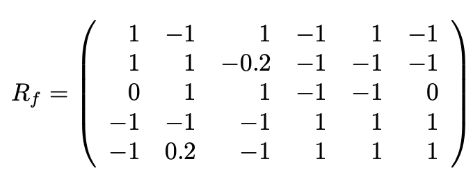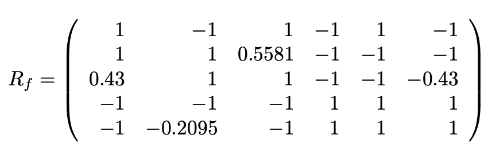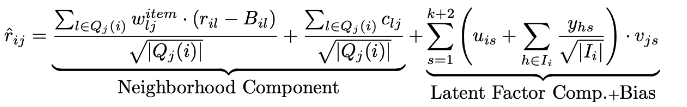출처
- Charu C. Aggarwal (2021) 추천시스템 : 기초부터 실무까지 머신러닝 추천 시스템 교과서. 에이콘 출판사 109-184p
- Charu C. Aggarwal (2016). Recommendation System. Springer International Publishing 93-160p
3.1 개요
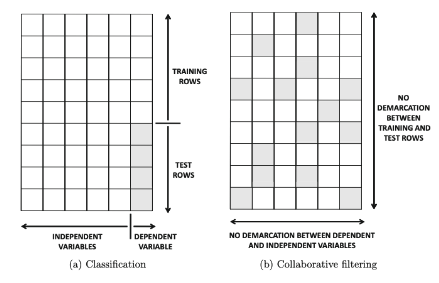
행렬 완성 문제와 전통적인 분류 문제의 차이
- 행렬 완성 문제:
- 독립변수와 종속변수의 구분이 없음
- train행과 test행의 구분이 없음
- 전통적인 분류 문제:
- 독립변수와 종속변수의 구분이 있음
- train행과 test행의 구분이 있음 (ex. 7:3, 8:2 등등)
협업필터링을 분류 모델과 비슷하게 추천 시스템으로 이해하는 것은
상당 수의 메타 알고리즘을 적용할 수 있게 해준다.
이웃 기반 방법 대비 모델 기반 추천 시스템의 장점
- 용량 효율성 (Space-efficiency)
- 용량 < O(m2), m: 사용자 수 or 아이템 수
- 학습 속도와 예측 속도
- 과적합 방지
3.2 의사 결정 및 회귀 트리
의사 결정 트리 : 종속변수가 범주형 데이터
회귀 트리 : 종속변수가 수치형 데이터
의사 결정 트리는 독립변수에서 split criteria로 데이터 공간을 계층적으로 분리
분리의 품질은 가중 평균 지니 계수 (Gini index)를 통해 평가
- Gini index:
- 수식: G(S)=1−∑i=1rpi2
- 값이 작을 수록 큰 분별 능력을 의미함
- p1…pr: 노드 S의 r개의 다른 클래스에 속한 데이터 기록의 분할 비율
- 값 범위: [0,1]
- 분할되는 Gini index (= 자식 노드 지니 계수의 가중 평균)
-
분할 시, 가장 작은 지니 계수를 갖는 속성이 선택됨
Gini(S⇒[S1,S2])=n1+n2n1⋅G(S1)+n2⋅G(S2)
* 3.2.1 의사 결정 트리를 협업 필터링으로 확장
의사 결정 트리를 협업 필터링으로 확장할 때 주된 문제점
- 피처 변수와 클래스 변수가 명확히 구분이 안됨
- 해결 방안: 각 아이템의 평점을 예측하는 별도의 의사 결정 트리를 구축
- 평점 행렬은 매우 sparse함 → 훈련 데이터를 계층적으로 분할하는 문제를 야기
- 해결 방안
- 누락된 데이터를 모든 branch에 할당
⇒ 훈련데이터를 더 이상 정확히 나누지 않게 됨
⇒ 테스트 인스턴스는 의사 결정 트리에서 다양한 경로에 대응됨
⇒ 충돌 발생
- [Re-Reading] 차원 축소 방법 적용
3.3 규칙 기반 협업 필터링
연관 규칙 마이닝의 핵심은 트랜잭션 DB에서 상관관계가 높은 아이템의 집합을 정하는 것
→ 지지도(support)와 신뢰도(confidence) 개념에 의해 이루어짐
- 정의
- I: 아이템 전체를 포함하는 전체 집합 (n개로 가정)
- T = {T1…Tm}, 각각의 거래 Ti는 I의 부분 집합
- 지지도 (X⊆I): T안의 부분집합 X의 트랜잭션의 비율
- A와 B 아이템의 지지도 = 전체 거래 항목 중에서 A와 B를 동시에 포함하는 거래 비율
- Support=P(A∩B)
- 신뢰도 (X⇒Y): 트랜잭션 T가 X를 포함할 때 Y도 포함할 조건부 확률
- A 아이템의 거래 중, B 아이템이 포함된 거래의 비율
- Confidence=P(B∣A)=P(A∩B)/P(A)=Support/P(A)
- 연관 규칙: 최소 지지도 s와 최소 신뢰도 c를 바탕으로 정의됨
- X∪Y의 지지도가 최소한 s
- X⇒Y의 신뢰도가 최소한 c
* 3.3.1 협업 필터링을 위한 레버리지 연관 규칙의 활용
연관 규칙은 단항 평점 행렬의 추천에 특히 유용함
최소 지지도와 최소 신뢰도는 예측 정확도를 높이기 위한 매개변수로 간주
3.3.2 아이템별 모델 vs 사용자별 모델
(사용자=앨리스, 평점=좋아요) ⇒ (사용자=밥, 평점=싫어요)
- 밥이 앨리스가 좋아하는 항목을 싫어할 가능성이 있음
(사용자=앨리스, 평점=좋아요) & (사용자=피터, 평점=싫어요) ⇒ (사용자=존, 평점=좋아요)
- 존은 앨리스가 좋아하고 피터가 싫어하는 항목을 좋아할 가능성이 있음
사용자-아이템 조합의 평가를 예측하기 위해, 해당 아이템에 대한 pseudo 사용자 기반 트랜잭션이 결정됨
3.4 나이브 베이즈 협업 필터링
Naive Bayes는 일반적으로 분류에 사용되는 생성 모델
협업 필터링에 적용하기 위해서는 기본 방법론을 약간 수정해야됨
- 협업 필터링은 모든 피처가 target class가 될 수 있고 불완전한 피처 변수와 작업해야하는 문제가 있기 때문
베이즈 규칙: P(A∣B)=P(B)P(A)⋅P(B∣A)
⇒ P(ruj=vs∣ObservedratingsinIu)=P(ObservedratingsinIu)P(ruj=vs)⋅P(ObservedratingsinIu∣ruj=vs) (3.4)
우변 분모의 값이 s와 관계 없기 때문에 (아래 식 3.5)
⇒ P(ruj=vs∣ObservedratingsinIu)∝P(ruj=vs)⋅P(ObservedratingsinIu∣ruj=vs)
- P(ruj=vs): j 항목에 대해 평가한 사용자의 비율로 추정됨
- P(ruj=vs∣ObservedratingsinIu): 나이브 가정을 사용해 추정 (평점 간의 조건부 독립성을 기반)
- 조건부 독립성(conditional independence)
- Iu의 다양한 항목에 대한 사용자 u의 평점이 서로 독립적
- P(ObservedratingsinIu∣ruj=vs)=∏k∈IuP(ruk∣ruj=vs) (3.6)
⇒ P(ruj=vs∣ObservedratingsinIu)∝P(ruj=vs)⋅∏k∈IuP(ruk∣ruj=vs) (3.7)
평점 ruj의 사후 확률 추정 방법
-
식 3.7의 우변을 각각의 s∈{1…l}에 대해 계산하고, 가장 큰 s값을 결정
ruj^=argmaxvsP(ruj=vs∣ObservedratingsinIu)
=argmaxvsP(ruj=vs)⋅∏k∈IuP(ruk∣ruj=vs)
- 평점을 범주형 값으로 취급
- 다양한 평점 사이의 모든 순서를 무시함
- 평점 수가 적을 때 합리적
-
예측된 값을 모든 평점의 가중 평균으로 추정
ruj^=∑s=1lP(ruj=vs∣ObservedratingsinIu)∑s=1lvs⋅P(ruj=vs∣ObservedratingsinIu)
=∑s=1lP(ruj=vs)⋅P(ObservedratingsinIu∣ruj=vs)∑s=1lvs⋅P(ruj=vs)⋅P(ObservedratingsinIu∣ruj=vs)
=∑s=1lP(ruj=vs)⋅∏k∈IuP(ruk∣ruj=vs)∑s=1lvs⋅P(ruj=vs)⋅∏k∈IuP(ruk∣ruj=vs)펴
3.4.1 과적합 처리
평가 matrix가 sparse하고, 관찰된 평가 수가 적을 때 발생
Laplacian smoothing 방법이 주로 사용됨
- P(ruj=vs)를 ∑t=1lqtqs로 추정하는 대신, (qt: j번째 아이템에 대한 평점 vt를 지정한 사용자 수)
- 라플라시안 스무딩 파라미터 α로 스무딩
P(ruj=vs)=∑t=1lqt+l⋅αqs+α (3.8)
- α값이 클수록 스무딩되는 효과가 더 크지만, 기본 데이터에 민감하게 영향을 받지 않음
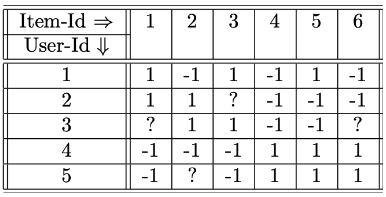
* 3.4.2 이진 평점에 대한 베이즈 방법의 예시
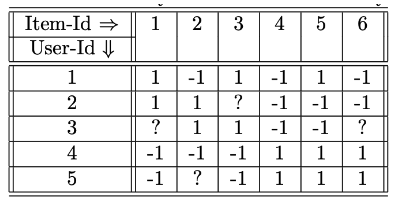
- P(ruj=vs): j 항목에 대해 평가한 사용자의 비율로 추정
- P(ruj=vs) = ∑t=1lqtqs
- P(r31=1) = 2 / 4 = 0.5
- P(r32=1∣r31=1) = P(r31=1)P(r32=1∩r31=1) = 1 / 2 = 0.5
- P(r33=1∣r31=1) = 1 / 1 = 1 (* user 2의 item 3이 null이므로 분모에 count를 안하는 것 같다)
- P(r34=−1∣r31=1) = 2 / 2 = 1
- P(r35=−1∣r31=1) = 1 / 2 = 0.5
→ P(r31=1∣r32,r33,r34,r35) = 0.5 0.5 1 1 0.5 = 0.125
→ P(r31=−1∣r32,r33,r34,r35) = 0
⇒ r31은 1의 값을 취할 확률이 더 높음 ⇒ 예측값은 1
3.5 임의의 분류 모델을 블랙 박스로 사용
평가 행렬이 단항인 경우
- 결측값을 0으로 추정하여 사용 가능
- 텍스트 마이닝 분류 알고리즘, SVM 적용 가능
평가 행렬이 단항이 아닌 경우
원래 피처 공간에서 작업하기 위해, 분류 방법을 반복 방법들과 메타 알고리즘으로 사용할 수 있음
-
결측값을 행 or 열의 평균을 사용하여 초기화
-
사용자 편향을 제거하기 위해 전처리 단계로 중앙에 배치할 수 있음 (선택 사항)
= 평균화 이후 결측치 0으로 입력
반복 단계 → 예측 항목의 편향을 반복적으로 줄일 수 있음
- 각 열에서 결측값은 target 변수로 지정하고 나머지는 피처 변수로 설정하고,
알고리즘 A를 사용해서 추정
- 알고리즘 A의 예측값으로 target 변수의 결측 값을 업데이트
3.5.1 Example: 신경망을 Black-Box로 사용
-
평균 중심화 행렬 생성
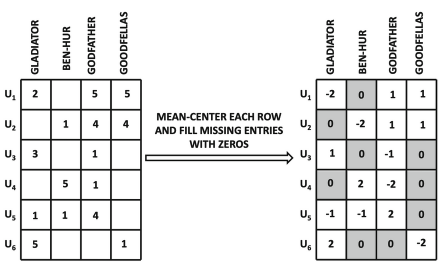
-
항목별 예측
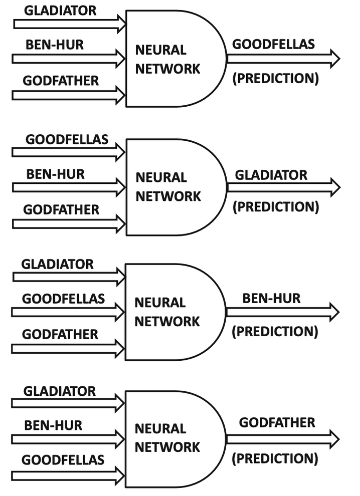
-
예측 값으로 결측값 업데이트
-
수렴이 될 때까지 반복
3.6 잠재 요인 모델
차원 축소 방법을 활용하여 결측값을 채움
차원 축소의 기본 아이디어: 축 시스템을 회전하여 차원 간의 쌍방향 상관관계를 제거하는 것
차원 축소의 핵심 아이디어: 축소, 회전 및 완전히 명시된 표현이 불완전한 데이터 행렬에서 강건하게 추정 가능
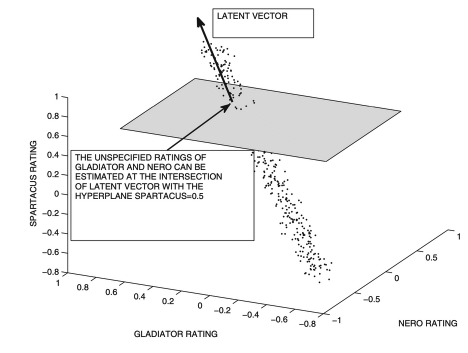
* 3.6.1 잠재 요인 모델에 대한 기하학적 직관
평가가 양의 상관관계가 있는 경우, 평가의 3차원 산점도는 1차원 선(잠재 벡터)을 따라 배열 될 수 있음
PCA, SVD와 같은 차원 축소 방법은 일반적으로 이 선을 따라 데이터를 근사적으로 투영함
Basic Idea: 잠재 벡터에 의해 정의된 초평면에서 데이터 포인트(개별 사용자의 평가)의 평균 제곱 거리가
가능한 작은 잠재 벡터 세트를 찾는 것
3.6.2 잠재 요인 모델에 대한 저차원 직관
행렬의 인수분해를 활용 R=UVT
- R: 평점 행렬 (m x n)
- U: m x k
- V: n x k
- Rank-2 행렬 인수분해 예제
-
U: 두 장르에 대한 사용자의 경향
-
V: 두 장르의 영화 멤버십
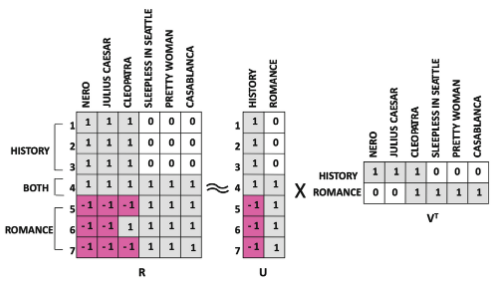
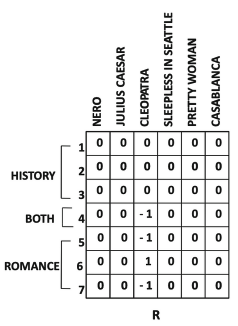
- 인수분해에 대한 잔차 행렬 (CLEOPATRA 기준)
3.6.3 기본 행렬 인수분해의 원리
R≈UVT
- U or V
- 각 열: 잠재 벡터 or 잠재 성분
- 각 행: 잠재 요인
rij≈uiˉ⋅vjˉ
≈∑s=1kuis⋅vjs
=∑s=1k(개념s에대한사용자i의선호도)×(개념s에대한사용자j의선호도)
3.6.4 제약 없는 행렬 인수분해
SVD(Singular Value Decomposition)에서 U, V Column은 직교해야된다.
행렬 R과 UVT를 어떻게 최대한 일치시킬 수 있을까?
MinJ=21∣∣R−UVT∣∣2 ⇒ 목적함수가 작을 수록 더 일치함
But.. 누락된 항목을 갖는 행렬은 위 Frobenius norm을 계산 할 수 없다
⇒ 관측된 항목에 대해서만 U,V를 학습
S={(i,j):관측된rij}
R의 (i,j)번째 항목 예측값
rij^=s=1∑kuis⋅vjs
특정 항목 (i,j)의 관측값과 예측 값의 차이: eij=(rij−rij^)=rij−∑s=1kuis⋅vjs
MinJ=21(i,j)∈S∑eij2=21(i,j)∈S∑(rij−s=1∑kuis⋅vjs)2
배치 업데이트 방법
위 식으로부터 오차 eij2를 최소화 하기위해 학습을 진행
→ 경사하강법으로 해결 가능 → uiq,vjq에 대한 J의 편미분 계산 필요
∂uiq∂J=j:(i,j)∈S∑(rij−s=1∑kuis⋅vjs)(−vjq)∀i∈{1...m},q∈1....k
=j:(i,j)∈S∑(eij)(−vjq)∀i∈{1...m},q∈1....k
∂vjq∂J=i:(i,j)∈S∑(rij−s=1∑kuis⋅vjs)(−uiq)∀j∈{1...m},q∈1....k
=i:(i,j)∈S∑(eij)(−uiq)∀j∈{1...m},q∈1....k
전체 벡터(VAR)에 대해 VAR ← VAR−α⋅ΔJ 로 업데이트
확률적 경사하강법
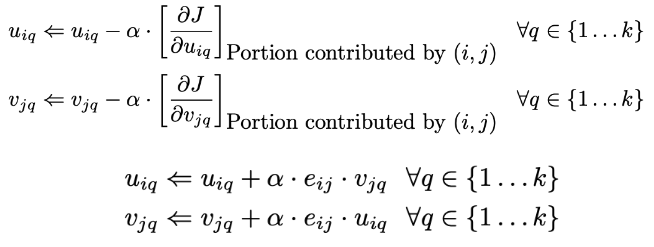
배치 업데이트 방법은 관측된 항목에서 오류의 선형 함수를 구했음
확률적 경사하강법은 개별 관찰 항목의 오류와 관련된 더 작은 요소로 분해하여 구할 수 있음
데이터 크기가 매우 크고, 계산 시간이 오래 걸리는 경우, 배치에 비해 효율적임
더 빠른 수렴이 가능함 (무작위로 선택된 단일 항목의 오류를 기반으로 업데이트)
일반적인 learning rate (α)는 0.005로 설정
*Bold driver algorithm: 국소 최적해를 피하면서 수렴 속도를 높이는 방법
정규화
평점 행렬이 희소하기 때문에 과적합이 생길 수 있음 → 일반적으로 정규화로 해결
정규화는 모델에 bias를 도입하는 대신에 모델이 과적합되는 경향을 줄임
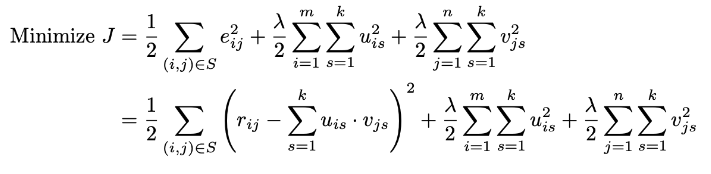
편미분 공식
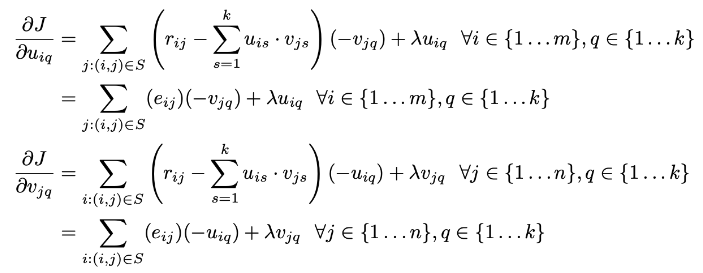
최적의 λ값이 선택되면 모델은 특정 학목의 전체 데이터 세트에 재학습
→ 이러한 파라미터 튜닝 방법을 “홀드 아웃 방법"이라고 함
But 때로는 최적의 λ값을 얻는 비용이 많이 들 수 있음
→ Gibbs sampling 활용 (파라미터와 하이퍼 파라미터를 공동 학습)
3.6.5 특이값 분해
U,V의 열이 서로 직교하도록 제약되는 행렬 인수분해의 한 형태
R≈Qkk∑PkT
U=Qk∑k, V=Pk
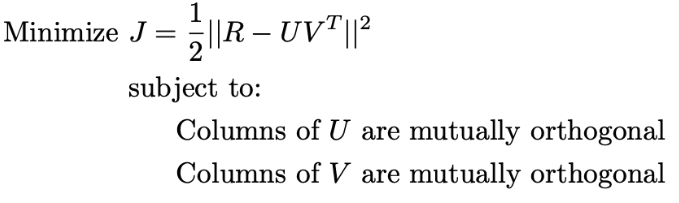
제약 없는 행렬 인수분해와의 차이는 직교성 제약 조건이다.
특이값 분해는 제약 없는 인수분해 대비 더 작은 공간의 솔루션에 최적화됨
간단한 반복 접근
추정을 개선하여 반복적으로 편향을 줄이는 방법
단계
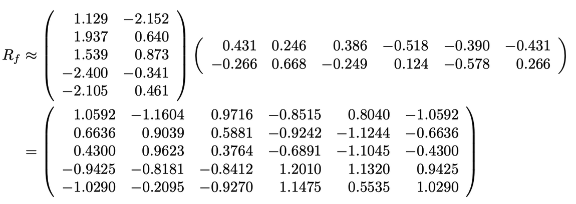
- R의 각 행을 평균 중심에 두는 것 (평균화 실행 R→Rf)
- 누락 항목은 0으로 설정됨
- Rank-K SVD 수행 → Rf=Qk∑kPkT
- 누락된 항목 추정 (rij^=uiˉ⋅vjˉ+μi)
초기 단계에서는 bias를 유발하지만 이후 반복함으로써 강력한 추정치를 제공
누락된 원소의 수가 많으면, 국소 최적 상태에 빠질 수 있음
→ 베이스 라인 예측자를 사용 (강력한 초기화 수행)
→ 학습된 사용자 및 아이템의 bias를 활용하여 초기 예측값을 계산
최적화 기반 접근
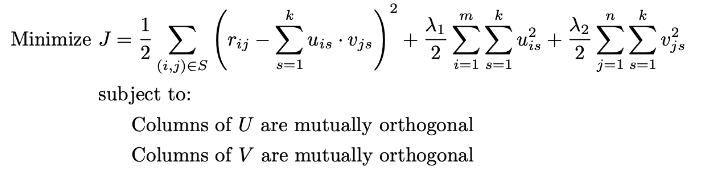
반복 접근법은 대규모 설정에서는 확장성이 어려움
→ 최적화 모델에 직교성 제약 조건을 추가하는 것
표본 외 추천
행렬 완성 방법은 평점 행렬에 존재하는 사용자 및 아이템에 대해서만 예측이 가능함
직교 벡터는 새로운 사용자 및 아이템에 대해 표본 외 추천을 좀더 쉽게 수행할 수 있음
→ 귀납적 행렬 완성 (Inductive matrix completion)
새로운 사용자는 UorV의 잠재요인으로 표시되지 않음
새 사용자가 총 h평가를 했다면, 평점 가능성 공간은 (n−h)차원 초평면이다 (h는 이미 평가를 해서, 고정)
초평면 H1에 가까운 H2지점을 결정
세 가지 가능성
- H1과 H2가 교차하지 않음 → 간단한 제곱합 최적화 문제
- H1과 H2는 고유한 지점에서 교차 → 교차점의 평점 값을 사용
- H1과 H2는 t차원 초평면에서 교차 → t차원 초평면에 가까운 평점을 모두 찾아야됨
→ 잠재 요인과 이웃 방법을 결합
예시
3.6.6 음이 아닌 행렬 분해
NMF(Non-negative Matrix Factorization)
이 방법은 사용자와 아이템의 상호 작용을 이해할 수 있도록 높은 수준의 해석을 제공함
Data: 암시적 피드백 데이터 세트
- 활동 빈도에 해당되는 단항 평점 or 행렬을 포함
ex. 아이템 구매, 아이템 탐색 행동, 좋아요 버튼, 아이템 선택 (클릭)
최적화 공식
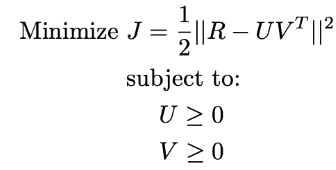
Lagrangian relaxation 방법 사용
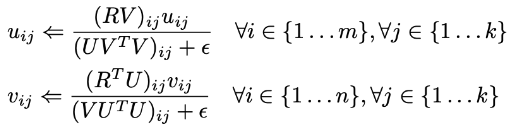
정규화
- 목적함수에 패널티 추가
- 과적합 방지를 위해 Tikhonov 정규화를 사용할 수 있음
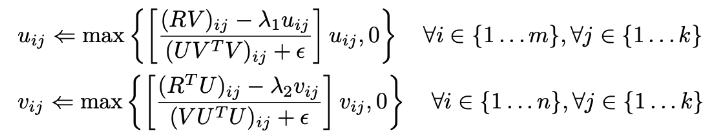
해석 가능성의 장점
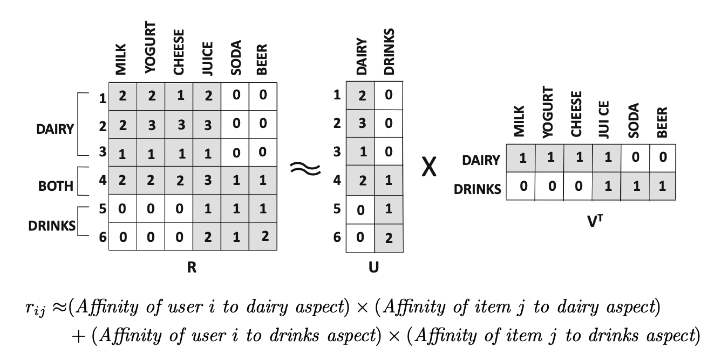
위 결과에서 모든 고객이 juice를 좋아하는 것처럼 보이나,
행렬 U를 통해, 1~4 고객은 유제품을 4~6 고객은 음료를 좋아하는 것을 알 수 있음
→ 행렬의 부분합 분해를 보여줌
누락된 데이터의 경우, 빈도수가 낮은 값으로 대체할 수 있다.
→ 데이터 부족으로 인한 과적합 방지 가능
ex. 단항평점에서 1이 더 많은 경우, 결측값을 0으로 대체
많은 양의 0 항목을 처리하는 계산 문제를 효율적으로 분해 과정 방법: ALS
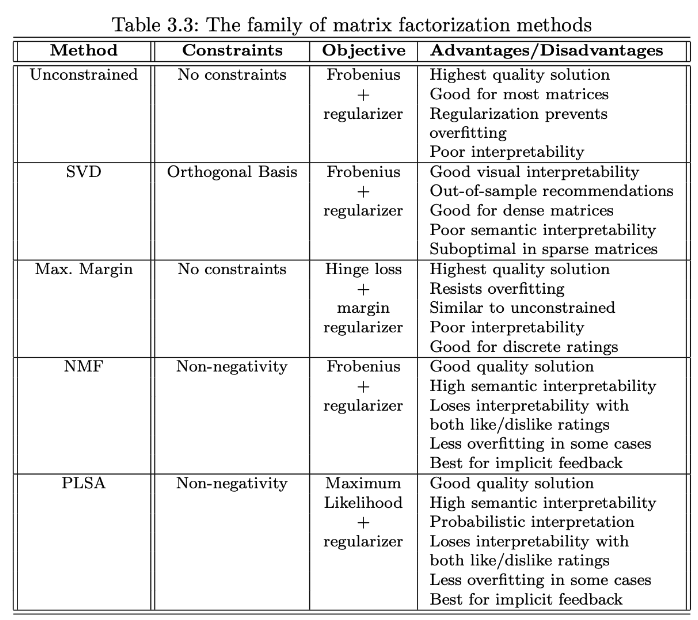
3.6.7 행렬 분해 Family의 이해
3.7 인수 분해와 이웃 모델의 통합
베이스라인 추정 모델 (개인화 X)
- 예측 평점
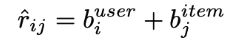
- S의 정의
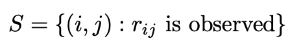
- 목적 함수
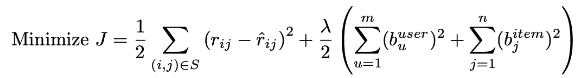
- Bias 업데이트
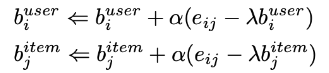
모델의 이웃
- 예측 평점
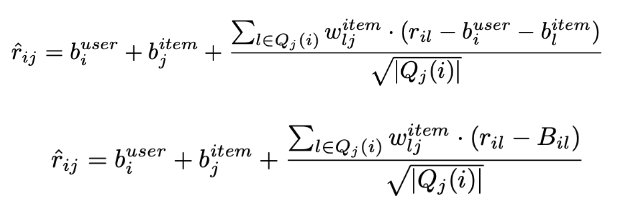
- 값 업데이트
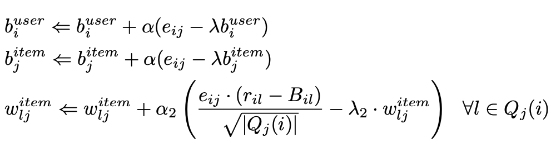
- 암시적 피드백으로 향상
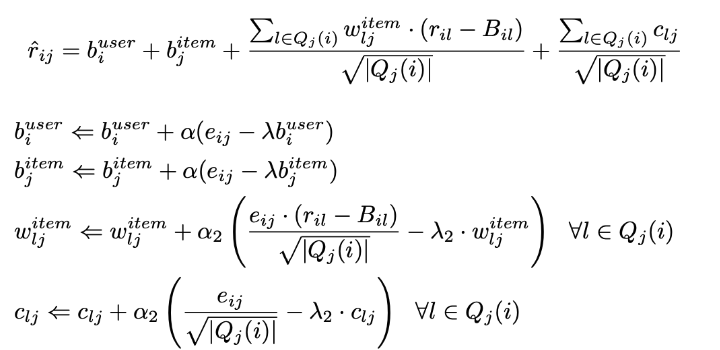
모델의 잠재 요인
- 예측 평점
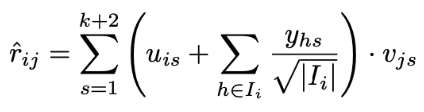
통합
결합된 모델이 개별 모델에 비해 우수한 결과를 제공함
하이브리드 추천 시스템에서 자주 사용되는 아이디어와 유사함
Bias 변수가 두 구성 요소에 의해 공유되어 과적합을 방지함
잠재 요인 모델을 임의의 모델과 통합
- 예측 평점
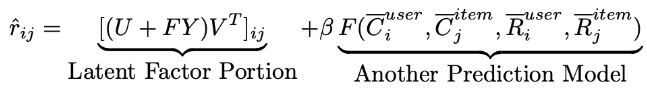
Reference
- Recommender Systems: The Textbook, Charu Aggarwal, 2016
- 연관성분석, LIB