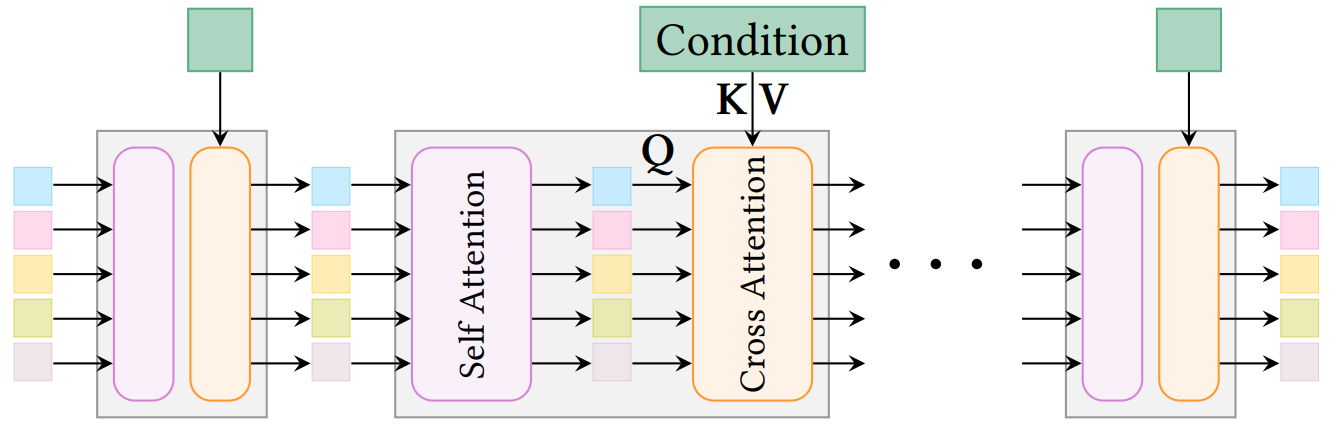
이 과정에서 condition modeling 은 다른 Diffusion model 과 비슷하게 cross-attention 의 KV 에 inject 한다. 즉 Sparse Strucrue Gen 은 일종의 Image/Text-to-3D Coarse Shape Generation 으로 작동한다.
이후 생성된 Sparse Structure 를 이용하여 SLAT 을 생성하는 model 2 를, 마찬가지로 Rectified Flow 를 이용하여 학습했다고 한다. 최종적으로 생성된 SLAT 에 ShapeVAE 의 decoder 를 사용하여 GSs / Mesh output 을 생성할 수 있다.
Mesh Decoder 가 있기 때문에 Mesh Output 은 Mesh Decoder Branch 의 output 을 바로 사용하나 싶었지만, 실제로는 그렇지 않다는 것을 유의하자. 최종 3D asset output 은 GS 생성 결과물은 RGB representation 으로, Mesh 생성 결과물은 geometry 로 이용하여 mesh 의 texture 를 GS rendering 에 fitting 하도록 되어 있다. 이는 Mesh branch 의 생성 fidelity 가 상대적으로 떨어지고, mesh geometry 자체도 post-processing 이전엔 artifacts 가 은근히 보이는 편이기 때문에 채택한 듯 하다.
구체적으로는,
-
Multi-view Rendering: GSs 생성 결과물을 정해진 num view 만큼 rendering
-
Post-processing: Mesh 생성 결과를 mincut 알고리즘을 이용한 retopology, hole filling 등의 post-processing
-
Texture Baking 1) 에서 rendering 된 multi-view GSs rendering 을 GT textures 로 하여, Mesh texture 와의 Total-Varation Loss (L1) 를 minimize 하도록 texture 를 배워서 Mesh 에 최종 baking
의 단계를 통해 최종 3D asset 을 생성하도록 되어 있다. 데모 페이지에서 다운 받을 수 있는 glb output 은 모두 이러한 pipeline 을 거쳐서 나온 결과이다.
- cf: to_glb, fill_holes

굉장한 퀄리티의 output 을 보여주는데, Demo 에서 모델을 돌려볼 수 있다.
단점이라면 아직은 instruction (input guidance) 를 완전히 잘 따라가지는 못하고, 상기한대로 Mesh branch 의 output quality 가 떨어지기 때문에 GSs rendering 을 post-processed Mesh 에 baking 하는 복잡한 작업이 필요하다. 또한 이 texture baking 자체는 multi-view rendering 을 기반으로 하기 때문에, occlusion 에서 완벽하게 자유롭지는 못하다.
3. Hunyuan3D-v2
Paper: Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Trellis 의 등장 이후 한 동안 3D Generation 의 SOTA 왕좌는 Trellis 가 굳건히 점유할 것으로 보였으나, Mesh Quality, Instruction Following 관점에서 Trellis 를 압도하는 중국의 Hyunyuan3D-v2 가 등장했다.
Hunyuan3Dv2 는 Trellis 와 다르게 end2end 가 아니라, Rodin 이나 CaPa 와 같은 2-stage, 1) Mesh Generation 2) Texture Generation 을 따르고 있다. 그 중 Mesh Generation quality 가 그야말로 SUPERIOR 한데, 자세하게 분석해보도록 하겠다.
3.1. Hunyuan-ShapeVAE
Hunyuan 의 ShapeVAE 설계도 vanilla ShapeVAE 와 많이 다르진 않지만, 몇 가지 주효한 차이점이 있다.
-
Point Sampling: ShapeVAE 학습할 시 대게는 GT mesh 로부터 point cloud 는 uniform sampling 을 통해 얻는다. 하지만 이렇게 되면 fine detail 을 잃는 경우가 다수이기 때문에, Hunyuan 은 uniform sampling 에 더불어 Edge / Corner 쪽에 더 집중된 point sampling 전략을 사용한다. 이는 최근 제시된 Dora 와도 비슷한 접근법이다.

Figure from Dora. Left: salient points ↔︎ Right: uniform -
SDF estimation: VAE output 이 binary voxel grid 가 아니라 SDF value 이다. Binary grid 를 예측해야하는 기존 occupancy 방식과 다르게 이렇게 되면 continuous real value 인 SDF 값을 estimation 하므로 Deeplearning 이 더 안정적인 결과물을 estimation 할 수 있다.
-
Point Query: Latent space 의 basis 를 latent vector set 으로 learnable 하게 배우는 전략을 사용하지 않는다. 대신에 앞서 설명한 salient/uniform sampled point 를 subsampling 하여 query 로 활용하게 된다.
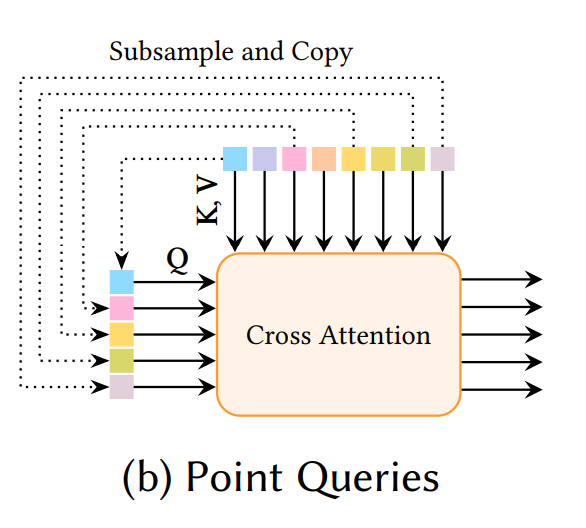
latent space 의 basis 는 배우지 않고 latent space 자체를 더 정밀하게 배우는 전략을 채택한 것인데, salinet sampling 이 각 3D shape 의 fine detail 을 충분히 반영하기 때문에 해당 접근법을 채택한 것 같다.
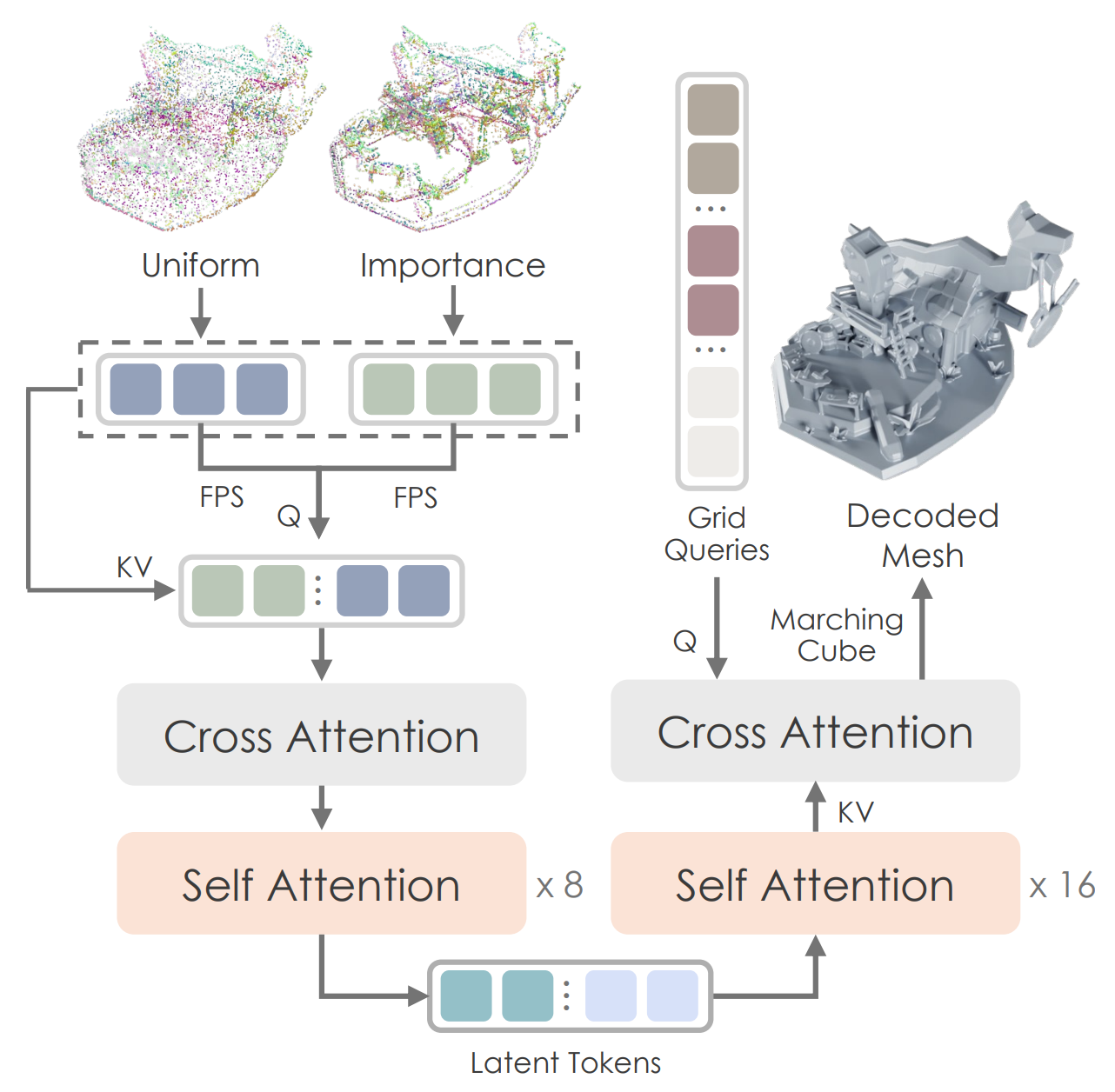
- Figure: Hunyuan-ShapeVAE
3.2. Hunyuan3D-DiT
이전 연구들은 Trellis 를 포함하여 일반적인 DiT 구조와 크게 다르지 않은 Transformer 를 차용했었는데, Hunyuan 은 Flux 에서 기반한 참신한 DiT architecture: ‘double- and single-stream’ design 을 사용한다. 이 구조로 인해 Hunyuan3D 가 기존 그 어떤 모델과 비교해도 input guidance 를 가장 잘 따르는 high quality Mesh 를 생성할 수 있게 되었다.
Flux 는 (official technical report 가 없지만) 공개된 dev version 코드에 의하면 text ↔︎ image modality 의 정보 처리를 double-stream 으로 설계하는데 (text / image branch 가 병렬로 분리되어 있음), 이것이 SDXL 대비 Flux 가 better instruction following performance 를 갖게된 주효한 원인으로 분석되고 있다.
| SDXL | Flux |
|---|---|
 |  |
-
my opinion) Double stream 의 구조를 보면 ControlNet 의 reference net 방식과 유사한데, 아마 ControlNet 방식이 original modal 의 generation capability 를 해치지 않으면서 condition 을 잘 반영하는데서 착안한 구조가 아닐까 싶다.
{kind=link}
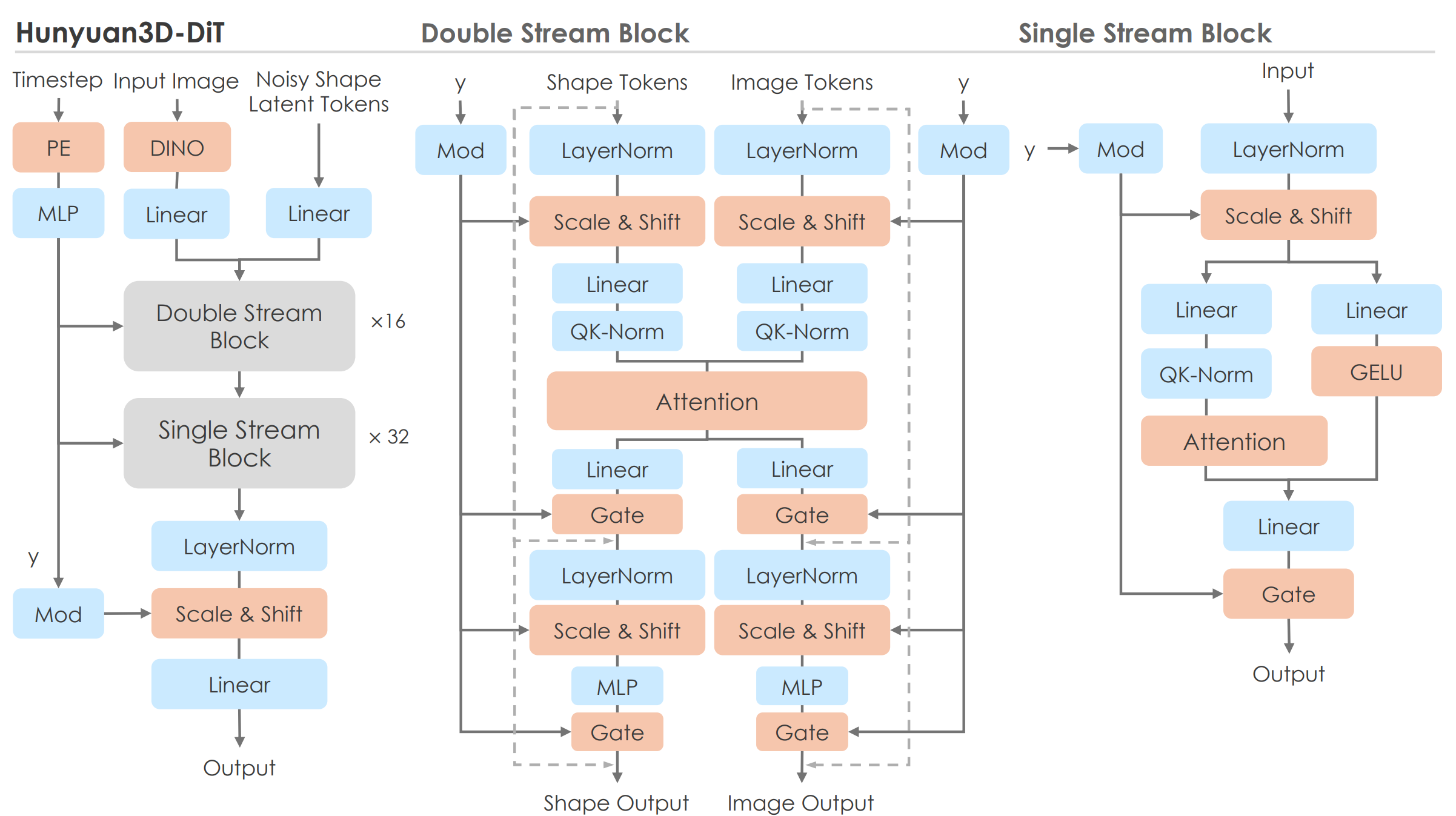
- Figure: Hunyuand3D-DiT
Hunyuan 도 이러한 ‘double-single’ 구조를 채택하여 condition (image, text) instruction 에 대한 정보를 최대한 잃지 않으면서 동시에 3D Shape 도 high-quality 로 생성하는 것을 목표로 한다.
Pipeline 의 핵심은 다음과 같은데,
-
Double Stream:
- Shape Tokens: 생성할 3D shape 의 latent representation token (noisy) 를 DiT 의 diffusion reverse process 를 통해 정제
- Image Tokens: input image (image prompt) 에서 pre-trained DINOv2 를 이용해 추출한 2D image feature
- Shared Interaction: Shape / Image Tokens 을 각각 독립적인 경로로 처리하되, Attention 연산 내에서 두 token 간의 interaction 을 반영한다. 이를 통해 image prompt 의 정보를 3D Shape 생성 과정에 효과적으로 반영된다.
-
Single Stream:
- Input: Double-stream 을 거쳐 이미지 정보가 반영된 Shape Tokens
- Output: Token 을 독립적으로 처리하여 3D shape latent representation 을 더욱 refine 하고, 최종 3D shape (latent) 를 생성
학습은 Trellis 와 마찬가지로 Rectified Flow Matching 을 이용했다고 한다.
언급된 학습 detail 중에 주목할만한 점으로, ViT 계열에서 주로 patch 단위에 positional embedding (PE) 을 더하는 것과 다르게 Hunyuan 은 PE 를 제거했다고 한다. 이는 Shape 생성 시 ‘fixed location’ 에 특정 latent 가 할당되는 것을 막기 위함이라고 한다.
3.3. Hunyuan3D-paint
Hunyuan 은 CLAY / CaPa 와 같은 2-stage 방식이기 때문에 texture synthesis 에서 Geometry-guided Multi-View Generation 을 이용한다. 하지만 단순히 MVDream / ImageDream 계열 모델 + MV-Depth / Normal ControlNet 을 학습시킨 것이 아니라 quality 를 높이기 위한 참신한 전략들을 다수 도입하였다.
우선 Hunyuan 은 기존 방식이 문제가 있다고 언급하고 시작하는데, MVDream, ImageDream 은 Stable Diffusion 모델을 Multi-View 로 tune 하면서 ‘noisy feature’ 를 generation branch 에서 Multi-View Synchronization 하려고 한다. 이는 reference image 의 origianl detail 을 손상시키는 문제가 발생할 수 있고, 실제로 ImageDream 이나 Unique3D 의 MV output 을 보면 front-view 조차 input image 와 대비되는 퀄리티를 보여주는 것이 다반사다.
| input | generated front view (MVDiffusion) |
|---|---|
 |  |
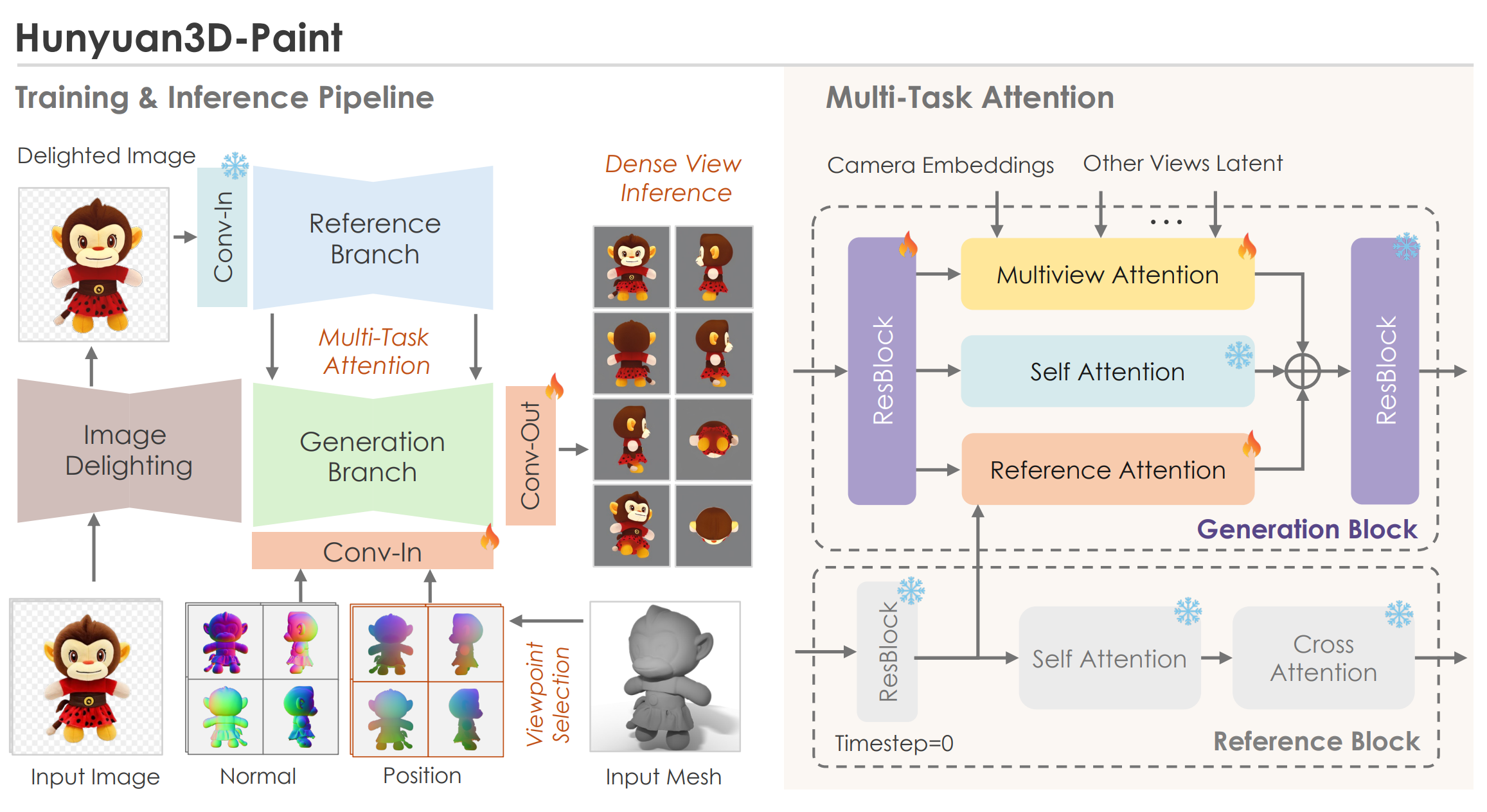
- Architecture Design of Hunyuan3D-Paint
언급한 기존 MVDiffusion 의 단점을 해결하기 위해, Hunyuan 은 다음과 같은 접근법을 사용하는데,
-
Clean Input Noise
- Reference image 의 "original VAE feature" (noise 가 섞이지 않은 clean VAE feature) 를 reference branch 에 직접 주입하여 reference image 의 detail 을 최대한 보존한다.
- Reference branch 에 입력되는 feature 가 noiseless (clean, input of the forward procee) 이기 때문에, reference branch 의 timestep 은 0 으로 설정한다.
-
Regularization & Weight Freeze Approach
- Style Bias Regularization: 3D assets 을 rendering 한 데이터셋에서 발생할 수 있는 style bias 를 방지하기 위해, shared-weighted reference-net 구조를 포기했다고 한다.
- Weight Freeze: 대신, original SD2.1 모델의 weights 를 freeze 하여 reference-net 으로 사용 한다. SD2.1 은 multi-view generation 의 base 모델 역할을 하며, 'freeze 된 weights 는 regularization 역할' 을 하게 된다. 이는 MVDream 에서 생성 결과의 30% 정도는 단순 text-to-Image (not MV) loss (from LAION dataset) 으로 학습하여 MVDiffusion model 의 fidelity 를 잃지 않으려 했던 것과 유사한 전략이다.
약간 이해가 안 될 수 있는데, 일반적인 ControlNet 과 반대 방향의 접근을 사용했다고 생각하면 된다. Control 역할을 하는 reference branch 는 학습하지 않고, generation branch (MV-Diffusion model) 를 학습하여 'guide' 는 original SD 모델이, 'gen' 은 MV-Diffusion model 이 담당하는 구조 이다.
-
Geometry Conditioning 으로는 generated mesh 를 다음 방식으로 렌더링 한 두가지를 사용한다.
- CNM (Canonical Normal Maps): 3D model surface normal vector 를 canonical coordinate system 에 projection 한 image
- CCM (Canonical Coordinate Maps): 3D model surface coordinate vector 를 canonical coordinate system 에 mapping 한 image
둘 모두 canonical system 에 projection 하여 geometry-invariant 하게 정보를 주입한다. coordinate 와 normal 정보를 모두 사용하여 공간 상의 위치와 위치간의 관계를 모두 mapping 해주는 것. MetaTextureGen 도 동일한 guide 를 사용하는데, detail / global 측면에서 point + normal 조합이 depth map 에 비해 좋다고 report 하고 있다.

또한 이러한 구조를 효과적으로 학습하기 위해 Multi-Task Attention 을 제시하는데, 수식으로 표현하면 다음과 같다.
Ref module 과 mv module 이 독립적으로 작동하는 일종의 ‘multi-task learning’ 을 위한 병렬로 설계된 attention 임을 알 수 있다.
이는 현재 구조에서 reference branch (controlnet) 과 generation branch (MV generation) 이 각각
-
referecne branch: origianl image 을 따라가려고 함
-
generation branch: generated view 간 consistency 를 유지하려고 함
의 다른 역할을 수행하고, 여기서 야기되는 multi-functionality 때문에 발생하는 conflict → 성능 저하를 막고자 함이다.
동일한 구조의 설계를 MV-Adapter 에서도 보여준 바 있다. 둘 모두 original branch 의 성능을 잃지 않으면서 Multi-View Generation Capability 를 얻으려고 동일한 구조를 설계했음을 알 수 있다. 어찌 보면 ShapeGen-stage 의 double stream 과도 일맥상통하는 설계이다.
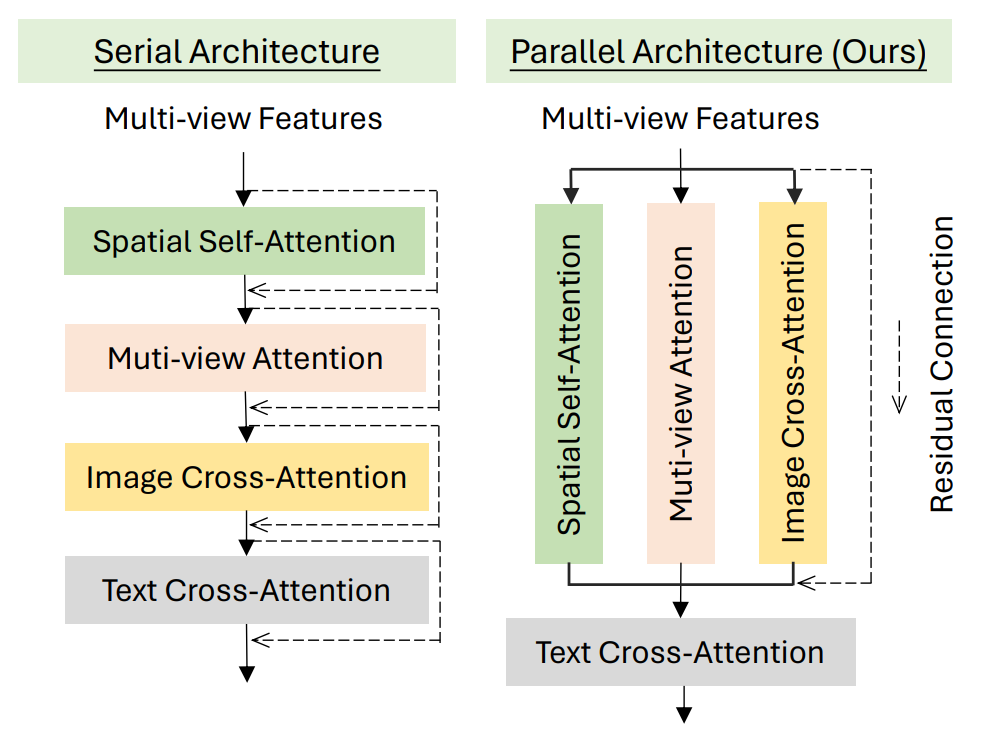
이를 이용해 reference image 를 guidance 로 활용하면서, 동시에 multi-view consistency 를 보장하는 diffusion model 설계. 즉, reference image 와 일관성을 유지하면서, 다양한 시점에서도 자연스러운 이미지를 생성할 수 있다.
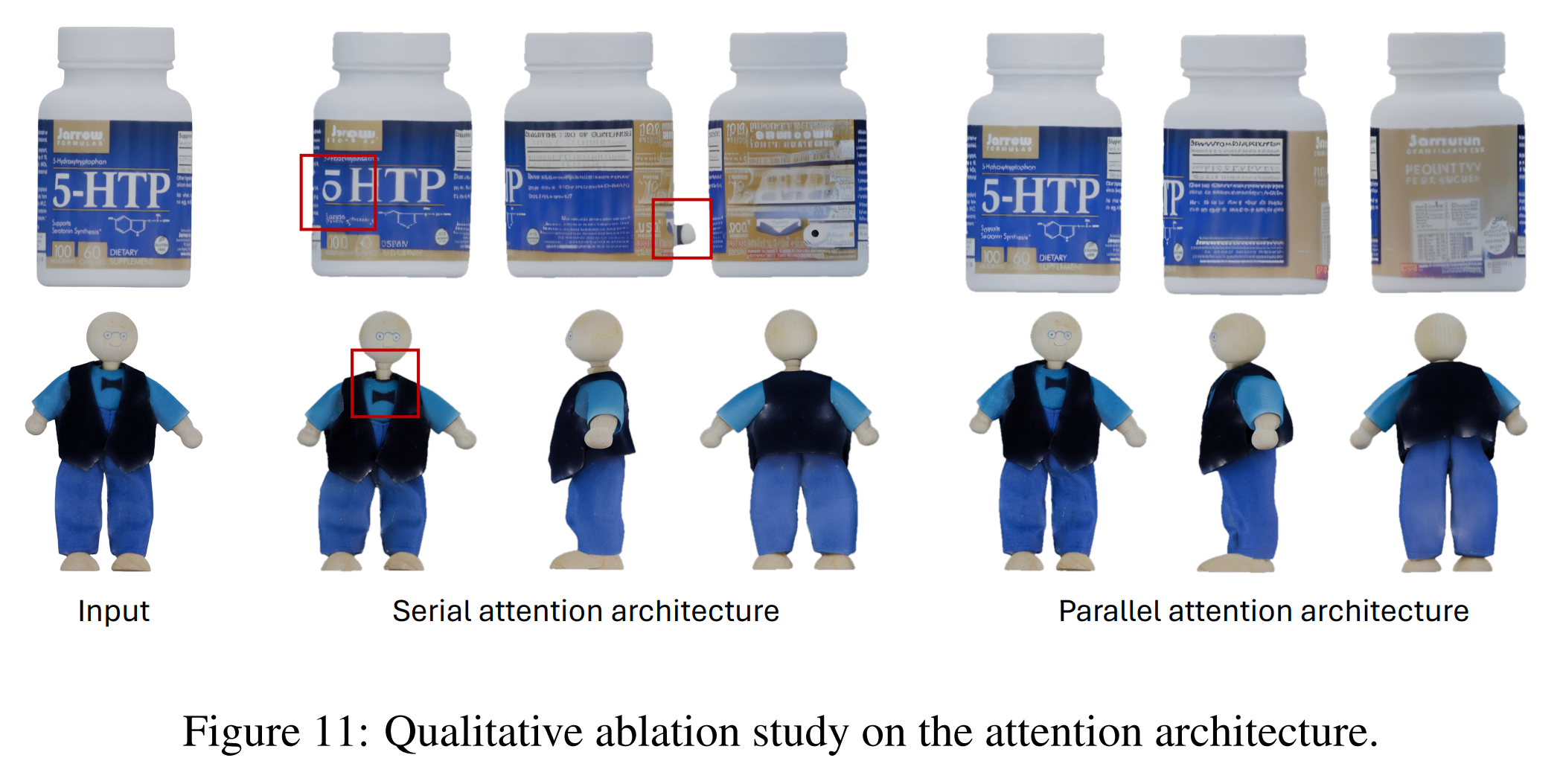
- Figure from MV-Adapter. Parallel 구조의 유용성을 보여주는 ablation study. 우측의 parallel attention 이 reference image 의 특징을 훨씬 잘 반영하는 것을 볼 수 있다.
테스트 결과, 기존 MVDiffusion 의 fidelity 를 월등히 뛰어 넘는 quality 의 MVDiffusion output 을 보여주었으며, 단순히 normal / depth map 정도를 guide 로 사용하는 competitor 들보다도 multi-view consistency 가 높고 seam, artifacts 가 적은 모습을 보여주었다.
| Multi-View Diffusion Results |
|---|
Hunyuan  |
ImageDream  |
4. Trellis vs Hunyuan3D
| Trellis | Hunyuan3D |
|---|---|
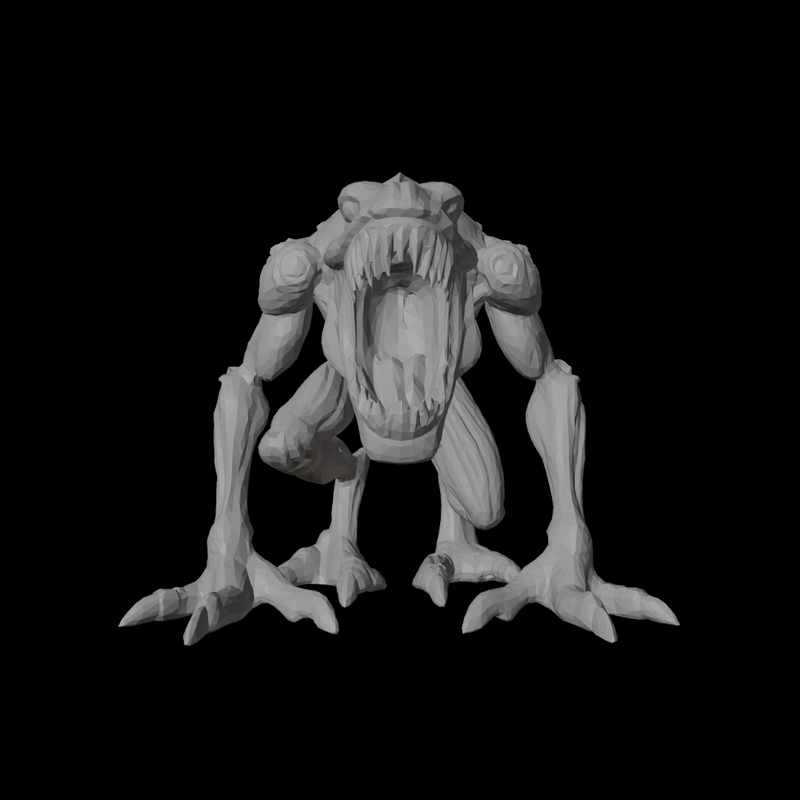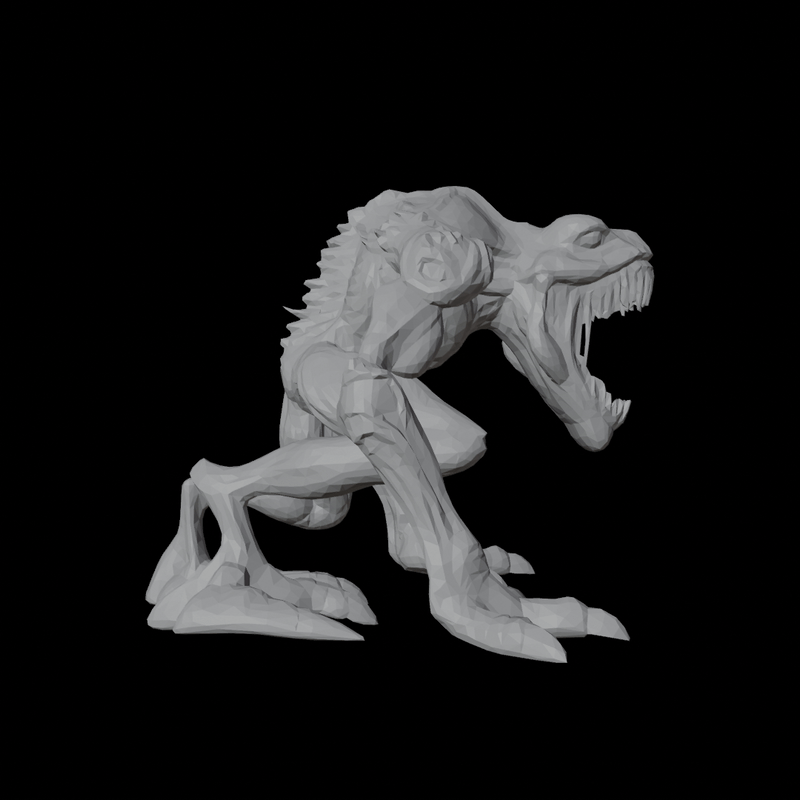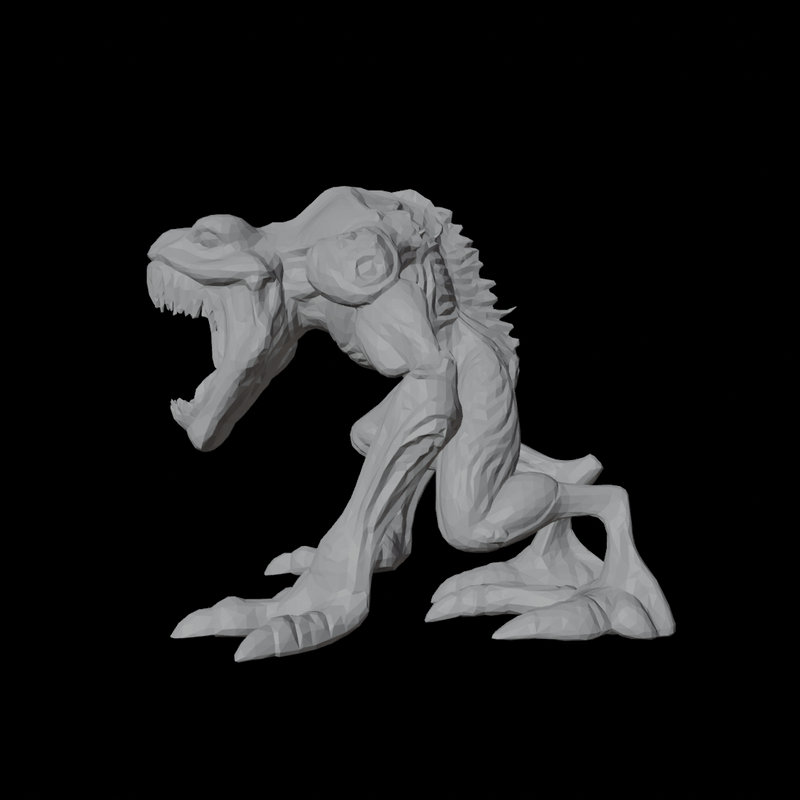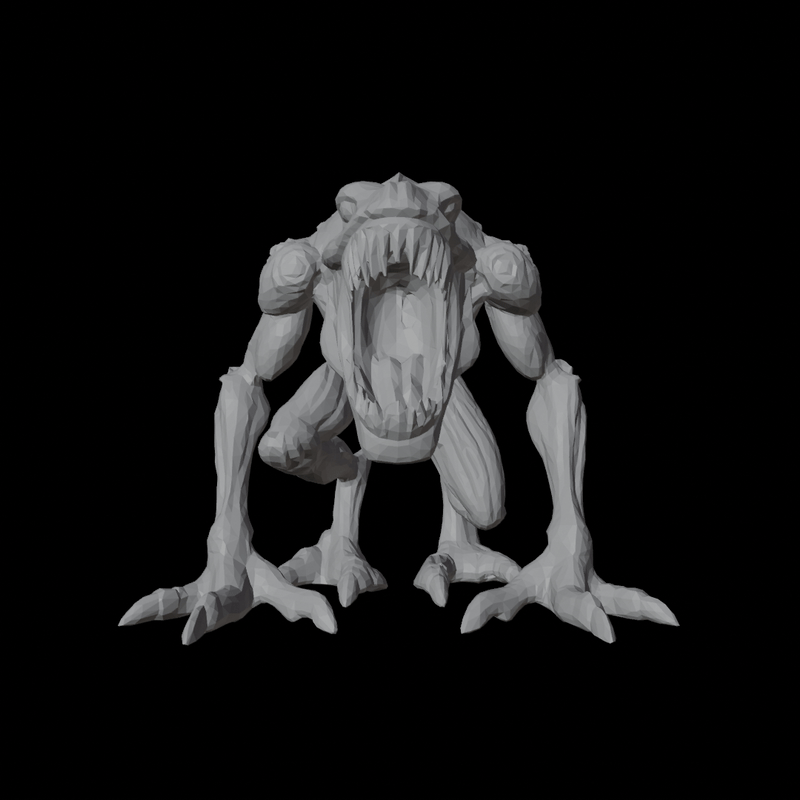 |  |
 |  |
Velog 엔 직접적으로 3D model viewer 를 포팅할 방법이 없어 부득이하게 rendering 결과로 대체한다.
생성의 input image 로는 하기 이미지를 사용했다.

Mesh Quality 의 경우 Trellis 보다 Hunyuan3D 의 topology 가 훨씬 좋다. 또한 블로그에 싣진 않았지만 Trellis 의 경우 종종 input image guidance 와 상이한 결과를 예측하는 경우도 있는데 Hunyuan 은 충실히 instruction follow 하는 모습을 보여주었다.
반면 Texture Quality 는 둘 모두 아직 그렇게 높지는 않다. Hunyuan 은 geometry-guided 로 6 view Multi View 를 생성하여 backprojecting 하는 식으로 texture 를 baking 하는데 이 때문에 occlusion 이 좀 있는 편이고, Trellis 는 상대적으로 Hunyuan 보단 occlusion 이 덜하지만 fidelity 가 더 안 좋은 모습이다. 또한 Hunyuan 의 경우 완벽하게 geometry guide 와 align 되지는 않아서, 일부 seam 이나 artifacts 들이 trellis 보다 눈에 띄는 경우가 있었다.
서로 end2end <-> 2-stage pipeline 이기 때문에 나타나는 장단점이 명확한 것 같다. 각자의 부분에서 quality 를 높여가면서 3D Latent Diffusion 후속 연구들이 등장할 것이라 예상되는 부분.
마지막으로 CaPa Result 를 별첨한다 :)

Closing
지금까지 ShapeVAE 의 기본 개념부터 Trellis / Hunyuan3D 에 이르는 SOTA 3D Latent Diffusion 의 발자취를 상세하게 분석해보았다.
CLAY 등장 이후에도 한동안 opensource 진영에서 3D 분야의 괄목할만한 성과를 이루지 못했는데, 최근 연구들이 참신한 설계를 보여주며 SOTA quality 를 달성하여 앞으로 3D domain 에서의 생성 모델들에 대해서도 더욱 기대감이 증폭된다.
특히 개인적으로는 Hunyuan 이 Flux, MV-Adapter 등에서 검증된 설계를 3D Generation scheme 에 적용한 것이 인상깊었다. 좋은 연구를 하고 싶다면 틈틈히 다른 분야의 연구 트렌드에 대한 following 도 놓지 않아야 한다는 것을 다시 한 번 느낀다.
마지막으로 최근에는 MeshAnything 을 필두로 mesh face 를 auto-regressive 하게 생성하여 일명 'Artistic-Created Mesh' 로 만드는 연구도 주목받고 있지만 (이 연구들도 ShapeVAE latent space 를 이용한다) auto-regressive 방식이라 시간이 오래 걸리고 아직은 퀄리티가 안 좋아서 당분간은 주시하기만 해야할 것 같다.
You may also likes

4개의 댓글

단일 이미지에서 3d모델 생성쪽으로 공부하고 있었는데 여기저기 정보가 흩어져 있어서 힘들었는데 여러 모델 비교해주시고 자세하게 최신정보를 잘 설명해주셔서 정말 잘 보았습니다
양질의 포스팅 감사합니다 !