출처: Natural Language Processing with Transformers by Lewis Tunstall, Leandro von Werra, and Thomas Wolf (O’Reilly). Copyright 2022 Lewis Tunstall, Leandro von Werra, and Thomas Wolf
Transformer Architecture
Original Transformer: Encoder Decoder architecture
- Encoder: 토큰의 입력 시퀀스를 임베딩 벡터 시퀀스로 변환 (hidden state or context)
- Decoder: encoder의 hidden state를 사용하여 한 번에 한 토큰씩 토큰의 출력 시퀀스를 반복적으로 생성
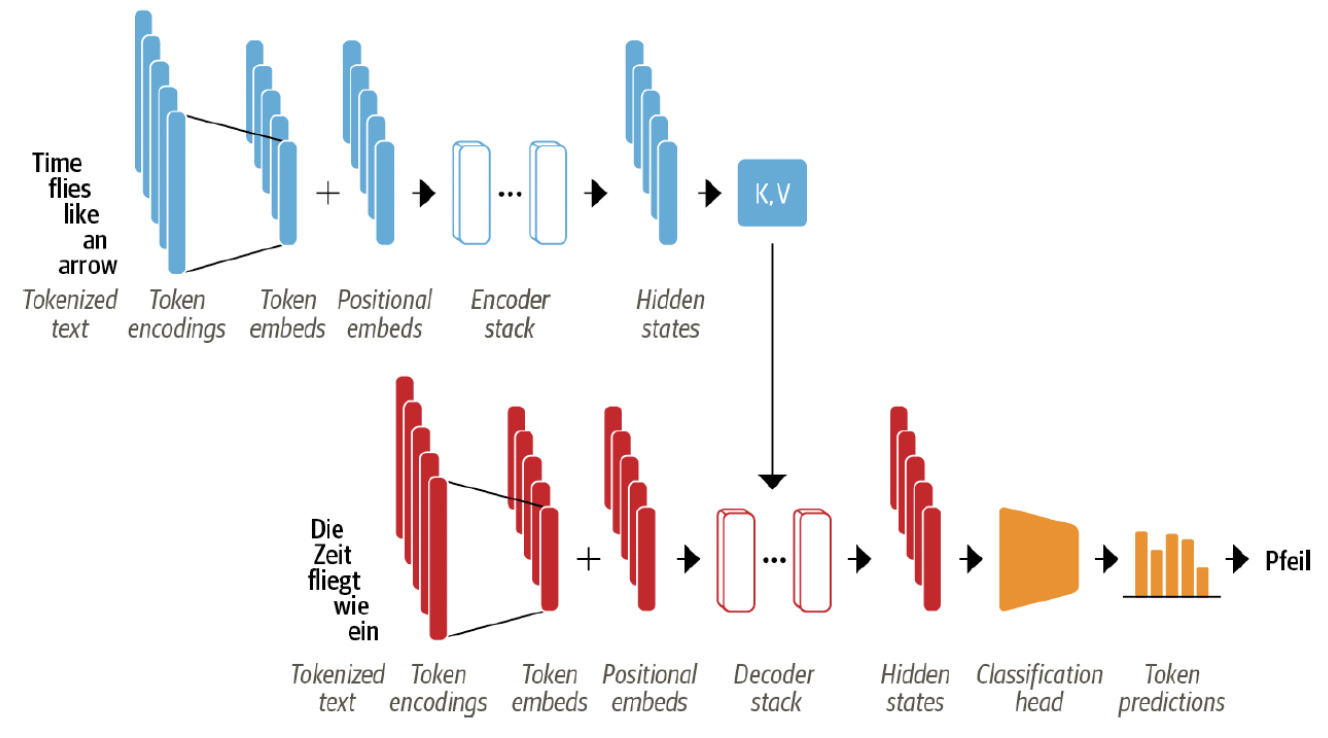
Characteristic of Transformer architecture
- tokenized input text
- token embeddings으로 변환
- token embeddings는 positional embeddings과 결합됨
- attention mechanism은 token의 상대적 위치를 알 수 없음
- 텍스트의 순차적인 특성을 모델링하기 위해 입력에 token 위치를 삽입해야함
- positional embeddings: 각 token의 위치 정보를 포함
- encoder/decoder 레이어 또는 블록의 스택으로 구성됨
- 컴퓨터 비전에서 convolutional layer를 쌓는 것과 유사
- encoder의 출력은 각 decoder 레이어에 제공됨
- decoder는 시퀀스에서 가장 가능성이 높은 next token에 대한 예측
- 예측된 출력값은 decoder로 피드백되어 next token을 생성
- decoder가 EOS token을 예측하거나 최대 길이에 도달할 때까지 진행
3 types of Transformer models
- Encoder only
- 텍스트의 입력 시퀀스를 숫자 표현으로 변환
- 텍스트 분류, 개체명 인식에 적합
- BERT (RoBERTa, DistilBERT)
- bidirectional attention
- Decoder only
- 가장 가능성이 높은 다음 단어를 반복적으로 예측하여 시퀀스를 자동 완성
- 왼쪽 context에만 의존
- family of GPT models
- causal(인과) or autoregressive(자기회귀) attention
- Encoder decoder
- 한 텍스트 시퀀스에서 다른 텍스트 시퀀스로 복잡한 매핑을 모델링할 때 사용
- 기계 번역, 요약 작업에 적합
- BART, T5
Reference

Data Scientist, Data Analyst