출처
- Charu C. Aggarwal (2021) 추천시스템 : 기초부터 실무까지 머신러닝 추천 시스템 교과서. 에이콘 출판사 185-218p
- Charu C. Aggarwal (2016). Recommendation System. Springer International Publishing 161-188p
4.1 Introduction
컨텐츠 기반 추천 시스템 (Content-Based Recommend System)
: 사용자가 과거에 좋아했던 것과 유사한 아이템을 사용자에게 추천
특징
- 사용자의 평점과 사용자가 좋아하는 아이템의 속성에 중점 → 다른 사용자 평점이 불필요
- 콜드 스타트 문제를 부분적으로 완화
- 새로운 콘텐츠 → 속성을 추출하여 예측 가능
- 새로운 사용자 → 해결 불가능 😓
- 다양성과 참신성이 떨어짐
- 다른 사용자 평점을 사용하지 않기 때문
- 사용자가 이전에 이용한 아이템 기반 추천을 하기 때문
활용
- 주로 많은 양의 속성 정보가 있는 시나리오에서 사용됨
-
기본 객체에서 텍스트 속성을 추출하기 때문
→ 텍스트가 풍부하고 구조화되지 않은 도메인에서 추천하는데 적합 (Ex. Web Page, E-Commerce ..)
-
4.2 기본 구성 요소
- 사용자의 다양한 아이템에 대한 설명 및 지식을 사용 → 비정형 데이터를 표준화해야됨
- 키워드로 변환하는 것이 좋음
- 주로 텍스트를 이용하는 분야에서 사용됨
구성 요소
- 전처리 및 피처 추출
- 피처를 추출하여 키워드 기반 벡터 공간으로 변환
- 사용자 프로파일의 콘텐츠 기반 학습
- 각 사용자의 구매 또는 평가한 아이템의 과거 이력을 기반으로 예측
- 사용자 피드백 활용
- 이전에 등록한 평점 (명시적 피드백)
- 사용자 활동 (암시적 피드백)
- 사용자의 평점을 아이템의 속성과 관련시키기 때문에 “user profile”이라고 함
- 필터링 및 추천
- 학습된 모델을 사용해 특정 사용자의 아이템에 대한 추천을 함
- 예측이 실시간으로 수행되어야 하기 때문에, 효율성이 필요함
4.3 전처리 및 피처 추출
피처 추출
- 아이템 간의 차이를 구분할 수 있도록 함 → 사용자의 관심 분야 예측
- 애플리케이션별로 다름
4.3.1 피처 추출
- 다양한 아이템에 대한 설명을 추출
- 기본 데이터에서 키워드를 추출 (ex. 책을 판매하는 사람: 책에 대한 설명 + 내용 + 제목 + 저자 등)
- 경우에 따라 키워드를 다차원 표현으로 작업할 수 있음
- 피처 가중치 설정이 필요
- 속성의 중요도에 따라 차별화
4.3.1.1 상품 추천 예시
- 도메인 별 지식을 사용해 키워드의 상대적 중요성을 결정 할 수 있음 (ex. 영화 제목 > 영화 설명 단어)
- 시행 착오를 통해 경험적 방식으로 수행
- 다양한 피처의 상대적 중요성을 자동화된 방식으로 학습하는 것이 가능할 수 있음
- 피처 가중치 설정 단계를 의미
4.3.1.2 웹 페이지 추천 예시
구조의 공통 속성과 내부의 링크가 많기 때문에 특수한 전처리 기술이 필요함
- 불필요한 특정 부분(ex. 태그)을 제거한 후, 문서의 실제 구조를 활용
- 중요도: 문서 제목 > 본문
- 앵커 텍스트: 링크에 대한 설명 (ex. 구글 “요런거" 키워드 검색)
- 주제와 관련정규화
- 주요 블록 추출
- 주요 블록을 결정하는 것은 데이터 마이닝이 별도로 필요
- 가장 자동화된 방법은 특정 사이트가 일반적으로 모든 문서에 유사한 레이아웃을 사용한다고 가정함
- 사이트의 태그 트리를 추출해서, 사이트의 문서에서 레이아웃의 구조를 학습함
- 트리 매칭 알고리즘 사용
4.3.1.3 음악 추천 예시
초기에 관심 있는 트랙을 지정 → 사례 기반 추천 시스템
사용자의 평점 피드백으로 음악을 추천 → 컨텐츠 기반 추천 시스템
4.3.2 피처 표현 및 정제
구조화되지 않은 형식의 표현에 사용될 때 특히 중요함 ⇒ 구조화되지 않은 설명에서 키워드 모음을 결정 가능
- 불용어 제거 (Stop-word removal)
- 관련 없는 단어 제거 (ex. 관사, 전치사, 접속사 등)
- 어간 추출 (Stemming)
- 동일한 단어(=유사어)를 통합 (ex. 단수/복수, 과거/현재/미래 시제)
- 구문 추출 (Phrase extraction)
- 문서에서 함께 자주 발생하는 단어를 검색
1,2,3 단계 실행 후, 키워드를 벡터 공간 표현으로 변환
가치 없는 단어 처리: 역문서 빈도(IDF) 사용 ⇒ tf-idf
- 한 단어가 과도하게 나타나는 것을 중요하지 않도록 방지 → 감쇠 함수(damping function) 사용
- 정규화된 빈도:
4.3.3 사용자가 좋아하는 것과 싫어하는 것 수집
사용자가 좋아하는 것과 싫어하는 것에 대한 데이터
- 평점: 아이템에 대한 선호도
- 암시적 피드백: 아이템 구매 or 검색과 같은 사용자의 행동
- 텍스트 의견: 텍스트로 작성한 피드백 → 암시적 평점 추출 가능
- 사례: 관심 있는 아이템의 예시를 명시 → 최근접 이웃 or Rocchio 분류 모델을 통해 암시적 피드백으로 사용
위 자료들을 기반으로 실제 평점으로 변환 가능 → 학습에 사용하는 종속 변수로 볼 수 있음
4.3.4 Supervised Feature Selection and Weighting
피처 선택: 단어 제거
가중치 설정: 단어에 더 큰 중요성을 부여
피처 선택 방법
-
지니 계수
- 값이 작을 수록 더 큰 식별력을 의미
- : 사용 가능한 평점의 총 개수
- : 각각 사용 가능한 t값에서 평가된 아이템의 비율
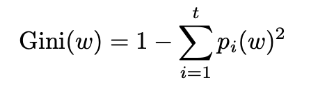
-
엔트로피
- : 사용 가능한 평점의 총 개수
- 작은 값은 차별성을 더 잘 보여줌
- 값의 범위: (0, 1)
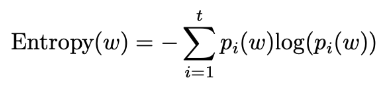
-
통계
- 단어와 클래스 간 동시 발생을 분할표로 처리해 계산 할 수 있음
- 통계의 값이 클수록 특정 용어와 아이템이 더 큰 관련이 있음

-
정규화된 편차
- 평점이 많이 세분화 됐을 때 활용
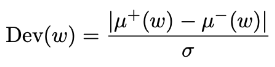
- : 단어 w를 포함하는 모든 문서의 평균 평점
- : 단어 w를 포함하지 않는 모든 문서의 평균 평점
- 값이 클수록 더 차별적인 단어를 의미
피처의 가중치 설정
- 비지도 측정: 역문서 빈도
- 지도 측정: 피처 선택 측정 값을 가져와서 가중치를 유도
-
범위:
-
값이 작으면 민감도가 높아짐 (: 가중 함수의 매개변수)
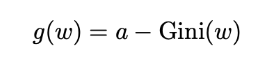
-
4.4 사용자 프로파일 및 필터링 학습
활성 사용자: 해당 사용자가 시스템에서 추천을 받은 경우
활성 사용자가 지정한 평가만 학습 데이터로 사용됨
→ 학습 모델은 활성 사용자에게만 적용됨
→ 활성 사용자에 대한 학습 모델은 사용자 프로파일을 나타냄
4.4.1 최근접 이웃 분류
유사함수 정의 → 코사인 유사도 (정규화된 빈도 사용)
코사인 유사도는 원본 문서의 다양한 길이에 맞게 조정할 수 있기 때문에, 텍스트 도메인에서 자주 사용
유사도 함수는 사용자 선호도가 알려지지 않은 아이템을 예측할 때 유용
계산 복잡도:
→ 클러스터링(ex. k-means)을 사용하여 의 학습 문서 수를 줄이면, 속도 향상 가능
4.4.2 사례 기반 추천 시스템과의 연결
최근접 이웃 방법은 일반적으로 지식 기반 추천 시스템과 연결됨 (특히 사례 기반 추천 시스템)
사례 기반 추천 시스템은 사용자가 한 개의 관심 있는 사례를 선택 (대화형)
→ 사례의 가능한 아이템을 받을 수 있음
오직 하나의 사례만 이용할 수 있음..!
→ 유사도 함수를 설계할 때 상당한 양의 도메인 지식을 활용
4.4.3 베이즈 분류 모델
: 훈련 문서를 포함하는 세트
: 테스트 문서를 포함하는 세트
베르누이 모델에서 단어의 빈도는 무시되고, 문서의 단어 존재 여부만 고려함
, 개의 이진 특성 , 평가
: i번째 단어가 문서 에 존재하는지 여부 (0, 1)
, 중에서 큰 것을 선택
→ 베이즈 규칙을 사용 → Naive assumption 적용 (개별 사건은 독립적)
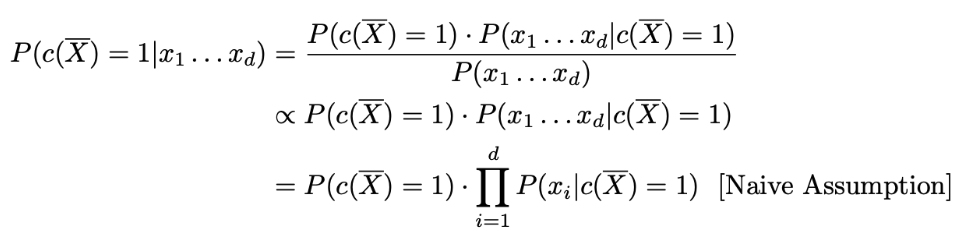
아이템 순위가 필요한 경우에는 비례 상수를 결정해야됨
→ 비례 상수 K는 모든 확률의 합이 1인 사실로 얻을 수 있음
4.4.3.1 중간 확률 추정
베이즈 규칙은 데이터 기반 방식으로 다른 확률에 대한 예측 확률을 표현함
베이즈 확률 계산
- 베이즈 조건
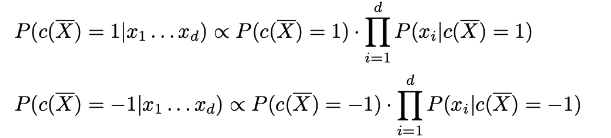
- 우측 식의 확률을 추정해야됨 → 과적합을 줄이기 위한 라플라시안 평활화 수행 ()
- 라플라시안 평활화는 학습데이터가 거의 없는 경우에 유용함
→ 훈련 데이터 양이 제한되었을 때, 이전에 옳다고 믿었던 것에 대한 중요성이 더 크다는 관점으로 해석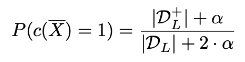
- 라플라시안 평활화는 학습데이터가 거의 없는 경우에 유용함
- 확률 추정
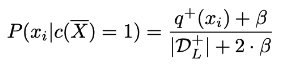
* 4.4.3.2 베이즈 모델의 예시
아래 특정 유저의 정보가 표로 정리되어 있을 때,
베이즈 모델을 사용하여 테스트 예제의 관찰된 피처를 기반으로 “Like/Dislike”에 대한 조건부 확률을 도출 할 수 있음
- 표
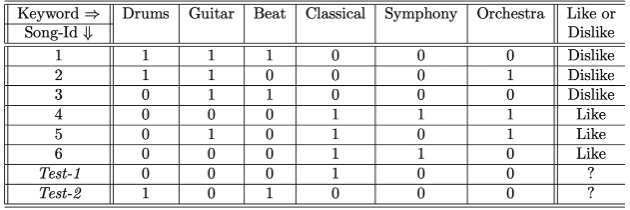
- 확률
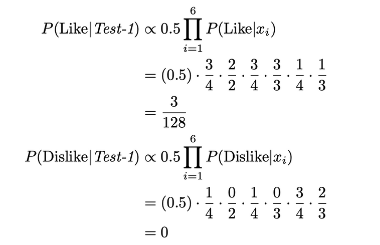
4.4.4 규칙 기반 분류 모델
사용자에 대한 모든 규칙을 마이닝하는 것
사용자의 관심을 알 수 없는 아이템에 대해서는 어떤 규칙을 실행할 것인지 결정
높은 수준으로 해석할 수 있는 장점이 있음
규칙의 지지도: 선행 규칙과 결과 규칙을 모두 충족시키는 행의 비율
규칙의 신뢰도: 선행을 만족시키는 것으로 알려진 행에서 결과를 만족시키는 행의 비율
전반적인 접근 방식
- 학습 단계
- 에서 원하는 수준의 최소 지지도 및 신로도에서 사용자 프로파일의 모든 규칙을 결정
- 테스트 단계
- 의 각 아이템 설명에 대해 실행된 규칙과 평균 평점을 결정 → 평균 평점을 기준으로 의 아이템 순위 결정
4.4.5 회귀 기반 모델
회귀 기반 모델은 binary, 구간, 수치 평가와 같은 다양한 평가에 사용할 수 있음
- : 크기 d의 어휘에 대한 학습 세트 n개의 문서를 나타냄
- : 각 단어의 계수
예측을 최대화하기 위해 → 벡터 노름의 제곱을 최소화
- : 과적합을 줄이기 위한 정규화 항 추가 ⇒ Tikhonov 정규화
우항 미분
⇒
- 평가의 성격 별 적용 가능한 회귀 모델
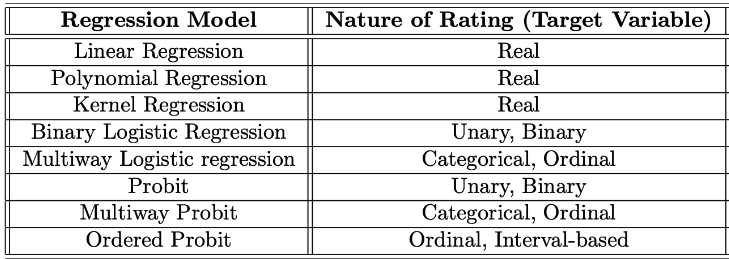
4.4.6 기타 학습 모델 및 비교 개요
콘텐츠 기반 필터링은 분류/회귀 모델링을 적용하기 때문에 다양한 기술이 사용될 수 있음
의사 결정 트리 → 텍스트와 같은 고차원적인 데이터에 효과적이지 못함
규칙 기반 분류 → 피처 공간의 엄격한 분할을 가정하지 않기 때문에 우수한 결과 제공
베이즈 방식 → 적절한 모델을 사용해 모든 유형의 피처 변수를 처리할 수 있는 이점이 있음
SVM → 과적합에 대한 내성이 뛰어남, 텍스트와 같은 고차원 데이터에도 사용 가능
신경망 → 사용 가능한 데이터 양이 적을 때는 권장하지 않음 (과적합 가능성이 있음)
4.4.7 콘텐츠 기반 시스템에 대한 설명
콘텐츠 기반 시스템은 콘텐츠 피처를 기반으로 모델을 추출하기 때문에,
추천 프로세스를 통찰력 있게 해석하는 경우가 많다.
→ 특정 아이템이 왜 좋은지에 대한 이유를 사용자에게 제시 할 수 있음 (ex. A 영화 - B 장르, C 배우 등..)
이러한 세부적인 설명은 협업 시스템에서 부족한 경우가 많음
통찰력의 정도는 사용하는 모델에 따라 다름
- 베이즈 모델, 규칙 기반 시스템 → 특정 인과 관계에 대해 해석을 잘함
- 선형 및 비선형 회귀 모델 → 해석이 어려움
- 라쏘 → 가장 관련성이 높은 기능에 대한 통찰력 제공
4.5 콘텐츠 기반 vs 협업 필터링
콘텐츠 기반 장점 (콘텐츠 기반 > 협업 필터링)
- 새 아이템 추가 시, 의미 있는 추천 가능
- 협업 필터링: 새로운 아이템, 사용자 모두에 콜드 스타트 문제 존재
- 콘텐츠 기반: 새로운 사용자에 콜드 스타트 문제 존재
- 아이템의 피처 측면에서 설명을 제공
- 상용 텍스트 분류 모델과 함께 사용할 수 있음
콘텐츠 기반 단점 (콘텐츠 기반 < 협업 필터링)
- 참신함(novelty)과 우연성(serendipity)이 떨어짐
- 콘텐츠 기반: 사용자가 지금까지 본 것과 유사한 아이템을 찾는 경향이 있음
- 협업 필터링: 피어 그룹의 관심을 활용해 새로운 아이템 추천 가능
- 새로운 사용자에 대한 콜드 스타트 문제
4.6 협업 필터링을 위한 콘텐츠 기반 모델 사용
협업 필터링 매핑
- “#” 기호를 이용하는 표현에 대한 최근접 이웃 분류 모델 → (협업 필터링) 아이템 기반 이웃 모델
- “#” 기호: 연결의 구분을 표시 + 각 사용자 평가 조합에 대한 고유한 키워드를 확인
- (콘텐츠) 대한 회귀 모델 → (협업 필터링) 사용자별 회귀 모델
- (콘텐츠) 규칙 기반 분류 모델 → (협업 필터링) 위한 사용자별 규칙 기반 분류 모델
- (콘텐츠) 베이즈 분류 모델 → (협업 필터링) 사용자별 베이즈 모델
- 사용자 프로파일이 지정된 키워드의 형태로 사용될 때 → 콘텐츠 속성으로 협업 필터링 모델 가능
⇒ 사용자가 지정한 피처를 통해 모든 사용자에 대한 전역 분류 모델을 만들 수 있음
⇒ 사용자 - 아이템의 조합을 사용자와 아이템의 속성 벡터의 크로네커 곱(Kronecker-product)으로 만들 수 있음
이러한 방법들은 콘텐츠 기반과 협업 필터링을 결합한
하이브리드 추천 시스템에서 사용할 수 있음
