6. 그라파나 Alert
Grafana
Grafana는 Grafana Labs에서 개발한 오픈소스로, 수집된 데이터들을 시각화하고 모니터링을 합니다.
Grafana의 특징은 다음과 같습니다.
- 다양한 데이터 소스 지원 (Prometheus, InfluxDB, Elasticsearch)
- 플러그인 및 커스터 마이징 가능
- 다양한 채널로 알림을 설정할수 있음 (Slack, 이메일 등)
Grafana 확인
- 버전 확인
kubectl exec -it -n monitoring **sts**/kube-prometheus-stack-grafana -- **grafana cli --version**
- Ingress 확인
# ingress 확인 kubectl get ingress -n monitoring kube-prometheus-stack-grafana kubectl describe ingress -n monitoring kube-prometheus-stack-grafana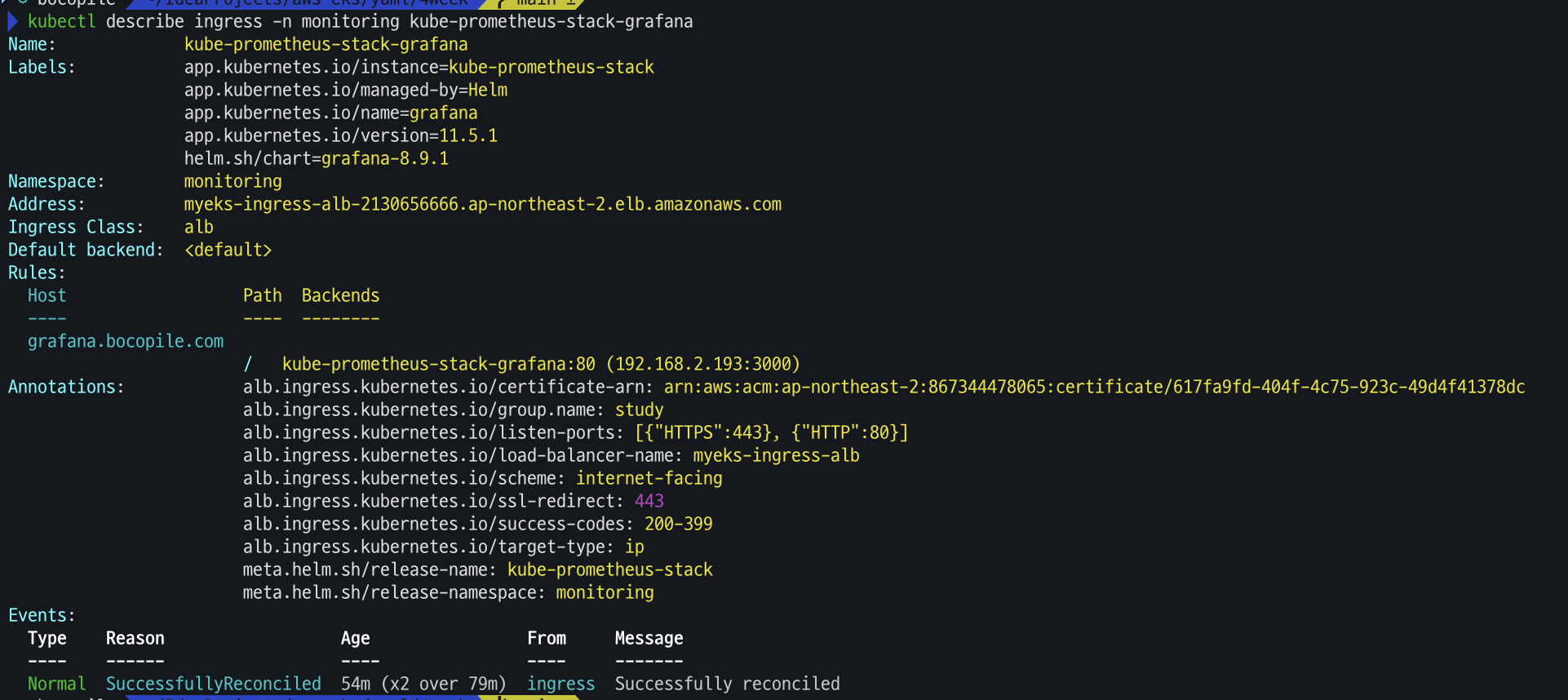
- 도메인 확인
# ingress 도메인으로 웹 접속 : 기본 계정 - **admin / prom-operator** echo -e "Grafana Web URL = https://grafana.$MyDomain"
- 해당 데이터 소스 접속 확인
# 테스트용 파드 배포 cat <<EOF | kubectl create -f - apiVersion: v1 kind: Pod metadata: name: netshoot-pod spec: containers: - name: netshoot-pod image: nicolaka/netshoot command: ["tail"] args: ["-f", "/dev/null"] terminationGracePeriodSeconds: 0 EOF kubectl get pod netshoot-pod
- 접속 확인
# 접속 확인 kubectl exec -it netshoot-pod -- nslookup kube-prometheus-stack-prometheus.monitoring kubectl exec -it netshoot-pod -- curl -s kube-prometheus-stack-prometheus.monitoring:9090/graph -v ; echo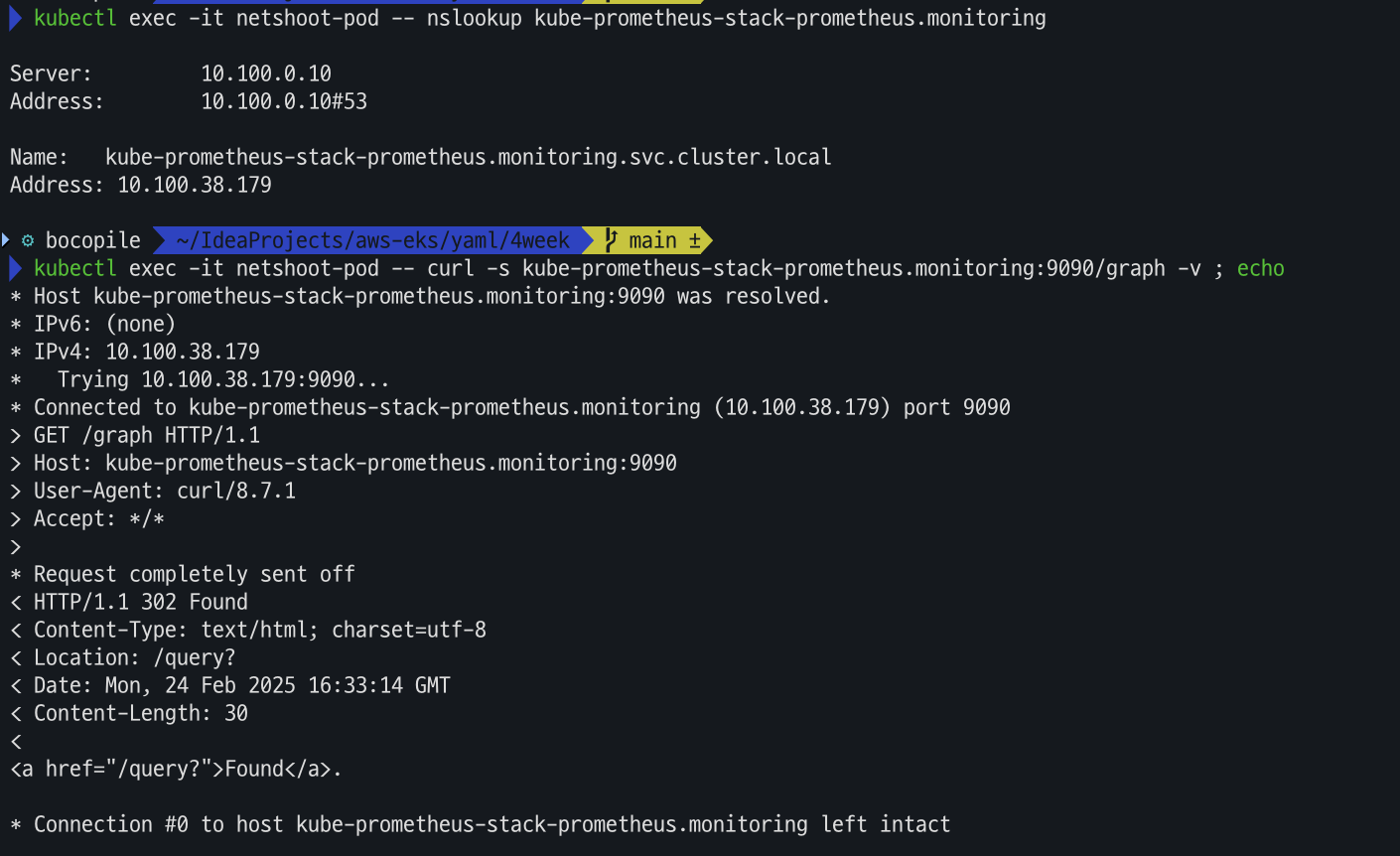
Grafana 공식 대시보드 가져오기
- [Kubernetes / Views / Global] Dashboard → New → Import → 15757 력입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [1 Kubernetes All-in-one Cluster Monitoring KR] Dashboard → New → Import → 17900 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
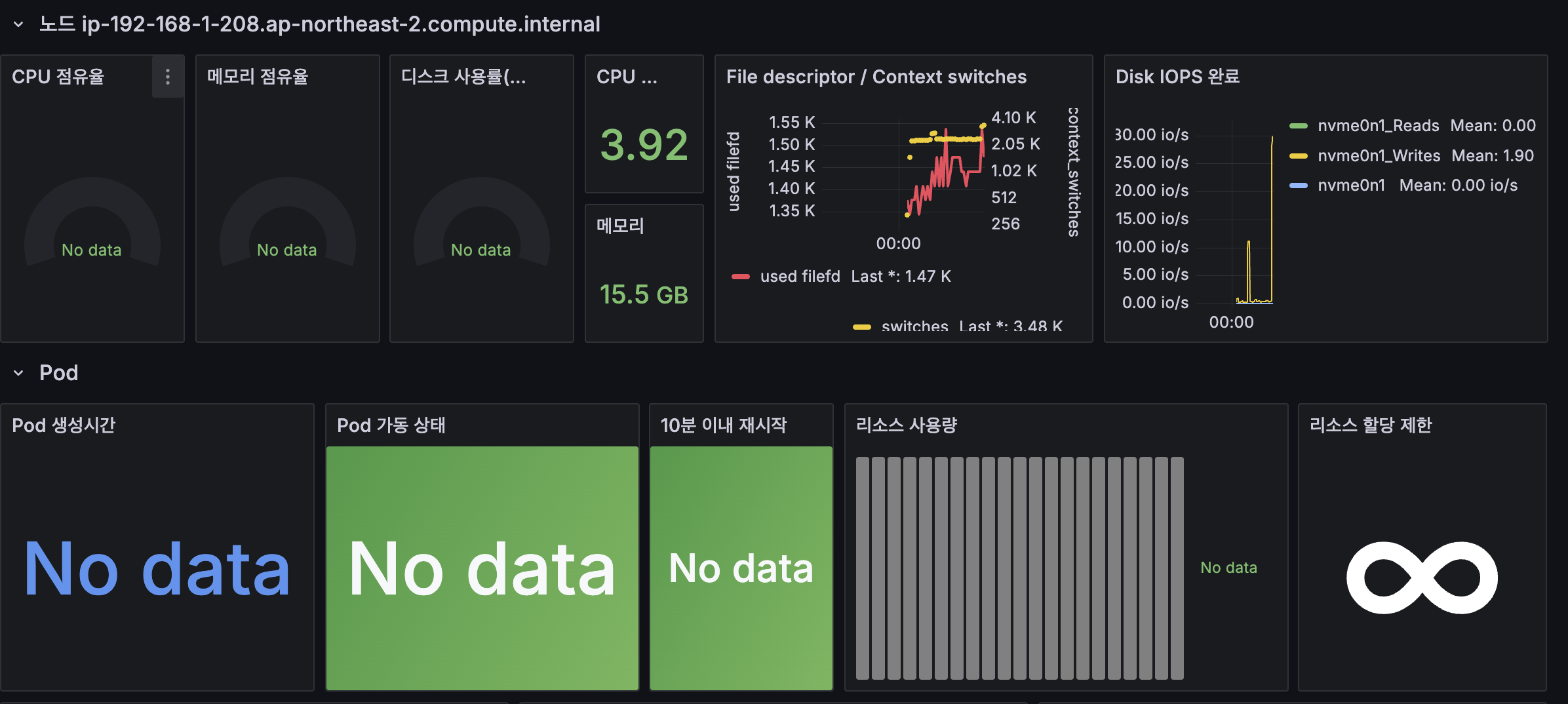
- 게시판 생성시 아래와 같이 일부 데이터가 표출 되지 않는 현상 발생
-
해당 패널에서 Edit → 아래 수정 쿼리 입력 후 Run queries 클릭 → 상단 Save 후 Apply
-
- 게시판 생성시 아래와 같이 일부 데이터가 표출 되지 않는 현상 발생
CPU 지표 수정
- 기존 설정
sum by (node) (irate(node_cpu_seconds_total{mode!~"guest.*|idle|iowait", node="$node"}[5m]))
-
Prometheus 확인
avg(node_cpu_seconds_total{mode!~"guest.*|idle|iowait"}) by (**node**) avg(node_cpu_seconds_total{mode!~"guest.*|idle|iowait"}) by (instance)- node 설정시 지표가 조회 되지 않음을 확인
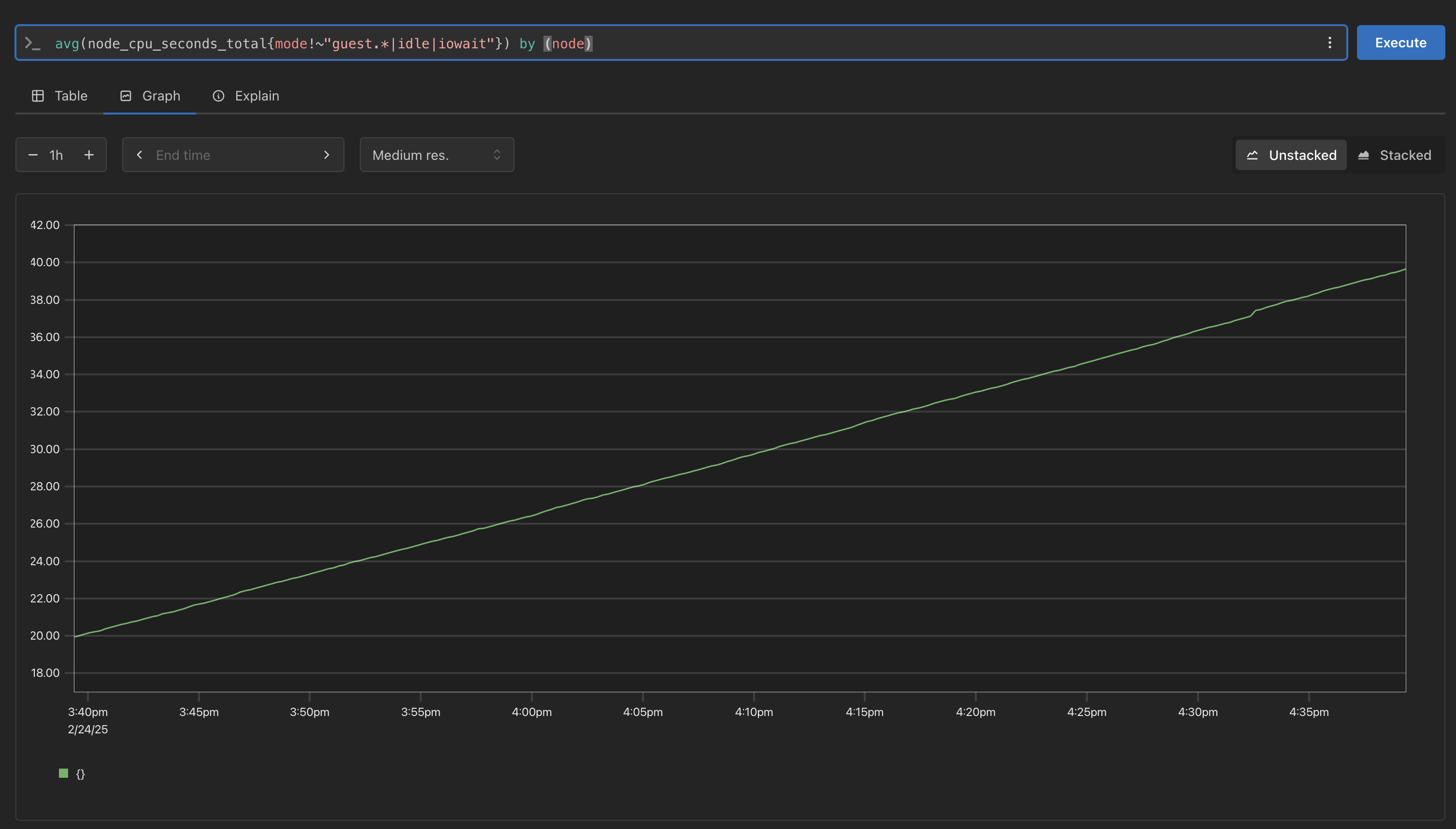
- instance로 변경시 지표가 조회 됨을 확인
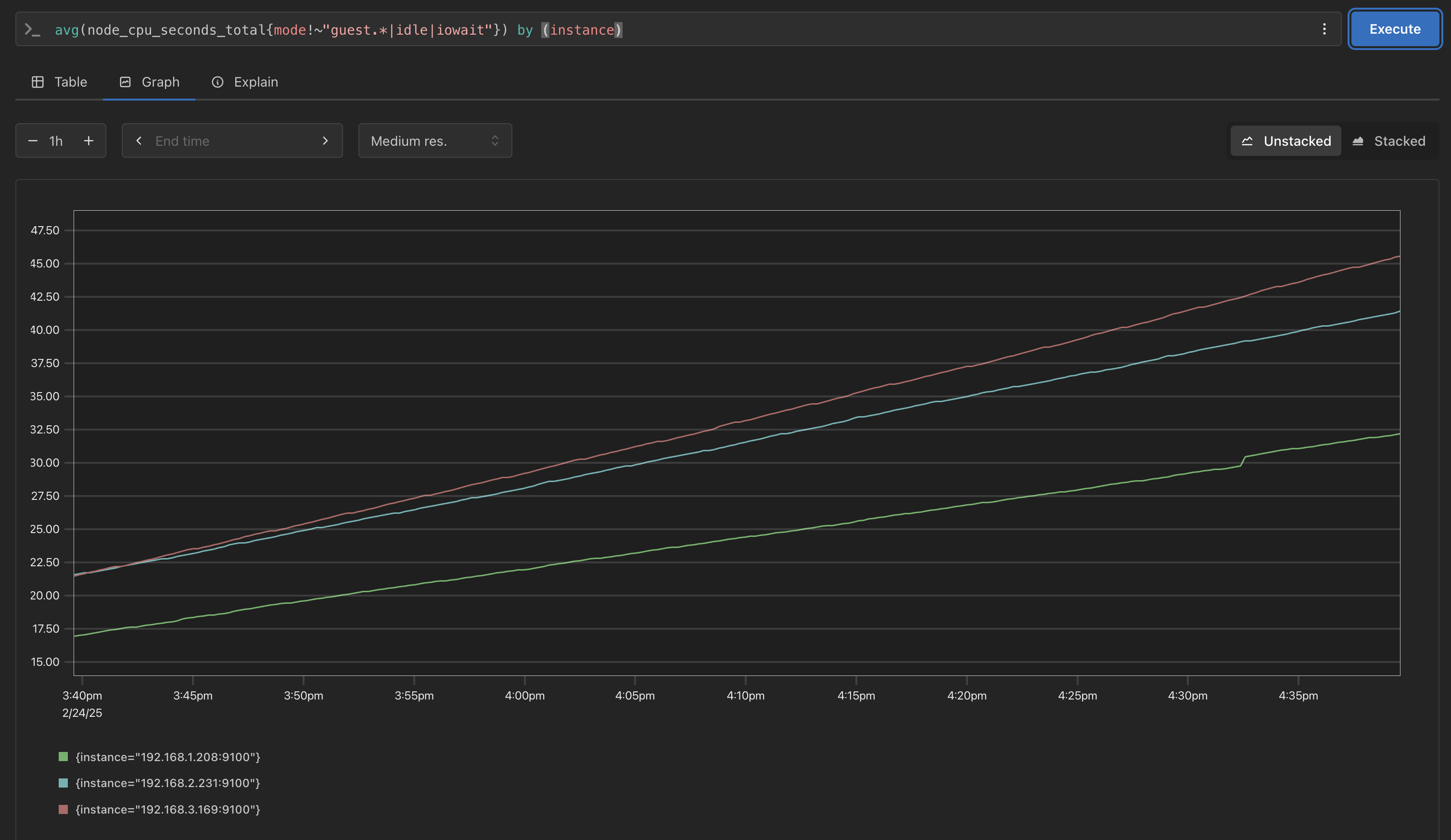
- node 설정시 지표가 조회 되지 않음을 확인
-
설정 변경
-
node → instance 변경시 동작 됨을 확인
sum by (instance) (irate(node_cpu_seconds_total{mode!~"guest.*|idle|iowait", instance="$instance"}[5m]))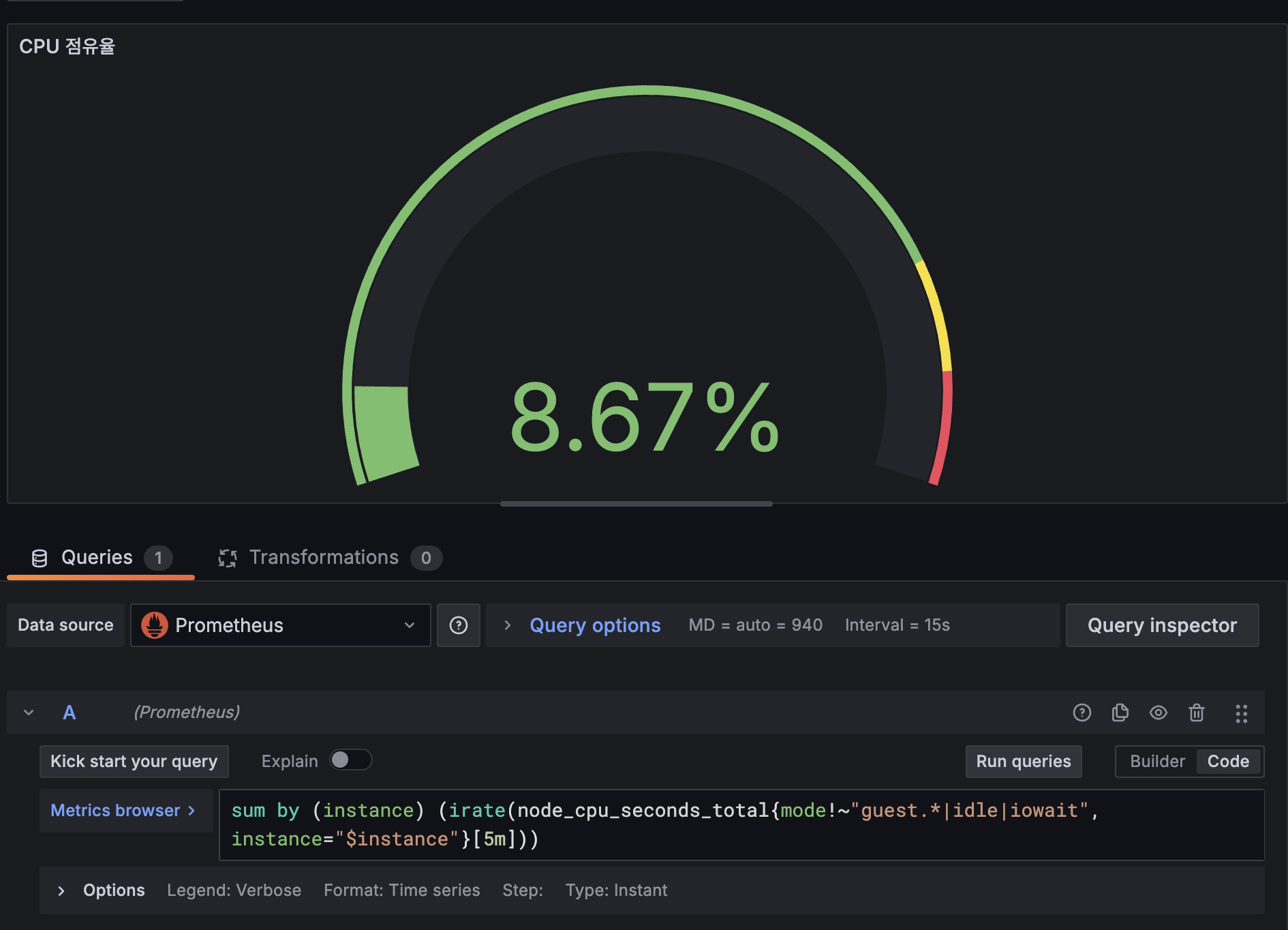
-
Memory, 디스크 사용률
- 메모리, 디스크 또한 다음과 같이 설정 되어 있음
# memory 점유율 sum(node_memory_MemTotal_bytes{node="$node"}-node_memory_MemAvailable_bytes{node="$node"})/node_memory_MemTotal_bytes{node="$node"} # 디스크 사용률 sum(node_filesystem_size_bytes{node="$node"} - node_filesystem_avail_bytes{node="$node"}) by (node) / sum(node_filesystem_size_bytes{node="$node"}) by (node) - 다음과 같이 수정 필요
-
변경 할 경우 지표 조회 되는 것을 확인
# 수정 : 메모리 점유율 (node_memory_MemTotal_bytes{instance="$instance"}-node_memory_MemAvailable_bytes{instance="$instance"})/node_memory_MemTotal_bytes{instance="$instance"} # 수정 : 디스크 사용률 sum(node_filesystem_size_bytes{instance="$instance"} - node_filesystem_avail_bytes{instance="$instance"}) by (instance) / sum(node_filesystem_size_bytes{instance="$instance"}) by (instance)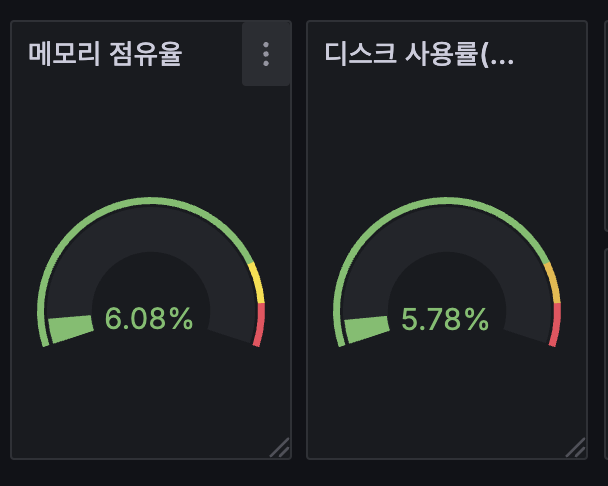
-
Pod
Pod 지표 또한 아래와 같이 보여지지 않는다
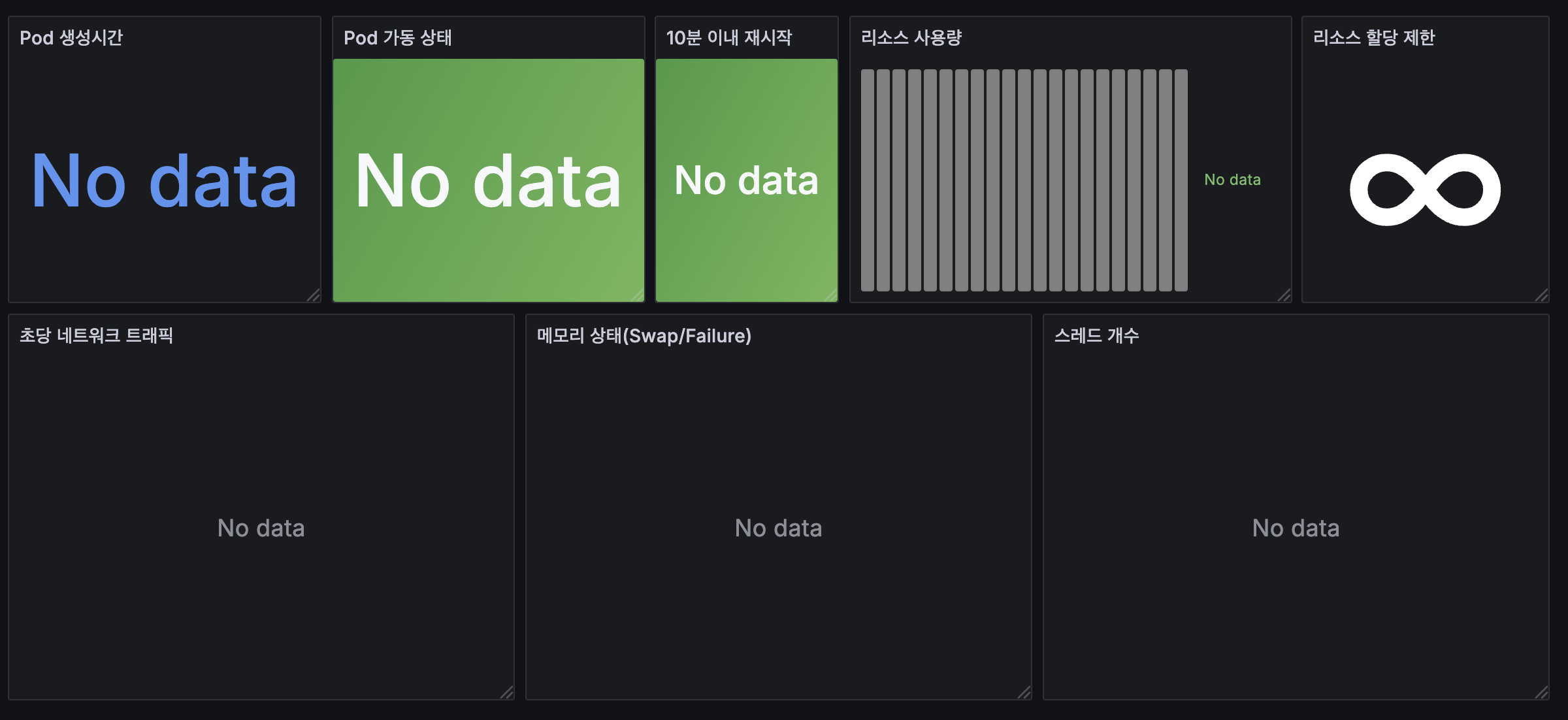
다만 앞에 CPU, Memory, Disk I/O하고 다르게 namespace/ pod parameter가 조회되지 않는다.

이런 경우 대시보드 우측 상단에 Setting 버튼을 클릭한다.

해당 버튼을 클릭한 다음 ‘Variables’ 탭을 클릭한 뒤 namespace, pod 설정 된 값이 Prometheus에서 조회 되는지 확인한다.
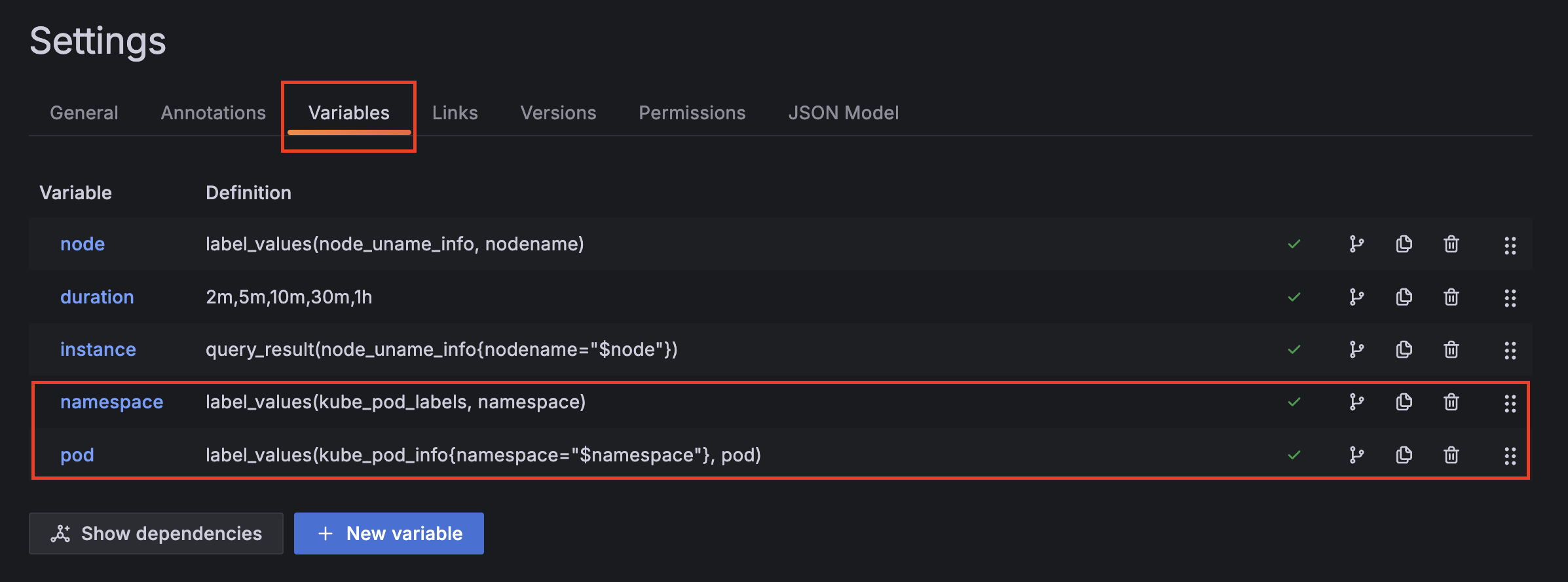
해당 값은 namespace가 조회 되지 않아서 발생하는 문제이므로 다음과 같이 변경한다.
label_values(kube_pod_labels,namespace)
-> label_values(kube_pod_info,namespace)변경이 완료되면 다음과 같이 조회 되는 것을 확인할 수 있다.
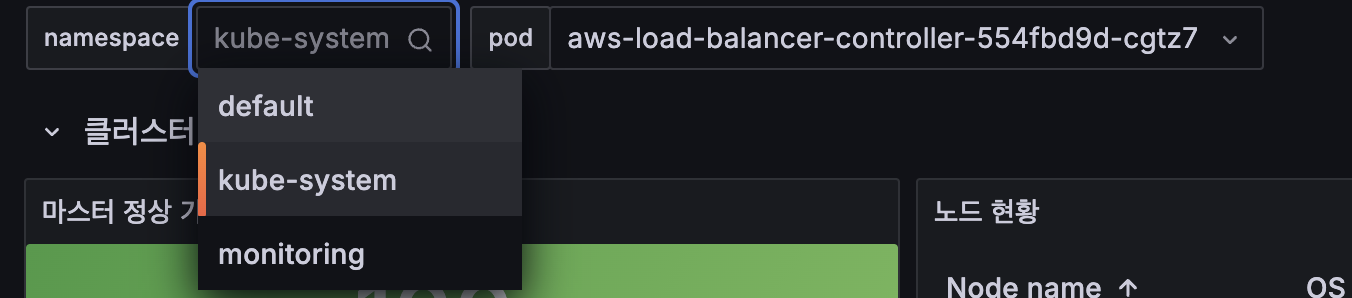
Pod / 리소스 할당 제한
리소스 설정을 확인하면 다음과 같이 설정 되어 있다.
# cpu
sum(kube_pod_container_resource_limits_cpu_cores{pod="$pod"})
# memory
sum(kube_pod_container_resource_limits_memory_bytes{pod="$pod"})우선 프로메테우스에서 조회가 되는지 확인이 필요함
# cpu
kube_pod_container_resource_limits_cpu_cores
# memory
kube_pod_container_resource_limits_memory_byte확인한 결과 cpu, memory 전부 조회 되지 않음


prometheus 버전에 따라서 PromQL을 검색해본 결과 다음과 같이 변경
# cpu
kube_pod_container_resource_limits{resource="cpu"}
# memory
kube_pod_container_resource_limits{resource="memory"}해당 조건으로 검색하면 다음과 같이 조회 되는 것을 확인 가능
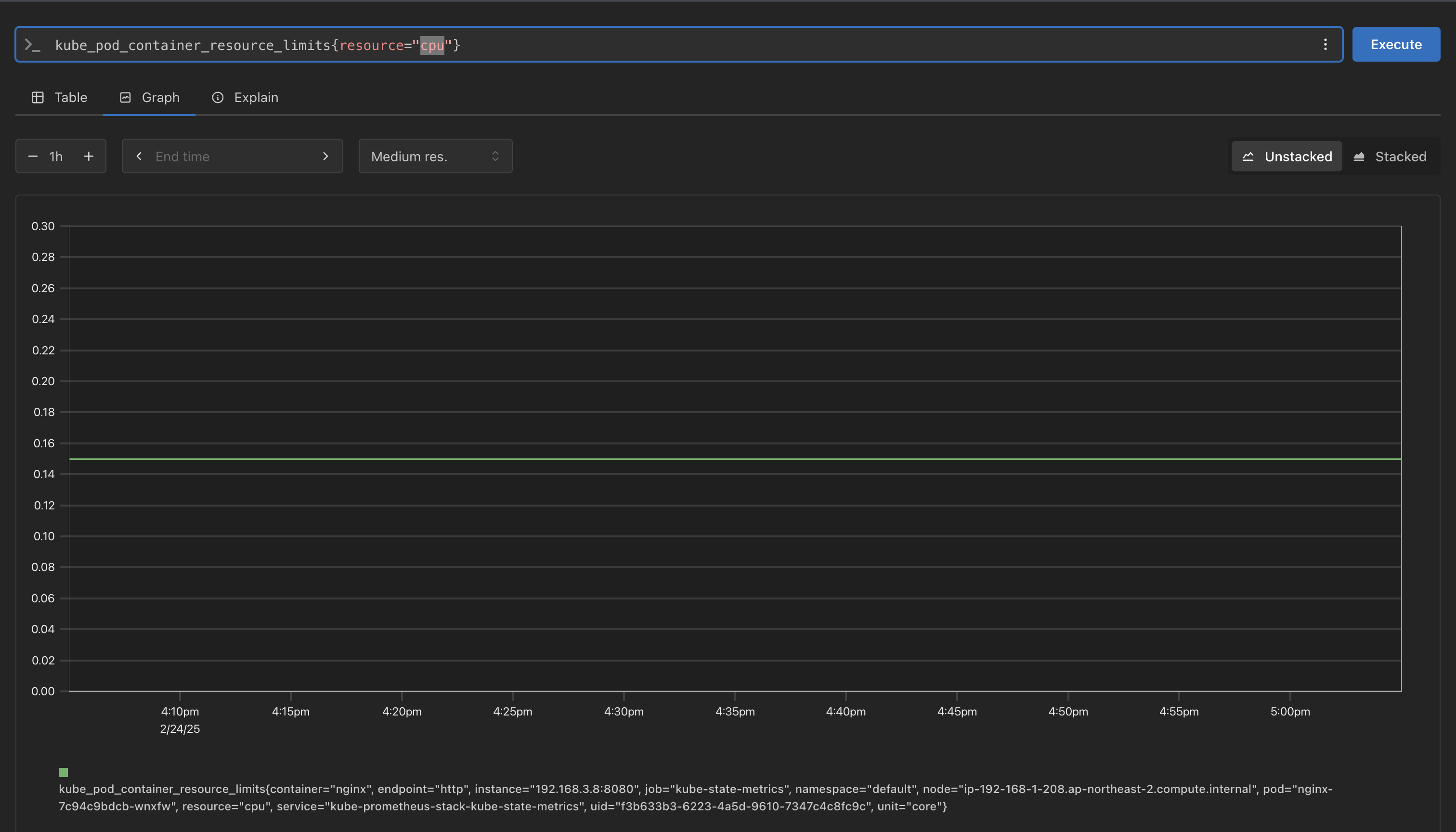
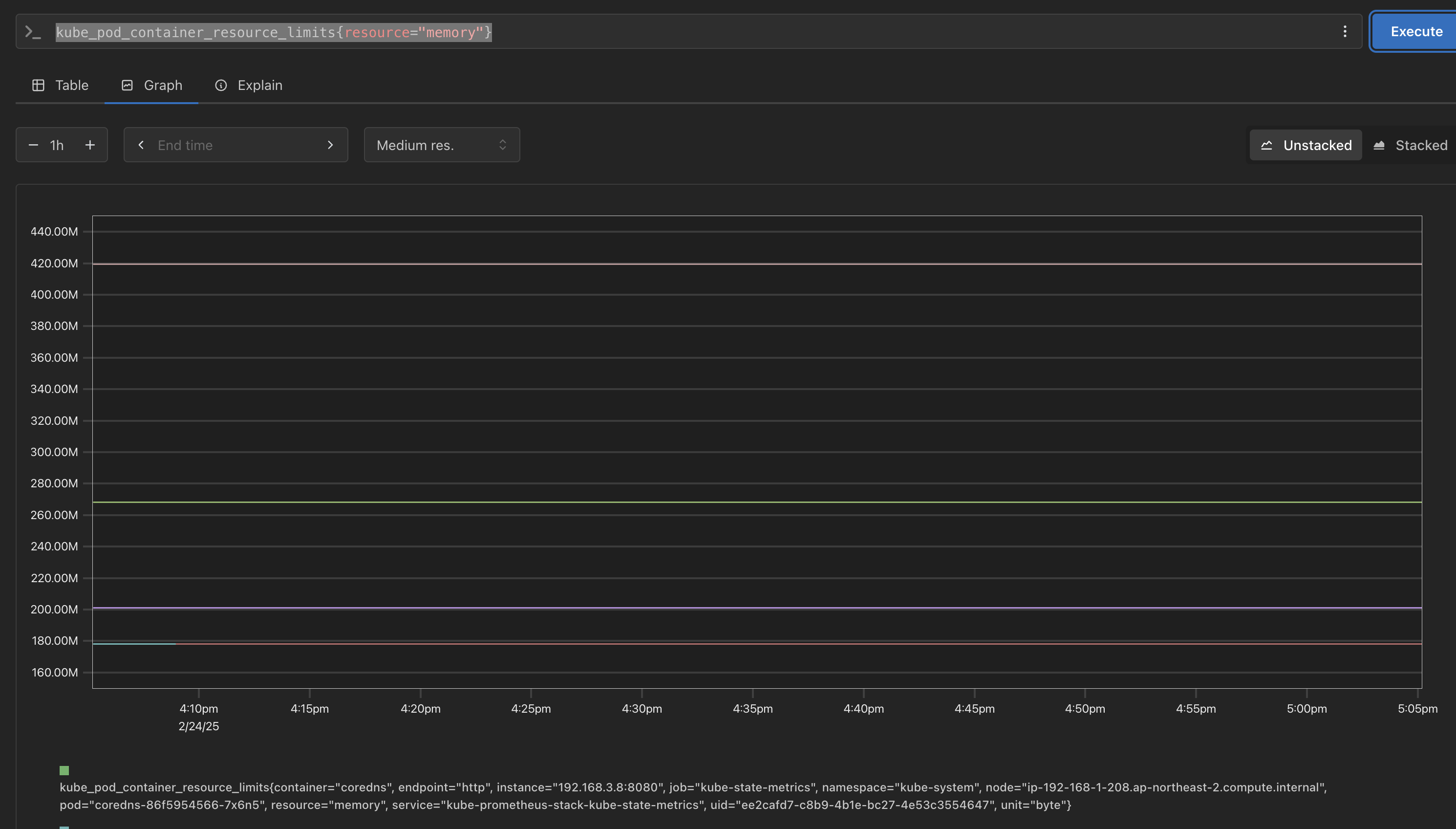
해당 값을 기반으로 Grafana 대시보드에서 적용하려면 다음과 같이 변경
# cpu
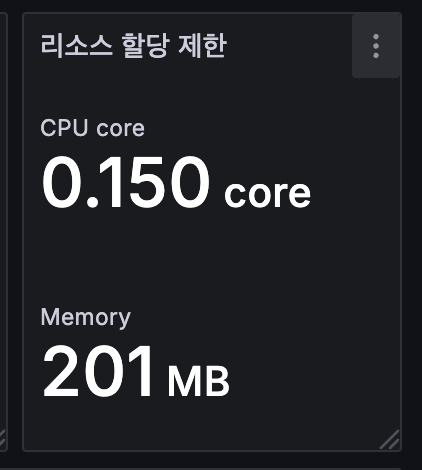
sum(kube_pod_container_resource_limits{resource="cpu", pod="$pod"})
# memory
sum(kube_pod_container_resource_limits{resource="memory", pod="$pod"})변경한 결과 다음과 같이 변경 되는것을 확인
7. OpenTelemetry
OpenTelemetry 개요
OpenTelemetry(OTel)는 추적(Tracing), 메트릭(Metrics), 로그(Logs) 등의 원격 측정 데이터를 생성하고 관리하도록 설계된 Observability 프레임워크 및 툴킷이다.
- 공급업체에 구애받지 않음 → Jaeger, Prometheus 같은 오픈소스 도구 및 상용 제품과 함께 사용 가능
- 원격 측정의 생성, 수집, 관리 및 내보내기에 중점 (저장 및 시각화는 별도의 도구 활용)
- 언어, 인프라, 런타임 환경에 관계없이 계측 가능
OpenTelemetry 핵심 개념
- Signals : 원격 측정의 주요 데이터 유형
- Traces (추적), Metrics (메트릭), Logs (로그), Baggage (여러 스팬에 전달되는 값, HTTP 헤더에 위치)
- Instrumentation : 계측 방식
- Zero-code (자동 계측), Code-based (수동 계측), Libraries (라이브러리 활용)
- Components : 데이터 수집 및 전파를 담당하는 주요 구성 요소
Distributed Tracing (분산 추적) 개요
클라우드 네이티브 애플리케이션의 요청이 여러 애플리케이션을 거치며 처리되기 때문에, 서비스 간 경계를 넘는 추적이 필수적이다.
- 요청마다 상관관계 ID(Correlation ID) 를 생성하여 이벤트 로그 및 서비스 간 전달
- 이를 통해 분산된 애플리케이션 전반에서 특정 트랜잭션과 관련된 로그를 추적
- 주요 목적 : 오류 파악, 성능 점검
분산 추적의 3가지 개념
- Trace (추적) : 하나의 요청 또는 트랜잭션과 관련된 모든 활동
- Trace ID 를 통해 고유 식별됨
- 여러 개의 스팬(Span) 으로 구성됨
- Span (스팬) : 요청 처리의 각 단계를 나타냄
- 시작 및 종료 타임스탬프를 포함
- Trace ID + Span ID 로 고유 식별됨
- Tag (태그) : 메타데이터 추가 (예: 요청 URI, 사용자 정보 등)
분산 추적 관련 도구
- OpenTelemetry는 사실상 표준으로 사용됨
- Java 기반 애플리케이션에서 OTel을 직접 사용할지, Spring Cloud Sleuth 같은 벤더 중립적인 솔루션과 통합할지 선택 가능
- Tempo : 운영 비용과 복잡성을 최소화하면서 대규모 분산 추적을 가능하게 하는 툴
- 푸시 기반 아키텍처 (애플리케이션이 직접 데이터 전송)
- 프로메테우스와 차별화됨
