
1. Introduction
RTX50 시리즈 발매가 얼마 남지 않은 요즈음, NVIDIA 측에선 차세대 RTX 시리즈에 적용될 신기술을 연이어 발표하며 기대를 모으고 있다.
바로 2025년 1월 7일 오늘, NVIDIA 측에서 Developer Blog 와 YouTube 에 ‘NVIDIA RTX Neural Rendering Introduces Next Era of AI-Powered Graphics Innovation’ 란 이름으로 RTX50 시리즈에 사용될 ‘RTX Kit’ 기술을 공개했다.
위 영상에서는
- RTX Neural Texture Compression
- RTX Neural Materials
- Neural Radiance Cache (NRC)
의 3가지 기술을 볼 수 있는데, 자세한 documentation 이 공개되지 않아 아직 정확히 어떤 기술이 사용된 것인지는 알 수 없다. 대신에 Technical Blog 글에서 각 기술에 대한 대략적인 설명이 있어, 이로 말미암아 이 기술들이 RTX 라인에 Neural Rendering 기술을 도입하려는 시도들로 추측 중이다.
이 글에서는, RTX50 시리즈에 적용될 Neural Rendering 기술을 함께 추측해보도록 하자. (Jan 07, 2025, PM 04:42 GMT+9)
2. RTX Neural Texture Compression
NVIDIA 측에서 공개한 Neural Texture Compression 에 대한 설명은 다음과 같다.
RTX Neural Texture Compression uses AI to compress thousands of textures in less than a minute. The neural representations are stored or accessed in real time or loaded directly into memory without further modification. The neurally compressed textures save up to 7x more VRAM or system memory than traditional block-compressed textures at the same visual quality.*
RTX Neural Texture Compression은 AI를 사용하여 텍스처를 압축, 기존 방식 대비 최대 7배 더 많은 VRAM을 절약하면서도 시각적 품질을 유지한다고 한다.
이러한 효율성을 가능하게 하는 Neural Rendering 기술 중 하나로 2D Instant-NGP를 생각해볼 수 있다. Instant-NGP는 Neural Radiance Fields (NeRF)의 실시간 렌더링을 가능하게 만든 기술로,
- Multi-level decomposition: 전체 scene 을 multi-level 로 나누어 저장하여 각 level 별로 scene geometry 의 다른 부분에 집중할 수 있도록 함.
- Hash Function: 해상도가 높은 level 일수록 저장해야하는 feature 의 수가 size 의 quadratic 하게 (3D 의 경우 cubic) 늘어나기 때문에, 모든 점에 대한 1:1 저장을 하지 않고 hash function 을 도입하여 필요한 메모리를 줄인다.
의 두 가지 핵심 아이디어를 사용한다. (블로그 리뷰 참조: link)
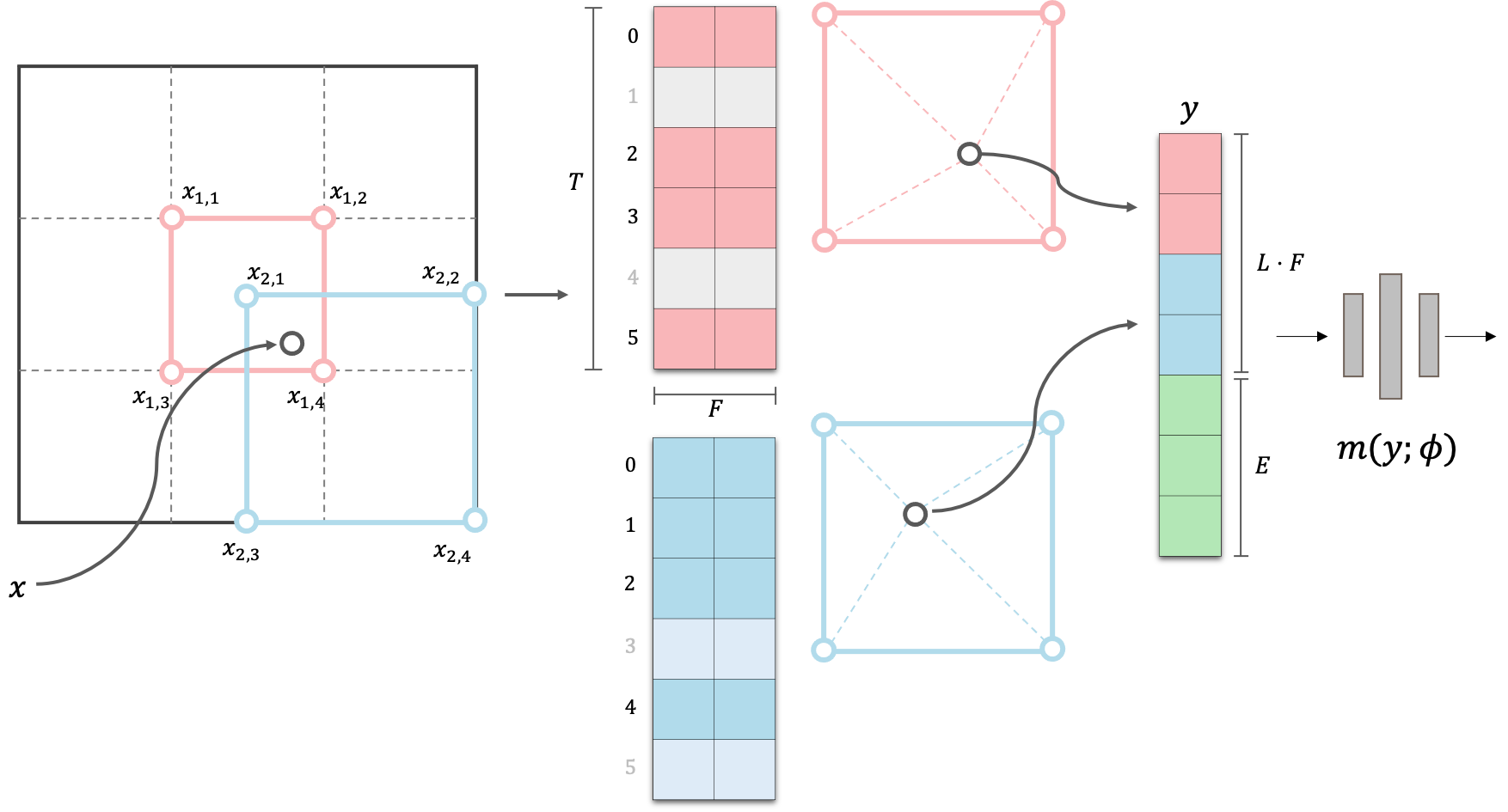
- Visualization of ‘2D’ Multi-Resolution Hash Encoding
Instant-NGP 자체도 3D scene 에 직접 적용하는 것은 아직 real time 으로 이를 다룰 수 없지만, 원 논문에서 보여준 Giga-Pixel 등의 응용 사례도 일종의 texture compression 으로 볼 수 있기 때문에 유사한 기술을 사용하지 않았을까 생각한다.
즉, texture 이미지를 multi-resolution 으로 분해하고, 각 level 의 정보를 hash function 을 통해 압축적으로 표현하는 방식을 사용할 수 있을 것이다. 이를 통해 texture 의 high-frequency fine detail 을 효율적으로 encoding 하고, 필요에 따라 빠르게 decoding 하여 높은 압축률과 시각적 품질을 동시에 달성할 수 있지 않았을까.
3. RTX Neural Materials
NVIDIA 측에서 공개한 RTX Neural Materials 에 대한 설명은 다음과 같다.
RTX Neural Materials uses AI to compress complex shader code typically reserved for offline materials and built with multiple layers such as porcelain and silk. The material processing is up to 5x faster, making it possible to render film-quality assets at game-ready frame rates.*
RTX Neural Materials 는 AI를 이용하여 복잡한 shader code 를 압축, 기존 방식 대비 최대 5배 빠른 material rendering 을 가능하게 하며, 특히 "porcelain and silk"과 같이 multi-layer shader 를 가진 복잡한 재질을 실시간으로 렌더링할 수 있다고 한다.
사실적인 소재를 복잡한 shader 없이 실시간으로 처리한다는 묘사를 보며, Gaussian Splatting 의 응용 기술이 아닐까하는 생각이 들었다.
대신에 단순히 GS 자체를 사용하는 것은, relighting 이나 충돌 처리, 각종 secondary light effect 를 적용하기 어렵기 때문에 SuGaR, Gaussian Frosting 에서 제시한 바와 같이 Polygonal Mesh + Gaussian Splatting 의 composition 형태 가 아닐까 싶다.
3.1. Mesh + Splats
Gaussian Splatting 으로 학습된 scene 은 mesh 형태로 변환할 때, Spherical Harmonics coefficients 로 학습한 detail 한 color 표현이 날아가는 경우가 많다.
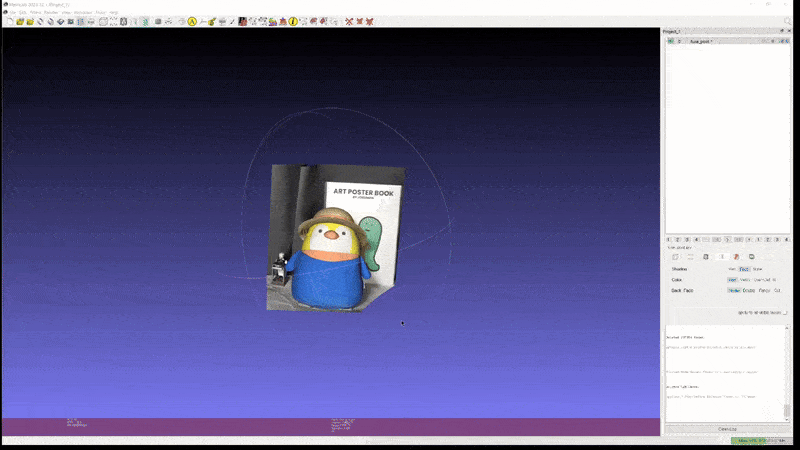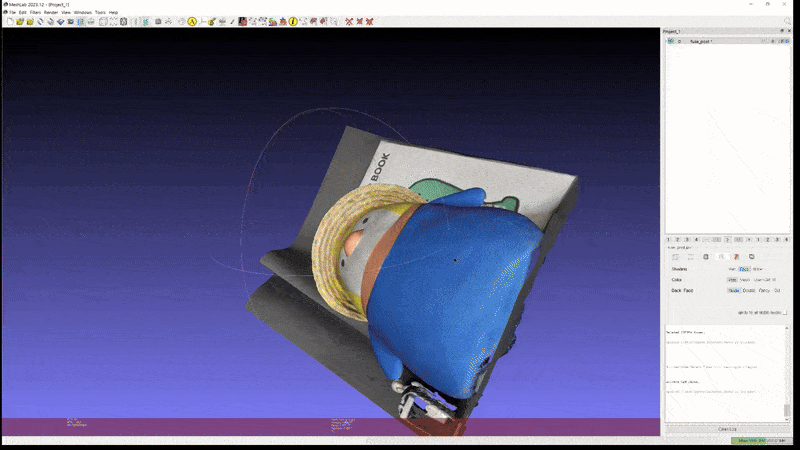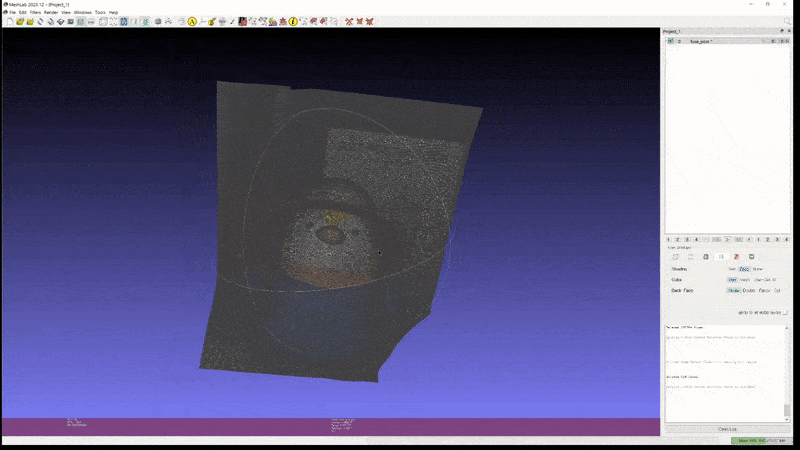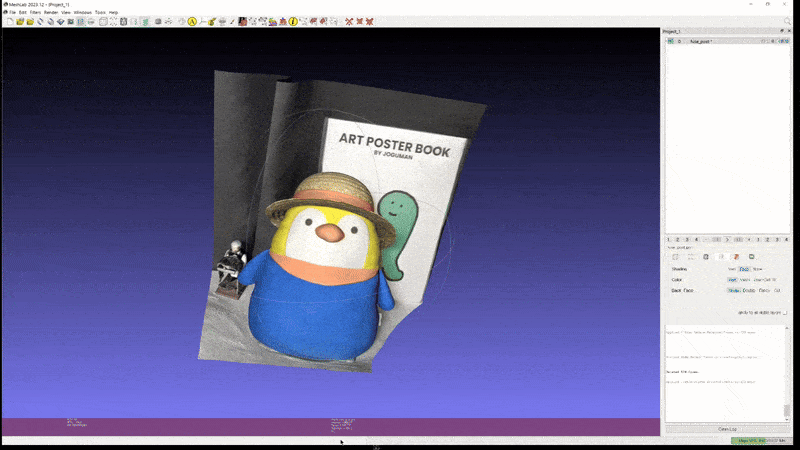
위 영상은 2D GS 로 학습한 scene 을 mesh 로 변환한 예시인데, geometry 자체는 망가지지 않고 깔끔하게 복원됐지만, 색 표현 등은 Radiance Fields 를 직접 볼 때만큼 realistic 하지 않은 모습임을 알 수 있다.
이는 mesh face 에 color 를 mapping 하는 방식이 보통 Spherical Harmonics 의 0 level coefficents 만을 취해서 이를 diffuse color 로 여기고 나머지 high level coefficients 를 버리기 때문이다.
SuGaR, Gaussian Frosting 에서는 이러한 conventional mesh texture 표현 방식을 사용하지 않고, geometry 는 mesh 의 형태로 효율적으로 표현하되, texture 는 GS SH parameter 를 그대로 사용하여, 극사실적인 texture 를 갖는 mesh 표현 방식을 제시한 바 있다.


이와 비슷한 방식을 사용한다면, 복잡한 shader 로 표현해야하는 material 이 있을 때 이를 GS 처럼 SH coefficients 로 학습시키고, 이 parameter 를 일종의 AI 로 압축된 single-layered shader 로 간주했을 가능성이 있다.
3.2. Splats Compaction
문제는 GS paramter 로 scene 을 저장하게되면, NeRF 와 다르게 memory cost 가 굉장히 높다는 단점이 생긴다.
GS scene 의 용량이 높다는 단점은 3D GS 가 제시된 이후로 꾸준히 제기되는 단점 중 하나로, 대표적인 Mip-NeRF360 bicycle scene 의 3D GS 용량은 1.4GB 에 이른다! 따라서 GS parameter 를 그대로 저장하기보단, 여러가지 compaction method 를 통해 용량을 압축했을 것이라 예상된다.
GS 압축은 연구로도 많은 방법들이 제시되고 있지만, 아래에서는 Unity Gaussian Splatting 의 저자인 Aras Pranckevičius 의 블로그 글에서 Gaussian Splatting 압축에 대한 좋은 intuition 이 많아 이를 공유하도록 하겠다.
Ref: Making Gaussian Splats Smaller by Aras P.
3D GS 를 ply 파일로 저장할 때, ply 파일 내의 내용은 random 하게 저장되어 있다. 하지만 이를 3D 상의 locality 를 고려한 (morton order) 형태로 reordering 할 수 있는데, 이렇게 되면 인접한 splats 끼리 데이터 배열 내에 모이게 된다.

이제 locality 를 고려해 모인 data 를 일정 splats 개수 단위로 Chunking 할 수 있는데, 한 chunk 안에는 비슷한 속성을 가진 splats 들이 모여있으므로 chunk 단위의 variance 가 낮을 것이라 예상할 수 있다. 즉 이는 다시 말해 lower bits 로 각 chunk 를 표현할 수 있음을 의미한다.
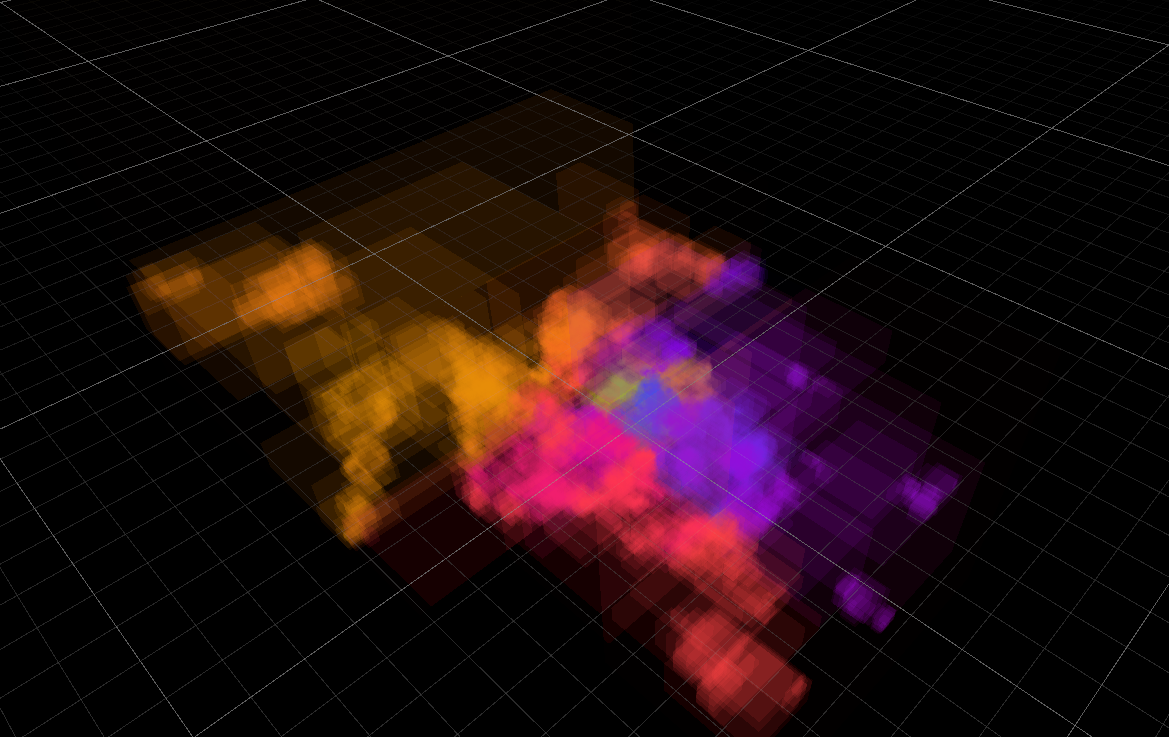
이 아이디어는 chunk 단위의 splats 들에게 일종의 ‘codebook compression’ 을 진행할 수 있음을 시사하는데, 각 chunk 단위에서 splats parameter 들을 normalize 한 후, mean / variance 를 통해 각 splats 값들을 효과적으로 나타낼 수 있게 된다.
또 한 가지 중요한 직관은, “one pixel per splat, in row major order” 로 chunking 된 GS param 정보를 visualize 해보면, 일종의 고해상도의 texture map 처럼 볼 수 있다는 것이다. 아래 두 그림은 position, SH0 parameter 에 대해 ‘one pixel per splat, in row major order’ 로 정렬해서 visualize 한 그림을 나타낸다.


즉, chunked splats paramter 들은 그 자체로 고해상도 텍스처와 매우 유사한 패턴을 보이며, 이러한 유사성을 바탕으로 기존 그래픽스에서 사용하는 block texture compression 기술을 사용할 수 있게 된다.
특히 chunk 단위에서 인접한 splats 속성 값이 서로 유사한 경향을 보이는 것은 (variance 가 작은 것) texture image 에서 인접한 픽셀의 색상이 유사한 것과 비슷한 양상이, 이러한 공간적 상관성은 데이터 압축에 매우 유리하게 작용한다.
Aras P. 는 이러한 직관을 통해 GS params 에 block compression (BC7 등) 을 적용하여 1.4G 에 달하는 original 3D GS 를 74MB 까지 줄일 수 있음을 보여주었다.
직관적으로 이 방식을 다시 표현하자면, 수많은 점으로 이루어진 그림 (Gaussian splats) 이 있을 때, 각 점의 색상, 위치 등의 정보를 모아 하나의 거대한 이미지 (고해상도 텍스처 맵) 를 만들고, 이 이미지를 JPEG 과 같은 이미지 압축 방식으로 압축하는 것이다.
RTX Neural Materials 역시 이와 유사하게, 복잡한 재질의 BRDF (Bidirectional Reflectance Distribution Function) 나 다양한 속성들을 Gaussian Primitives 로 표현하고, 이를 텍스처 압축과 유사한 방식으로 압축하여 저장 및 렌더링에 활용할 가능성이 있다. 이를 통해 복잡한 shader code 를 직접 실행하는 대신, 압축된 정보를 활용하여 렌더링 속도를 크게 향상시킬 수 있을 것이라 예상된다.
4. RTX Neural Radiance Cache
RTX Neural Radiance Cache 에 대한 설명은 다음과 같다.
*RTX Neural Radiance Cache uses AI to learn multi-bounce indirect lighting to infer an infinite amount of bounces after the initial one to two bounces from path traced rays. This offers better path traced indirect lighting and performance versus path traced lighting without a radiance cache. NRC is now available through the RTX Global Illumination SDK, and will be available soon through RTX Remix and Portal with RTX.*
multi bounce 에 대해 AI 가 추론한다는 접근 방식은 과거 발표된 NeRV: Neural Reflectance and Visibility Fields for Relighting and View Synthesis (https://pratulsrinivasan.github.io/nerv/) 에서 제시된 아이디어와 유사한 면모를 보인다.
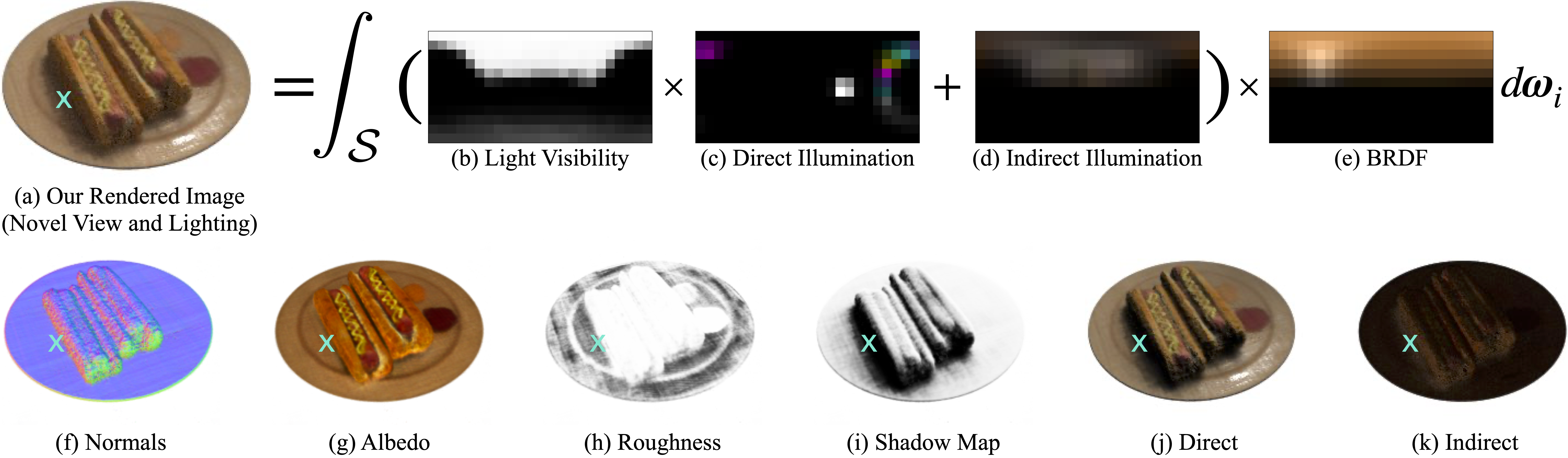
NeRV는 일반적인 NeRF model 처럼 3D coordinates 를 입력으로 받아 해당 위치에서의 opacity, color, normal vector 뿐만 아니라 아니라 임의의 방향으로의 visibility 과 첫 번째 표면 교차점까지의 거리를 예측한다.
NeRF 에서 사용하는 rendering equation 은 indirect illumination, outgoing radiance 의 다양한 reflection, refraction 등을 실제로 modeling 하지 않기 때문에 relight 하기가 힘들다.
하지만 relight 를 위해 rendering equation 에서 multi-bounce (second, third path) 를 추가로 계산하게 되면 computation cost 가 급격히 늘어나는데, NeRV 는 MLP 를 통해 계산량을 줄인 것이다.
- visibility: 가시성, 즉 multi-bounce 할 것인지 아닌지를 결정.
- distance: second path 의 거리, 즉 이 값을 통해 상호작용하는 surface 를 바로 알 수 있어 ray 에서 점을 sampling 하지 않고 MLP 를 통해 얻은 distance 의 점만 sampling 하는 식으로 계산량을 줄일 수 있음.
RTX Neural Radiance Cache는 NeRV와 유사하게, Neural Network 를 통해 장면의 light transport 특성을 학습하고, 제한된 수의 레이 트레이싱 결과를 바탕으로 multi-bounce indirect illumination 을 효과적으로 예측하는 방식으로 작동할 가능성이 높다. 이를 통해 기존의 Ray Tracing 방식보다 더 적은 연산으로 고품질의 간접 조명 효과를 얻을 수 있을 것이다.
5. Conclusion
오늘은 NVIDIA에서 공개된 RTX Kit을 통해, NVIDIA가 차세대 Graphics 혁신을 위한 핵심 기술로 도입했을 만한 Neural Rendering 기술에 대해 흥미로운 추측들을 해보았다. 물론 위에서 기술한 내용은 현재까지 공개된 정보와 관련 연구들을 기반으로 한 추측일 뿐이며, 실제 기술 구현 방식은 다를 수 있다. 하지만 이러한 추측을 통해 우리는 NVIDIA가 그리고 있는 미래의 그래픽스 기술의 방향성을 어렴풋이 엿볼 수 있다.
개인적으로 연구하는 분야가 이렇게 상용화되어 실제로 사용되는 모습을 보니 놀랍기도 하고, 한편으로는 정말 대단하다는 감탄사 나온다. 역시 NVIDIA… 앞으로 RTX 50 시리즈가 벌써부터 기대된다! (가격도 포함….)
