인프런 권철민님 강의 정리
Section8: 텍스트 분석
텍스트 분석 개요
- NLP: 인간의 언어를 이해하고 해석하는데 중점
- 텍스트 분석: 머신러닝, 언어 이해, 통계 등을 활용해 모델을 수립하고 정보를 추출해 BI나 예측 분석 등의 분석 작업을 주로 수행
주요 영역
- 텍스트 분류: 문서가 특정 분류 또는 카테고리에 속하는 것을 예측하는 기법을 통칭
- 감성 분석: 텍스트에 나타나는 감정/판단/믿음/의견/기분 등의 주관적인 요소를 분석하는 기법을 총칭
- 텍스트 요약: 텍스트 내에서 중요한 주제나 중심 사상을 추출하는 기법
- 텍스트 군집화와 유사도 측정: 비슷한 유형의 문서에 대해 군집화를 수행하는 기법
파이선 기반 NLP, 텍스트 분석 패키지
- NLTK: 대표적인 NLP 패키지, 실제 대량의 데이터 기반에서는 수행 속도 문제로 활용되지 못하고 있음
- Gensim: 토픽모델링 분야에서 두각을 나타냄. Word2Vec 구현 등의 다양한 신기능 제공
- SpaCy: 뛰어난 수행 성능으로 가장 주목 받음
텍스트 전처리
텍스트 정규화
- 클렌징: 불필요한 문자, 기호 등을 사전에 제거 (ex. html, xml tag)
- 토큰화: 문장/단어 토큰화, n-gram
- 필터링/불용어(stopwords) 제거/철자 수정: 불필요한 단어나 의미 없는 단어 제거
- Stemming/Lemmatization: 문법적 or 의미적으로 변화하는 단어의 원형을 찾는 것
- Stemming: 원형 단어로 변환 시, 일반적인 방법 또는 더 단순화된 방법을 적용해서 원래 단어에서 일부 철자가 훼손된 어근 단어를 추출하는 경향이 있음
- python library: nltk.stem.LancasterStemmer
- Lemmatization: 품사와 같은 문법적인 요소와 더 의미적인 부분을 감안해 정확한 철자로 된 어근 단어를 찾아줌
- 변환 시간이 Stemming보다 오래 걸림
- python library: nltk.stem.WordNetLemmatizer
- Stemming: 원형 단어로 변환 시, 일반적인 방법 또는 더 단순화된 방법을 적용해서 원래 단어에서 일부 철자가 훼손된 어근 단어를 추출하는 경향이 있음
N-gram
- 문장을 개별 단어 별로 하나씩 토큰화하면 문맥적인 의미가 무시됨. 이러한 문제를 해결하려고 도입한 것이 n-gram
- 연속된 n개의 단어를 하나의 토큰화 단위로 분리해 내는 것
- Agent Smith knocks the door 을 2-gram(bigram)으로 만들면 (Agent, Smith), (Smith, knocks), (knocks, the), (the, door)과 같이 연속적으로 2개의 단어들을 순차적으로 이동하면서 단어들을 토큰화함
텍스트 피처 벡터화 유형
BOW (Bag of Words)
- 문서가 가지는 모든 단어를 문맥이나 순서를 무시하고 일괄적으로 단어에 대해 빈도 값을 부여해 피처 값을 추출하는 모델
- 장점: 쉽고 빠른 구축
- 단점:
- 문맥 의미 반영 부족 (단어의 순서를 고려하지 않기 때문)
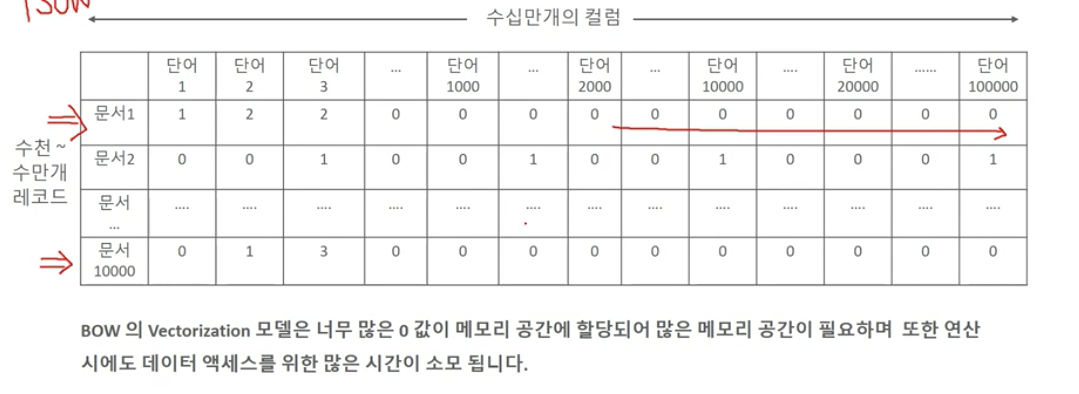
- 희소 행렬 문제 (대부분의 데이터가 0이기 때문에 수행 시간과 예측 성능이 떨어질 수 있음)

벡터화 유형
- 단순 카운트 기반의 벡터화
- 단어의 빈도 수를 기반으로 단어 피처에 값을 부여
- 카운트 값이 높을수록 중요한 단어로 인식됨
- TF-IDF 벡터화
- 언어의 특성상 문장에서 자주 사용될 수 밖에 없는 단어까지 높은 값을 부여하는 단점을 보완
- 개별 문서에서 자주 나타나는 단어에 높은 가중치를 주되ㅡ 모든 문서에서 전반적으로 자주 나타나는 단어에 대해서는 페널티를 줌

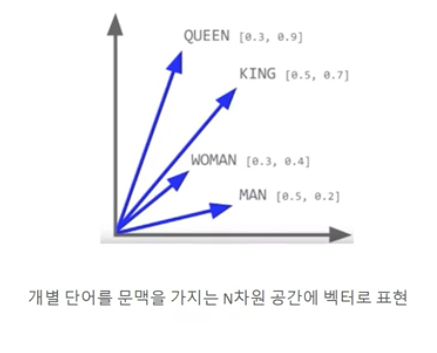
Word Embedding (Word2Vec)
희소행렬
저장 변환 형식
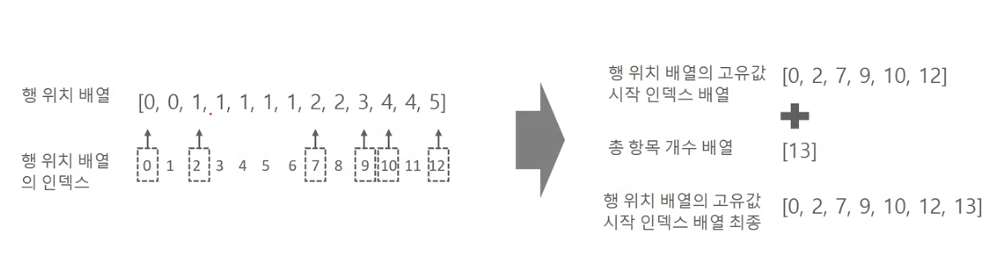
- COO 형식
- 0이 아닌 데이터만 별도의 배열에 저장하고, 그 데이터를 가리키는 행과 열의 위치를 변도의 배열로 저장하는 방식

- 0이 아닌 데이터만 별도의 배열에 저장하고, 그 데이터를 가리키는 행과 열의 위치를 변도의 배열로 저장하는 방식
- CSR 형식
- COO 형식이 위치 배열값을 중복적으로 가지는 문제를 해결한 방식
- 일반적으로 많이 사용됨
감성 분석
- 문서의 주관적인 감성/의견/감정/기분 등을 파악하기 위한 방법
- 소셜미디어, 여론조사, 온라인 리뷰 등 다양한 분야에서 활용됨
- 분석 방법
- 지도 학습 기반의 분석: 텍스트 기반 분류와 거의 동일
- 감성 어휘 사전을 이용한 분석: 감성 분석을 위한 용어와 문맥에 대한 정보를 가지고 있음. 이를 이용해 긍부정 감성 여부를 판단
감성 어휘 사전 기반 분석
- SentiWordNet: 감성 단어 전용의 WordNet을 구현한 것, Synset별로 3가지 감성 점수를 할당 (긍정/부정/객관성)
- VADER: 소셜미디어의 텍스트에 대한 감성분석을 제공, 비교적 빠른 수행 시간을 보장하기에 대용량 텍스트 데이터에 잘 사용됨
- Pattern: 예측 성능 측면에서 가장 주목받음. 파이썬 2.x버전에서만 동작함
SentiWordNet
- 문서를 문장 단위로 분해
- 다시 문장을 단어 단위로 토큰화하고 품사 태깅(POS)
- 품사 태깅된 단어 기반으로 synset 객체와 senti_synset객체를 생성
- senti_synset에서 긍/부정 감성 지수를 구하고 이를 모두 합산해 특정 임계치 값 이상일 때 긍정으로 아닌 경우는 부정으로 결정
VADER
- 소셜미디어의 감성 분석 용도로 만들어진 룰 기반의 Lexicon
- SentimentIntensityAnalyzer 클래스 이용
- 문서별로 polarity_scores 메서드를 호출해 감성 점수를 구한 뒤, 해당 문서의 감성 점수가 특정 임계값 이상이면 긍정, 아니면 부정으로 판단
- neg: 부정, neu:중립, pos:긍정, compound: neg,neu,pos를 적절히 조합해 -1 ~ 1 사이의 감성 지수를 표현한 값
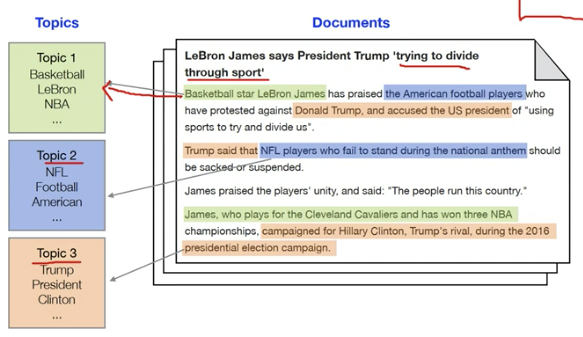
토픽모델링, LDA
- 토픽모델링: 문서들에 잠재되어 있는 공통된 토픽들을 추출해 내는 기법을 의미
- 문서들이 가지는 주요 토픽의 분포도와 개별 토픽이 어떤 의미인지를 제공하는 특징을 가짐

알고리즘 유형, 종류
- 종류
- LSA (Latent Semantic Analysis), pLSA
- LDA (Latent Dirichlet Allocation)
- NMF (Non Negative Factorization)
- 유형
- 행렬 분해 기반 토픽 모델링: LSA, NMF
- 확률 기반의 토픽 모델링: pLSA, LDA
- 가정
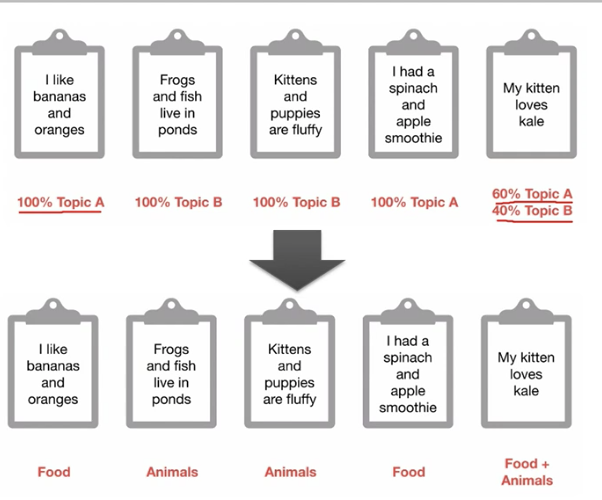
개별 문서는 혼합된 여러 개의 주제로 구성되어 있다
개별 주제는 여러 개의 단어로 구성되어 있다.
행렬 분해 기반
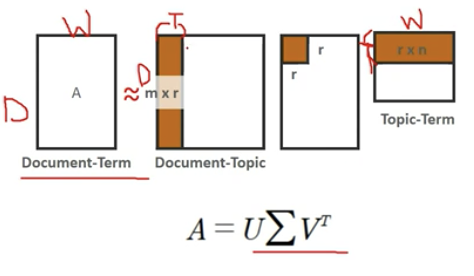
확률 기반
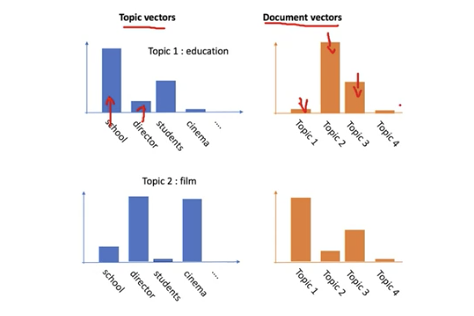
LDA
- 관찰된 문서내 단어들을 이용하여 베이즈 추론을 통해 잠재된 문서내 토픽 분호와 토픽별 단어분포를 추론하는 방식
- LDA 베이즈 추론의 사전 확률분포로 사용되는 것이 디리클레 분포임

켤레 사전 분포
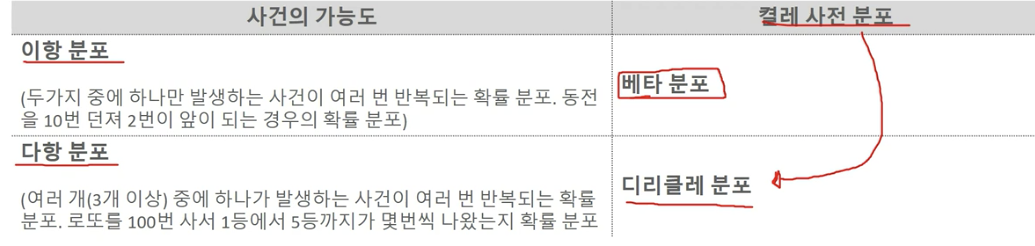
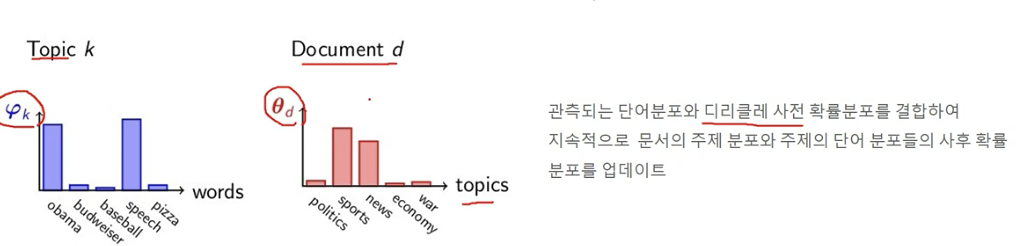
구성 요소
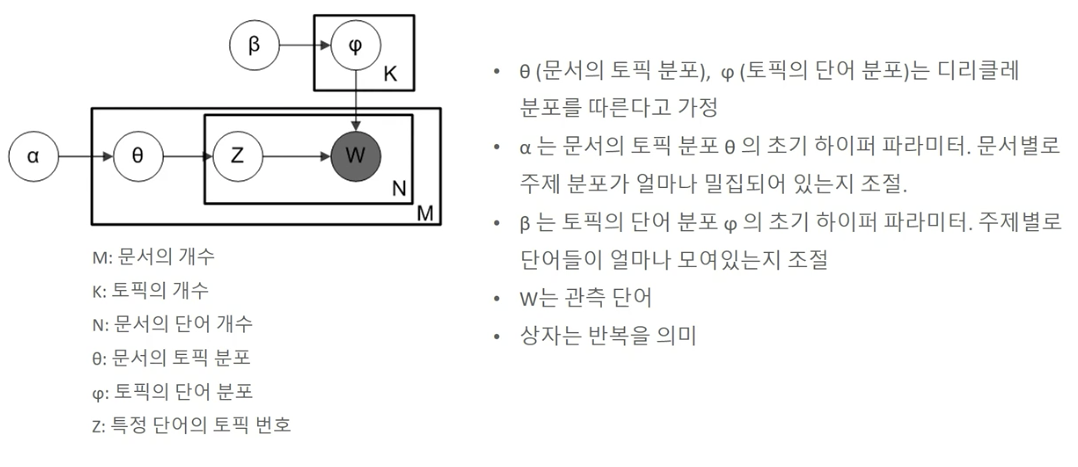
수행 프로세스

단점
- 추출된 토픽은 다시 사람의 주관적인 해석이 필요함
- 초기화 파라미터(토픽개수, , ) 및 Document-Term 행렬의 단어 필터링 최적화가 어려움
문서 군집화
- 비슷한 텍스트 구성의 문서를 군집화 하는 것
- 동일한 군집에 속하는 문서를 같은 카테고리 소속으로 분류할 수 있음
- 비지도학습 기반으로 동작함
문서 유사도 측정
- Cosine Similarity
- Jaccard Similarity
- Manhattan Distance
- Euclidean Distance
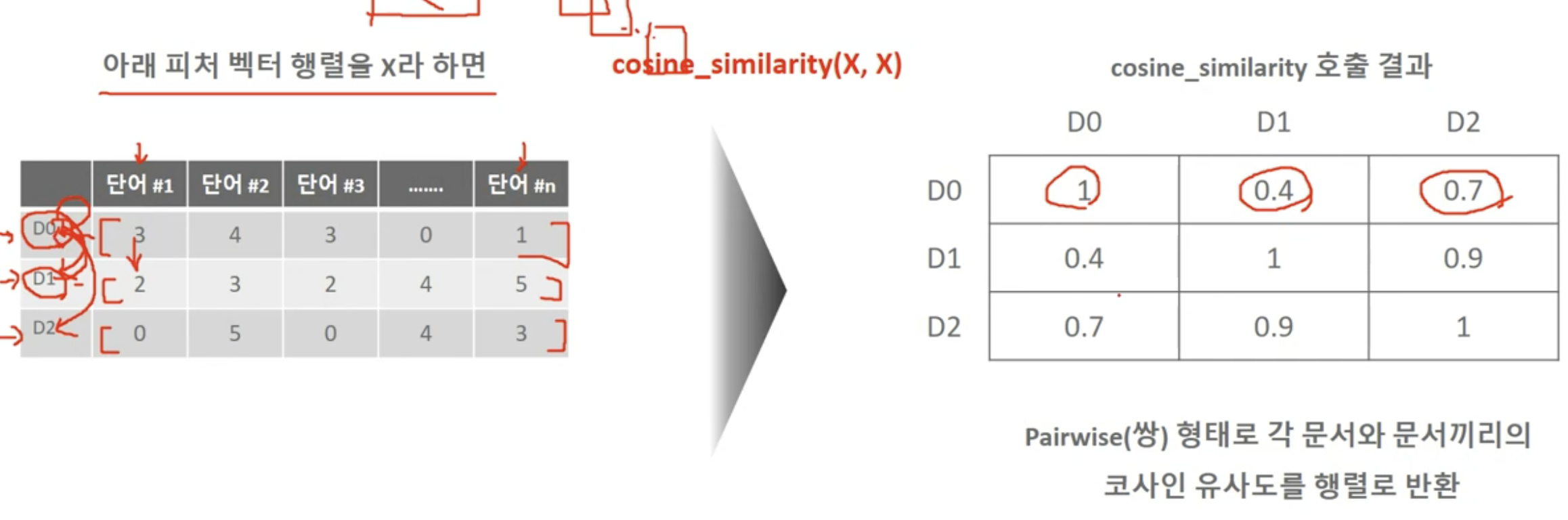
코사인 유사도
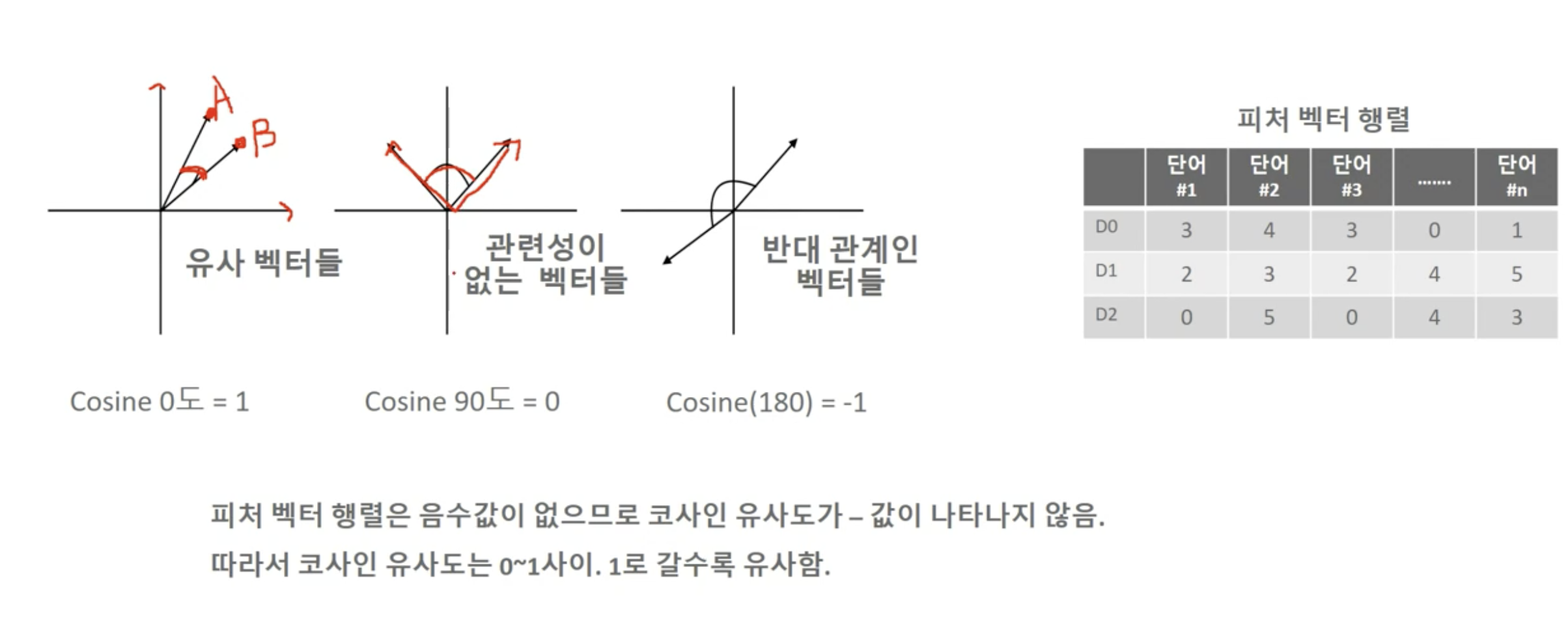
-
공식
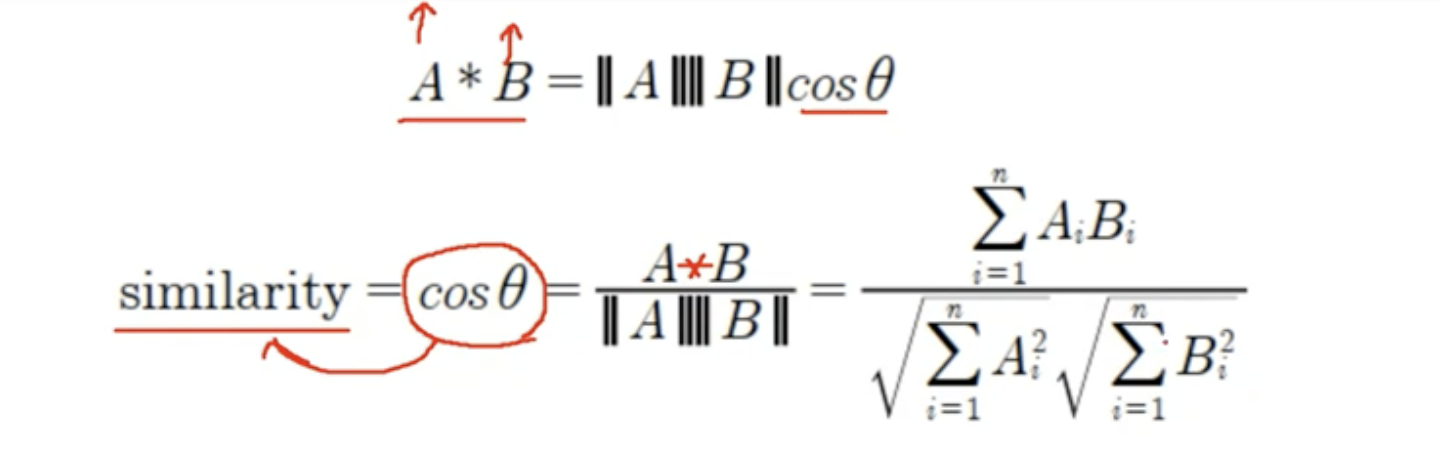
-
library: sklearn.metrics.pairwise.cosine_similarity
한글 NLP
- 한글 NLP를 어렵게 만드는 요인들
- 띄워 쓰기
- 다양한 조사
- 주어/목적어가 생략되어도 의미 전달 가능
- 의성어/의태어, 높임말 등
한글 형태소 분석
- 형태소의 사전적인 의미는 단어로서 의미를 가지는 최소 단위로 정의
- 형태소 분석(Morphological analysis)이란 말뭉치를 형태소 어근 단위로 쪼개고 각 형태소에 품사 태깅을 부착하는 작업을 일반적으로 지칭
- 예시
- 머릿결 --> 머리 + 결
- 너를 --> 너 + 를(을)
KoNLPy
- 기존의 C/C++, Java로 만들어진 한글 형태소 엔진을 파이썬 래퍼 기반으로 재작성한 패키지
- 종류
- 꼬꼬마
- 한나눔
- Komoran
- Mecab

Data Scientist, Data Analyst