작년 하반기에, 3D 생성 방법론을 1년여간 연구한 경험을 바탕으로 오랜만에 논문을 작업하여 공개할 수 있었다. (클릭 시 project page로)

preprint 버젼이고, 사내 project code 가 포함되어 있어 코드는 공개할 수 없지만, 공개된 퀄리티 만으로 HuggingFace daily featured papers / TLDR AI newsletter / X (트위터) 조회수 100K & likes 1K 를 달성했다. (잠깐 자랑 좀...😎)
원래는 이 연구에 대한 연구노트를 공유하려 했는데, CaPa 의 설계에 대한 당위성을 설명하기 위해선 NeRF 와 SDS 가 3D 분야의 실사용에서 ‘절대 쓰일 수 없는 이유' 에 대해서 먼저 짚고 넘어가야 할 것 같다.
따라서 오늘은 ‘왜 NeRF 와 SDS 는 도태될 수밖에 없는가?’ 에 대한 내 개인적인 해답을 공유하려 한다
1. 들어가며
그전까진 (그리고 블로그에서도 주로 작성한 글들도) Neural Rendering, 3D Reconstruction 분야를 주로 연구했지만, 2024년 팀의 R&R 이 ‘3D 생성’ 쪽으로 방향을 선회하면서 2023년 말부터 3D 생성 SOTA 연구들을 살펴보고 이를 실제로 적용할 수 있는지 테스트해보고 있었다.
그 시점까지도 가장 유망하고, 사람들이 많이 연구하는 방법은 Score (gradient of log probability) Distillation Sampling, SDS 라는 pre-trained 2D generative model 과 NeRF 를 이용하여 3D asset (NeRF) 를 생성하는 방법이었다.
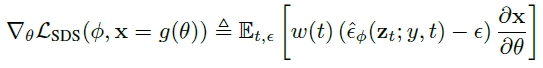
간략히 개괄하자면, init NeRF model 의 rendering 을 일종의 diffusion noise 라고 생각하고, diffusion reverse process 를 이용해 image 를 text-prompt 에 잘 맞게 만들기 위한 "score" (Gradient) 를 추출해서 NeRF 학습에 사용하는 것이다. 즉 2D generative model 이 잠재적으로 알고 있는 3D 정보를 추출하여 3D 로 생성하는 기술이라고 할 수 있다.
컨셉만 봐도 아주 매력적인 기술이고, 실제로 1) 3D 데이터 부족 문제를 우회하거나, 2) 생성 모델에 기반하여 다양하고 창의적인 3D 모델을 생성하는 등의 장점이 있어 최근까지도 이 SDS variants 들이 물밀듯이 쏟아져 나오고 있다.
문제는 SDS 가 가진 태생적인 한계를 극복하기가 정말 어렵다는데 있다.
2. Challenges of NeRF & SDS
SDS 는 주로 다음과 같은 문제점들이 있다.
a) Slow Speed
NeRF + SDS 는 시간이 너~무 오래 걸린다. 애초에 indirect 하게 distillation 하는 방식에, NeRF 의 implicit representation 까지 사용하다보니 asset 당 몇 시간은 기본으로 걸리는 것이 가장 큰 문제였다. (A100 기준으로 기본 1시간 이상은 걸린다)
b) Mesh Quality
이건 NeRF, GS 를 representation 으로 주로 사용하기 때문에 생기는 문제인데, NeRF / GS 는 clean 한 mesh 로 바꾸기가 정말 어렵다.

학교에 있는 연구 그룹들은 이 문제를 중히 생각하지 않을 수도 있으나, mesh conversion 이 어렵고 quality 가 떨어진다는 것은 실사용에서 매우 심각한 문제이다.
애초에 3D content 를 사용하는 engine 들에서 NeRF 는 지원하는 경우가 없을뿐더러 (정말 아예 없다). Rasterization 기반인 Gaussian Splatting 이야 사정이 좀 낫지만, 충돌 처리, relighting, popping (flickering) 등 당장 실사용하기 힘든 수많은 문제가 존재한다.
c) Multi-Face Problem
Multi-face problem, 이집트 신화의 신 Janus 가 머리가 두 개인 것에 빗대어 janus problem 이라고도 부르는 이 문제는 SDS 가 근간으로 삼는 2D generative model 의 학습 데이터가 이미지이기 때문에, frontal-view bias 가 있어 생기는 문제이다 (back/side 를 이해하지 못함). 따라서 2D diffusion model 을 SDS 하면 ‘face’ 가 이상한 곳곳에 튀어나온다.

Janus Problem 을 해결하기 위해 등장하기 시작한 것이 MVDream, ImageDream 혹은 Zero123 등을 위시한 ‘Multi-View Diffusion’ 이다.
이는 다음과 같이 prompt (text / image) 에 대해서 front 뿐 아니라 side / back view 등도 함께 생성하도록 diffusion model 을 tune 하는 것이다.

이 모델에 SDS 를 활용하면 janus problem 은 생기지 않지만, 위에 언급한 slow speed 나 mesh quality 를 해결하기엔 여전히 요원하다.
또한 현존하는 모든 MVDiffusion model 은 training 의 어려움 때문인지 SD1.5, 2.1 모델을 기반으로 한다. 이는 즉 model 의 capacity 가 가뜩이나 512 resolution 으로 작은 예전 SD 모델에서 2x2 grid 로 MV image 를 생성하면서 256 resolution 으로 quality 가 제한되는 심각한 문제가 발생했다.
Super-Resolution / Latent-Upscaling 등의 우회 방법이 있긴 하지만, MVDiffusion 은 단순히 256 res 로 제한되는걸 넘어, back ↔︎ side view 에 대해 심각하게 떨어지는 fidelity 의 결과물을 내놓는다.
| input | front | back | side |
|---|---|---|---|
 |  |  |  |
따라서 SR/Latent-Upscale 의 원본 재료 자체가 너무 저열한 quality 의 input 이기 때문에 이전 연구들은 주로 frontal view 는 input image 로 바꿔치기하고, 이 결과에 SR 을 적용하여 마치 '모델의 생성 결과가 1K 이상인 것처럼' 눈속임하는 전략을 내세웠다. 당연히 실사용은….
misc.
-
속도 향상을 위해 NeRF 대신 Gaussian Splatting 사용하는 DreamGaussian 등이 등장하기도 했는데, 알고리즘을 테스트해보면 알겠지만 update 가 정말 불안정하다.
- Explicit Primitive 인 3D Gaussian 을 사용하기 때문에 SDS 의 간접적인 Distillation 방식이 3D 에셋을 쉽게 "튀게" 만드는 경향이 있다. (splat artifacts)
- 공식 코드에서도 이러한 문제를 인지하고 있는지, 500 iteration 의 짧은 Coarse Training 만 진행하고, Mesh Optimization 으로 Second Stage 에서 Refine 하는 우회적인 방식을 사용한다.
- 결과적으로 DreamGaussian 의 성능은 기대에 미치지 못했다.
-
그리고 research 에서는 그리 언급되지 않지만, 사내 아티스트 피드백 중 또 하나는 ‘색감’ 이 너무 이상하다는 것. 이 또한 distillation 학습에서 latent space <-> RGB space 의 차이 때문인 것 같은데, 해결할 방법이 요원했다.
(ICLR2025 에 제시된 SDS SOTA 인 CFD project page 를 첨부한다… SDS 특유의 이상한 색감이 있다)

3. Large Reconstruction Model
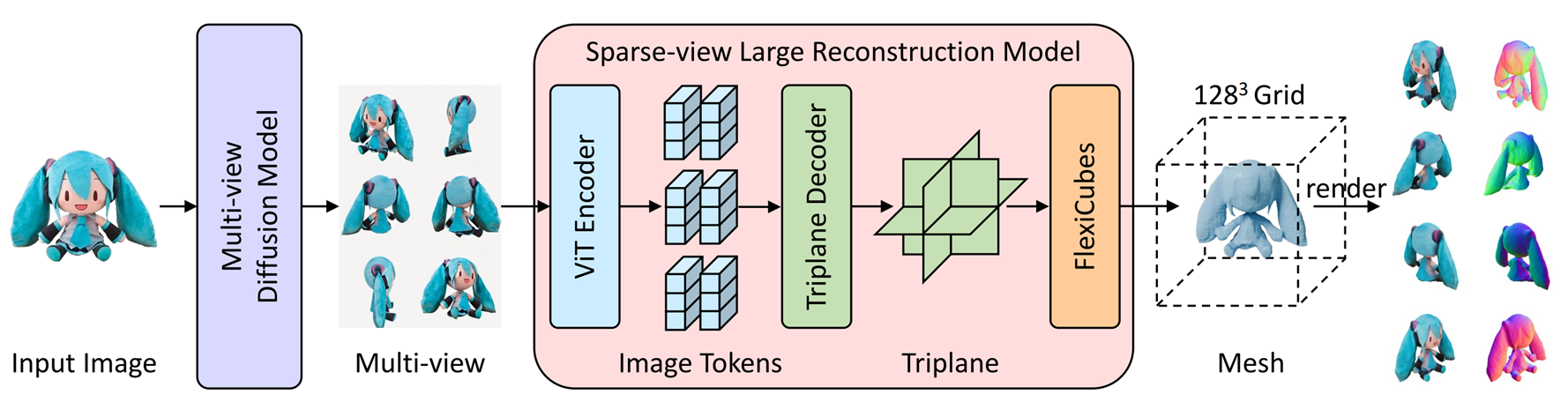
Transformer model 의 성공을 3D NeRF 에서도 도입하겠다는 야심찬 시도가 Large Reconstruction Model 계열이라고 할 수 있다. Janus 를 없애기 위해 Multi-View Diffusion 의 feature 로부터 시작해 tri-plane NeRF parameter 자체를 estimation 하는 방법 등이 있다.
하지만 LRM 계열은 "Parameter 를 예측하는 방식" 이라는 구조적인 한계 때문에 품질을 높이기가 매우 어렵다. 최근까지 LRM 계열의 SOTA 였던 stability 사의 SF3D 가 384 res 를 가지고 있다. 언뜻 봐서 괜찮아 보일지 모르지만 크게 본다면… 여전히 실사용 수준의 품질에는 미치지 못하는 것을 알 수 있다.
| input | output |
|---|---|
 |  |
LRM 의 output 도 NeRF/GS 이기 때문에 생기는 meshing 문제는 차치하고서라도, 다른 domain 에서의 생성 모델 발전 속도를 생각하면 사실 이는 쉽게 해결될 수 있는 문제로 보였다.
하지만… 2024년 말 / 2025년 초 연이어 등장한 압도적인 SOTA 모델들의 등장으로 (Trellis, Hunyuan, and,…… CaPa ㅎㅎ), 3D 생성의 주류는 LRM 계열에서 멀어지는 추세이다. 이에 해당하는 내용은 연작으로 다음 글에서 자세히 다루도록 하겠다.
4. Else: MV RGB/Normals + Mesh Optimization / Sparse Neural Reconstruction
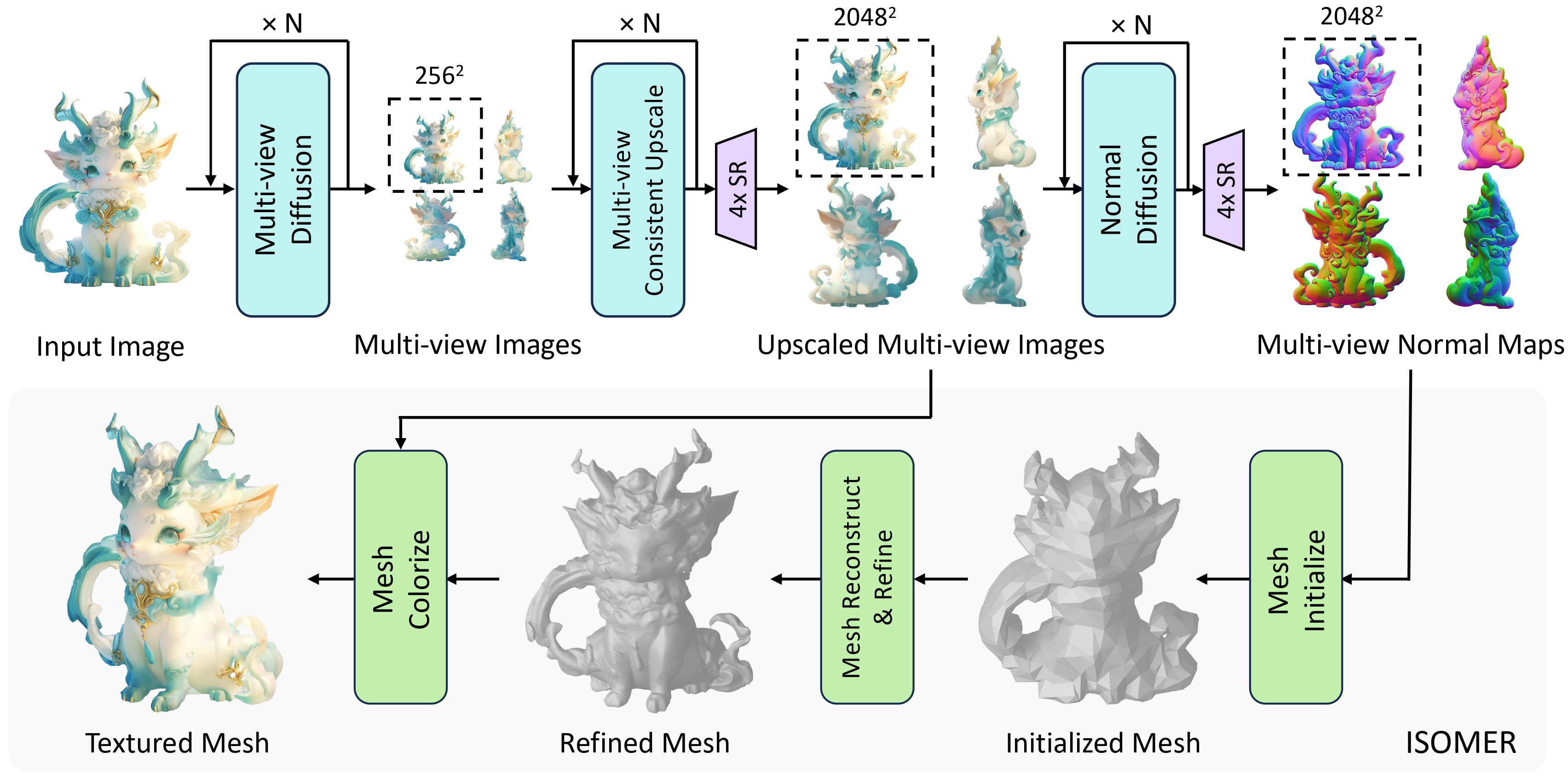
MVDiffusion 이 등장하면서, MVDiffusion output 을 이용해 ‘sparse view 3D reconstruction’ 하게 되면 그 결과 자체를 3D generation 으로 바라보는 접근법들이 등장했다.
대신에 4 view 만으로는 high-quality reconstruction 이 힘들기 때문에, Multi-View RGB 에 더불어 normal map 까지 estimation 하여 MV RGB/normals 정보를 이용하는 방법들이 대두되었다.
-
Wonder3D (& Era3D): Sparse-view NeRF Reconstruction
-
Unique3D: Spase-View Differentiable Mesh Optimization
등이 그 예시.
언뜻 reasonable 한 방식인데, 문제는 최종 품질이 generated output 의 multi-view consistency 에 대해 굉장히 구애받는다는데 있다.이 때문에 안정성이 극히 떨어졌다.
Fig: MV RGBs + Normal → Differential Mesh Optimization
| Mesh Optimization w/ GT Normal | Texturing |
|---|---|
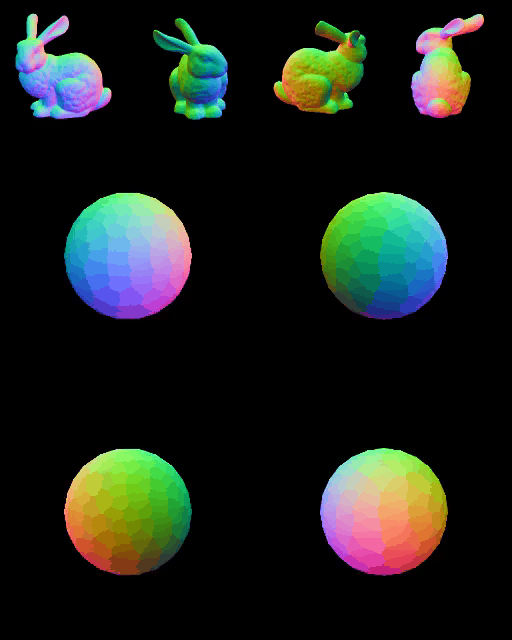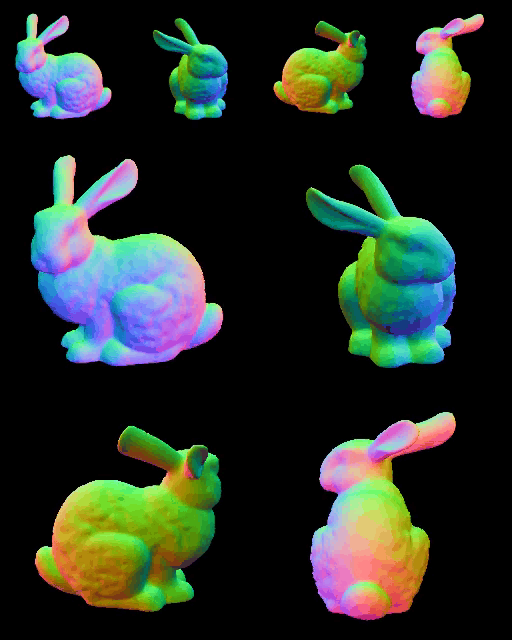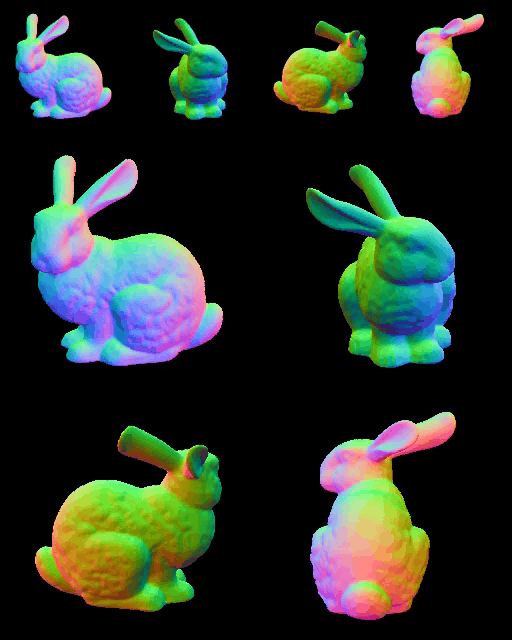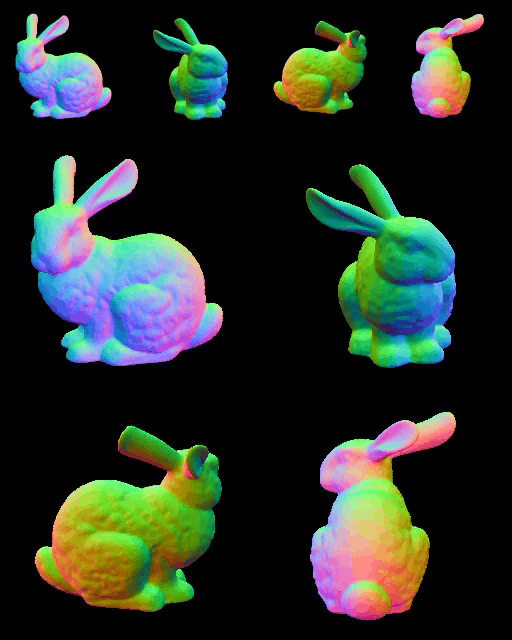 |  |
실험하던 MV RGB+Normals → Mesh Optimization 방식의 GT normal 일 때의 결과이다. Normal 에서의 multi-view consistency 가 완벽하면 shape 은 잘 생성하는 모습이지만, normal 이 조금이라도 엇나가면 다음과 같은 결과물이 생성된다…

5. 마치며
물론 SDS 는 2D 생성 모델과 NeRF 를 결합하여 3D 에셋 생성 분야에 새로운 가능성을 제시한 중요한 기술이다. 2D 생성 모델의 힘을 빌려 3D 생성의 어려움을 극복하고, 텍스트 프롬프트 기반 3D 에셋 생성이라는 새로운 패러다임을 제시한 3D 생성 모델 발전의 중요한 이정표임에는 틀림없다. 하지만 실사용 단계에서 심각한 문제점들,
-
Time Complexity (SDS)
-
Janus Problem (SDS)
-
Janus ↔︎ Quality Tradeoff (MVDiffusion)
-
Geometric Stability (MV RGBs/Normals → Differential Optimization)
-
Quality (sparse NeRF, LRM)
-
Mesh Conversion (NeRF representation)
을 극복하지 못하는 모양새다.
NeRF 의 속도, 실사용의 제한성은 NeRF → GS 로의 paradigm 이동의 결정적인 빌미였다고 생각했는데, 역시나 비슷한 상황이 3D 생성 분야에서도 어김 없이 일어났다.
그렇다면 이런 문제를 어떻게 해결할 수 있을까? 바로 다음 글에서 점차 SOTA paradigm 을 굳혀가는 ShapeVAE 기반 3D 생성 method (Trellis, Hunyuan3D) 등에 대해서 톺아보도록 하겠다.
stay tuned...!

저는 real scale Digital twin 분야쪽 종사자로서 NeRF 보다는 explicit 한 3DGS 쪽을 면밀히 보고 있었는데, 최근 MeshGPT 이나 그 연계 논문인 MeshAnything 쪽을 보면서 NeRF, 3DGS 의 representation 방법에 너무 매몰되어있었나? 라는 생각이 최근에 들더라구요. 이제는 슬슬 direct Mesh generation 방법론들이 부상할 것 같습니다ㅎㅎ 좋은 글 잘 봤습니다.